
- 1【iosH5开发】IOS浏览器对于Vue3 Element-plus el-input中,input.value.focus无法聚焦问题_element plus el-input focus函数不存在
- 2Java 多线程(一)—— 概念的引入
- 3CSS【详解】层叠 z-index (含 z-index 的层叠规则,不同样式的层叠效果)
- 4常见经典目标检测算法_最流行的目标检测算法
- 52023软件测试的4个技术等级,你在哪个级别?_软件测试工程师职级评定
- 6云计算基础:理解AWS、Azure和Google Cloud_对云服务(如aws,azure,阿里云等)的理解如何?
- 7Python 学到什么程度才可以去找工作?掌握这四点足够了!_python学到什么程度可以找工作
- 82024年Android最新Android过渡动画,发现掘金小秘密(1),数据结构与算法面试题库_android过渡动画leash
- 9Flutter完整开发实战详解(一、Dart语言和Flutter基础)
- 10SM4加密算法原理以及C语言实现_sm4算法如何将一个字分成4个字节c语言
Attention优化|2w字原理&图解: 从Online-Softmax到FlashAttention V1/V2/V3_online softmax
赞
踩
Attention优化|2w字原理&图解: 从Online-Softmax到FlashAttention V1/V2/V3

作者丨DefTruth@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/668888063
本文首先从Online-Softmax的角度切入,由浅入深地讲解了3-pass Safe-Softmax、2-pass Online-Softmax以及1-pass FlashAttention的原理;然后,进一步详细讲解了FlashAttention-1和FlashAttention-2算法中各自的优化点、FlashAttention IO复杂度分析以及适用场景、FlashAttention在分布式训推中的应用;并且,通过图解的方式通俗易懂地讲解了FlashAttention种关于MQA/GQA以及Causal Mask的处理。
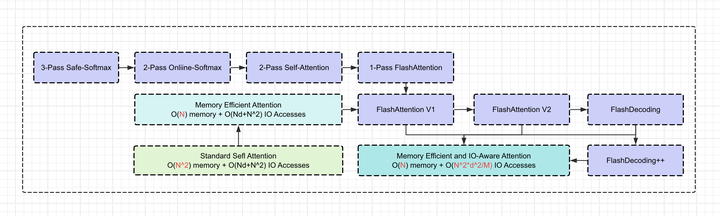
0x00 前言
本文通过原理分析和图解的方式,通俗易懂地FlashAttention系列算法。FlashAttention V1/V2在LLM领域的应用已经非常广泛,相关的论文也反复读了几遍。FA1和FA2论文非常经典,都推荐读一下(不过FA2论文中公式错误不少)。本文大约1.8w字,包括以下内容:
-
0x01 Standard Self-Attention
-
0x02 (Safe) Softmax: 3-pass
-
0x03 Online Softmax: 2-pass
-
0x04 FlashAttention V1
-
0x05 FlashAttention V2
-
0x06 Analysis: IO Complexity of FlashAttention
-
0x07 分布式训推使用FlashAttention
-
0x08 Memory-Efficient Attention
-
0x09 FlashAttention中MQA/GQA以及Causal Mask处理
-
0x0a FlashAttention V3: FlashDecoding以及FlashDecoding++
对于FA入门,非常推荐这篇手稿:
https//courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
本篇文章,主要是记录些FlashAttention论文阅读笔记,温故知新,不追求独特见解。主要参考以下几篇论文,先从Online Softmax的角度来理解FlashAttention,然后再梳理一些可能需要注意的细节。推荐按照以下顺序阅读,每篇认真读完都会有不同的收获~论文链接见文末参考。
-
From Online Softmax to FlashAttention(http://cs.washington.edu)[1]
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness[2]
-
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning[3]
-
The I/O Complexity of Attention, or How Optimal is Flash Attention?[4]
-
A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library[5]
-
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.[6]
FlashAttention1/2相关的论文,还是值得反复读的,虽然FA2论文思路更加直观易懂,但是很多细节的证明,其实都在FA1的论文。比如IO复杂度的计算,忽略了这个细节,可能你就会想不明白为什么FA到现在也不支持大headdim的计算(比如headdim>256时)。因此,FA1的论文,个人也是很推荐细读的。我更倾向把FA1和FA2两篇论文当成完整的一篇论文(况且,FA2中有不少错误公式...,对着FA1论文阅读比较容易避坑)
0x01 Standard Self-Attention
标准的Self-Attention如下 (为了描述方便,省略了Attention Mask和Scale),公式如下。
![]()
其中 都是 Q, K, V, O 矩阵,shape为 (N,d), 为seqlen, 为headdim。由于 MultiHeadAttention各个Head的计算逻辑是一致的。这里也只描述单个Head的情况。把上述公式展开,可以得到一个3-pass的Self-Attention计算步骤。具体如下:

通过 获得每个query相对于所有key的点积,由于 , 都是经过layernorm后的数值,所以直观上,点积越大,某个 行和某个 的列的相关性就大。3-pass的算法中,步骤一和步骤二,会分别产生两个中间矩阵S和 ,内存需求均是 , IO Accesses需求是 [2]。因此,如果采用这种原始的实现,当seqlen也就是N很大时,就会爆显存,同时GPU HBM的访存压力也会急剧变大。

Transformer Multi-Head Attention(from xformers)
Attention是Transformer中的标准组件,常见的包括Multi-Head Attention(MHA)、Mask Multi-Head Attention、Cross Attention、MQA和GQA等等。目前大部分LLM大模型以及Stable Diffusion中的基础模型,都是Transformer-Based,因此也出现很多针对Transformer进行训推性能优化的方法,这其中,优化Attention的计算效率和访存效率,可以说是重中之重。FlashAttention就是这些优化算法中的明珠,也是本人近期最喜欢的算法之一。FlashAttention不需要保留中的S和P矩阵,而是整个Attention计算融合到单个CUDA Kernel中。FlashAttention利用了Tiling(forward)+Recompute(backward)对Attention计算进行融合,特别是对于forward阶段的tiling,可以看做是对online-softmax技术的一种延伸。
我们知道矩阵乘,具有分块和累加的特性,一个大的矩阵乘法,可以通过Tiling技术,分成小块的可以在片上计算的矩阵乘法,然后通过将各个分块矩阵乘的结果进行累加获得最后的正确结果。
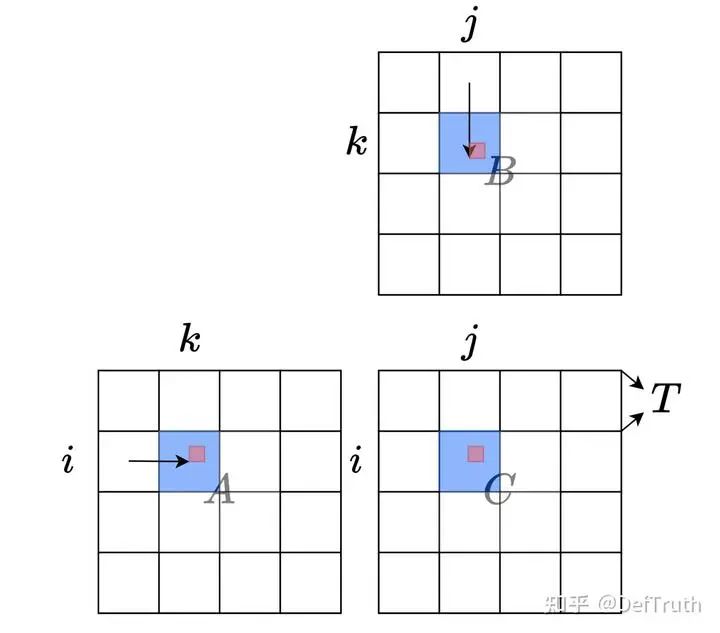
矩阵分块计算
遗憾的是Attention中的Softmax计算,并没有这种累加特性,它依赖于一个全局的分母项。FlashAttention和online softmax想解决的核心问题,正是如何将算法本身从这个全局的依赖中解耦,从而可以使用Tiling进行快速的片上计算。从结果上来看,相对于原始的3-pass算法,online-softmax是2-pass算法,而FlashAttention是1-pass算法。
接下来,本文将从online-softmax开始,逐步讲解FlashAttention算法。再次推荐一下:From Online Softmax to FlashAttention(https//courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf) 这篇手稿,结合FA1/2论文看,相信肯定会让你觉得开卷有益。
0x02 (Safe) Softmax: 3-pass
首先讲safe softmax,它的原理很简单。相对于原生的softmax,它先减去一个max值,以确保计算过程中不会导致数值溢出,比如对于float 16 ,最大值是 65536 ,只要指数项 ,就会发生溢出。原始softmax:
safe-softmaxi十算公式如下,由于 ,因此可以确保softmax计算不会导致溢出。
-
Algorithm 3-pass safe softmax
对于safe-softmax,在工程上,我们可以采用以下算法进行实现[1]。

Algorithm 3-pass safe softmax
这个算法要求我们对[1,N]重复3次。在Transformer的Self-Attention的背景下,x是由Q*K^T计算的pre-softmax logits。这意味着,如果我们没有足够大的SRAM来保存pre-softmax logits(显存需求为O(N^2)),就需要访问Q和K三次,并实时重新计算x,对于访存IO来说,这样是非常低效的。
0x03 Online Softmax: 2-pass
那么我们能不能将上图中的公式 (7),(8) 和 (9) fuse成一个计算呢? 从而可以将对全局内存的访问从3次减少为一次。不幸的是,我们不能对 (7) 和 (8) 公式直接做融合,因为公式 (8) 依赖于 , 这个值必须等 这一次loop跑完才能获得。
那么怎么解决呢? 既然问题是,公式 (8) 依赖于 ,那么有没有办法将这个依赖去掉呢? 这个公式看着像不像数学归纳中常见的范式:当前步的结果依赖于上一步的结果? 如果我们能推导出一个关于 和 的,并且不依赖于 的递归公式,比如:
是不是就可以把 (7) 和 (8) 融合到一个loop里边了呢? 根据手稿From Online Softmax to FlashAttention(https//courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf) 中的说明,这样的方法是存在的。既然 和 之间不存在不依赖 的递归关系,那我们就尝试先绕个弯子,先来研究一下 和 之间是否存在不依赖 的递归关系。构造 定义如下:
具备的一个重要特性是: 对于 ,当 时,恰好有:
现在,我们来推导一下 和 之间递归关系:
非常棒! 我们可以看到 和 之间递归关系只依赖 ,于是我们可以把 和 的计算放到同一个循环中,当这个循环跑到 时,我们得到了 ,也就是得到了 。
-
Algorithm 2-pass online softmax
根据上述的公式推导,在工程上,我们就得到了2-pass的online-softmax算法。

Algorithm 2-pass online softmax
可以看到,在2-pass算法中,公式 (7) 和 (8) 已经被放到了同一个loop循环中。那么,2-pass 算法对比3-pass算法到底有啥优势呢? 好像FLOPs计算量并没有减少,甚至还略有增加,因为现在每次都需要计算额外的scale,也就是 。对于这个细节的理解很重要,所以这里特别写一下。首先,我们要谨记一个基础假设:
值,也就是pre-softmax logits,由于需要O( 的显存无法放在SRAM中。因此:
要么提前计算好 ,保存在全局显存中,需要 的显存,容易爆显存。
要么在算法中online计算,每次循环中去load一部分 , 到片上内存,计算得到 。
Attention优化的目标就是避开第一种情况,尽可能节省显存,否则,LLM根本无法处理类似100K 以上这种long context的情况。而对于第二种情况,我们不需要保存中间矩阵x,节省了显存,但是计算没有节省,并且增加了HBM IO Accesses(需要不断地load , K)。此时,2-pass算法相对于3-pass算法,可以减少一次整体的load Q K以及减少一次对 的online recompute,因为在2-pass的第一个pass中, 是被两次计算共享的。类似online-softmax这种算法,对应到 Attention中的应用,就是Memory Efficient Attention (注意不是FlashAttention)。
0x04 FlashAttention V1
从这一小节开始,我们将进入到FlashAttention部分。接着2-pass online softmax继续思考,既然2-pass都整出来了,那么,我们还能不能整一个1-pass online softmax算法呢?遗憾的是,对于safe softmax并不存在这样的1-pass算法[1]。但是!Attention的目标,并不是求softmax,而是求最终的O:
softmax没有1-pass算法,那么Attention会不会有呢?有!这就是FlashAttention!首先,我们先看一下原始的Multi-pass Self-Attention在工程实现上的算法。
-
Algorithm Multi-pass Self-Attention

Algorithm Multi-pass Self-Attention
我们可以看到,这是一个在2-pass online softmax基础上的2-pass FlashAttention算法,在算法的第一个循环,使用了2-pass online-softmax中推导得到的公式 ,在2-pass FlashAttention中,实际上第一个循环,和2-pass online softmax是完全一致的,只是增加了 的计算。
而在2-pass FlashAttention的第二个循环中,计算了概率值,以及当前迭代步得到的 :
第二个循环中,和2-pass online softmax的区别是多了: 。 OK,这就是Multi-Pass版本FlashAttention,我们可以观察到 这个公式,与 似乎有相同的范式。 计算公式,由于依赖了 ,因此,无法合并到第一个循环中,必须等第一个循环结束后,获得 的值。
进一步,回忆一下2-pass online softmax的推导。那么,有没有可能,像2-pass online softmax 那样,找到 与 的不依赖于 的递归关系?
-
Algorithm 1-pass FlashAttention
从2-pass FlashAttention和online-softmax的推导思路出发,我们来推导1-pass版本的 FlashAttention。首先,定义 为:
具备的一个重要特性是: 对于 ,当 时,恰好有:
现在,我们来推导一下 和 之间递归关系:
可以看到 和 之间递归关系,只依赖 ,不依赖 ,因此,我们和把第二个循环的计算,完全合并到第一个循环中去。从而得到1-pass FlashAttention的算法:

Algorithm 1-pass FlashAttention
进一步,如果我们对矩阵Q, K进行Tiling,就可以得到分块Tiling版本的FlashAttention。

FlashAttention Tiling

FlashAttention Tiling
这个Tiling中,将K矩阵分成了多个块(实际上Q也可以这样分块),切分后的小块可以load到 SRAM中,然后计算 ,接着进行剩余的计算。从算法逻辑上看,现在只需load 一次,就能把Attention计算在kernel中全部完成。由3-pass的原始Self Attention,到1-pass 的 FlashAttention,节省了S和P矩阵的显存,并且减少了Q, K的HBM IO Accesses。
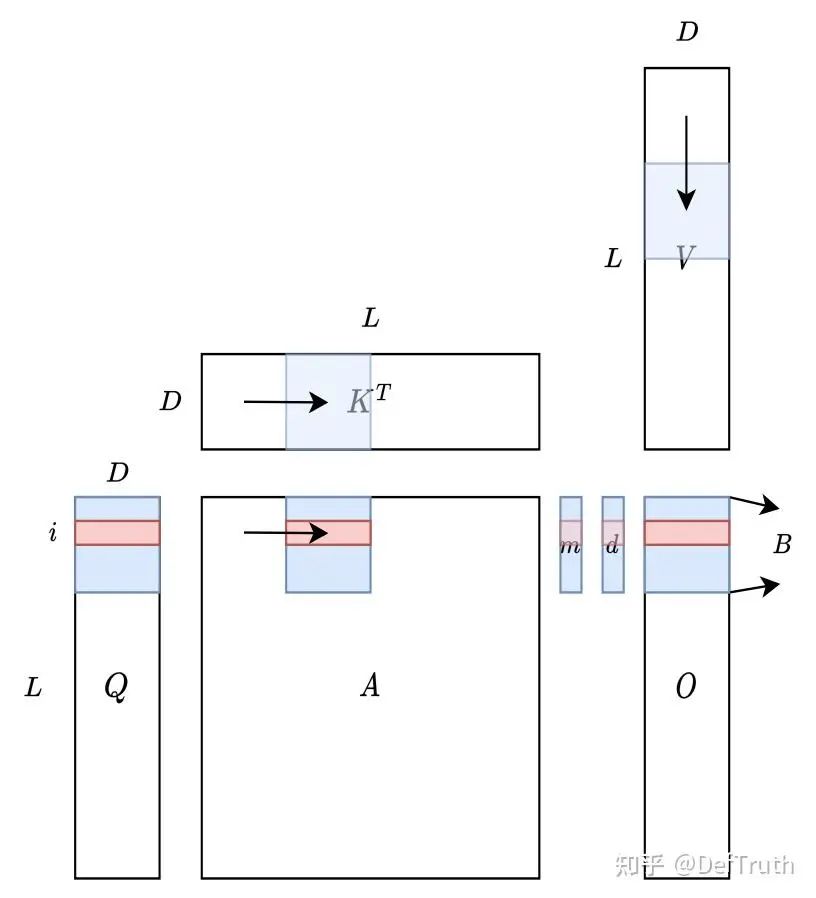
FlashAttention Tiling
以上1-pass FlashAttention的算法逻辑,来自于From Online Softmax to FlashAttention(https//courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf)[1]。在本章节最后,我们再来看看FA1论文中给出的算法伪代码。
-
FlashAttention-1 forward pass

Algorithm 1 FlashAttention forward pass
其中公式 ,实际上就是:
我们来看下FlashAttention论文中完整的公式和推导,只要理解了上述手稿From Online Softmax to FlashAttention 中的证明逻辑,FlashAttention-1论文中的证明就很好理解。对于前向 forward pass,FlashAttention采用的是和online-softmax类似的Tiling技巧。首先,将Q,K,V进行分块,然后把各个小的分块从性能低的全局显存,load到速度快的SRAM,在SRAM上完成当前 block Attention的计算,最后再写入HBM,整个过程,不需要保存中间矩阵 和P。这里贴一下论文 中的证明,不再重复阐述里边的原理。 (1)首先,对于向量 , softmax常规的计算是这样的:
(2)按照online-softmax的计算技巧,对于 ,我们可以将其先分解成两个向量:
(3)然后,按照online-softmax分块的逻辑,可以得到以下和 (1) 等价的计算方式:
(4)在 (3) online-softmax的基础上,将对输出值O的计算考虑进来,就是:
(5)具体证明如下,证明过程来自于论文 附录部分,看着很复杂,其实和前边说到1-pass FlashAttention的证明是一个事情。两种证明,只要理解其中一种就可以了。令:
(6) 对于 次迭代,我们首先会更新 ,其中 表示的是 矩阵的从 列到 列的切片。这意味着:
(7) 同样的,易得: ,其中 。于是,可以推导出:
(8) 进一步,我们令 表示 矩阵的从 列到 列的切片,则有:
可以看到,最终可以证明 ,于是,当迭代到最后一步,就可以得到最终的正确值: 。
-
Effect of Block Size
需要注意的是,FlashAttention的算法中有个Block Size的概念,也就是 和 :
这样设置的目的是,为了确保SRAM能够放下所有 , 的小块,其中 就是系统可用的SRAM 上限。那么,对于每一个 的分块 以及 的分块 需要的共享内存为:
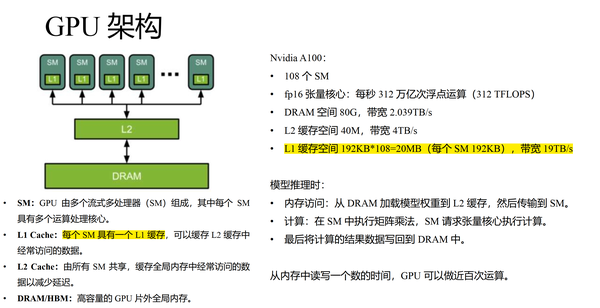
再加上 所额外需要占用的存储,基本上就是把能用的SRAM给打满了。当然,这这是算法伪代码上的分析结论。具体工程上的实现还是会有细微的差别,但总体的思路基本一致。这里再补充一些关于SRAM的认知,比如A100,我们常说,他的L1 Cache(SRAM)是192KB,这个值的颗粒度是SM,也就是每个SM都有 的SRAM,而A100有 108 个SM,因此,A100单卡上总共有20MB的SRAM。但是由于每个thread block只能被调度到一个SM上执行,SM之间的SRAM是不共享的。因此,实际算法设计时,考虑的是thread block的编程模型,要按照192KB去计算 SRAM上能放的数据量。
再贴一下算法中 Block Size设置的一些影响,更多细节推荐阅读FA1原始论文。我们可以看到 Block Size 越大,HBM Accesses 越低,在256附近基本就是效率最优的转折点。
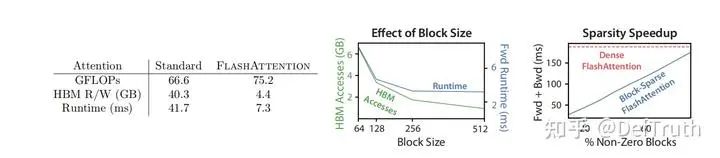
Effect of Block Size
-
Block-Sparse FlashAttention forward pass

Block-Sparse FlashAttention forward pass
简单讲下。Block-Sparse FlashAttention是对FlashAttention的稀疏化扩展,需要先假定存在一个butterfly形式的Attention稀疏化矩阵 表示是被稀疏的部分,在计算Attention 时,直接跳过该block的计算。
-
FlashAttention-1 backward pass

FlashAttention-1 backward pass
FlashAttention backward pass最主要的优化就是:Recompute。对比Standard Self Attention,FlashAttention在前向不需要保留S和P矩阵,但是backward pass又需要S和P矩阵的值来计算梯度。那么怎么办呢?那自然就是就是和forward一样,利用Tiling技术,将Q,K,V分块load到SRAM,然后通过online recompute计算得到当前块的S和P值。具体到backward pass中计算逻辑就是:

Backward pass Recompute
那么,这样做带来的优化是什么呢?首先,针对Q,K,V矩阵,无论是否有recompute,都是必须要load到SRAM进行计算的,因为计算梯度需要。那么,没有recompute时,P矩阵是事先算好保存在HBM中的,此时在backward时,需要load Q,K,V,dO,dS + load P,dP + write dS,dP,dQ,dV,dK。

Standard Attention Backward Pass
在使用了recompute+tiling后,则只需要load Q,K,V,dO + write dQ,dV,dK,这个公式可能没有算的很精确,但总的意思就是关于S,P,dS,dP的load/write IO被消除了。虽然recompute增加了计算量FLOPs,但是IO的减少带来的收益更大。按照NV PTX ISA 8.1 6.6章节-Operand Costs 中的文档说明,GPU HBM IO Accesses通常耗时>100 时钟周期,而计算指令一般只需要几个时钟周期。
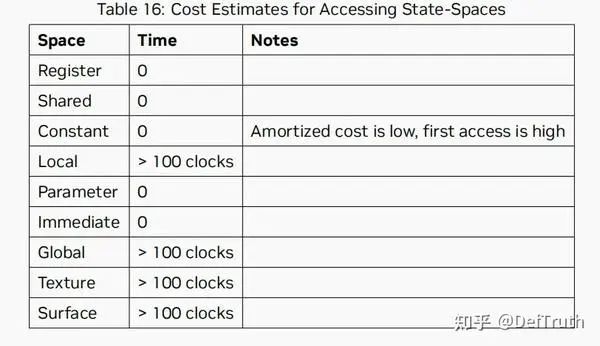
NV PTX ISA 8.1 6.6-Operand Costs
0x05 FlashAttention V2
现在广泛应用的主要是FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning[3],FlashAttention-2对比FlashAttention-1,主要是做了一些工程上的优化,关于Tiling和Recompute的核心思路,和FlashAttention-1是一致的。似乎也没看到FA2的论文投到顶会,只是挂了arxiv(吐槽...而且真的有些错误的公式后来似乎就一直没修...)接下来,我们就继续看下FlashAttention-2都做了哪些优化。优化点主要包括以下几点:
1. 减少大量非matmul的冗余计算,增加Tensor Cores运算比例
2. forward pass/backward pass均增加seqlen维度的并行,forward pass交替Q,K,V循环顺序
3. 更好的Warp Partitioning策略,避免Split-K(感觉这部分是为了故事完整加上的...)
-
减少非matmul的冗余计算,增加Tensor Cores运算比例
首先,为什么要减少非matmul计算?虽然一般来说,非matmul运算FLOPs要比matmul底,但是非matmul计算使用的是CUDA Cores,而矩阵计算可以利用Tensor Cores加速。基于Tensor Cores的matmul运算吞吐是不使用Tensor Cores的非matmul运算吞吐的16x[3]。接下来,我们来详细看下冗余计算是怎么被减少的。以forward pass为例,FA2中将其修改为:
对比FA1,主要的区别在于计算 的逻辑,FA2中为:
而在FA1中, O的计算逻辑为:
FA2的计算中,先不在每个block的每次迭代计算中执行全部的rescale操作,而是最后执行一次 rescale。每次计算可以减少一次除法运算。可以这样做的原因是,只要每次迭代,确保分子部分 被scale为正确值以及分母部分 计算正确即可。对于backward pass,不再分别保存 和 序列,而是保存
这样之后,backward pass中 的计算量就可以减少:
-
增加seqlen维度的并行
回忆一下FA1中的forward pass算法,我们就会发现一个诡异的事情。就是,FA1的两重循环中,是先外层循环load K, V,然后内层循环再load Q。这就会导致内层循环,每次计算的只是Qi的一部分,每次内循环的迭代都需要对Oi进行全局内存的读写。而且,一个显而易见的事实就是,在Attention的计算中,不同query的Attention计算是完全独立的。也就是说,如果外部循环是先load Q,那么就可以把不同的query块的Attention分配不同thread block进行计算,这些thread block之间是不需要通信的。没错,在FA2中,正是这样做的,对于forward pass,算法调换了循环的顺序,先load Q,再load K, V。

FlashAttention-2 forward pass
调整循环顺序后,对比FA1,内循环不需要每次reads/writes 到HBM,从而减少了IOAccesses,耗时也会随之减少。在行seqlen方向做并行,无论是FA1还是FA2其实都可以做,只是 FA1没有这样处理而已。FA1只在batch_size和headnum做并行,但seqlen比较长,bs比较小时,FA1的效率就大幅下降。于是,FA2增加seqlen并行,提高了occupancy,并且对于forward pass, 在【行】方向的seqlen上天然可以并行, thread block之间不需要额外的通信。
对于backward pass,FA2也增加了seqlen维度的并行。但与forward pass不同的是,并没有改变循环的顺序,backward pass依然是外层循环先load K,V, 内层循环再load Q。这里,backward pass采用的是【列】方向seqlen维度的并行策略。

FlashAttention-2 Backward Pass
forward pass和backward pass在seqlen并行方向上的区别如下:
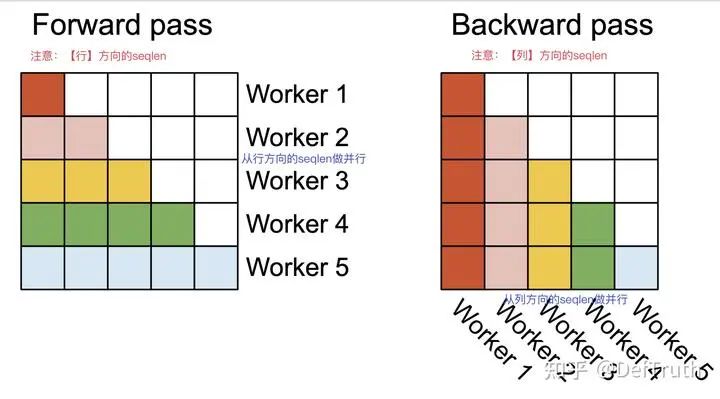
Fwd 行方向seqlen并行 vs Bwd 列方向seqlen并行
说实话,一开始我也没看懂为什么backward pass不改变循环的顺序,为此,我还跑到FlashAttenion的官方repo提了issue来咨询了FA的作者大佬,非常感谢大佬的热情回复,issue具体见:
https//github.com/Dao-AILab/flash-attention/issues/815
为什么不调换顺序?调换循环顺序后,会导致需要通信的操作增加:1 -> 2。原先只有dQi需要通信,如果调换循环顺序,会导致dV,dK需要通信。因此,采用先K,V再Q的顺序,会稍微更快一些。
For bwd you either need to do atomic adds on dQ, or atomic adds on dK and dV. The current loop order means we're using atomic adds on dQ, and that's a little bit faster than the other way.
-
更好的Warp Partitioning策略,避免Split-K
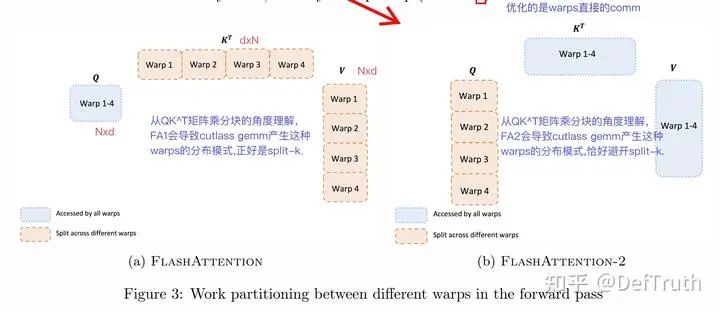
这部分还没有完全理解...,我暂且理解成,从QK^T矩阵乘分块的角度看,FA1会导致cutlass gemm产生这种warps中数据的分布模式,正好是split-k,而FA2会导致cutlass gemm产生warps中数据的分布模式,则恰好避开了split-k。具体和cutlass底层源码实现逻辑以及Tensor Cores相关。关于Warp Level的并行,推荐看:Antinomi:FlashAttention核心逻辑以及V1 V2差异总结(https://zhuanlan.zhihu.com/p/665170554),写得实在太好了。以下这段分析来自Antinomi:FlashAttention核心逻辑以及V1 V2差异总结(https://zhuanlan.zhihu.com/p/665170554)(侵删)
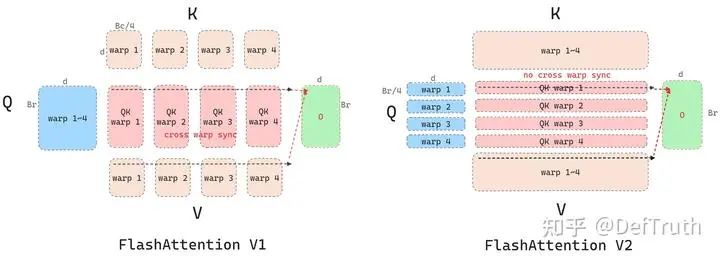
图片来自 @Antinomi (侵删)
“首先看fwd,相比V1,V2改进了Warp Partition:4个warp会从smem的K/V tile load同样的数据做mma计算,但是load 不同Q,把V1 sliced-K sliced-V 改成了v2 sliced-Q,V1的做法是需要warp之间产生同步通信的,因为在计算QK结果乘V的时候,如图所示需要跨warp reduction得到O的结果,而且fwd的目的是沿着行方向计算softmax,行方向信息最后要汇总的,这也需要跨warp不同。V2就不需要了,这样可以减少同步开销。”
基于以上对FlashAttention V2的分析,我们可以大致画出它的分块Tiling逻辑。以batch=8,heads=8,每个分块大小为BLOCK_MxBLOCK_N=128x128为例。FlashAttention V2的分块策略如下,其中标记为skip的部分,指的是可以执行Early Exit策略的块,这些块的计算可以直接跳过(请看后续的章节分析)。
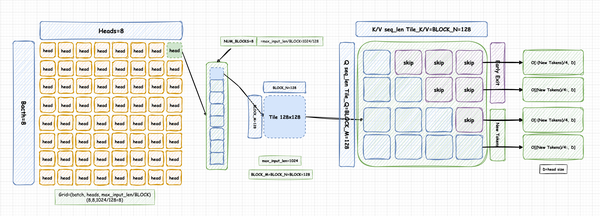
FlashAttention V2 Tiling
0x06 Analysis: IO Complexity of FlashAttention
这一章节放到较为靠后,是因为IO复杂度的分析,对于FA1和FA2都是相同的,因此可以放到这里统一讲。FlashAttention的IO复杂度分析,是目前大部分博客中容易忽略的。但是,这部分内容,其实也是挺重要的,因为他可以帮助我们理清楚,到底在什么时候使用FlashAttention是有收益的?想写这一小节的原因,在于先前有尝试对TensorRT MHA/Myelin和FlashAttention-2的性能进行对比分析,具体见我的另一篇文章:
(https://zhuanlan.zhihu.com/p/678873216)
在这次的对比的分析中,发现FlashAttention具有的一些局限性,比如:
1. FlashAttention/MHA目前不支持超过256的headdim,d>256时,无法使用FA/MHA加速
2. headdim>128时,MHA和FlashAttention各有优劣,FA不一定是最优的
本文不关注问题2,这大概是由于TensorRT MHA内部的实现与FA的实现差异导致的。对于问题1,不禁让人好奇,为什么呢?让我们回到本文开篇的提到的小问题,为什么“FA到现在也不支持大headdim的计算(比如headdim>256时)”。这就需要结合FlashAttention的IO复杂度分析来理解。关于这个问题,我也提了个issue咨询了FA2的作者大佬,详见:
https//github.com/Dao-AILab/flash-attention/issues/801
意思就是当headnum=1, headdim>256时,可能使用原生的Attention会比FlashAttention更快。
with numhead = 1 and large headdim
i think it's faster to compute attention naively rather than using flash-attn.
首先回顾一下FA的算法流程以及Block Size的影响:
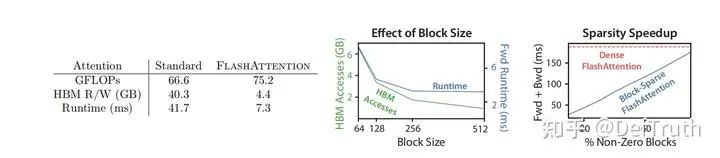
Effect of Block Size
其中Block Size也就是 和 的计算公式为:
这样设置的目的是,为了确保 能够放下所有 , V的小块,其中 就是系统可用的SRAM 上限。那么,对于每一个 的分块 以及 的分块 需要的共享内存为:
再加上 所额外需要占用的存储,基本上就是把能用的SRAM给打满了。根据论文中的算法 (FA1+FA2), headdim=d越大时,意味着 和 会越小,也就是Block Size会越小。 Block Size越小,Runtime耗时会越大,这是由于每个thread block的SRAM能放的数据是有限的,这限制了系统中活跃的SM上限。d越大,意味着,对于相同的seqlen,需要遍历更多的次数,也就是更多的thread block。在相同的occupancy下,需要schedule更多次才能将计算算完,耗时就变高了。并且,由于 变小,意味着外层 循环的次数变多了,对于每一次 的循环,都要分块加载全部的K、V到SRAM,也就是说,Memory Accesses也会增加,这也会导致耗时的增加,同时也远离了FA2优化Memory Accesses的目标。我们可以看到论文中给的FA需要的 Memory Accesses计算公式:

FlashAttention IO Complexity
Memory Accesses和d的平方成正比关系,当d越大,FA的Memory Accesses会增长剧烈。比如对于N=2K, M=192KB, 当d=256时,依然满足 FA IO Acesses < Naive Attention,但是当d=512时,这个结论就会反过来,变成是 FA IO Acesses > Naive Attention IO Acesses,并且由于FA本身的FLOPS就是比Naive Attention高的,于是,此时无论是IO还是FLOPS,FA都会比Naive Attention高,无论是访存还是计算量都没有优势,唯一剩下的优势,应该就只剩节省显存了(不需要保存中间的S和P矩阵,O(N^2)的内存复杂度)
- # N=2048, d=256, M=192KB(A100) FA IO Acesses < Naive Attention IO Acesses
- >>> 2048*256 + 2048*2048 # Naive Attention
- 4718592
- >>> 2048*2048*256*256/(192*1024) # FA
- 1398101.3333333333
- # N=2048, d=512, M=192KB(A100) FA IO Acesses > Naive Attention IO Acesses
- >>> 2048*512 + 2048*2048 # Naive Attention
- 5242880
- >>> 2048*2048*512*512/(192*1024) # FA
- 5592405.333333333
关于IO复杂度的分析, FA1 论文中还有更多的结论,这里就不一一展开了,推荐直接看论文。另外,最近还翻到一篇挂在arxiv上,专门分析FlashAttention IO复杂度的论文:The I/O Complexity of Attention, or How Optimal is FlashAttention? ,论文从 $d^2<m$ 和="" $d^2="" \geq="" m$="" 的角度对flashattention="" io复杂度和标准attention的।o复杂度进行了详细的分析。先不展开了,有机会再补充...<="" p="">
0x07 分布式训推使用FlashAttention
首先,FlashAttention的官方repo,目前并没有实现多卡版本的FlashAttention,翻了下代码,确实没有看到类似nccl相关的分布式通信代码。FlashAttention本身就极大节省了显存,只需要O(N)的显存,因此可以支持超长seqlen的Attention操作,对于80G的显存,大约支持80 * (1024 ** 3) / (1024*2)~4.19千万K=O(千万K)级别的seqlen(注意是,千万【K】,half=2byte),从目前Long LLM的发展来看,还远远没到能让FlashAttention爆显存的程度,因此也就没必要去搞个多卡版本的FlashAttention了。此时,反而是Q, K, V, O, word embedding, lm_head和KV Cache占用的显存会成为明显的瓶颈。
-
Megatron-LM Self Attention Tensor Parallel[6]
Megatron-LM Self Attention Tensor Parallel
每张卡包含一个head,每个head各自计算自己的Attention,不同卡上的Attention是完全独立的。因此一个比较自然的想法就是,使用FlashAttention替换掉原先的单卡上的Attention部分即可。以下是Megatron-LM中关于ParallelAttention的部分源代码。
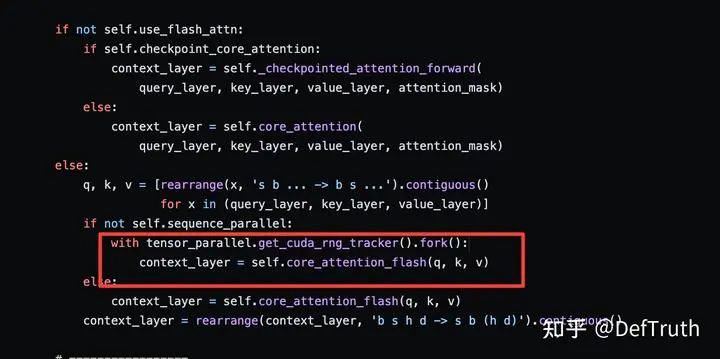
FlashAttention in Megatron-LM ParallelAttention
分布式训练这部分不是我目前擅长的,如果理解有误,欢迎指正哈~
0x08 Memory-Efficient Attention
-
Memory-efficient forward pass
在FlashAttention出现之前,已经有Memory-Efficient Attention,这里也简单提一下Memory-Efficient Attention相关的内容。xformers中已经集成了memory_efficient_attention。以下是Memory-Efficient Attention forward pass的算法流程。

Memory-efficient forward pass
Memory-Efficient Attention的做法是先提前计算好 ,每计算一个 只需要加载对应的 和 ,计算后只保存 ,不保存中间结果 ,这样就可以节省矩阵 和 的显存,而保存 序列,只需要 显存。对于 的计算也是如此,等所有的 计算完成后,再次加载 和 , online计算softmax值,得到最终结果:
-
Memory-efficient backward pass
Memory-efficient backward pass的计算流程相对复杂些,因为涉及到反向梯度的计算。但是节省显存的原理和Memory-efficient forward pass是一样的。比如,对于求和项 ,先提前计算;对于概率项 ,每次加载 和 , online计算softmax值,不保存中间结果。这样在求 的时候,就可以节省大量显存。

Memory-efficient backward pass part1

Memory-efficient backward pass part2
同样的计算技巧,可以应用到 的计算上。从上边的算法公式看,由于概率项 是可以 online计算的,而 是事先已知的 (算法的输入),所以 是可以online计算的。 依赖于 ,而 是已知的,并且 是可以online的,因此, 也是可以online计算的。整体的计算流程如下:

Memory-efficient backward pass part3
对比FlashAttention,Memory-Efficient Attention 同样可以节省显存,但是HBM IO-Accesses没有下降,依然为quadratic O(N^2)。更多细节请参考:Self-attention Does Not Need O(n^2) Memory[7]
0x09 FlashAttention中MQA/GQA以及Causal Mask处理
补档内容:关于FlashAttention,还有几个细节处理相关的内容需要补充,放在这个章节单独说明。
-
MHA/MQA/GQA Attention
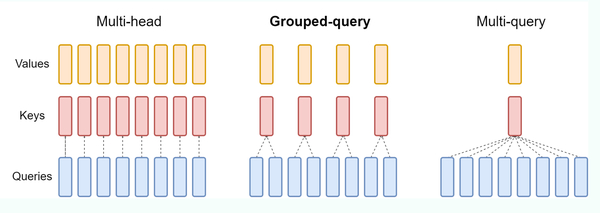
MHA/GQA/MQA
首先简单介绍一下MQA和GQA。标准的多头注意力就是MHA(Multi Head Attention),在MHA中,KV Heads的数量和Query Heads的数量相同,每个Query Head持有一个独立的KV Head,在Attention中,对单独的KV Head做计算。但是,当模型层数加深和Heads数变多后,QKV Attention的计算和IO都会快速增加。为了缓解这种情况,有学者提出了MQA和GQA。
MQA (Multi Queries Attention): MQA比较极端,只保留一个KV Head,多个Query Heads共享相同的KV Head。这相当于不同Head的Attention差异,全部都放在了Query上,需要模型仅从不同的Query Heads上就能够关注到输入hidden states不同方面的信息。这样做的好处是,极大地降低了KV Cache的需求,但是会导致模型效果有所下降。
GQA (Group Queries Attention): GQA与MQA不同,而是采取了折中的做法。GQA把Query Heads进行分组,每组Query Heads对应一个KV Head。比如,把8个Query Heads分成4组,每个Grouped Query Head包含2个Query Heads,一个Grouped Query Head对应一个KV Head,此时总共有4个KV Heads。GQA可以在减少计算量和KV Cache同时确保模型效果不受到大的影响。
在FlashAttention中,也支持MQA和GQA。对于MQA和GQA的情形,FlashAttention采用Indexing的方式,而不是直接复制多份KV Head的内容到显存然后再进行计算。Indexing,即通过传入KV/KV Head索引到Kernel中,然后计算内存地址,直接从内存中读取KV。

-
Causal Mask处理
Causal Mask的概念不多做介绍,想必各位LLMer很熟悉了。FlashAttention中,由于已经按照block的方式在kernel进行计算了,所以存在计算过程Early Exit的可能。也就是,存在mask全为0的block以及索引满足某些条件的block,可以不需要计算直接返回。

Early Exit的优化,这样说明不是很直观,我们可以通过图解来说明下。以FlashAttention2 forward pass为例,假设seq_len_q=seq_len_k=9,causal mask则是下图所示的一个下9x9三角形。FA2会对Q在seqlen维度做行方向的并行,也就是按照Q,将Attention计算切分到不同的Thread block计算,比如按照tile_q=3,则会将3个queries的Attention计算放到一个Thread block。并且Thread block内,会按照tile_k=3,将K再切分成小块load到SRAM中,再共享给后续的计算。也就是每个Thread block内对KV的循环是一次K上micro block的过程,每次迭代,对应的是一个3x3的micro block,causal mask也自然是切分成3x3的micro block。
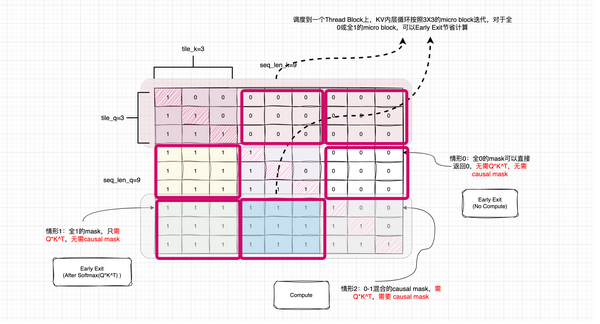
那么在micro block这个粒度,就存在计算Early Exit的优化空间。具体可以分为以下3种情况:
情况0: 全Early Exit。全0的mask可以直接返回0,无需QxK^T,无需causal mask。
情况1: 部分Early Exit。全1的mask,只需Softmax(QxK^T),无需causal mask。
_情况3: 无法Early Exit。0-1混合的causal mask,需QxK^T,需要causal mask,然后Softmax(Mask(Qx_K^T))。
因此,对于情况0和情况1,FlashAttention2可以节省大量的计算。另外,对于seqlen_q不等于seqlen_k的情况,v2.1之后的FlashAttention的实现中有个Causal Mask右对齐的概念需要注意:
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero
这样不好理解,但是画个图来看看就很清晰了(应该不需要我再写文字来说明了吧...偷懒):
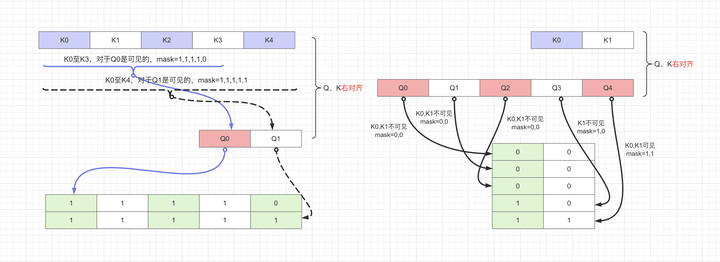
FlashAttention Causal Mask右对齐约定
0x0a FlashAttention V3: FlashDecoding以及FlashDecoding++
考虑到篇幅问题,内容过长反而不利于阅读和吸收,并且FlashDecoding/FlashDecoding++优化的重点已经是集中在Decoding部分,因此,单独摘出来写一篇Decoding优化的内容。感兴趣的,请阅读:
https://zhuanlan.zhihu.com/p/696075602
0x0b 总结
本文首先从Online-Softmax的角度切入,由浅入深地讲解了3-pass Safe-Softmax、2-pass Online-Softmax以及1-pass FlashAttention的原理;然后,进一步详细讲解了FlashAttention-1和FlashAttention-2算法中各自的优化点、FlashAttention IO复杂度分析以及适用场景、FlashAttention在分布式训推中的应用;并且,通过图解的方式通俗易懂地讲解了FlashAttention种关于MQA/GQA以及Causal Mask的处理。最后,还梳理了Memory-Efficient Attention的基本算法原理。老样子,错误先更后改,欢迎指正...
参考
1.From Online Softmax to FlashAttention. (https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf)
2.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. (https://arxiv.org/pdf/2205.14135.pdf)
3.FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. (https://arxiv.org/pdf/2307.08691.pdf)
4.The I/O Complexity of Attention, or How Optimal is Flash Attention? (https://arxiv.org/pdf/2402.07443.pdf)
5.A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library. (https://research.colfax-intl.com/wp-content/uploads/2023/12/colfax-flashattention.pdf)
6.Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. (https://arxiv.org/pdf/1909.08053.pdf)
7.Self-attention Does Not Need O(n^2) Memory (https://arxiv.org/abs/2112.05682)

