
- 1Hive初始化报错:org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
- 2【HIVE数据倾斜常见解决办法】_hive数据倾斜解决办法
- 3Linux上的Redis客户端软件G-dis3_g-dis3 使用
- 4(1)监听QQ消息自动回复-QQ自动化(.Net)_uianimations监控qq
- 5【附源码】基于flask框架基于微信小程序点餐系统的设计与实现 (python+mysql+论文)_基于微信小程序的点餐小程序的设计与实现
- 6【MongoDB】万字长文,命令与代码一一对应SpringBoot整合MongoDB之MongoTemplate
- 73种策略让微服务测试的ROI最大化_实现roi最大
- 8自动化脚本如何有效防检测、防风控?_脚本防止无障碍检测
- 9《Unity3D高级编程之进阶主程》第三章 数据表(二) - 数据表的制作方式
- 10Hadoop学习笔记(1)——单机版搭建_hadoop2.8单机部署
论文笔记:NAFNet: Simple Baselines for Image Restoration
赞
踩
向孙老师致敬!
相关工作
图像恢复模型体系结构比较

方法
块内(Intra-block)结构比较:
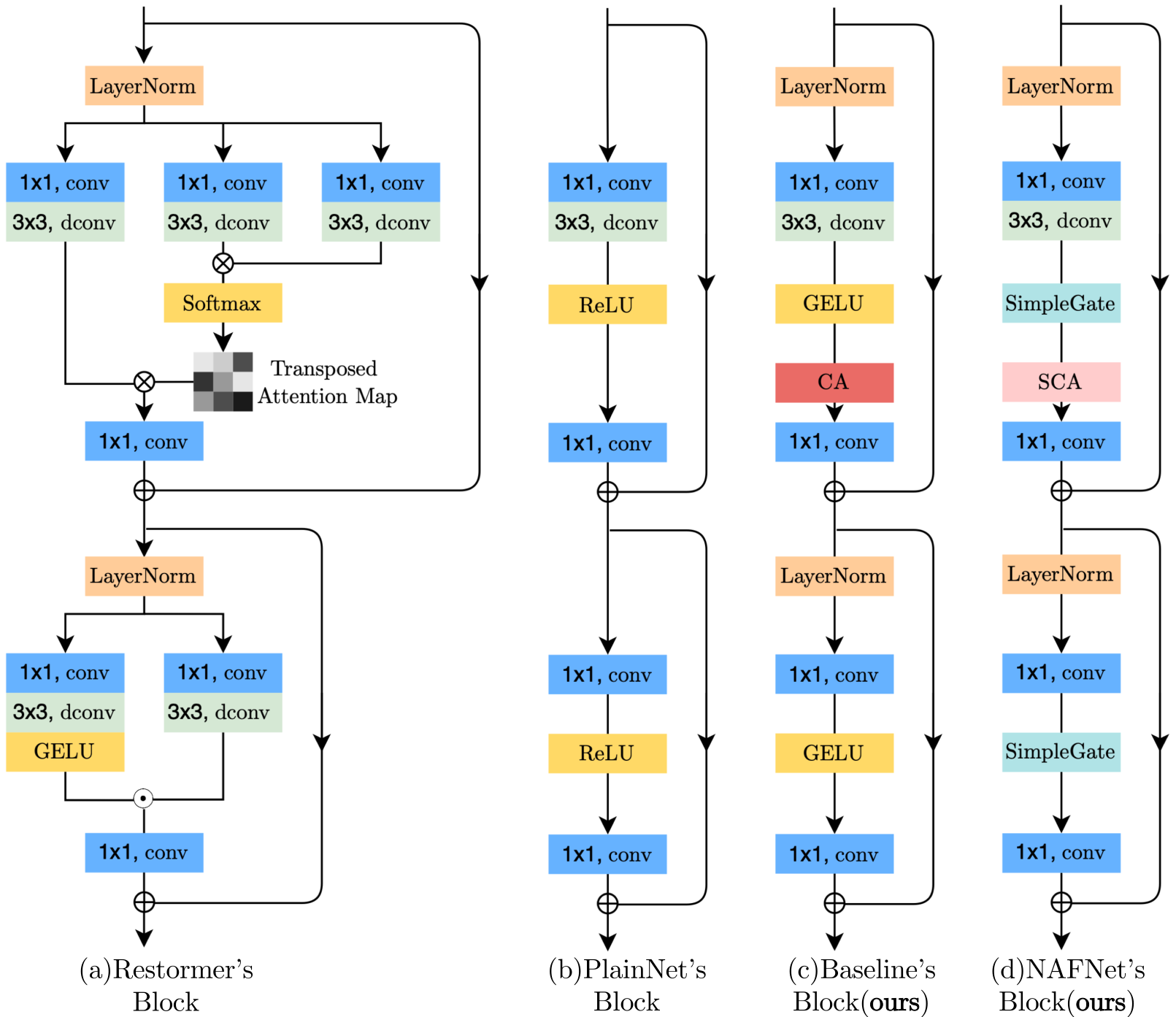
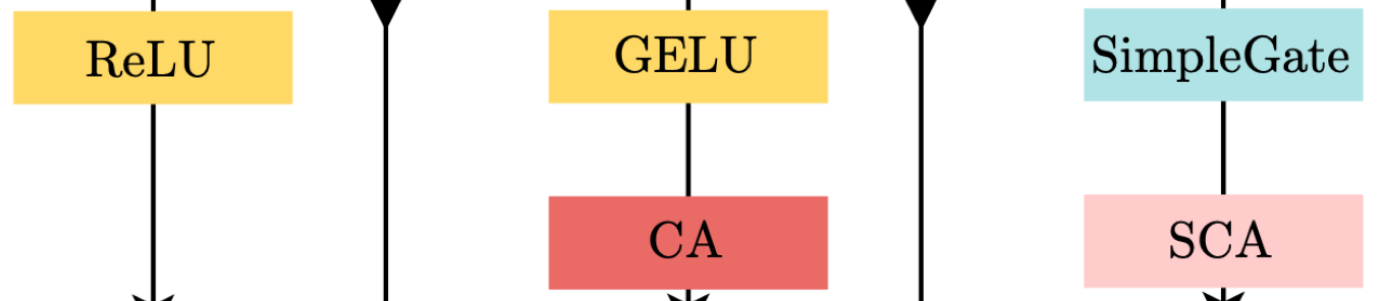
其中Channel Attention (CA),Simplified Channel Attention(SCA),从左到右依次替换
归一化:将层归一化(Layer Normalization)添加到普通块中,因为它可以稳定训练过程。
激活函数:在plain块中用GELU替换ReLU,因为它在保持图像去噪性能的同时,为图像去模糊带来了非平凡的收益。
注意力:通道注意力

Nonlinear Activation Free Network
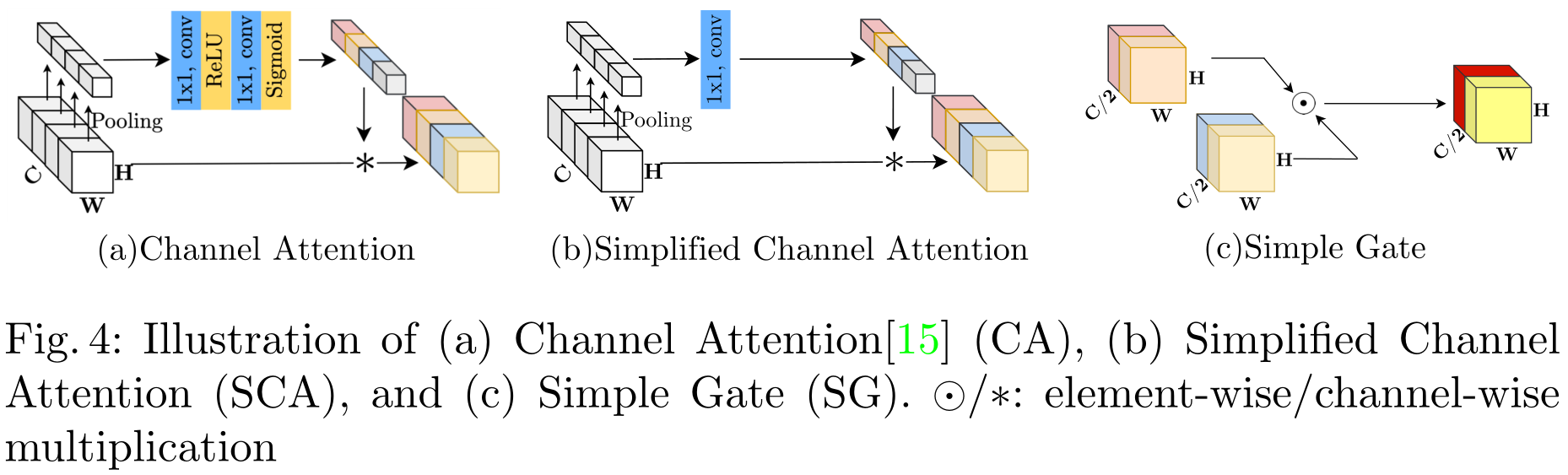
Gated Linear Units:
Gate
(
X
,
f
,
g
,
σ
)
=
f
(
X
)
⊙
σ
(
g
(
X
)
)
\operatorname{Gate}(\mathbf{X}, f, g, \sigma)=f(\mathbf{X}) \odot \sigma(g(\mathbf{X}))
Gate(X,f,g,σ)=f(X)⊙σ(g(X))
GELU: G E L U ( x ) = x Φ ( x ) G E L U(x)=x \Phi(x) GELU(x)=xΦ(x),其中 Φ Φ Φ表示标准正态分布的累积分布函数。GELU可以通过以下方式进行近似和实现 0.5 x ( 1 + tanh [ 2 / π ( x + 0.044715 x 3 ) ] ) 0.5 x\left(1+\tanh \left[\sqrt{2 / \pi}\left(x+0.044715 x^{3}\right)\right]\right) 0.5x(1+tanh[2/π (x+0.044715x3)])
我们提出了一个简单的GLU变体:直接将特征映射划分为通道维度的两部分,并将它们相乘 SimpleGate ( X , Y ) = X ⊙ Y \text { SimpleGate }(\mathbf{X}, \mathbf{Y})=\mathbf{X} \odot \mathbf{Y} SimpleGate (X,Y)=X⊙Y其中,X和Y是大小相同的特征映射。
Simplified Channel Attention:使用的是SENet C A ( X ) = X ∗ σ ( W 2 max ( 0 , W 1 pool ( X ) ) ) C A(\mathbf{X})=\mathbf{X} * \sigma\left(W_{2} \max \left(0, W_{1} \operatorname{pool}(\mathbf{X})\right)\right) CA(X)=X∗σ(W2max(0,W1pool(X)))
其中X表示特征映射,pool表示将空间信息聚合到通道中的全局平均池化操作。 σ σ σ是一个非线性激活函数Sigmoid, W 1 W_1 W1、 W 2 W_2 W2是全连接层,两个全连接层之间采用ReLU,最后的 ∗ ∗ ∗是一种通道乘积运算(channelwise product operation)。简化的CA: S C A ( X ) = X ∗ W pool ( X ) S C A(\mathbf{X})=\mathbf{X} * W \operatorname{pool}(\mathbf{X}) SCA(X)=X∗Wpool(X)
本质上删除了激活函数。
实验

代码
github.com/megvii-research/NAFNet

