
- 1Xilinx 7系列FPGA收发器架构之发送器(TX)(九)_txpostcursor
- 2应届生拿到offer之后的流程_毁约offer,我付了8000元违约金......
- 3mvn install本地jar到仓库_mvn install 本地jar
- 4解决Cipher Suites导致的“未能创建 SSL/TLS 安全通道”异常问题_tls encrypted alert
- 5数据结构(Data Structure)——线性表ADT(C/C++语言)_返回l中第1个与e满足关系compore()的数据元素的位序。 若这样的数据元素不存
- 6【项目日记(一)】搜索引擎-索引解析
- 7B站大课堂-自动化精品视频(个人存档)
- 8【好物推荐】Redis Desktop Manager使用介绍_redis-desktop-manager是什么?
- 9一文搞懂 Transformer(总体架构 & 三种注意力层)_注意力机制包含transform架构吗
- 10为什么要使用 git pull --rebase_git pull --rebase的作用
PaddleSeg训练推理及模型转换全流程_paddleseg onnx推理
赞
踩
本文记录一下使用paddleseg进行语议分割模型对人体进行分割的使用流程。事实上,做算法是脱离框架的,用啥实现都何以,但到2024了,一个点是如果有预训练模型,那就用起来;另一个是放下内心对于不同框架的喜好,结束束battle,什么 tensorflow,pytorch,paddlepaddle,keras,jax。。。,重心集中到算法和自己的需求上。需求无非是两个,一个是研究,就是researcher,需要发文章,那就看文章用什么做的,我们就跟着用什么,不会的api现场查,用chatgpt生成都可以;框架同质化的今天,真是一通百通,做到能查能用即可,道理都一样; 另一个点就是落地,engineer,最后肯定是用onnx,tensorrt,openvino…布署到相应的硬件上,更多的是拿来主义,跑通,在自己特定的场景上生效就可以。在跑通过程中,可以适当对原理进行探纠。整个过程可以先看看https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.9/docs/whole_process_cn.md
本文主打一个细致,快速训练模型,时间长了也怕忘记,感觉有帮助的话请点个赞。
1、数据准备
1.1 数据标注
用标注神器x-anylabeling,就是咱国产的,功能强大特别好用。labelimg,labelme都用过,相比差多了。如图:

那说一下它的好处,就是可以用官方的训练好的模型来直接跑图,不用人标,只要后期调一下错的就行。我用的是 combining GroundingDINO with HQ-SAM to achieve sota zero-shot high-quality predictions,就是dino检测+sam分割,效果比人标的好。也可以用自己训练好的yolov8-seg模型来做为预训练模型去自动标注数据。
对标注的理解,也可以参考contrib/PaddleLabel/doc/CN/project/semantic_segmentation.md:
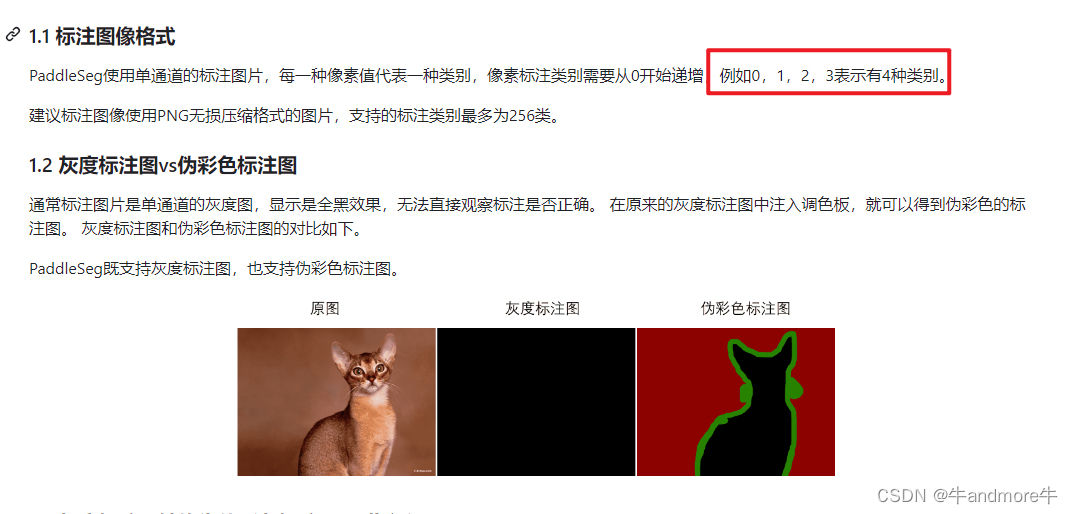
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.9/docs/data/marker/marker_cn.md 这个也要看。
就是说paddleseg是要用灰度标注的,但是支持伪彩色标注的。
1.2 数据导出
关于数据导出,就参考https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/user_guide.md。这里吧。
paddleseg支持的标签是uint8,8bit 灰度图,0默认是表示 background,255表示无作用(应该是为了方便可视化,图像加pad这类操作,不参加loss计算)。1-254 共254个类是我们可以用的(现在不知道超过这个范围怎么办)。

导出后的图保存在与图片同路径下的mask文件夹下,肉眼看不了,就是全黑。
1.3 标签较验
导出的标签要通过可视化来看是否标注正确。
tools/data 下边有两个一个是gray2pseudo_color.py,另一个是visualize_annotation.py。前一个是转成伪彩色来看,后一个相对麻烦,后边再说。
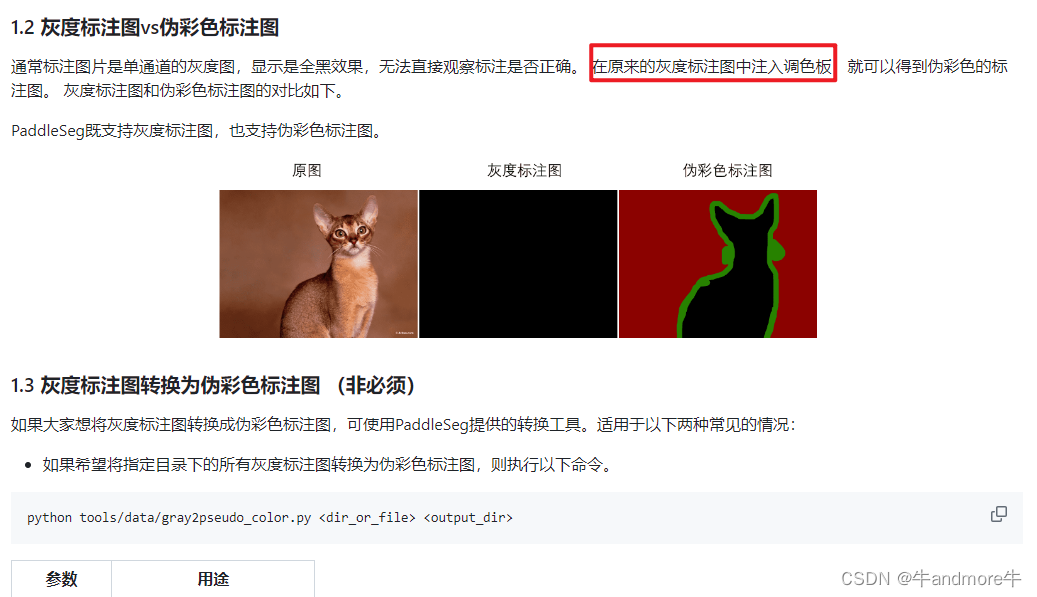
生成图片后,看看效果,我这里遇到的一个问题就是dino+sam标注,因为dino检测框多了,所以会有重复的部分,正常操作应该是要在x-anylbeling中删除,但太没没删尽,或者这个单分类的分割任务是不用删的。

person标签本来是1的,但重叠部分是会变成2,写代码把所有2的部分变成1就可以。
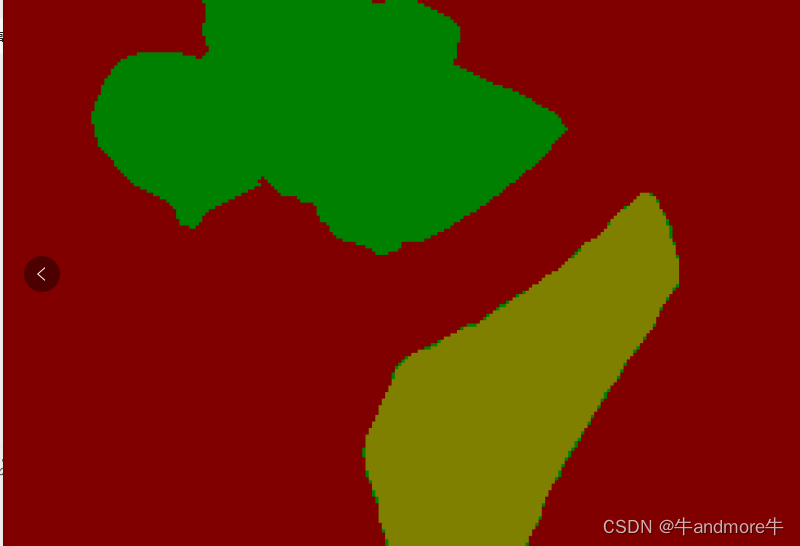
背景是红色的,1是绿色,2是黄。
这就是看伪彩色的意义。
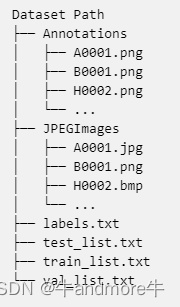
1.4 数据集整理
官方的结构是这样:

这里我的准备是这样的:
datasets
|
|-----images
| |
| |----a
| |----b
| |----c
|
|----labels
| |---a
| |---b
| |---c
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
a,b,c是三个不同数据的来源,images 下边是原图,labels 同名的png标签。
接着生成各个数据集的训练和验证数据集,用如下代码:
Description: 主要是用来生成各个训练集的训练和测试列表 path_root images a b labels a b 将生成a_train.txt b_train.txt ,这里把所有的数据全做成训练集就ok,不浪费数据;验证集把训练集复制一份就好了,不用担心过拟合,不用担心的 ''' import os from tqdm import tqdm path_root="/home/tl/PaddleSeg29/datasets" #最好上一个绝对路径 img_path = os.path.join(path_root,"images") lb_path = os.path.join(path_root,"labels") image_names=os.listdir(img_path) label_names=os.listdir(lb_path) #取个交集,更加安全 dataset_names = list(set(image_names) & set(label_names)) #接着对各个数据集分别生成训练列表 for i,dataset in enumerate(dataset_names): print(f"start to do dataset:{dataset}") dataset_images=[i for i in os.listdir(os.path.join(img_path,dataset)) if os.path.splitext(i.lower())[1] in [".png",".jpg",".jpeg"]] #不做过多的数据集质量较验 # dataset_labels=os.listdir(os.path.join(img_path,dataset)) lines=[] for imgname in tqdm(dataset_images): labelname = os.path.splitext(imgname)[0]+".png" #注意这个后缀,正常都是小写png,如果自己有特别的 line = os.path.join("images",dataset,imgname)+" "+os.path.join("labels",dataset,labelname)+"\n" lines.append(line) save_name=os.path.join(path_root,f"{dataset}_train.txt") with open(save_name,"w") as f: f.writelines(lines) print("Done")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
接着,生成最图训练所用的数据列表:
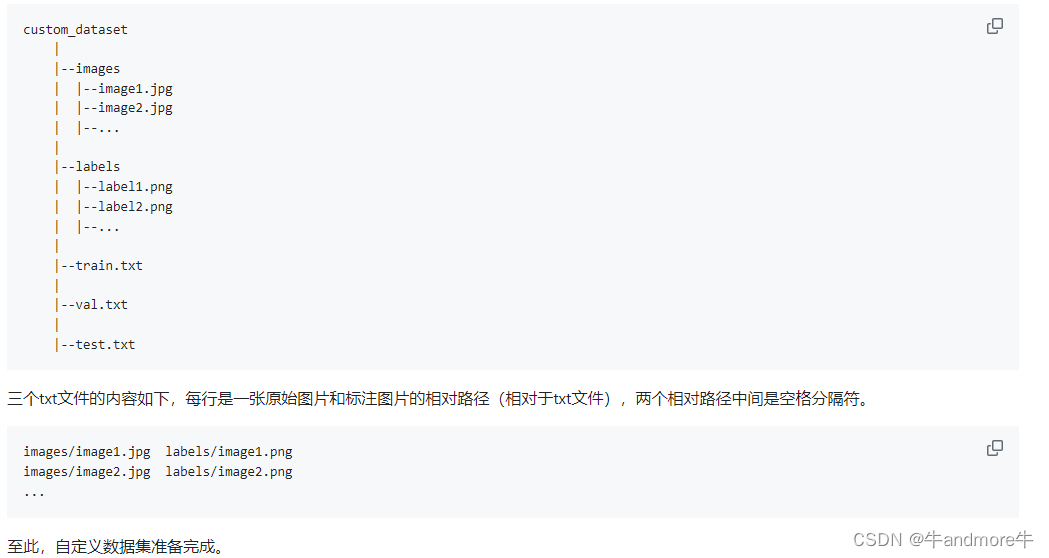
cat a_train.txt b_train.txt c_train.txt > train.txt
cat b_train.txt c_train.txt > val.txt
- 1
- 2
每一行都是:
images/a/1.jpg labels/a/1.png
....
images/b/1.jpg labels/b/1.png
...
images/c/1.jpg labels/c/1.png
- 1
- 2
- 3
- 4
- 5
1.5 标签可视化
这次用到的是tools/data/visualize_annotation.py
python3 tools/data/visualize_annotation.py --file_path ./dataset/MT_dataset/train.txt --save_dir ./show/
- 1
效果是这样的:

这个脚本还可以同时把predict的图显示出来,但要把预测的mask.png放到与原图同一个文件件下,这里就没做,具体看代码。
2、 模型训练
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.9/contrib/PP-HumanSeg/README_cn.md
因为是训练人像分割,就用pphuman了,配置文件在contrib/config/PPHUmanSeg中,默认的config下边也有好多的模型。
配置文件保存在./configs目录下,如下。配置文件中,已经通过pretrained设置好预训练权重的路径。
configs
├── human_pp_humansegv1_lite.yml
├── human_pp_humansegv2_lite.yml
├── human_pp_humansegv1_mobile.yml
├── human_pp_humansegv2_mobile.yml
├── human_pp_humansegv1_server.yml
执行如下命令,进行模型微调(大家需要根据实际情况修改配置文件中的超参)。模型训练的详细文档,请参考链接。
export CUDA_VISIBLE_DEVICES=0 # Linux下设置1张可用的卡
# set CUDA_VISIBLE_DEVICES=0 # Windows下设置1张可用的卡
python tools/train.py \
--config configs/human_pp_humansegv2_lite.yml \
--save_dir output/human_pp_humansegv2_lite \
--save_interval 100 --do_eval --use_vdl
- 1
- 2
- 3
- 4
- 5
v1-lite 大概2M,v2-lite 4M v1 mobile 13M v2 mobile 20M
按需求来取。
配置文件和预训练模型都可以拿来用,如下:
batch_size: 256 iters: 2000 train_dataset: type: Dataset dataset_root: /home/tl/PaddleSeg29/datasets train_path: /home/tl/PaddleSeg29/datasets/train.txt num_classes: 2 transforms: - type: Resize target_size: [192, 192] - type: ResizeStepScaling scale_step_size: 0 - type: RandomRotation - type: RandomPaddingCrop crop_size: [192, 192] - type: RandomHorizontalFlip - type: RandomDistort - type: RandomBlur prob: 0.3 - type: Normalize mode: train val_dataset: type: Dataset dataset_root: /home/tl/PaddleSeg29/datasets val_path: /home/tl/PaddleSeg29/datasets/val.txt num_classes: 2 transforms: - type: Resize target_size: [192, 192] - type: Normalize mode: val export: transforms: - type: Resize target_size: [192, 192] - type: Normalize optimizer: type: sgd momentum: 0.9 weight_decay: 0.0005 lr_scheduler: type: PolynomialDecay learning_rate: 0.0005 end_lr: 0 power: 0.9 loss: types: - type: MixedLoss losses: - type: CrossEntropyLoss - type: LovaszSoftmaxLoss coef: [0.8, 0.2] coef: [1] model: type: PPHumanSegLite align_corners: False num_classes: 2 #pretrained: /home/tl/PaddleSeg29/models/segv1-lite/human_pp_humansegv1_lite_192x192_pretrained/model.pdparams pretrained: /home/tl/PaddleSeg29/output/seglitev1/best_model/model.pdparams
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
batch-size iters 看自己的显卡大小来改;学习率也可以改,各参数的意义可以参看:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.9/docs/whole_process_cn.md,路径的改动:

最后读取图片,大致是dataset_root分别加上txt文件里的两部分来读取图和target.
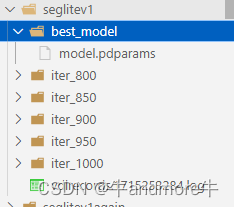
模型保存结果为:
3、模型验证
这步就不做了,因为在训练过程做过。如查要做,可以参看:
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.9/docs/evaluation/evaluate_cn.md
命令就是:
python tools/val.py \
--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams
- 1
- 2
- 3

这里我们只关注我们关注的类别,分别有Iou,精确率和召回率。
4、模型推理
命令行如下:
python tools/predict.py \
--config configs/human_pp_humansegv2_lite.yml \
--model_path pretrained_models/human_pp_humansegv2_lite_192x192_pretrained/model.pdparams \
--image_path data/images/human.jpg \
--save_dir ./data/images_result
- 1
- 2
- 3
- 4
- 5
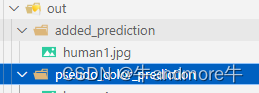
added_prediction:

pseudo_color_prediction:

5、模型导出
导出方便部署,命令行如下:
python tools/export.py \
--config configs/human_pp_humansegv2_lite.yml \
--model_path pretrained_models/human_pp_humansegv2_lite_192x192_pretrained/model.pdparams \
--save_dir output/human_pp_humansegv2_lite \
--without_argmax \
--with_softmax
- 1
- 2
- 3
- 4
- 5
- 6
更多的需要参照这个文档:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.9/docs/model_export_cn.md
因为后处理,只有一个算子,所以一个都不要,我们在外边处理。
导出文件为:
6、导出文件的推理
导出文件推理,导出模型时的后处理要加argmax,
推理命令为:
python deploy/python/infer.py --config output/inference_model/mobilev2_192_argx/deploy.yaml --image_path human1.jpg --save_dir ./show/out4
- 1
输出结果是伪彩色图,大小是192x192和输入一样大小。并没有转回到原图。

7、将模型转换成onnx
需要用使用paddle2onnx这个工具,转换命令参照这里:
https://github.com/PaddlePaddle/Paddle2ONNX,命令行如下:
paddle2onnx --model_dir saved_inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file model.onnx
- 1
- 2
- 3
- 4
接着对onnx 进行简化,要用到onnxsim这个包:
python -m onnxsim litev1_192.onnx litev1_sim_192.onnx
- 1
- 2
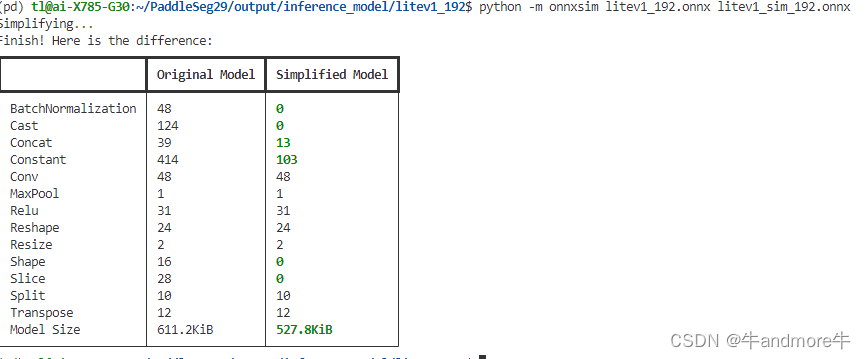
这里作了四个模型,分别如图:
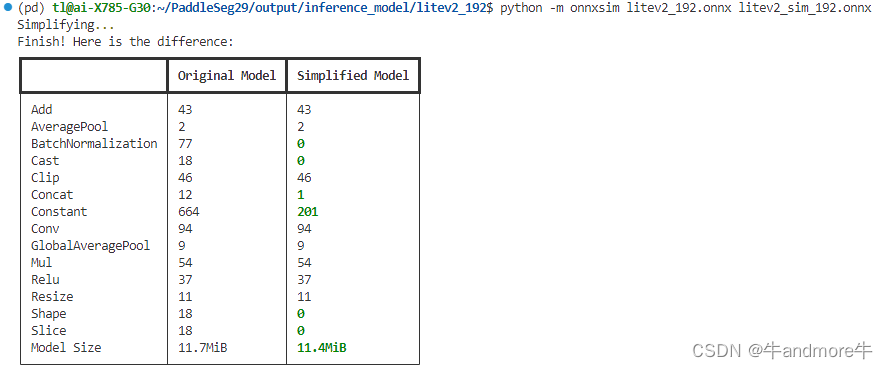
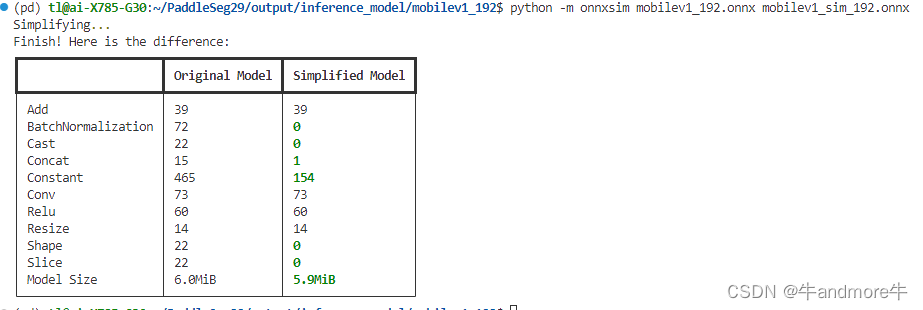
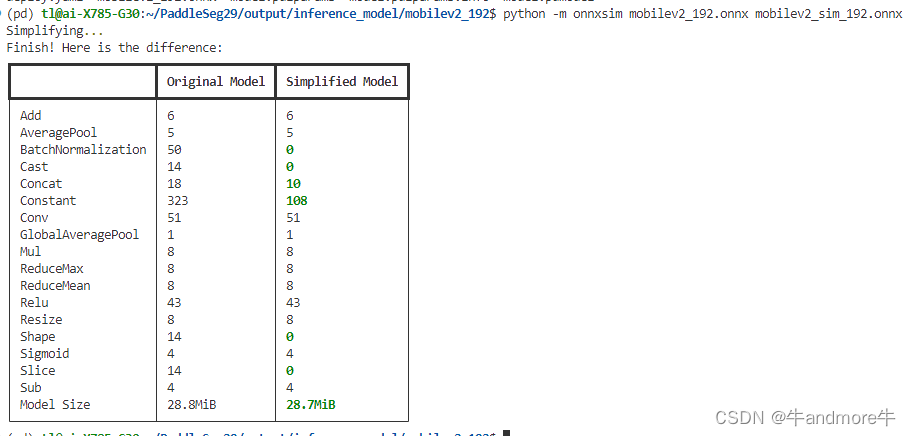
从精度和性能来看。选合适的来用。
onnx相比是更加重要的,因为我们通常是基于onnx进行各种转换再部署到相应的硬件上的。
8、使用onnx进行推理
这部分代码是从predict.py中按照处理流程,结合deeploy/python中的部分代码及github自己整理的,c++的就不搞了,上个Python的.
''' Author: tianliang Date: 2024-05-14 16:33:15 LastEditors: tianliang LastEditTime: 2024-05-16 16:25:47 FilePath: /deeplabv3/main.py Description: ''' #!/usr/bin/env python # -*- coding: utf-8 -*- import copy import argparse import cv2 import numpy as np import onnxruntime class mobilev1seg: def __init__(self): # Initialize model self.onnx_session = onnxruntime.InferenceSession("/home/tl/deeplabv3/mobv1_save_shape_sim.onnx") self.input_name = self.onnx_session.get_inputs()[0].name self.output_name = self.onnx_session.get_outputs()[0].name self.input_shape = self.onnx_session.get_inputs()[0].shape self.input_height = self.input_shape[2] self.input_width = self.input_shape[3] self.mean = np.array([0,0,0], dtype=np.float32).reshape(1,1,3) self.std = np.array([1.,1.,1.], dtype=np.float32).reshape(1,1,3) def prepare_input(self, image): input_image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) input_image = cv2.resize(input_image, dsize=(self.input_width, self.input_height),interpolation=cv2.INTER_LINEAR) input_image = (input_image.astype(np.float32) / 255.0 - self.mean) / self.std input_image = input_image.transpose(2, 0, 1) input_image = np.expand_dims(input_image, axis=0) return input_image def detect_argmax(self, image): input_image = self.prepare_input(image) # Perform inference on the image result = self.onnx_session.run([self.output_name], {self.input_name: input_image}) # Post process:squeeze segmentation_map = result[0] # 1x2x384x384 segmentation_map = np.squeeze(segmentation_map) #2x384x384 segmentation_map = np.transpose(segmentation_map,(1,2,0)) #384x384x2 image_width, image_height = image.shape[1], image.shape[0] #原图形状 segmentation_map = cv2.resize( segmentation_map, dsize=(image_width, image_height), interpolation=cv2.INTER_LINEAR, ) #双线性插值回到原图 pred = np.argmax(segmentation_map,axis=-1) # OrigH x OrigW x 2 -> OrigH x OrigW 值就是0,1 pred = pred.astype("uint8") #可视化 dst_image = copy.deepcopy(image) contours,hierarchy= cv2.findContours(pred,cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) #for c in contours: if len(contours)>0: cv2.drawContours(dst_image, contours, -1, (0, 255, 0), 1) #contours就是所有的点的坐标 return dst_image if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--imgpath', type=str, default='3.jpg', help="image path") parser.add_argument('--use_video', type=int, default=0, help="if use video") args = parser.parse_args() save=True segmentor = mobilev1seg() if args.use_video != 1: srcimg = cv2.imread(args.imgpath,cv2.IMREAD_COLOR) # Detect Objects dstimg = segmentor.detect_argmax(srcimg) if save: cv2.imwrite("dst.jpg",dstimg) else: winName = 'Seg in ONNXRuntime' cv2.namedWindow(winName, 0) cv2.imshow(winName, dstimg) cv2.waitKey(0) cv2.destroyAllWindows() else: cap = cv2.VideoCapture(0) ###也可以是视频文件 while True: ret, frame = cap.read() if not ret: break dstimg = segmentor.detect(frame) key = cv2.waitKey(1) if key == 27: # ESC break cv2.imshow('Seg Demo', dstimg) cap.release() cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
对于多分类的,后处理可以适当自己再处理一下。

