
热门标签
热门文章
- 1mysql8.0.18相关配置_mysql8.0.18配置文件
- 2探秘LeetCode竞赛评级预测神器:LCCN Predictor
- 3【成为架构师课程系列】系统架构设计:非功能性目标的设计
- 4ISO26262标准概览_iso26262规范文件
- 5深度解析大数据之殇_阐述数字信息资源长尾分布与大型商业数据库利用之间的矛盾
- 6C#进阶-基于.NET Framework 4.x框架实现ASP.NET WebForms项目IP拦截器_webforms教程
- 7数据标准化的重要性与应用场景
- 8教程 | 通过OTA升级的方式为RK3568开发板部署新功能_rk3568 u盘 ota
- 9FPGA设计规范_学习部门制定的fpga设计规范的好处
- 10口袋奇兵游戏攻略:云手机辅助战锤入侵策略指南!_口袋奇兵脚本
当前位置: article > 正文
ACL 2023 | ProPETL:一种高效的Parameter-Efficient迁移学习方法
作者:黑客灵魂 | 2024-07-20 19:37:17
赞
踩
parameter-efficient transfer learning

©PaperWeekly 原创 · 作者 | 曾广韬
单位 | 新加坡设计科技大学
我们很高兴向大家分享我们在 ACL 2023 上发表的关于大模型、parameter-efficient transfer learning 方向的最新工作。

论文标题:
One Network, Many Masks: Towards More Parameter-Efficient Transfer Learning
论文链接:
https://arxiv.org/pdf/2305.17682.pdf
代码链接:
https://github.com/ChaosCodes/ProPETL
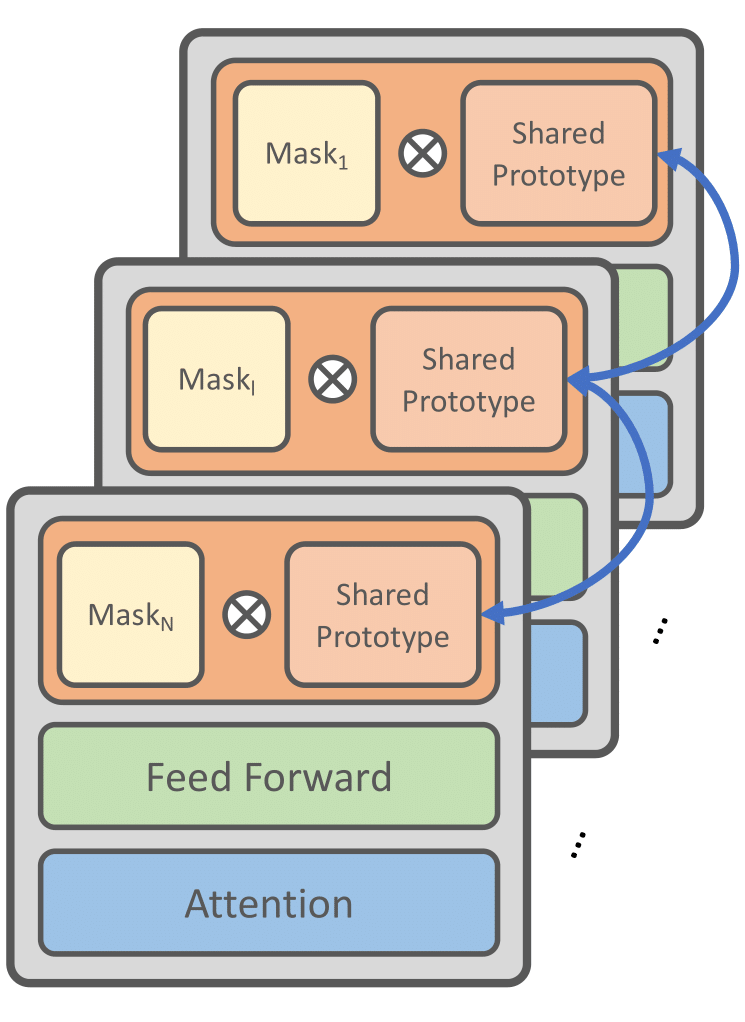

背景与动机
在深度学习领域,我们一直在寻找更有效的方法来提高模型的性能,同时降低计算和存储需求。我们的工作主要关注如何通过共享参数和掩码子网络的设计(也可以看作是一种剪枝操作)来提高模型的参数效率。
1.1 问题一:参数效率的挑战
在大型语言模型中,参数数量通常是巨大的,这不仅增加了计算和存储的需求,也可能导致过拟合等问题。因此,在 finetune 大型语言模型时, 许多 Parameter Efficient Transfer Learning(PETF)方法被提出。这些方法只需要更新很少一部分的额外参数, 节省了 finetune 时的显存以及存储需求。但是当下游任务变得越来越大的时候,计算和存储的需要也会变大从而很难应用在资源受限的环境。
于是我们希望找到一种方法,
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/858116
推荐阅读
相关标签

