
- 1数据实时传输平台(CDC)与低代码平台(APAAS)数据集成_cdc平台
- 2ZYNQ petalinux系统使用axi_bram进行PL与PS数据交互_ps和pl通过bram批量数据读写
- 3课工场题库自动化脚本原理分析及实现(文章末尾附免费可用版本)_免费脚本题库配置链接
- 4IOS - swift SDK开发_制作 swift sdk
- 5AI产品经理入门全指南资料库_ai产品经理知识库
- 6Phoenix启动过程出现的问题_phoenix启动后没有master
- 7将句子表示为向量:无监督句子表示学习(sentence embedding)
- 8Fine-tuning: 深度解析P-tuning v2在大模型上的应用_ptuning v2原理
- 9Git笔记-Connection reset by 13.229.188.59 port 22 fatal: Could not read from remote repository._connection reset by 180.76.198.77 port 22 fatal: c
- 1010张图看AI趋势:到2025年全球AI企业营收增幅53%_ai产业对gdp的贡献率 图表
【全网瞩目】最强文生图模型,Stable Diffusion 3技术报告解禁_sd3的文本编码器
赞
踩
12号,终于在Hugging Face上出现了 Stable Diffusion 3 Medium。没错,正如他所承诺的,最强文生图模型真的开源了。而且此次开源不仅是以SD2的比较下性能得到了更好的升级,同时也向我们展示了最前沿的DiT技术——MMDiT。

是什么让 SD3 Medium 脱颖而出?
SD3 Medium 是一款拥有 20 亿参数的 SD3 型号,具有一些显著特点:
-
整体质量和逼真度: 提供具有卓越细节、色彩和照明的图像,实现逼真输出以及灵活风格的高质量输出。通过 16 通道 VAE 等创新技术,成功解决了手部和面部逼真度等其他模型的常见问题。
-
理解提示: 可理解涉及空间推理、构图元素、动作和风格的冗长而复杂的提示。通过使用所有三种文本编码器或其组合,用户可以在性能与效率之间进行权衡。
-
排版: 利用我们的扩散变换器架构,实现前所未有的文本质量,减少拼写、字间距、字母形状和间距错误。
-
节省资源: 由于 VRAM 占用较少,因此非常适合在标准消费 GPU 上运行,而不会降低性能。
-
微调: 能够从小型数据集中吸收微妙的细节,非常适合定制。
MMDiT
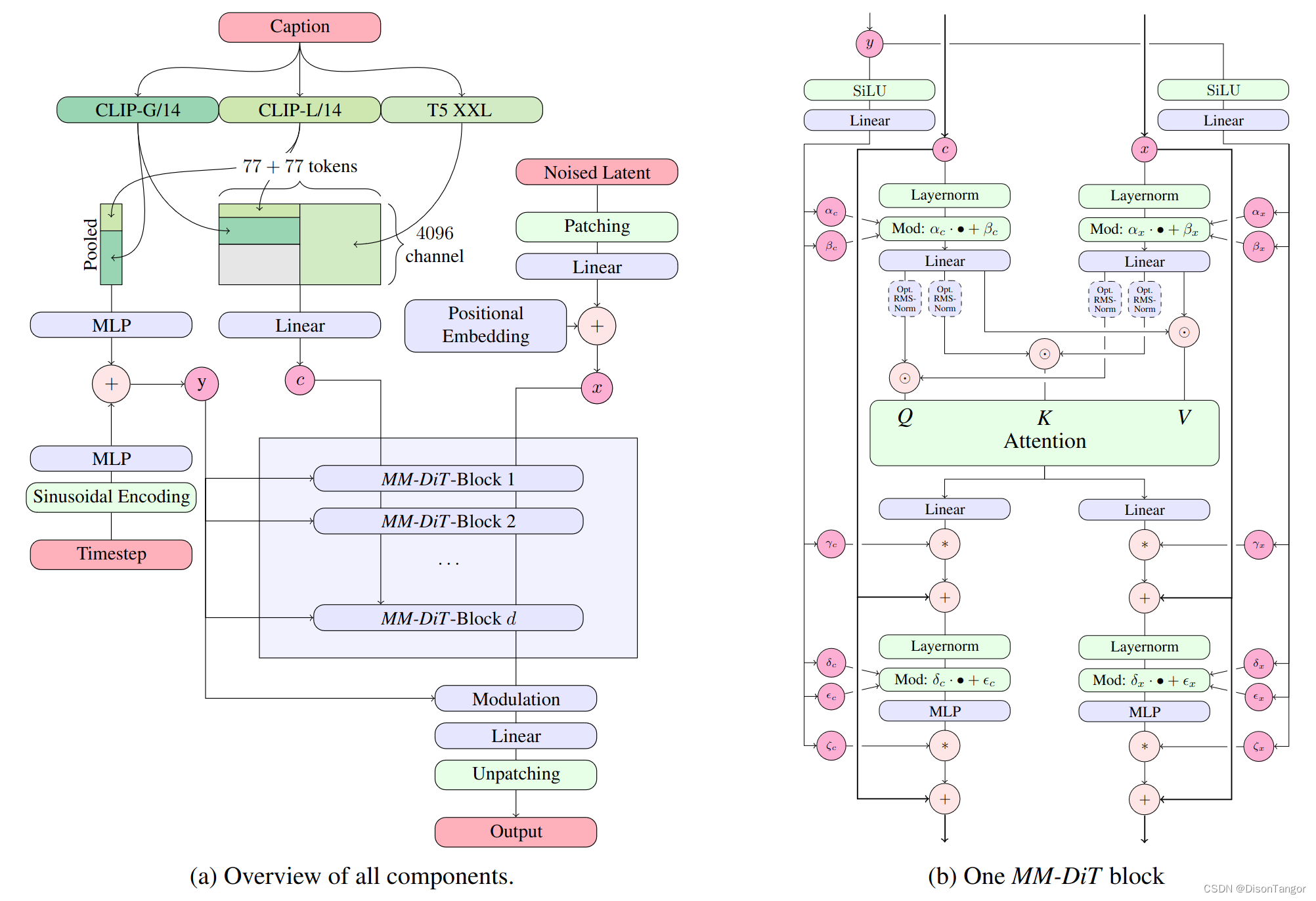
这一架构采用了独立的权重集合来处理图像和语言表示,这意味着对于文本和图像两种不同的输入模态,MMDiT 分别使用不同的权重参数来进行编码和处理,以此能够更好地捕捉每种模态的特征和信息。
在 MMDiT 架构中,文本和图像的表示分别通过预训练模型进行编码。具体地说,MMDiT 采用了三种不同的文本嵌入器(两个 CLIP 模型和 T5 模型),以及一个改进的自动编码模型来编码图像 token。这些编码器能够将文本和图像输入转换为模型可以理解和处理的格式,为后续的图像生成过程提供了基础。
代码实现
这里我们参考 https://github.com/lucidrains/mmdit.git (
在 Pytorch 中实现《Stable Diffusion 3》中提出的单层 MMDiT)
import torch from mmdit import MMDiTBlock # define mm dit block block = MMDiTBlock( dim_joint_attn = 512, dim_cond = 256, dim_text = 768, dim_image = 512, qk_rmsnorm = True ) # mock inputs time_cond = torch.randn(1, 256) text_tokens = torch.randn(1, 512, 768) text_mask = torch.ones((1, 512)).bool() image_tokens = torch.randn(1, 1024, 512) # single block forward text_tokens_next, image_tokens_next = block( time_cond = time_cond, text_tokens = text_tokens, text_mask = text_mask, image_tokens = image_tokens )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
广义的版本如下
import torch from mmdit.mmdit_generalized_pytorch import MMDiT mmdit = MMDiT( depth = 2, dim_modalities = (768, 512, 384), dim_joint_attn = 512, dim_cond = 256, qk_rmsnorm = True ) # mock inputs time_cond = torch.randn(1, 256) text_tokens = torch.randn(1, 512, 768) text_mask = torch.ones((1, 512)).bool() video_tokens = torch.randn(1, 1024, 512) audio_tokens = torch.randn(1, 256, 384) # forward text_tokens, video_tokens, audio_tokens = mmdit( modality_tokens = (text_tokens, video_tokens, audio_tokens), modality_masks = (text_mask, None, None), time_cond = time_cond, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
在模型结构上,MMDiT 架构建立在 Diffusion Transformer(DiT)的基础上。由于文本和图像的表示在概念上有所不同,MMDiT 使用了两组独立的权重参数来处理这两种模态。这样一来,模型能够在文本和图像的表示空间中分别进行操作,同时又能够考虑到彼此之间的关联关系,从而实现更好的信息传递和整合。
论文:https://arxiv.org/pdf/2403.03206
性能
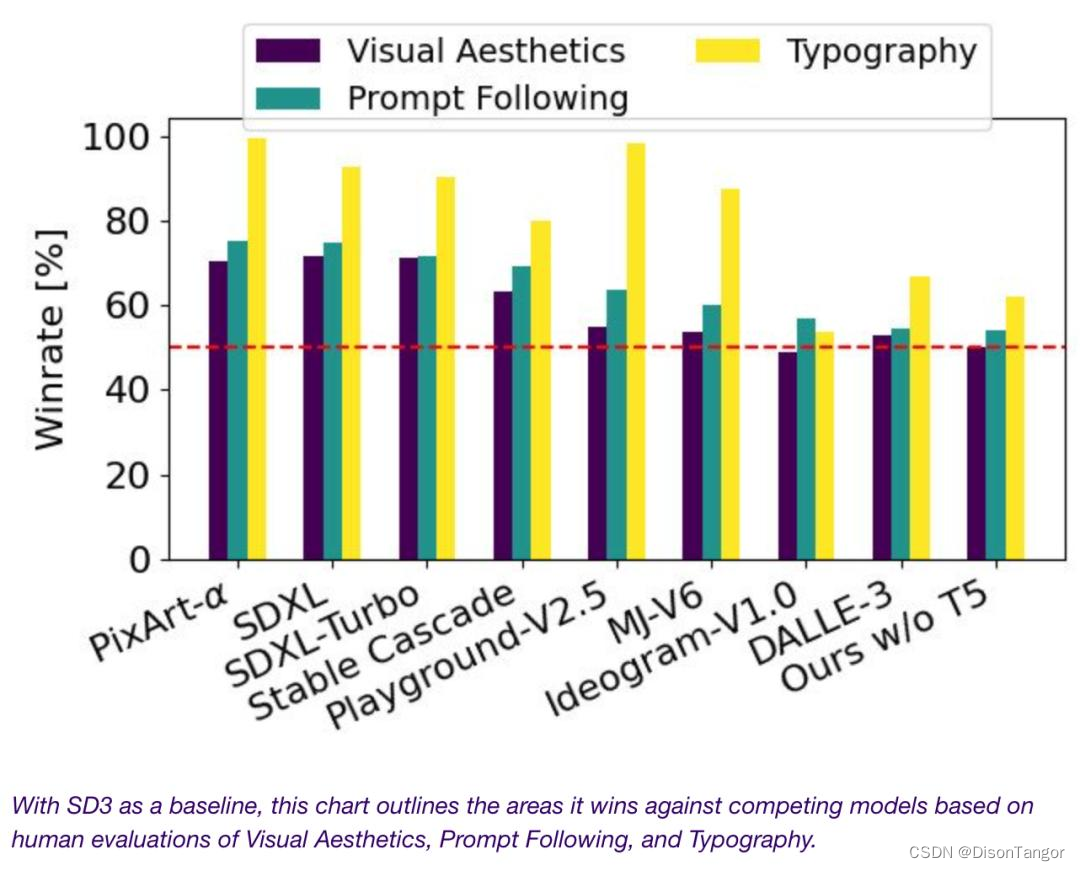
我们将 Stable Diffusion 3 的输出图像与其他各种开放模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及封闭源代码系统(如 DALL-E 3、Midjourney v6 和 Ideogram v1)进行了比较,以便根据人类反馈来评估性能。在这些测试中,人类评估员从每个模型中获得输出示例,并要求他们根据模型输出在多大程度上紧跟所给提示的上下文(“紧跟提示”)、在多大程度上根据提示渲染文本(“排版”)以及哪幅图像具有更高的美学质量(“视觉美学”)来选择最佳结果。
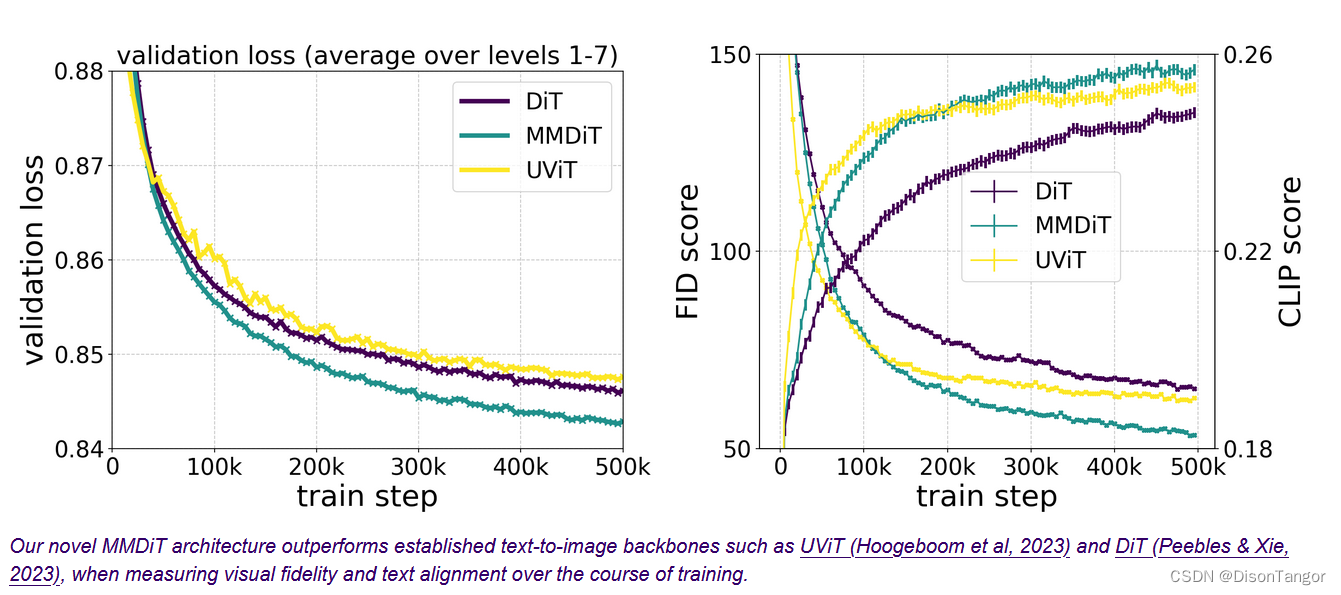
根据测试结果,我们发现 Stable Diffusion 3 在上述所有方面都与目前最先进的文本到图像生成系统相当,甚至更胜一筹。
在消费级硬件上进行的早期未优化推理测试中,我们最大的 8B 参数 SD3 模型适合 RTX 4090 的 24GB VRAM,使用 50 个采样步骤生成分辨率为 1024x1024 的图像需要 34 秒。此外,在最初发布时,Stable Diffusion 3 将有多种变体,从 800m 到 8B 参数模型不等,以进一步消除硬件障碍。
灵活的文本编码器
Stable Diffusion 3 不仅注重了图像生成的质量,还专注于与文本的对齐和一致性。其改进的 Prompt Following 功能使得模型能够更好地理解输入文本并根据其创作图像,而不仅仅是简单地产生图像。这种灵活性使 Stable Diffusion 3 能够根据不同的输入文本生成多样化的图像,满足不同主题和需求。
Stable Diffusion 3 采用了改进的 Rectified Flow(RF)方法,通过线性轨迹将数据和噪声相连接,使得推断路径更直,从而在少量步骤内进行采样。同时,Stable Diffusion 3还引入了一种新的轨迹采样调度,将更多的权重分配给轨迹的中间部分,从而改进了预测任务的难度。这种创新的方法改善了模型的性能,并在文本到图像生成任务中取得了更好的效果。
在文本到图像生成领域,Stable Diffusion 3 的问世标志着技术的重大进步。通过 MMDiT 架构的创新、Rectified Flow 的优化以及对硬件设备和模型规模的灵活调整,Stable Diffusion 3 在视觉美感、文本遵循和排版等方面表现出色,超越了当前的文本到图像生成系统。
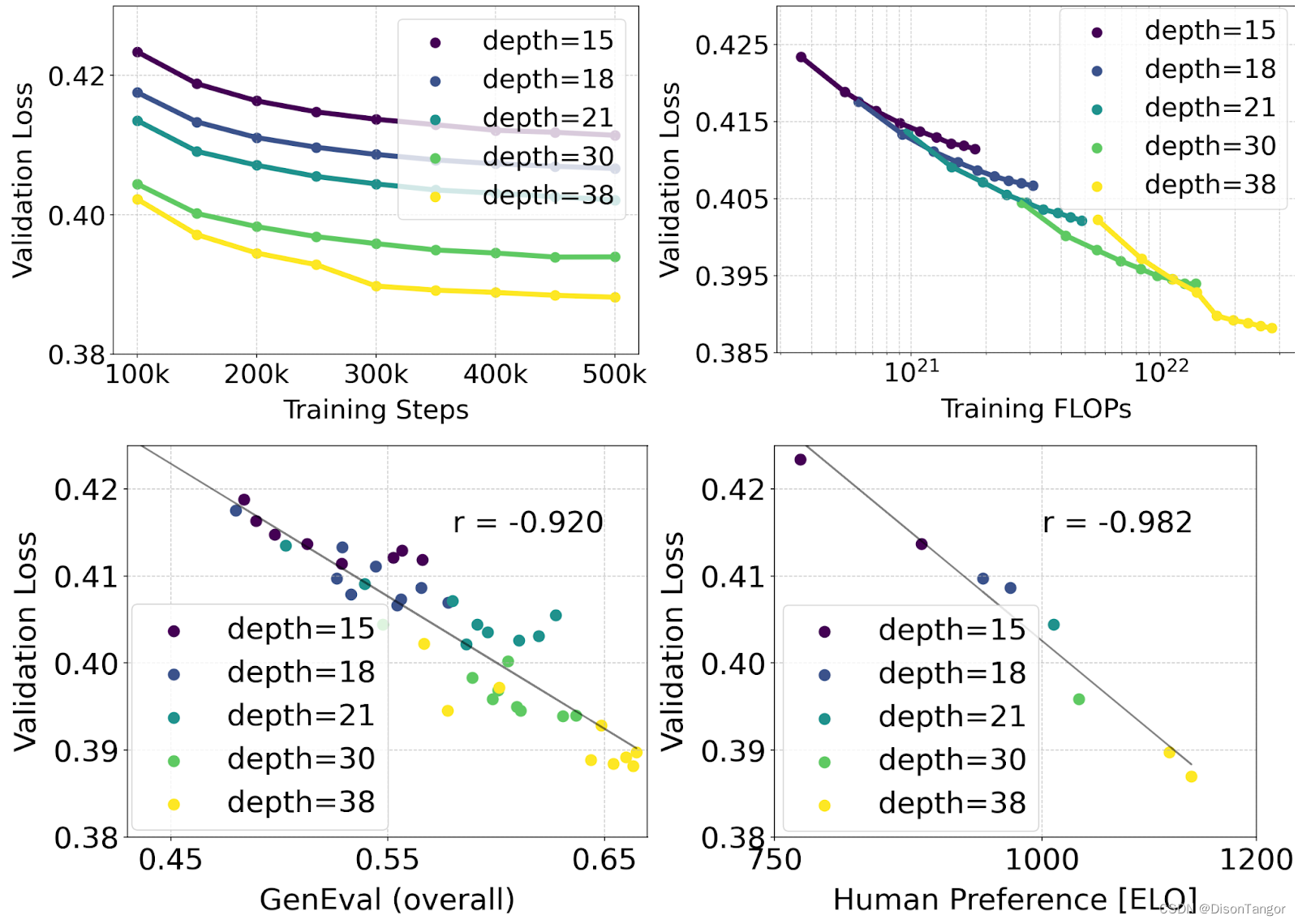
通过移除用于推理的内存密集型 4.7B 参数 T5 文本编码器,SD3 的内存需求可显著降低,而性能损失却很小。如上图 "性能 "部分所示,移除该文本编码器不会影响视觉美感(不使用 T5 时的胜率为 50%),只会略微降低文本粘着率(胜率为 46%)。不过,我们建议在生成书面文本时加入 T5,以充分发挥 SD3 的性能,因为我们观察到,如果不加入 T5,生成排版的性能下降幅度更大(胜率为 38%),如下图所示:

源文件
文件结构
├── comfy_example_workflows/ │ ├── sd3_medium_example_workflow_basic.json │ ├── sd3_medium_example_workflow_multi_prompt.json │ └── sd3_medium_example_workflow_upscaling.json │ ├── text_encoders/ │ ├── README.md │ ├── clip_g.safetensors │ ├── clip_l.safetensors │ ├── t5xxl_fp16.safetensors │ └── t5xxl_fp8_e4m3fn.safetensors │ ├── LICENSE ├── sd3_medium.safetensors ├── sd3_medium_incl_clips.safetensors ├── sd3_medium_incl_clips_t5xxlfp8.safetensors └── sd3_medium_incl_clips_t5xxlfp16.safetensors
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
为了方便用户,我们为 SD3 Medium 型号准备了三种包装形式,每种都配备了相同的 MMDiT 和 VAE 配重。
- sd3_medium.safetensors 包括 MMDiT 和 VAE 配重块,但不包括任何文本编码器。
- sd3_medium_incl_clips_t5xxlfp16.safetensors 包含所有必要的权重,包括 fp16 版本的 T5XXL 文本编码器。
-sd3_medium_incl_clips_t5xxlfp8.safetensors 包含所有必要的权重,包括 fp8 版本的 T5XXL 文本编码器,在质量和资源需求之间取得了平衡。 - sd3_medium_incl_clips.safetensors 包含除 T5XXL 文本编码器之外的所有必要权重。它需要的资源极少,但如果没有 T5XXL 文本编码器,模型的性能会有所不同。
- text_encoders 文件夹包含三个文本编码器及其原始模型卡链接,以方便用户使用。text_encoders 文件夹中的所有组件(以及嵌入到其他软件包中的相应组件)均受其各自原始许可证的约束。
- example_workfows 文件夹包含 comfy 工作流程示例。
Diffusers
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
image
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
官方推荐
ComfyUI: https://github.com/comfyanonymous/ComfyUI
StableSwarmUI: https://github.com/Stability-AI/StableSwarmUI
Tech report: https://stability.ai/news/stable-diffusion-3-research-paper
Demo: https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium
Diffusers support: https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers

