
- 110分钟实现dotnet程序在linux下的持续部署_dotnet linux
- 2微博高并发场景下的分布式缓存架构_请求漂移
- 3人工智能(AI)、机器学习、深度学习 的关系_机器学习 深度学习 ai
- 42024年高职云计算实验室建设及云计算实训平台整体解决方案
- 5互联网大厂需要什么样的人才
- 6mac 关闭sip 保护系统_chmod: unable to change file mode on jetbrains.vmo
- 7Zookeeper 的 Leader 选举
- 8python的JSON用法——dumps的各种参数用法(详细)_json.dump()方法
- 9docker privileged作用_docker总结
- 10ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory解决方案
Fastchat + vllm + ray + Qwen1.5-7b 在2080ti 双卡上 实现多卡推理加速_fastchat qwen
赞
踩
首先先搞清各主要组件的名称与作用:
-
FastChat
FastChat框架是一个训练、部署和评估大模型的开源平台,其核心特点是:提供SOTA模型的训练和评估代码
提供分布式多模型部署框架 + WebUI + OpenAI APIController管理分布式模型实例
Model Worker是大模型服务实例,它在启动时向Controller注册
OpenAI API提供OpenAI兼容的API服务,接受请求后,先向Controller获取Model Worker地址,再向Model Worker实例发送请求生成文本,最后返回OpenAI兼容的报文。
Fastchat 兼容的llm集合 请见 https://github.com/lm-sys/FastChat/blob/main/docs/model_support.md
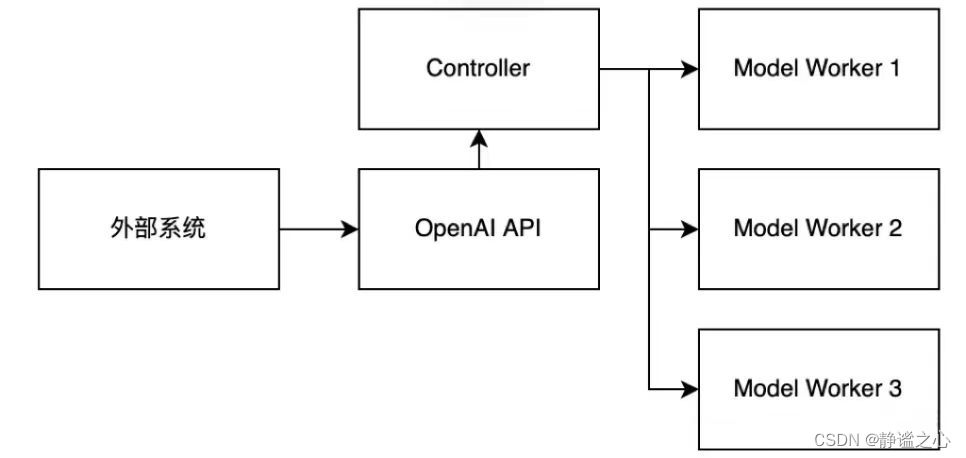
-
vllm 推理加速框架
vLLM 用于大模型并行推理加速,核心是 PagedAttention 算法,官网为:https://vllm.ai/。 -
ray 分布式框架
Ray 是一个高性能的分布式计算框架,由UC Berkeley RISELab 开发,支持Python 语言,并可与PyTorch 等机器学习框架结合使用。Ray提供了高效的任务调度、支持多种编程语言和机器学习框架,且系统层的抽象使得资源利用和任务调度更加灵活高效。它比Spark更轻量级,且易于使用和扩展。相较于TensorFlow和PyTorch,Ray注重分布式计算的高效和弹性。在隐私计算方面,Ray提供了数据隐私保护,支持数据共享和协作,同时允许在不泄露原始数据的情况下进行深度学习模型训练。 -
本地环境情况 2080ti 双卡 共 44g显存 64g内存
开始操作
1. 启动worker控制协调器 ---- controller
python -m fastchat.serve.controller --host 0.0.0.0
- 1
2. 启动API服务 ---- API server
python -m vllm.entrypoints.api_server --trust-remote-code --model /home/ksl/llms/CodeQwen1.5-7B-Chat/CodeQwen1.5-7B-Chat --served-model gpt-3.5-turbo --tensor-parallel-size 2 --dtype=half
- 1
3. model worker 有2种 如下
- 启动不带推理加速的 模型worker
python -m fastchat.serve.model_worker --model-path /home/ksl/llms/CodeQwen1.5-7B-Chat/CodeQwen1.5-7B-Chat --host 0.0.0.0 --dtype=half
- 1
- 启动 带vllm推理加速的 模型worker
python -m fastchat.serve.vllm_worker --model-path /home/ksl/llms/CodeQwen1.5-7B-Chat/CodeQwen1.5-7B-Chat --host 0.0.0.0 --dtype=half
- 1
注意这几个参数
--dtype=half由于我的显卡是2080ti bf16算力只有7.5 所以需要变成fp16运行--tensor-parallel-size 2启动apiserver时候 如果需要多卡张量并行 加上卡的数量
那么服务正常情况下已经跑起来了 地址服务器所在 localhost:8000
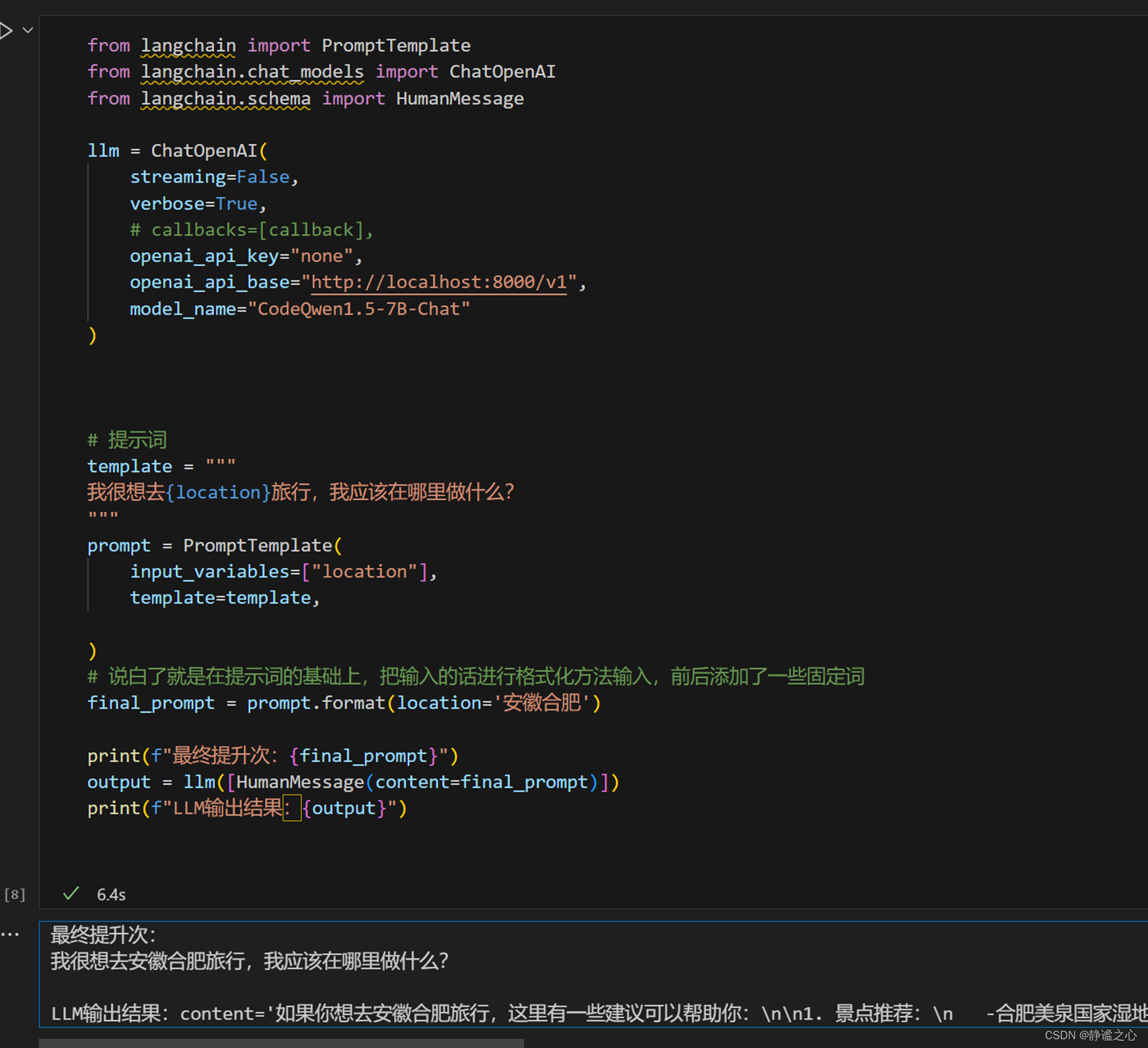
使用langchain进行测试
from langchain import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
llm = ChatOpenAI(
streaming=False,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://localhost:8000/v1",
model_name="CodeQwen1.5-7B-Chat"
)
# 提示词
template = """
我很想去{location}旅行,我应该在哪里做什么?
"""
prompt = PromptTemplate(
input_variables=["location"],
template=template,
)
# 说白了就是在提示词的基础上,把输入的话进行格式化方法输入,前后添加了一些固定词
final_prompt = prompt.format(location='安徽合肥')
print(f"最终提升次:{final_prompt}")
output = llm([HumanMessage(content=final_prompt)])
print(f"LLM输出结果:{output}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
我又写了一个简易的多线程来请求 回复速度很快
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
super().__init__() #必须调用父类的初始化方法
def run(self) -> None:
print()
output = llm([HumanMessage(content=final_prompt)])
print("当前线程:"+threading.current_thread().name+f"LLM输出结果:{output}")
for i in range(0,100):
new_job = MyThread()
new_job.setName(i)
new_job.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
执行情况如下 并发速度还不错

显存占用情况如下
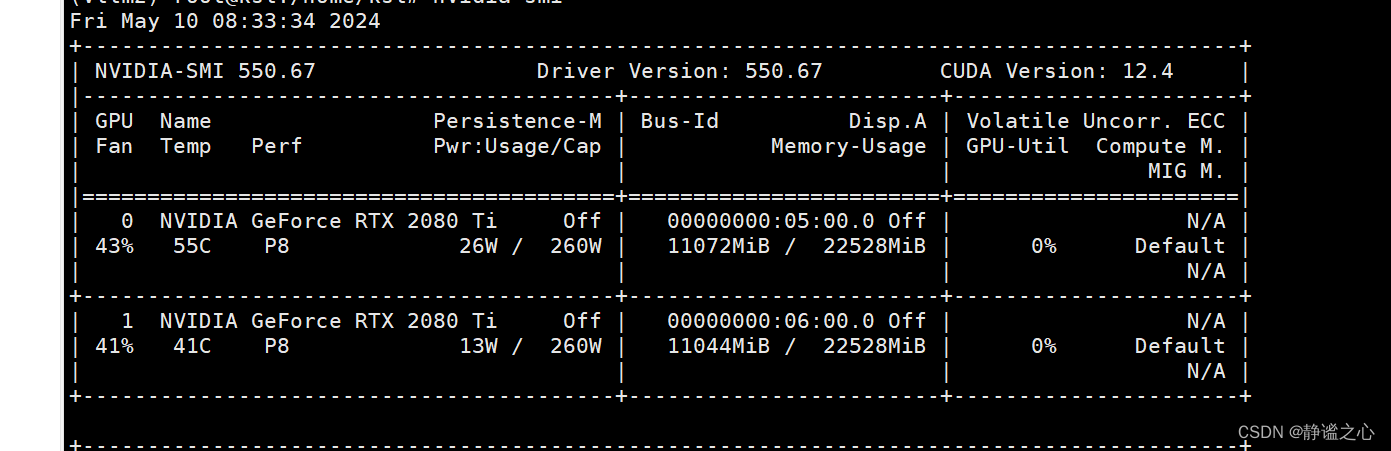
我这套方案 是我本人跑通验证过的
streaming=False可以用
streaming=True的话 估计要写符合Streamevent的http格式接收 但这个不是重点 后面有老哥研究好的话可以@我一下 共同进步!


