
- 1SpringBoot项目连接,有Kerberos认证的Kafka_springboot kafka kerberos认证
- 2android 蓝牙源码分析_android系统修改蓝牙状态为关闭状态源码
- 3「豆包Marscode体验官」AI加持的云端IDE——三种方法高效开发前后端聊天交互功能
- 4sql基础语法大全_sql逗号连接是98规范吗
- 5【软考系统架构设计师】2018年下系统架构师论文写作历年真题_论软件开发过程rup及其应用
- 6产品经理项目管理技巧:高效管理产品的五步法
- 7Python 爬虫项目实战(六):爬取大众点评商家数据
- 8Mac OS安装Docker容器的解决方案_mac docker_docker mac
- 9Linux命令---用户组管理_linux命令修改文件的用户组
- 10一篇文章搞懂人工智能、机器学习、深度学习_ai与机器学习
有手就行,轻松本地部署 Llama、Qwen 大模型,无需 GPU_本地部署 微调 llama大模型
赞
踩
用 CPU 也能部署私有化大模型?
对,没错,只要你的电脑有个 8G 内存,你就可以轻松部署 Llama、Gemma、Qwen 等多种开源大模型。
非技术人员,安装 Docker、Docker-compose 很费劲?
不用,这些都不需要安装,就一个要求:有手就行~
今天主要为大家分享保姆级教程:如何利用普通个人电脑,本地私有化部署 Qwen 大模型。
一、Ollama 与 Qwen7B 安装和使用
一)下载
进入下载地址,目前支持 Mac、Windows、Linux 以及 docker 部署,本次演示,主要针对 Mac。
下载地址:https://github.com/ollama/ollama
我已经为大家提前下载好了 Mac、Windows 的安装包,公众号回复 ollama 领取。
二)安装 Ollama
1、下载到本地,并解压后,双击 Ollama 图标。
2、点击 Move to Applications ,按照建议,将其移动到应用程序文件夹下。

3、按照从左到右的顺序执行这三步。到这 Ollama 安装完成了。

三)安装模型
作为国内的优质大模型,Qwen 对于中文的支持力度还是很强的,最终选择用它来试手。
大家也可以尝试选择自己喜欢的模型,比如 Llama3、Gemma 等等。
1、进入模型仓库
地址:https://ollama.com/library
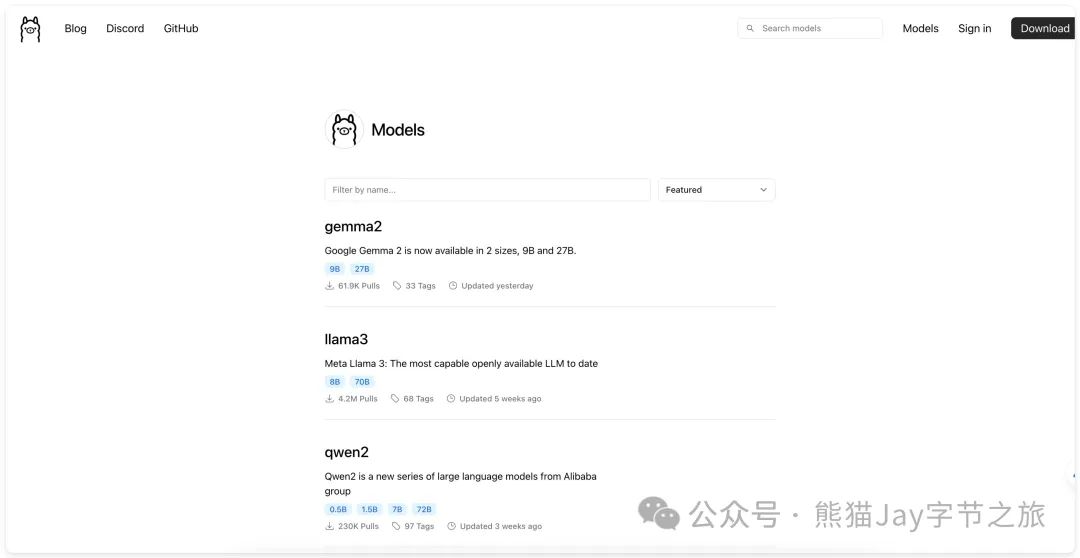
2、搜索对应模型。发现目前有 Qwen 0.5B ~ 110B 可供使用。
因为内存不够用,最终选择下载 Qwen:7b,大家可以按照自身硬件情况下载模型。
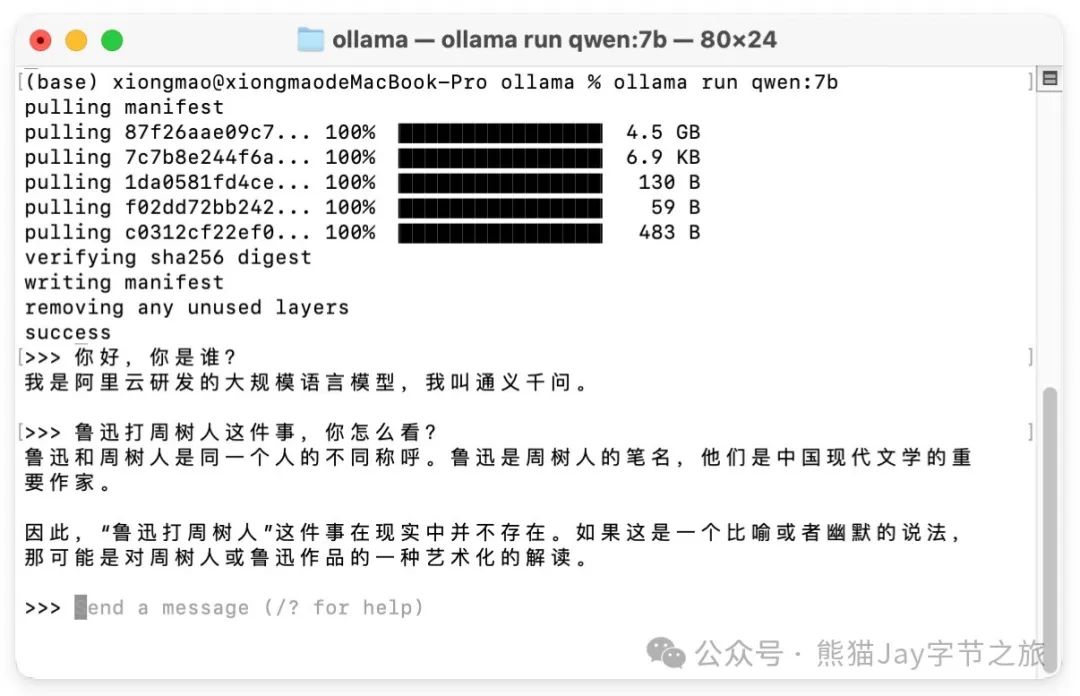
可以使用图中对应型号的命令,进行下载。7b 下载命令为:ollama run qwen:7b
官方建议: 至少有 8 GB 可用内存来运行 7 B 型号,16 GB 来运行 13 B 型号,32 GB 来运行 33 B 型号。

3、下载完成,开始对话,中文能力的确可以~
但是命令行对话总不是事儿啊,我们需要一个网页应用,这就得请出下一位主角:ChatGPT-Next-Web。
二、ChatGPT-Next-Web 安装和使用
一)安装
进入 ChatGPT-Next-Web 仓库地址,选择对应版本下载。
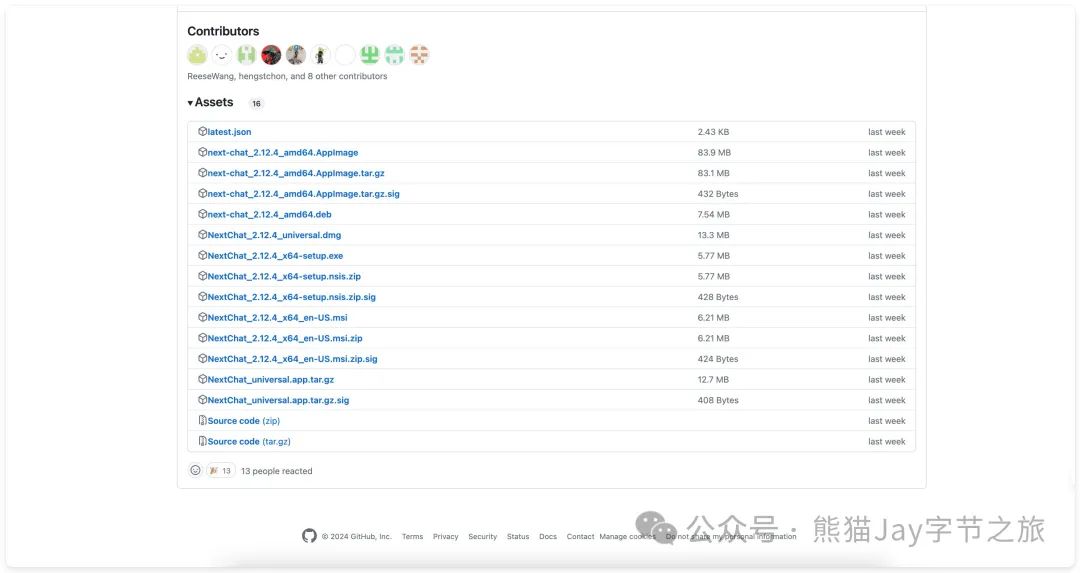
地址:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/releases/tag/v2.12.4
我选择了 NextChat_2.12.4_universal.dmg
我已经为大家提前下载好了 Mac、Windows 安装包,公众号回复 ollama 领取。
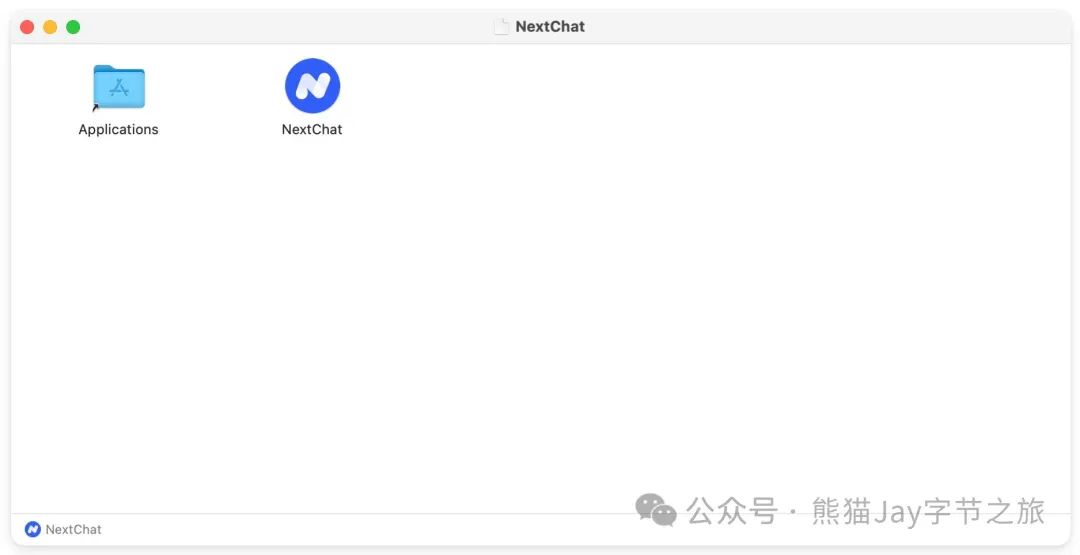
下载完成后,可以直接安装,无需额外下载其他软件。
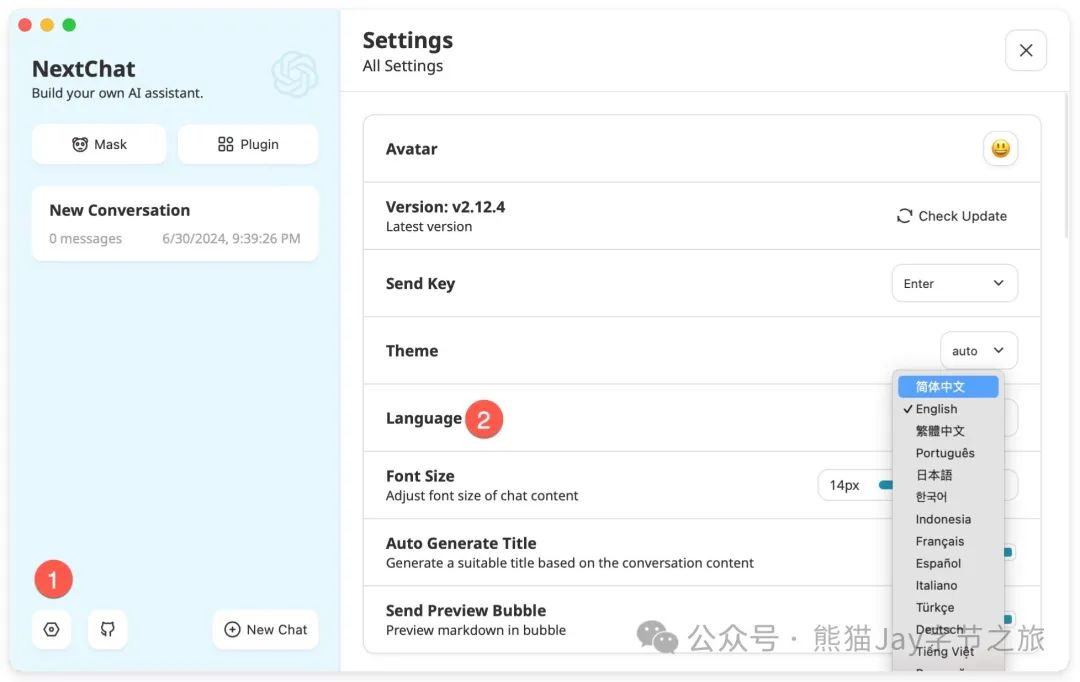
二)设置语言(可选)
按需选择语言偏好。
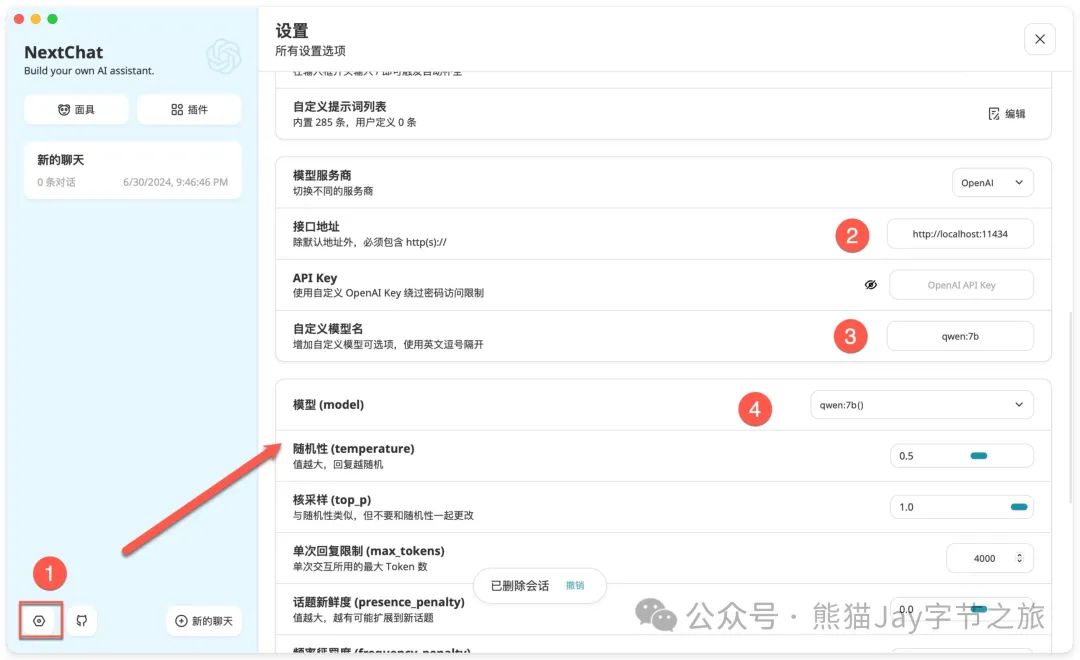
三)配置
1、点击图标,进行配置页面。
2、输入接口地址:http://localhost:11434
3、自定义模型名:qwen:7b
4、模型(model):qwen:7b() ,注意该选项在最下方。
四)对话测试
1、普通对话
效果还不错。

2、面具对话
使用面具对话功能时,需要注意,软件模型忽略了自定义的 qwen:7b,每次利用面具对话时,需要重新选择模型。
2.1、没有选择模型时,则会出错。
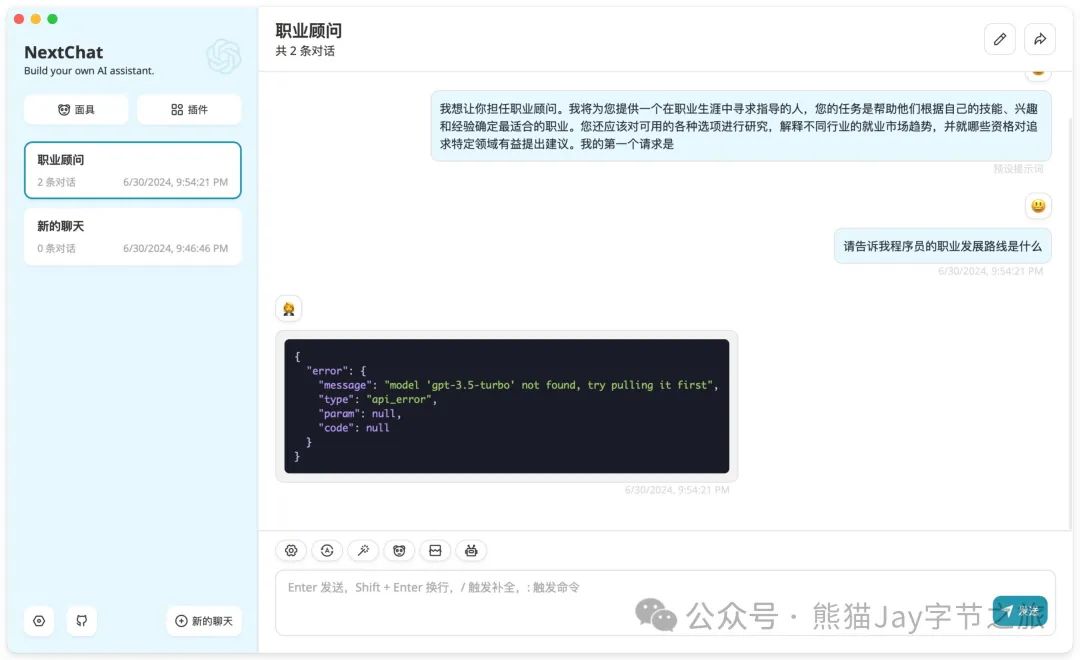
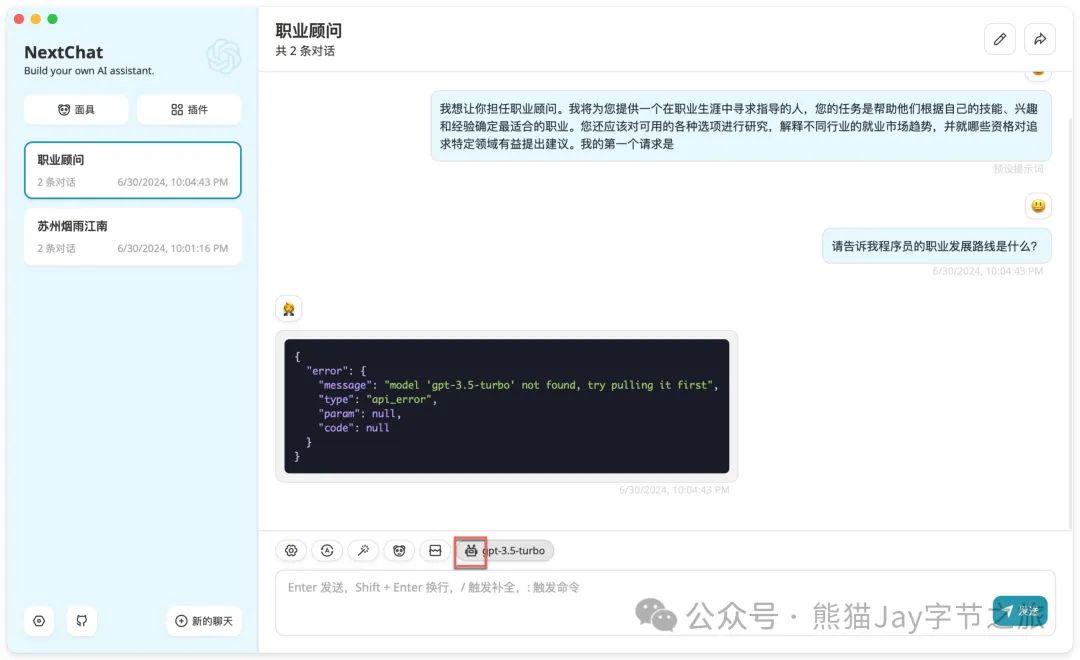
2.2、点击图标,并选择正确的模型。
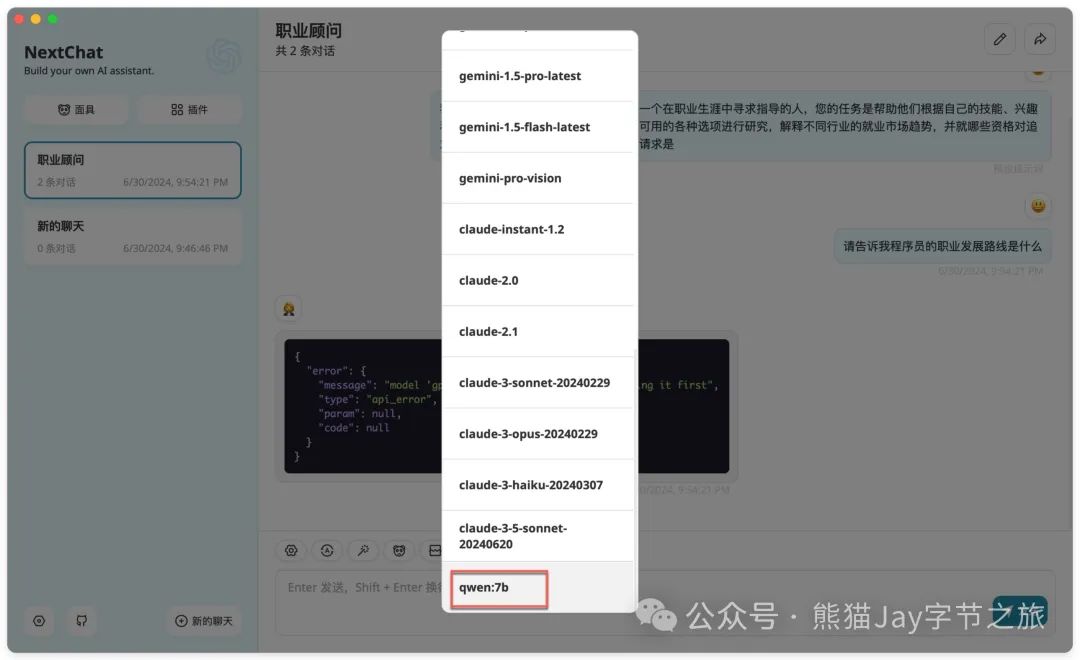
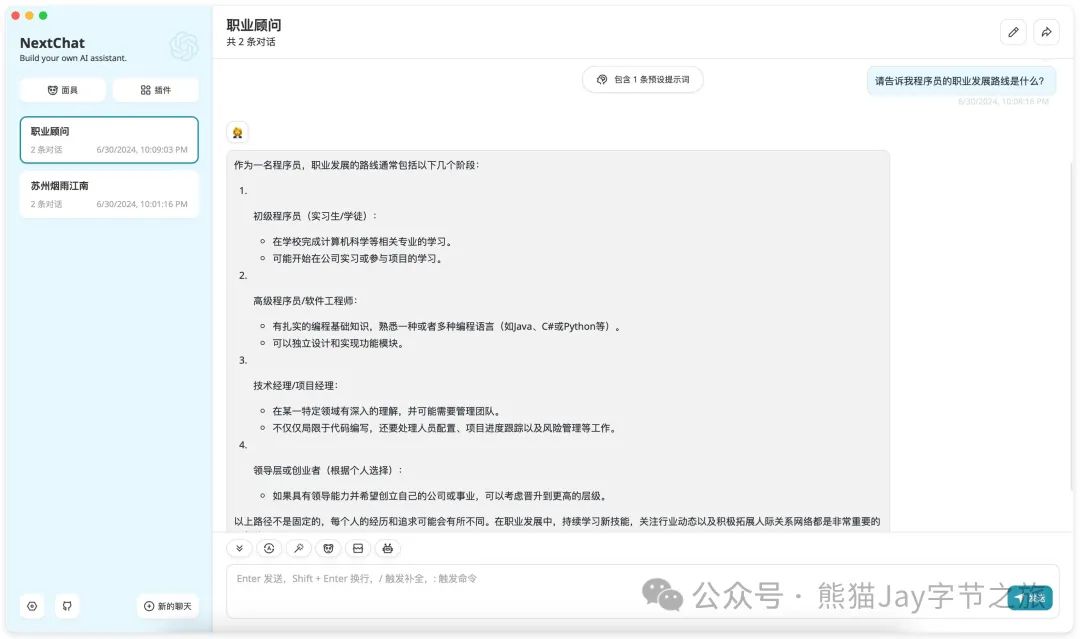
2.3、对话显示成功。
三、总结
没有消费级的 GPU,竟然都可以拥有自己的本地大模型。
部署过程基本上没有卡点,一台普通的 Mac 就能搞定,太香了~
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/908403
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

