
热门标签
热门文章
- 1Hive初始化报错:org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
- 2【HIVE数据倾斜常见解决办法】_hive数据倾斜解决办法
- 3Linux上的Redis客户端软件G-dis3_g-dis3 使用
- 4(1)监听QQ消息自动回复-QQ自动化(.Net)_uianimations监控qq
- 5【附源码】基于flask框架基于微信小程序点餐系统的设计与实现 (python+mysql+论文)_基于微信小程序的点餐小程序的设计与实现
- 6【MongoDB】万字长文,命令与代码一一对应SpringBoot整合MongoDB之MongoTemplate
- 73种策略让微服务测试的ROI最大化_实现roi最大
- 8自动化脚本如何有效防检测、防风控?_脚本防止无障碍检测
- 9《Unity3D高级编程之进阶主程》第三章 数据表(二) - 数据表的制作方式
- 10Hadoop学习笔记(1)——单机版搭建_hadoop2.8单机部署
当前位置: article > 正文
Transformer模型详解(原理版+图解版+实战版)
作者:一键难忘520 | 2024-07-11 03:32:42
赞
踩
transformer模型
前言
最近读了《Attention Is All You Need》,对Transformer模型有了初步的了解。
1.ransformer是什么?
Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构,它在2017年由Vaswani等人首次提出。Transformer架构引入了自注意力机制(self-attention mechanism),这是一个关键的创新,使其在处理序列数据时表现出色。
以下是Transformer的一些重要组成部分和特点:
- 自注意力机制(Self-Attention):这是Transformer的核心概念之一,它使模型能够同时考虑输入序列中的所有位置,而不是像循环神经网络(RNN)或卷积神经网络(CNN)一样逐步处理。自注意力机制允许模型根据输入序列中的不同部分来赋予不同的注意权重,从而更好地捕捉语义关系。
- 多头注意力(Multi-Head Attention):Transformer中的自注意力机制被扩展为多个注意力头,每个头可以学习不同的注意权重,以更好地捕捉不同类型的关系。多头注意力允许模型并行处理不同的信息子空间。
- 堆叠层(Stacked Layers):Transformer通常由多个相同的编码器和解码器层堆叠而成。这些堆叠的层有助于模型学习复杂的特征表示和语义。
- 位置编码(Positional Encoding):由于Transformer没有内置的序列位置信息,它需要额外的位置编码来表达输入序列中单词的位置顺序。
- 残差连接和层归一化(Residual Connections and Layer Normalization):这些技术有助于减轻训练过程中的梯度消失和爆炸问题,使模型更容易训练。
- 编码器和解码器:Transformer通常包括一个编码器用于处理输入序列和一个解码器用于生成输出序列,这使其适用于序列到序列的任务,如机器翻译。
2.Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:

可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
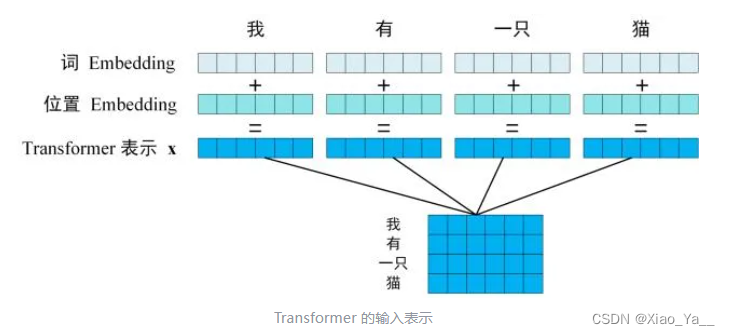
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

