
- 1Flume数据监听实验中Ncat:Connection refused_hadoop ncat connection refused
- 2智障儿童欢乐多,蹦蹦哒哒过六一:用 Python 开发连连看小游戏_python使用pygame写连连看游戏
- 3吴恩达深度学习笔记:神经网络的编程基础2.5-2.8
- 4is there any way to stop auto block
- 5排序算法1:归并排序的基本思想和应用示例_外排序的归并排序的算法思想以及归并排序的基本过程
- 6弹性盒子 justify-content: space-between; 换行问题_弹性盒子自动换行
- 7【Ubuntu系统下百度Apollo7.0与LGSVL2021.3联合教程(亲测有效)】_ubuntu ros lgsvl安装
- 8【深度学习】DQN网络代码详解_dqn代码
- 9Dockerfile部署Java项目挂载使用外部配置文件_java项目外部挂载配置
- 10java常用英语单词_.k .n . v .
Google开源OCR项目Tesseract训练(自己训练的记录,未成功)_google ocr
赞
踩
本文训练Tesseract用的方法主要参考文章 http://my.oschina.net/lixinspace/blog/60124 ,下面自写下自己的训练记录!
看懂本文需要上一篇博文(Google开源OCR项目Tesseract安装版在Windows下的使用测试记录)的基础!
一、
准备若干张待训练图片(我这里准备了10张),并全部转化为tif格式,我这里使用的转换软件是iSee,下载链接:iSee.rar_免费高速下载|百度网盘-分享无限制,具体使用方法如下图所示:
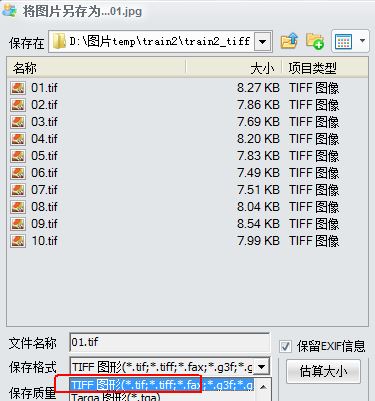
我准备的待训练图片(已转化为tif格式)下载链接:train2_tiff.rar_免费高速下载|百度网盘-分享无限制
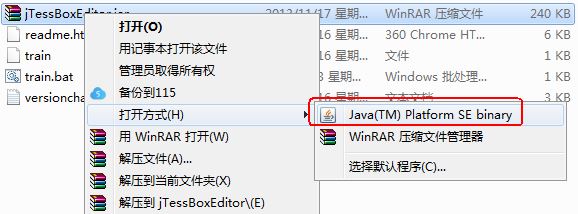
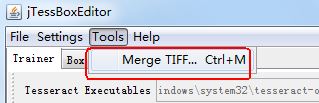
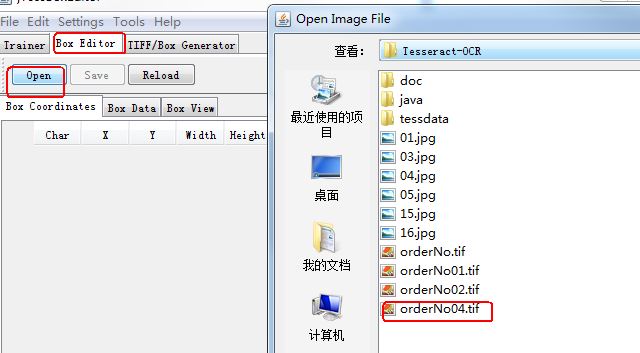
二、下载jTessBoxEditor-1.0(下载链接 http://pan.baidu.com/s/1geRbgQ3),并使用这个工具把上面的10张待训练的tif图片合成为一张tif图片,合成的tif图片取名为orderNo04.tif。
注意:要运行jTessBoxEditor-1.0,需要安装Java Runtime Environment,版本为6.0以上,这里给大家“Java Runtime Environment-6.0.450.exe”的下载链接:Java Runtime Environment-6.0.450.exe_免费高速下载|百度网盘-分享无限制
相关操作截图如下:
三、把orderNo04.tif复制到Tesseract的安装目录Tesseract-OCR下。
四、在CMD窗口下运行下面的语句:
tesseract.exe orderNo04.tif orderNo04 batch.nochop makebox
上面语句运行后生成了orderNo04.box文件,里面存储了tesseract.exe的识别结果,包括每个识别区域的坐标,区域大小及识别出来的字符等...
若要用已经训练好的数据库来生成box文件,比如用中文识别数据库chi_tra.traineddata,就执行下面的语句:
tesseract.exe orderNo04.tif orderNo04 -l chi_tra batch.nochop makebox
五、利用jTessBoxEditor-1.0编辑box文件,如下图所示:
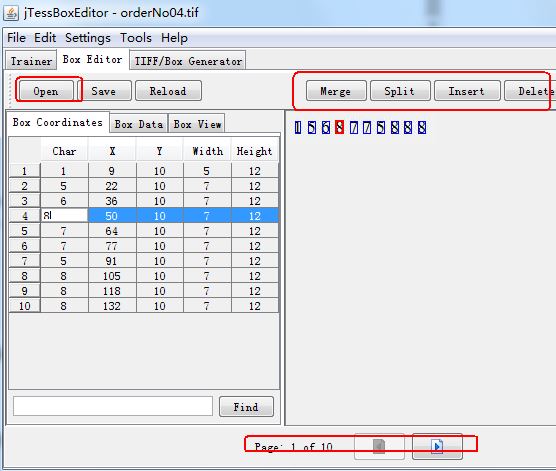
六、修改完成后,运行下面的语句:
tesseract.exe orderNo4.tif orderNo04 nobatch box.train
我就卡在这一部了,不管作何种尝试,就报下面的错误:
Cannot open input file: orderNo4.tif

明明orderNo4.tif是在文件夹Tesseract-OCR下面的,却说不能打开这个图片文件,真是够了!这个问题搞了两天,也搞不定,只好作罢,暂时放在这里,但愿以后能解决吧!
博主2022-04-18 11:31:07注:博主当时太粗心了,把文件名给写错了,详情大家看此篇博文下大家的回复吧。

