
- 1Stable Diffusion基础:ControlNet之人体姿势控制_为什么我的controlnet不能控制骨架
- 2在VSCode中配置Verilog语言环境并使用学习WaveTrace插件
- 3GitHub配置SSH Key(详细版本)_github ssh key配置
- 4OpenCV项目开发实战--条形码和 QR 码扫描器(C++ 和 Python)的代码实现_opencv二维码检测c++
- 5六、Redis 分布式系统 —— 超详细操作演示!_redis怎么实现分布式
- 6解决 springboot项目打包部署到linux系统下,下载resources/static/静态资源找不到的问题_spirngboot 静态资源,打包到linux 丢失
- 7Linux文件权限_linux 文件权限
- 8vscode连接 gitee_vscode 使用ssh连接gitee
- 9图论(二):图的四种最短路径算法
- 10anaconda实现python环境搭建_anaconda配置python环境
MySQL中InnoDB索引数据结构(B+树)详解_mysql innodb b+树
赞
踩
MySQL中InnoDB索引数据结构(B+树)详解
参考文章:CodingLabs - MySQL索引背后的数据结构及算法原理
MySQL中常用存储引擎有哪些?它们相互之间有什么区别? - 知乎 (zhihu.com)
一、MySQL中的数据存储引擎
存储引擎介绍
1、存储引擎其实就是对于数据库文件的一种存取机制,如何实现存储数据,如何为存储的数据建立索引以及如何更新,查询数据等技术实现的方法。
2、MySQL中的数据用各种不同的技术存储在文件(或内存)中,这些技术中的每一种技术都使用不同的存储机制,索引技巧,锁定水平并且最终提供广泛的不同功能和能力。在MySQL中将这些不同的技术及配套的相关功能称为存储引擎。
show engines;
- 1
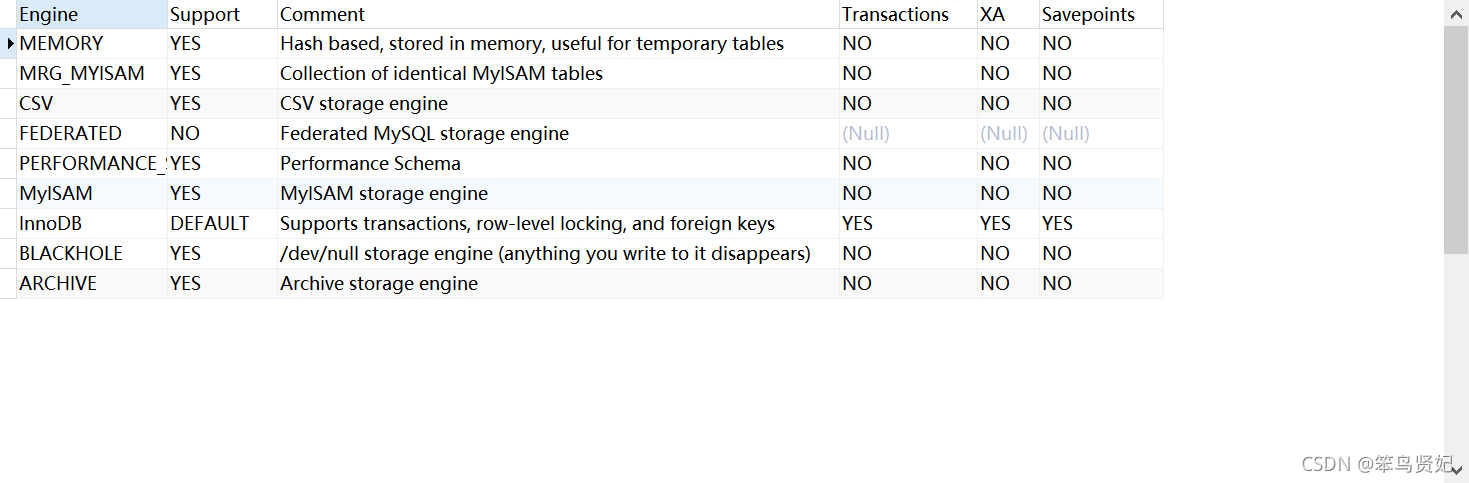
show variables like '% storage_engine'; // 查看mysql 默认的存储引擎
show create table tablename ; // 查看具体某一个表所使用的存储引擎,这个默认存储引擎被修改了!
show table status from database where name="tablename" //准确查看某个数据库中的某一表所使用的存储引擎
- 1
- 2
- 3
- 4
- 5
MySQL中常用的几种存储引擎:
MyISAM存储引擎:
存放的位置: MySQL如果使用MyISAM存储引擎,数据库文件类型就包括.frm、.MYD、.MYI,默认存放位置是C:\Documentsand Settings\All Users\Application Data\MySQL\MySQL Server 5.1\data
存放的方式: MyISAM 这种存储引擎不支持事务,不支持行级锁,只支持并发插入的表锁,主要用于高负载的select。
索引的方式: MyISAM也是使用B+tree索引但是和Innodb的在具体实现上有些不同。
该引擎基于ISAM数据库引擎,除了提供ISAM里所没有的索引和字段管理等大量功能,MyISAM还使用一种表格锁定的机制来优化多个并发的读写操作,但是需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间,否则碎片也会随之增加,最终影响数据访问性能。MyISAM还有一些有用的扩展,例如用来修复数据库文件的MyISAMChk工具和用来恢复浪费空间的 MyISAMPack工具。MyISAM强调了快速读取操作,主要用于高负载的select,这可能也是MySQL深受Web开发的主要原因:在Web开发中进行的大量数据操作都是读取操作,所以大多数虚拟主机提供商和Internet平台提供商(Internet Presence Provider,IPP)只允许使用MyISAM格式。
MyISAM类型的表支持三种不同的存储结构:静态型、动态型、压缩型。
静态型:指定义的表列的大小是固定(即不含有:xblob、xtext、varchar等长度可变的数据类型),这样MySQL就会自动使用静态MyISAM格式。使用静态格式的表的性能比较高,因为在维护和访问以预定格式存储数据时需要的开销很低;但这种高性能是以空间为代价换来的,因为在定义的时候是固定的,所以不管列中的值有多大,都会以最大值为准,占据了整个空间。
动态型:如果列(即使只有一列)定义为动态的(xblob, xtext, varchar等数据类型),这时MyISAM就自动使用动态型,虽然动态型的表占用了比静态型表较少的空间,但带来了性能的降低,因为如果某个字段的内容发生改变则其位置很可能需要移动,这样就会导致碎片的产生,随着数据变化的增多,碎片也随之增加,数据访问性能会随之降低。
对于因碎片增加而降低数据访问性这个问题,有两种解决办法:
a、尽可能使用静态数据类型;
b、经常使用optimize table table_name语句整理表的碎片,恢复由于表数据的更新和删除导致的空间丢失。如果存储引擎不支持 optimize table table_name则可以转储并 重新加载数据,这样也可以减少碎片;
压缩型:如果在数据库中创建在整个生命周期内只读的表,则应该使用MyISAM的压缩型表来减少空间的占用。
优缺点:MyISAM的优势在于占用空间小,处理速度快。缺点是不支持事务的完整性和并发性。
innoDB存储引擎
存储位置:MySQL如果使用InnoDB存储引擎,数据库文件类型就包括.frm、ibdata1、.ibd,存放位置有两个,.frm文件默认存放位置是C:\Documents and Settings\All Users\ApplicationData\MySQL\MySQL Server 5.1\data,ibdata1、.ibd文件默认存放位置是MySQL安装目录下的data文件夹。
innodb存储引擎的mysql表提供了事务,回滚以及系统崩溃修复能力和多版本迸发控制的事务的安全。
innodb支持自增长列(auto_increment),自增长列的值不能为空,如果在使用的时候为空的话怎会进行自动存现有的值开始增值,如果有但是比现在的还大,则就保存这个值。
innodb存储引擎支持外键(foreign key) ,外键所在的表称为子表而所依赖的表称为父表。
innodb存储引擎最重要的是支持事务,以及事务相关联功能。
innodb存储引擎支持mvcc的行级锁。
innodb存储引擎索引使用的是B+Tree
优缺点:InnoDB的优势在于提供了良好的事务处理、崩溃修复能力和并发控制。缺点是读写效率较差,占用的数据空间相对较大。
MEMORY存储引擎
memory存储引擎相比前面的一些存储引擎,有点不一样,其使用存储在内从中的数据来创建表,而且所有的数据也都存储在内存中。
每个基于memory存储引擎的表实际对应一个磁盘文件,该文件的文件名和表名是相同的,类型为.frm。该文件只存储表的结构,而其数据文件,都是存储在内存中,这样有利于对数据的快速处理,提高整个表的处理能力。
memory存储引擎默认使用哈希(HASH)索引,其速度比使用B-+Tree型要快,如果读者希望使用B树型,则在创建的时候可以引用。
memory存储引擎文件数据都存储在内存中,如果mysqld进程发生异常,重启或关闭机器这些数据都会消失。所以memory存储引擎中的表的生命周期很短,一般只使用一次。
ARCHIVE存储引擎
该存储引擎非常适合存储大量独立的、作为历史记录的数据。区别于InnoDB和MyISAM这两种引擎,ARCHIVE提供了压缩功能,拥有高效的插入速度,但是这种引擎不支持索引,所以查询性能较差一些。
四种存储引擎比较
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
MEMORY:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archiv
注意,同一个数据库也可以使用多种存储引擎的表。如果一个表要求比较高的事务处理,可以选择InnoDB。这个数据库中可以将查询要求比较高的表选择MyISAM存储。如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎。
二、InnoDB索引
B树
B-Tree 其实就是 B 树,很多人都会说成 B 减树,其实是错的,要注意。
B 树不要和二叉树混淆,B 树不是二叉树,而是一种自平衡树数据结构。 它维护有序数据并允许以对数时间进行搜索,顺序访问,插入和删除。B 树是二叉搜索树的一般化,因为 B 树的节点可以有两个以上的子节点。
与其他自平衡二进制搜索树不同,B 树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统,例如 mysql 的 InnoDB 引擎使用的数据结构就是 B 树的变形 B+ 树。
B 树是一种平衡的多分树,通常我们说 m 阶的 B 树,它必须满足如下条件:
- 每个节点最多只有 m 个子节点。
- 每个非叶子节点(除了根)具有至少 ⌈m/2⌉ 子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有 k 个子节点的非叶节点包含 k -1 个键。
- 所有叶子都出现在同一水平,没有任何信息(高度一致)。
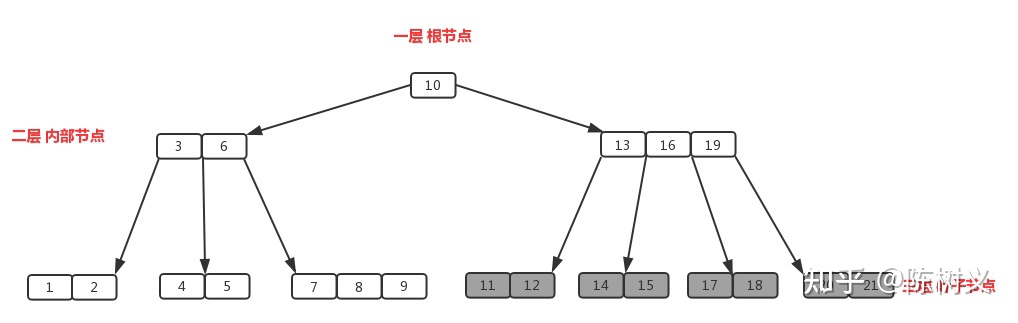
B 树的阶,指的是 B 树中节点的子节点数目的最大值。例如在上图的书中,「13,16,19」拥有的子节点数目最多,一共有四个子节点(灰色节点)。所以该 B 树的阶为 4,该树称为 4 阶 B 树。在实际应用中,B 树应用于 MongoDb 的索引。
B+树
B+ 树是应文件系统所需而产生的 B 树的变形树。B+ 树的特征:
- 有 m 个子树的中间节点包含有 m 个元素(B 树中是 k-1 个元素),每个元素不保存数据,只用来索引。
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。而 B 树的叶子节点并没有包括全部需要查找的信息。
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。而 B 树的非终节点也包含需要查找的有效信息。例如下图中的根节点 8 是左子树中最大的元素,15 是右子树中最大的元素。

与 B 树相比,B+ 树有着如下的好处:
- B+ 树的磁盘读写代价更低
B+ 树的内部结点并没有指向关键字具体信息的指针,所以其内部结点相对 B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,所以一次性读入内存中的需要查找的关键字也就越多。相对来说 IO 读写次数也就降低了,查找速度就更快了。
- B+ 树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以 B+ 树中任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。而对于 B 树来说,因为其每个节点都存具体的数据,因此其查询速度可能更快,但是却并不稳定。
- B+ 树便于范围查询(最重要的原因,范围查找是数据库的常态)
B 树在提高了 IO 性能的同时,并没有解决元素遍历效率低下的问题。为了解决这个问题,B+ 树应用而生。B+ 树只需要去遍历叶子节点就可以实现整棵树的遍历。在数据库中基于范围的查询是非常频繁的,因此 MySQL 的 Innodb 引擎就使用了 B+ 树作为其索引的数据结构。
B+树叶子结点有指针的原因
- 在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
InnoDB中的B+树索引
- 第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
- InnoDB建表要求必须要有主键,如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。这种索引叫做聚集索引
- 非聚集索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
三、索引使用策略及优化
-
索引一般加在经常查询、数据不经常变动的字段
-
不建议使用过长的字段作为主键
因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
-
使用与业务无关的自增字段作为主键
用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
-
索引不是越多越好,根据索引的选择性来判断
既然索引可以加快查询速度,那么是不是只要是查询语句需要,就建上索引?答案是否定的。因为索引虽然加快了查询速度,但索引也是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。一般两种情况下不建议建索引。第一种情况是表记录比较少,我个人的经验是以2000作为分界线。另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:Index Selectivity = Cardinality / #T 选择性越高的索引价值越大,这是由B+Tree的性质决定的。
-
前缀索引
有一种与索引选择性有关的索引优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。


