
- 1HTML静态网页成品作业(HTML+CSS)——原神介绍设计制作(4个页面)
- 25步搞定Android Studio无线调试_android studio 同一个局域网无法实现wifi调试
- 3鸿蒙浏览器是华为,鸿蒙javascript项目开发----华为轻量级运动手表
- 4数据中台的产生背景、核心理念、发展阶段_数据中台系统背景
- 5好玩的小程序
- 6springboot支持https请求
- 7MySQL是什么?它有什么优势?_云数据库mysql有什么具体优势
- 8架构师之路(16)定时任务的防重设计_java传统的定时任务同时请求数据库引起的脏数据问
- 9如何下载android studio的历史版本
- 10上海航芯 ACM32F030K8U7 带CAN的M0内核MCU简介_can lcd arm m0
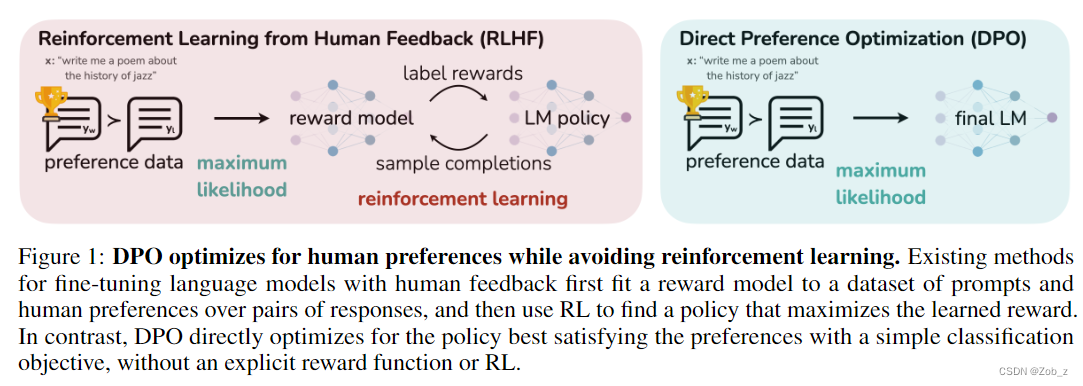
DPO(Direct Preference Optimization):LLM的直接偏好优化
赞
踩
DPO(Direct Preference Optimization):LLM的直接偏好优化
背景:
LLM经过无监督训练后,可以得到知识和理解能力,但是很难去控制他们的生成行为,并且从模型的广阔的知识和能力中选择符合人类偏好的回答或者行为是十分重要的!
目前常用人类对模型生成数据的反馈来进一步训练LM,对齐人类偏好;RLHF是其中的代表工作,先通过训练一个反映人类对生成回答偏好的reward model(RW),再通过强化学习**(PPO)来最大化预测的回报(reward),同时,施加KL限制(constraints)**避免模型偏离太远。
但是,RLHF存在一些不足的地方:
pipeline比较复杂,需要先训练一个reward model得到回报分数,再通过PPO强化学习最大化reward更新策略(模型参数),其中的PPO阶段,需要多个模型(actor&ref model& critic model& reward model),特别耗内存,并且在训练过程中,需要对策略进行采样,计算量巨大。
现在主流的LLM,比如chatglm、chinese-alpaca,主要进行了三步操作:
Step1:知识学习,CLM,大规模语料库上的预训练,本步的模型拥有续写的功能
Step2:知识表达,指令微调,在指令数据上进行微调,本步骤可以使用Lora等节省显存的方式,使模型可以听懂人类指令并进行回答的功能
Step3:偏好学习,RLHF或本文所提的DPO,可以让模型的输出更符合人类偏好,通俗说就是同样一句话,得调教的让模型输出人类喜欢的表达方式,好比高情商的人说话让人舒服
SFT:RLHF 通常开始于一个通用的预训练 LM。这个模型针对感兴趣的下游任务(比如对话,指令遵循和摘要生成),通过在高质量数据集上进行有监督学习(最大似然)的微调,来获得一个 SFT 模型
π
S
F
T
{\pi}^{SFT}
πSFT
奖励建模:在第二个阶段中,SFT 模型通过 prompts
x
x
x生成答案对
(
y
1
,
y
2
)
∼
π
S
F
T
(
y
∣
x
)
(y_1,y_2)\sim {\pi}^{SFT}(y|x)
(y1,y2)∼πSFT(y∣x)。这些答案接着会呈现给人类标注者,并让他们给出一个答案偏好,并表示为
y
w
≻
y
l
∣
x
y_{w}≻y_{l}|x
yw≻yl∣x。其中
y
w
y_{w}
yw 是更优的那一个答案。假设这些偏好是由某个潜在的奖励模型
r
∗
(
y
,
x
)
r^*(y,x)
r∗(y,x) 生成的。有多种方法可以建模偏好,Bradley-Terry(BT)模型是一个常见选择(在可以获得多个排序答案的情况下,Plackett-Luce 是更一般的排序模型)。BT 模型规定人类偏好分布
p
∗
p^*
p∗ 可以表示成:
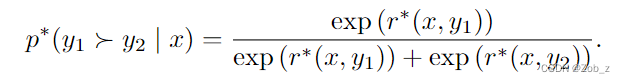
RL 微调:首先,最大化KL约束下的奖励函数公式(3),下面是具体的推导过程,其中的核心在于:本来的RL是最大化reward,通过取反变换,转换成最小化目标函数公式:
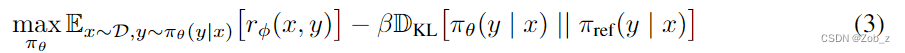
其中
β
\beta
β是控制与基本参考策略
π
r
e
f
{\pi}_{ref}
πref的偏差的参数,即初始SFT模型
π
S
F
T
{\pi}^{SFT}
πSFT。在实践中,语言模型策略
π
θ
{\pi}_{\theta}
πθ也被初始化为
π
S
F
T
{\pi}^{SFT}
πSFT。加入的这项约束非常重要,因为它需要防止策略模型过于偏离奖励模型(能准确预测的)的分布,同时保持生成结果多样性并避免模式坍塌到单一的高奖励答案。由于语言生成的离散性,因此目标是不可微的并且通常使用强化学习来优化。标准的奖励函数如下,并通过 PPO 来最大化。
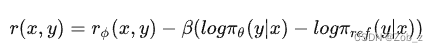
第二步,还是多多少少学习了一点知识,第三步则几乎不学知识,只学表达方式了。
RLHF太耗时耗力了,得提前训练好RewardModel,然后PPO阶段,得加载4个模型,2个推理,2个训练,实在是太不友好了。
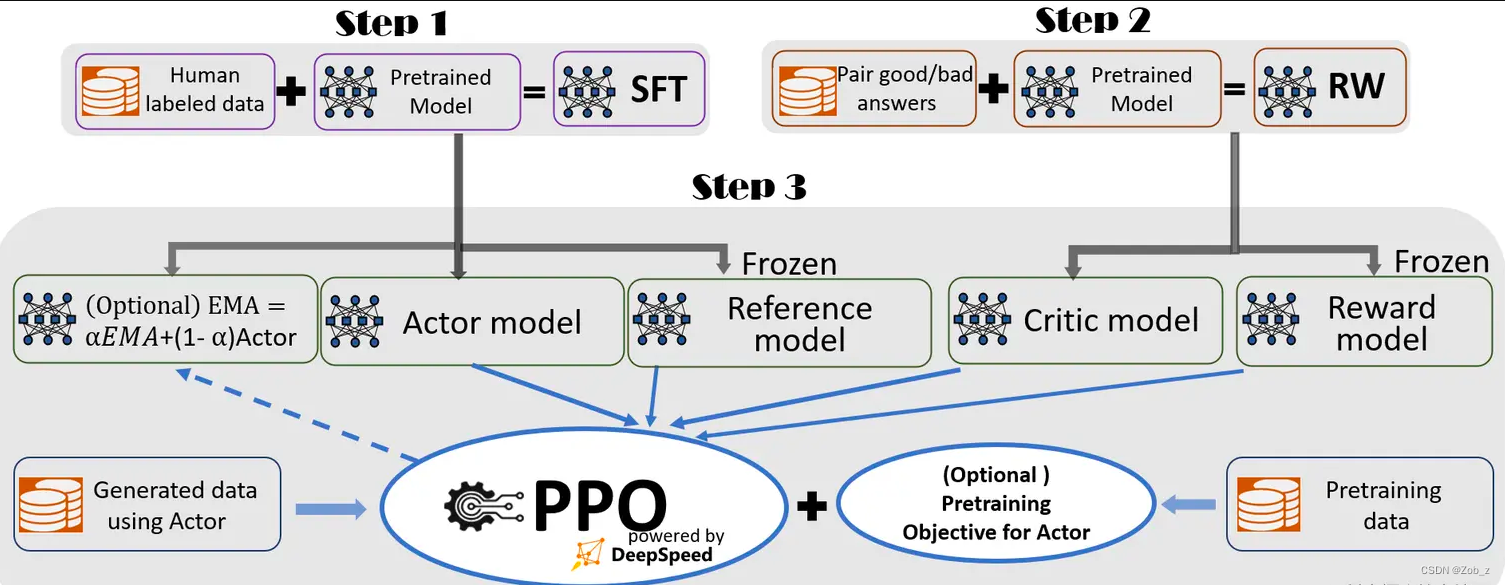
相比之下DPO就很友好,只需要加载2个模型,其中一个推理,另外一个训练,直接在偏好数据上进行训练即可:
如果可以访问一个从 p ∗ p^* p∗ 中采样的静态对比数据集 $D={x{(i)},y_w{(i)},y_l{(i)}}{N}_{i=1} $,那么我们可以通过最大似然估计来参数化奖励模型 r ϕ ( y , x ) r_\phi(y,x) rϕ(y,x)。将问题建模为二分类问题,我们可以使用负对数似然损失:
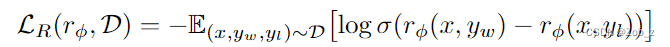
其中 σ \sigma σ 是逻辑函数。对于 LMs 来说, r ϕ ( y , x ) r_\phi(y,x) rϕ(y,x)通常初始化自 SFT 模型 π S F T ( y ∣ x ) {\pi}^{SFT}(y|x) πSFT(y∣x) ,并在最后一层 transformer 层后添加一个线性层以获得奖励值的标量预测。为了确保奖励函数具有较低的方差,之前的工作会对奖励进行归一化,比如对所有 x x x 有 E x , y ∼ D [ r ϕ ( y , x ) ] = 0 \mathbb{E}_{x,y\sim D}[r_\phi(y,x)]=0 Ex,y∼D[rϕ(y,x)]=0。
目标:
根据 Bradley-Terry 模型推导 DPO 目标
受到将强化学习算法应用于微调语言模型等大规模问题的挑战的激励,本文的目标是导出一种直接使用偏好进行策略优化的简单方法。与之前的 RLHF 方法(学习奖励然后通过 RL 对其进行优化)不同,本文的方法绕过奖励建模步骤,直接使用偏好数据优化语言模型。关键步骤是利用从奖励函数到最优策略的分析映射,这使我们能够将奖励函数的损失函数转换为策略的损失函数。这种变量变化方法使我们能够跳过显式奖励建模步骤,同时仍然在现有的人类偏好模型(例如 Bradley-Terry 模型)下进行优化。本质上,策略网络既代表了语言模型,也代表了奖励。
我们从与之前工作相同的 RL 目标开始,即式(3)中的一般奖励函数。根据之前的工作,容易得到这个公式中的 KL 约束的奖励最大化目标的最优解为:
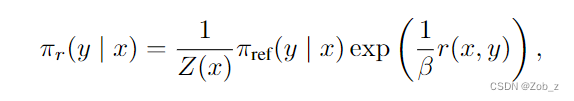
下面是推导过程:
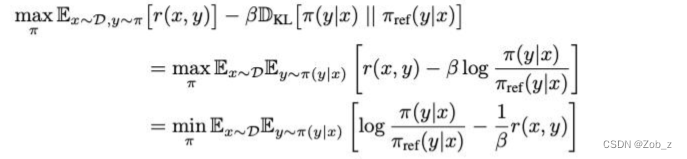
最后得到:
min π E x ∼ D E y ∼ π ( y ∣ x ) [ l o g π ( y ∣ x ) 1 Z ( x ) π r e f ( y ∣ x ) e x p ( 1 β r ( x , y ) ) − l o g Z ( x ) ] \min\limits_{\substack{\pi}}\mathbb{E}_{x\sim D}\mathbb{E}_{y\sim \pi(y|x)}\left[log\frac{\pi(y|x)}{\frac{1}{Z(x)}{\pi}_{ref}(y|x)exp(\frac{1}{\beta}r(x,y))}-logZ(x)\right] πminEx∼DEy∼π(y∣x)[logZ(x)1πref(y∣x)exp(β1r(x,y))π(y∣x)−logZ(x)]
其中 Z ( x ) Z(x) Z(x)是一个配分函数:
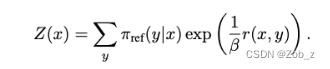
这个函数只与 x x x和参考策略 π r e f {\pi}_{ref} πref有关,而不依赖于策略 π {\pi} π。现在我们可以定义:
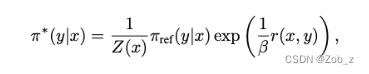
这是一个有效的概率分布,因为对于所有的 y y y都有 π ∗ ( y ∣ x ) > = 0 {\pi}^*{(y|x)}>=0 π∗(y∣x)>=0且 ∑ y π ∗ ( y ∣ x ) = 1 \sum_{y}{{\pi}^*{(y|x)}}=1 ∑yπ∗(y∣x)=1,由于 Z ( x ) Z(x) Z(x) 不是一个关于 y y y 的函数,因此我们把上式重新组织成最终目标:
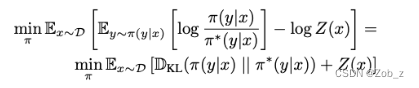
现在,由于 Z ( x ) Z(x) Z(x) 与 π {\pi} π无关,上式等价于最小化第一个 KL 项。根据吉布斯(Gibbs)不等式,当且只当两个分布相等时,KL 散度有最小值 0。 因此对于任意 x x x 我们可以得到最优解:
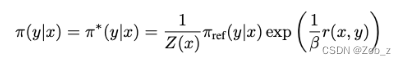
即使我们使用 ground-truth 奖励函数 r ∗ r^* r∗ 的最大似然估计(MLE)值 r ϕ r_\phi rϕ,估计配分函数 Z ( x ) Z(x) Z(x)依然十分困难,这使得这种表示方法在实践中难以利用。
因此对上式两边取对数,然后通过一些代数运算得到:
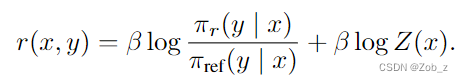
我们可以将这个重参数化应用于 ground-truth 的奖励函数 r ∗ r^* r∗和对应的最优模型 π ∗ \pi^* π∗。幸运的是,Bradley-Terry 模型只依赖于两个不同生成回答奖励的差异,即
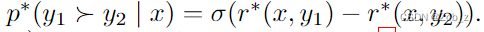
将上式对 r ∗ ( x , y ) r^*(x,y) r∗(x,y)的重参数化代入奖励建模公式的偏好模型,可以将配分函数消除,并将人类偏好概率表示为最优策略 π ∗ \pi^* π∗ 和参考策略 π r e f {\pi}_{ref} πref 的函数。于是,根据 Bradley-Terry 模型,最优的 RLHF 策略 π ∗ {\pi}^{*} π∗满足偏好模型:
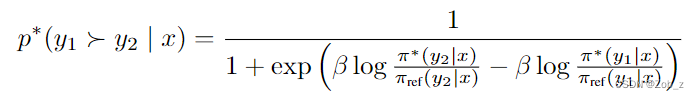
现在我们可以将人类偏好数据的概率表示为最优策略而不是奖励模型,这样我们就可以为参数化的策略 π θ {\pi}_{\theta} πθ 构建最大似然目标。类似于奖励建模方法,即负对数似然损失,策略目标变为:
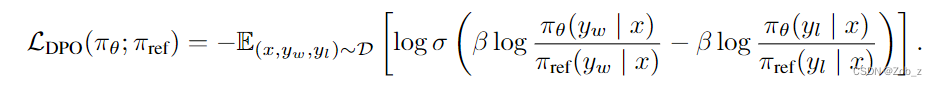
通过这种方式,我们同时跳过了显示的奖励建模步骤,并避免了强化学习的过程。此外,由于我们的过程等价于拟合重参数化的 Bradley-Terry 模型,因此它具有一些理论基础,比如在合适的偏好数据分布假设下的一致性。
为了从机制上理解 DPO ,分析损失函数的梯度有所助益。参数 θ \theta θ 相关的梯度可以写成:
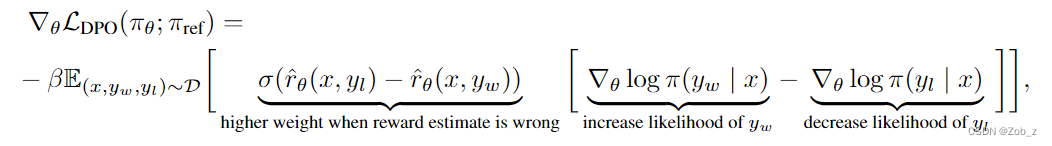
直观上,损失函数的梯度会增加生成更优回答 y w y_w yw的概率,降低非最优回答 y l y_l yl 的概率。重要的是,样本根据隐式奖励模型 r θ r_{\theta} rθ 对非首选回答打分的高低进行加权并通过 β \beta β 进行缩放,即隐式奖励模型对回答进行错误排序的程度,体现出 KL 约束的强度。我们的实验表明了这种加权的重要性,因为没有加权的朴素版本会导致语言模型的退化

这个过程有助于减小真实参考分布(不可知)和 DPO 实际使用的 π r e f \pi_{ref} πref之间的分布偏移。
评估:
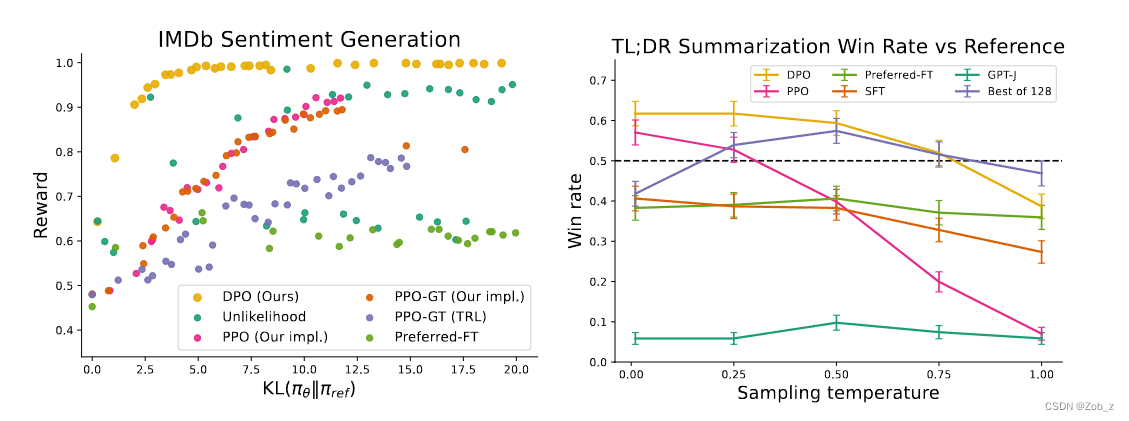
实验采用了两种不同的评估方法。为了分析每个算法在优化带约束的奖励最大化目标方面的效果,在受控情感生成 中,通过取得的奖励和与参考策略的 KL 散度的边界来评估每个算法;这个边界是可以计算的,因为我们可以访问到真实的奖励函数(一个情感分类器)。然而,在现实世界中,真实的奖励函数是未知的;因此,我们通过与基准策略的 胜率 来评估算法;在 摘要生成 和 单轮对话 中,我们使用 GPT-4 作为代理,分别评估摘要质量和回答有用性。对于摘要生成,使用测试集中的参考摘要作为基准;对于单轮对话,使用测试数据集中的优选回答作为基准。虽然现有的研究表明,语言模型可以比现有的评估指标更好地进行自动评估,但本文还是进行了一项人类研究(human study)以证明在评估中使用 GPT-4 的合理性。实验发现,GPT-4 的判断与人类之间存在很强的相关性,人类与 GPT-4 的一致性通常与多人标注一致率相似或更高。
结果:
传统 RLHF 中使用的 KL 约束奖励最大化目标会在限制优化策略偏离参考策略过远的同时,平衡对奖励的追求。因此,在比较算法时,我们必须同时考虑获得的奖励和 KL 差异;为了获得略高一点的奖励而让 KL 高得多并不可取。Figure 2 展示了在情绪实验中各种算法的奖励-KL边界。
基于 Llama v2 进行实验:
一个典型的 RLHF 流水线通常包含以下几个环节:
- 有监督微调 (supervised fine-tuning,SFT)
- 用偏好标签标注数据
- 基于偏好数据训练奖励模型
- RL 优化
TRL 库包含了所有这些环节所需的工具程序。而 DPO 训练直接消灭了奖励建模和 RL 这两个环节 (环节 3 和 4),直接根据标注好的偏好数据优化 DPO 目标。
使用 DPO,仍然需要执行环节 1,但仅需在 TRL 中向 DPOTrainer 提供环节 2 准备好的偏好数据,而不再需要环节 3 和 4。标注好的偏好数据需要遵循特定的格式,它是一个含有以下 3 个键的字典:
prompt: 即推理时输入给模型的提示chosen: 即针对给定提示的较优回答rejected: 即针对给定提示的较劣回答或非给定提示的回答
对于 stack-exchange preference 数据集,可以通过以下工具函数将数据集中的样本映射至上述字典格式并删除所有原始列:
def return_prompt_and_responses(samples) -> Dict[str, str, str]: return { "prompt": [ "Question: " + question + "\n\nAnswer: " for question in samples["question"] ], "chosen": samples["response_j"], *# rated better than k* "rejected": samples["response_k"], *# rated worse than j* } dataset = load_dataset( "lvwerra/stack-exchange-paired", split="train", data_dir="data/rl" ) original_columns = dataset.column_names dataset.map( return_prompt_and_responses, batched=True, remove_columns=original_columns )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
一旦有了排序数据集,DPO 损失其实本质上就是一种有监督损失,其经由参考模型获得隐式奖励。因此,从上层来看,DPOTrainer 需要我们输入待优化的基础模型以及参考模型:
dpo_trainer = DPOTrainer(
model, # 经 SFT 的基础模型
model_ref, # 一般为经 SFT 的基础模型的一个拷贝
beta=0.1, # DPO 的温度超参
train_dataset=dataset, # 上文准备好的数据集
tokenizer=tokenizer, # 分词器
args=training_args, # 训练参数,如: batch size, 学习率等
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中,超参 beta 是 DPO 损失的温度,通常在 0.1 到 0.5 之间。它控制了我们对参考模型的关注程度,beta 越小,我们就越忽略参考模型。对训练器初始化后,我们就可以简单调用以下方法,使用给定的 training_args 在给定数据集上进行训练了:
dpo_trainer.train()
- 1
有监督微调
先用 TRL 的 SFTTrainer 在 SFT 数据子集上使用 QLoRA 对 7B Llama v2 模型进行有监督微调:
# load the base model in 4-bit quantization bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16, ) base_model = AutoModelForCausalLM.from_pretrained( script_args.model_name, # "meta-llama/Llama-2-7b-hf" quantization_config=bnb_config, device_map={"": 0}, trust_remote_code=True, use_auth_token=True, ) base_model.config.use_cache = False # add LoRA layers on top of the quantized base model peft_config = LoraConfig( r=script_args.lora_r, lora_alpha=script_args.lora_alpha, lora_dropout=script_args.lora_dropout, target_modules=["q_proj", "v_proj"], bias="none", task_type="CAUSAL_LM", ) ... trainer = SFTTrainer( model=base_model, train_dataset=train_dataset, eval_dataset=eval_dataset, peft_config=peft_config, packing=True, max_seq_length=None, tokenizer=tokenizer, args=training_args, # HF Trainer arguments ) trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
DPO 训练
SFT 结束后,我们保存好生成的模型。接着,我们继续进行 DPO 训练,我们把 SFT 生成的模型作为 DPO 的基础模型和参考模型,并在上面生成的 stack-exchange preference 数据上,以 DPO 为目标函数训练模型。选择对模型进行 LoRa 微调,因此我们使用 Peft 的 AutoPeftModelForCausalLM 函数加载模型:
model = AutoPeftModelForCausalLM.from_pretrained( script_args.model_name_or_path, # location of saved SFT model low_cpu_mem_usage=True, torch_dtype=torch.float16, load_in_4bit=True, is_trainable=True, ) model_ref = AutoPeftModelForCausalLM.from_pretrained( script_args.model_name_or_path, # same model as the main one low_cpu_mem_usage=True, torch_dtype=torch.float16, load_in_4bit=True, ) ... dpo_trainer = DPOTrainer( model, model_ref, args=training_args, beta=script_args.beta, train_dataset=train_dataset, eval_dataset=eval_dataset, tokenizer=tokenizer, peft_config=peft_config, ) dpo_trainer.train() dpo_trainer.save_model()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
总结:
在通过 RL 优化人类衍生偏好时,一直以来的传统做法是使用一个辅助奖励模型来微调目标模型,以通过 RL 机制最大化目标模型所能获得的奖励。直观上,我们使用奖励模型向待优化模型提供反馈,以促使它多生成高奖励输出,少生成低奖励输出。同时,我们使用冻结的参考模型来确保输出偏差不会太大,且继续保持输出的多样性。这通常需要在目标函数设计时,除了奖励最大化目标外再添加一个相对于参考模型的 KL 惩罚项,这样做有助于防止模型学习作弊或钻营奖励模型。
DPO 绕过了建模奖励函数这一步,这源于一个关键洞见: 从奖励函数到最优 RL 策略的分析映射。这个映射直观地度量了给定奖励函数与给定偏好数据的匹配程度。有了它,作者就可与将基于奖励和参考模型的 RL 损失直接转换为仅基于参考模型的损失,从而直接在偏好数据上优化语言模型!因此,DPO 从寻找最小化 RLHF 损失的最佳方案开始,通过改变参量的方式推导出一个 仅需 参考模型的损失!
有了它,我们可以直接优化该似然目标,而不需要奖励模型或繁琐的强化学习优化过程。

