
- 1大模型: 提示词工程(prompt engineering)_大模型的提示词作用是什么
- 2手把手做一个公众号GPT智能客服【二】实现微信公众号回复(订阅送源码!)_微信公众号回复消息接入大模型
- 3[问答]-ARM文档中的†和‡的含义_是什么意思
- 4【Vue】创建vue项目 npm ERR! code CERT_HAS_EXPIRED npm ERR! errno CERT_HAS_EXPIRED
- 5数据挖掘入门项目二手交易车价格预测之特征工程
- 6全连接网络(FC)、前馈神经网络(BP)、多层感知机(MLP)、人工神经网络(ANN)指的是一个东西吗_全连接神经网络和前馈神经网络
- 7从62%到5%‼️找人降重算代写吗_人工降重属于代写吗
- 8Pytorch模型部署开发板所遇到的坑....._torch模型部署到开发板
- 9《Python+Kivy(App开发)从入门到实践》自学笔记:第三章 图形绘制目录及知识点概览_kivy从入门到实践pdf
- 10从0开始实现一个Auto-GPT在WSL2环境中的部署和运行_wsl2 gptfast
基于知识图谱的问答系统(KBQA)_基于知识图谱的问答系统的实现原理
赞
踩
最近因为工作原因暂时停止机器学习方面知识的学习,研究了一段KBQA。,下面是一个简单的关于中小学生需要掌握的诗词的demo,各位看官有兴趣的可以瞅瞅,欢迎来信一起交流。

1. 原理
KBQA简单讲就是将问题带入提前准备好的知识库寻求答案的一种基于知识库的问答系统。该问答系统可以解析输入的自然语言问句,主要运用REFO库的对象正则表达式匹配得到结果,然后利用对应的SPARQL查询语句,请求后台基于TDB知识谱图数据库的服务,最终得到我们想要的结果。
2. 流程
1.实体检测,获取问题的关键词,比如问题“李白写了哪些诗?”,那么首先必须找到李白,才可以进行下一步。
2.目的获取,一个问题,我们只获取了实体还不够,比如上面,只有李白,还要有目的,不然可能我是想问李白是哪个朝代的人,哪里的人等等,所以需要找到问题的真实目的。
3.关系预测,有了实体和目的,那么我们就需要在知识库里面寻找双方的关系,想办法联系起来。
4.查询构建,将处理好的三元组带入知识库搜索答案。
3. 知识图谱
1.介绍
知识图谱由google于2012年率先提出,其初衷是用以增强自家的搜索引擎的功能和提高搜索结果质量,使得用户无需通过点击多个连接就可以获取结构化的搜索结果,并且提供一定的推理功能。这里我还是用《将进酒》这首诗举个例子,很多人看到《将进酒》,估计第一时间想不到这是哪个年代的诗歌,但是不妨看看作者,李白,很多人对李白就比较耳熟能详了,那么就来了,很多人都知道李白是唐朝人(这里假设没人不知道哈),那么自然而然就知道《将进酒》这首诗写在唐朝了。说了这些,我们发现,如果知识库里面有这些信息,那么就很容易找到答案。如果我们再多加一些相关属性,就可以构成一张简单的知识图了,如下图,具体的我就不描述了,大家可以看看知识图谱介绍这篇文章,讲述的非常明白,我就不在关公门前耍大刀了。

2. 数据格式
在知识图谱中,数据一般以RDF形式的三元组表示。
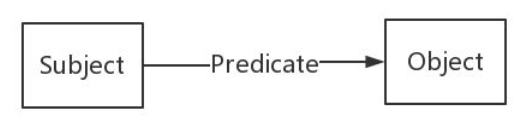
RDF(Resource Description Framework)即资源描述框架,其本质是一个数据模型。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF形式上表示为SPO三元组,知识图谱中我们也称其为一条知识。RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。如下图所示:
RDF数据集方式主要有以下几种,主要使用Turtle。
1、RDF/XML,用XML的格式来表示RDF数据。之所以提出这个方法,是因为XML的技术比较成熟,有许多现成的工具来存储和解析XML。然而,对于RDF来说,XML的格式太冗长,也不便于阅读,通常我们不会使用这种方式来处理RDF数据。
2、N-Triples,即用多个三元组来表示RDF数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理。开放领域知识图谱DBpedia通常是用这种格式来发布数据的。
3、Turtle, 应该是使用得最多的一种RDF序列化方式了。它比RDF/XML紧凑,且可读性比N-Triples好。
4、RDFa, 是HTML5的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等。也就是说,将RDF数据嵌入到网页中,搜索引擎能够更好的解析非结构化页面,获取一些有用的结构化信息。
5、JSON-LD,用键值对的方式来存储RDF数据。
但是RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性,这个时候就有人提出RDFS和OWL这两种技术或者说模式语言/本体语言来解决了RDF表达能力有限的困境,详细介绍参考知识图谱基础之RDF,RDFS与OWL。后面的实例分析就是使用OWL来存储数据。
4. 实例分析
知识图谱这个专栏讲的非常详细,我也是参考这位前辈的专栏实现的小demo,所以我就不在这里花过多的时间描述相关方面的知识了,避免理解错误,误导大家。下面就直接开始我自己的实例。本demo实现是为了展示知识图谱,所以将数据分开,其实也可以直接将诗词名、作者、朝代、诗词内容放在一起,全部作为属性,不需要在SQL中创建多个数据表,所以希望大家不要觉得麻烦,感兴趣的可以使用一张表试着做一下。
-
数据准备
数据是中小学必背诗词,其中信息有诗词名、作者、朝代、诗词内容。
作者信息:姓名、朝代
诗词信息:诗词名、诗词内容
诗句使用scrapy在百度上爬取,如果想自己动手的,可以参考一下前面的博客scrapy学习(一):scrapy框架(爬古诗词)。 -
数据建模
这步是非必须的,但是为了后面数据映射更容易理解,我还是在这里简述一下。构建数据结构一般使用工具protégé,构建过程参考本体建模,根据我们自己的功能需要,创建三个类Poem(诗词)、Poet(诗人)、Verse(诗句):
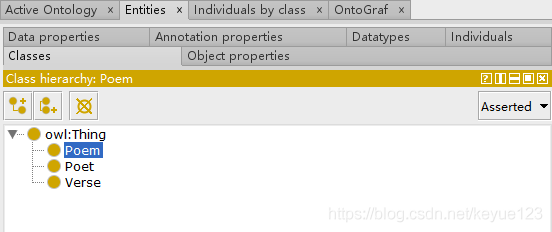

上面的类和推理都创建好了,接下来就需要定义每个类里面的属性:poemContent(诗词内容)、poemName(诗词名)、poetDynasty(诗人朝代)、poetName(诗人名)、sentenceId(诗句ID)、verseId(诗词ID)、sentenceContent(诗句内容)、verseLen(诗词长度)。同样右下角也需要定义属性,Domain为属于哪个类,Range与前面关系的Domain有区别,这里表示的是数据类型。

类、关系、属性都定义好之后,就组成了一个简单的数据模型,点击"Window–>Tabs–>OntoGraf",就可以在protégé中很明了的看出相互之间的关系。

将我们构建好的关系导出备用,导出格式如下,文件名随意,我这里取为poem_kbqa.owl

- 数据映射
现在数据有了,关系也有了,如何将两者联系起来呢,我们以mysql中的诗词名为例,将poem这个表映射到我们在protege中定义的Peom类上,poem title映射到poemName上。
map:poem a d2rq:ClassMap;
d2rq:dataStorage map:database;
d2rq:uriPattern "poem/@@poem.poem_id@@";
d2rq:class :Poem; # 类名
d2rq:classDefinitionLabel "poem"; # sql数据表
.
map:poem_title a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:poem;
d2rq:property :poemName;
d2rq:propertyDefinitionLabel "poem title";
d2rq:column "poem.title";
.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
很多人看到上面的语句就懵逼了,但是别急,这可以直接通过D2RQ来实现,D2RQ是以RDF图的方式访问关系数据库的,将RDF的查询等操作翻译成SQL语句,最终在TDB上实现对应操作。用户可以在数据库自动生成的映射文件上修改,从而将数据映射到自己的本体上。
进入D2RQ目录,执行下列语句生成映射文件,我这里取名poem_demo_mapping.ttl,大家自己随意就好。
$ ./generate-mapping -u root -p 123456 -o poem_demo_mapping.ttl jdbc:mysql://127.0.0.1:3306/poem_kbqa_demo?serverTimezone=UTC
# Table poem #Poem类 map:poem a d2rq:ClassMap; d2rq:dataStorage map:database; d2rq:uriPattern "poem/@@poem.poem_id@@"; d2rq:class vocab:poem; d2rq:classDefinitionLabel "poem"; . map:poem__label a d2rq:PropertyBridge; d2rq:belongsToClassMap map:poem; d2rq:property rdfs:label; d2rq:pattern "poem #@@poem.poem_id@@"; . map:poem_poem_id a d2rq:PropertyBridge; d2rq:belongsToClassMap map:poem; d2rq:property vocab:poem_poem_id; d2rq:propertyDefinitionLabel "poem poem_id"; d2rq:column "poem.poem_id"; d2rq:datatype xsd:integer; . map:poem_title a d2rq:PropertyBridge; d2rq:belongsToClassMap map:poem; d2rq:property vocab:poem_title; d2rq:propertyDefinitionLabel "poem title"; d2rq:column "poem.title"; . map:poem_content a d2rq:PropertyBridge; d2rq:belongsToClassMap map:poem; d2rq:property vocab:poem_content; d2rq:propertyDefinitionLabel "poem content"; d2rq:column "poem.content"; .

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
belongsToClassMap为类名,property为属性名,propertyDefinitionLabel为数据描述,column数据表的标签。这里我们发现这和我们上面数据建模的关系很相似,belongsToClassMap–>domain,这里将上面的映射文件修改成我们在数据建模里使用的定义,结合关系图,这样看起来更明白。
# Table poem map:poem a d2rq:ClassMap; d2rq:dataStorage map:database; d2rq:uriPattern "poem/@@poem.poem_id@@"; d2rq:class :Poem; d2rq:classDefinitionLabel "poem"; . map:poem_title a d2rq:PropertyBridge; d2rq:belongsToClassMap map:poem; d2rq:property :poemName; d2rq:propertyDefinitionLabel "poem title"; d2rq:column "poem.title"; . map:poem_content a d2rq:PropertyBridge; d2rq:belongsToClassMap map:poem; d2rq:property :poemContent; d2rq:propertyDefinitionLabel "poem content"; d2rq:column "poem.content"; .
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 数据查询
数据映射完成后,我们可以类似使用SQL查询关系数据库一样使用SPARQL查询RDF格式的数据。
SPARQL查询是基于图匹配的思想。比如我想查询《将进酒》的内容,那么需要将查询语句与RDF图进行匹配,找到符合该匹配模式的所有子图,最后得到变量的值。SPARQL查询分为三个步骤:
1. 构建查询图模式,表现形式就是带有变量的RDF。
2. 匹配,匹配到符合指定图模式的子图。
3. 绑定,将结果绑定到查询图模式对应的变量上。
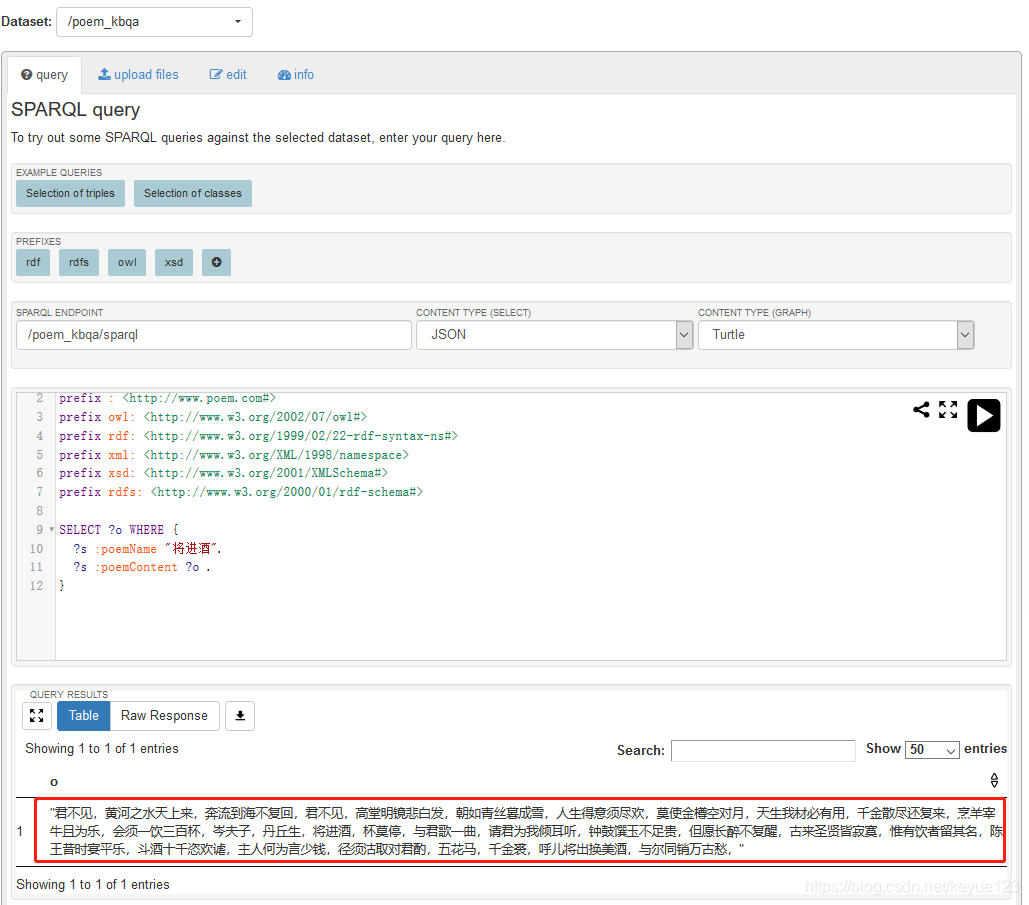
由上面分析,查询《将进酒》的内容对应的SPARQL查询语言为:
PREFIX : <http://www.poem.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX vocab: <http://localhost:2020/resource/vocab/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX map: <http://localhost:2020/resource/#>
PREFIX db: <http://localhost:2020/resource/>
SELECT ?o WHERE {
?s :poemName '将进酒'.
?s :poemContent ?o.
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
SELECT指定我们要查询的变量。这里需要查询内容,用?o代替。
WHERE指定我们要查询的图模式。意思上和SQL的WHERE没有区别。
?s、?o为三元组的实体表示。
:poemContent、:poemName为关系
最终查询出来的结果为:
"君不见,黄河之水天上来,奔流到海不复回,君不见,高堂明镜悲白发,朝如青丝暮成雪,人生得意须尽欢,莫使金樽空对月,天生我材必有用,千金散尽还复来,烹羊宰牛且为乐,会须一饮三百杯,岑夫子,丹丘生,将进酒,杯莫停,与君歌一曲,请君为我倾耳听,钟鼓馔玉不足贵,但愿长醉不复醒,古来圣贤皆寂寞,惟有饮者留其名,陈王昔时宴平乐,斗酒十千恣欢谑,主人何为言少钱,径须沽取对君酌,五花马,千金裘,呼儿将出换美酒,与尔同销万古愁,"- 查询实践
上一章简单讲了一下SPARQL查询的语句,下面我们就来实际操作一下,这里讲解两种方式:
1.利用D2RQ开启SPARQL endpoint服务
2.利用Apache jena开启SPARQL endpoint服务 - D2RQ
进入d2rq目录,使用下面的命令启动D2R Server:
$ ./d2r-server.bat poem_demo_mapping.ttl


from SPARQLWrapper import SPARQLWrapper, JSON sparql = SPARQLWrapper("http://localhost:2020/sparql") sparql.setQuery(""" PREFIX : <http://www.poem.com#> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX vocab: <http://localhost:2020/resource/vocab/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX map: <http://localhost:2020/resource/#> PREFIX db: <http://localhost:2020/resource/> SELECT ?o WHERE { ?s :poemName '将进酒'. ?s :poemContent ?o. } """) sparql.setReturnFormat(JSON) results = sparql.query().convert() for result in results["results"]["bindings"]: for x in results["head"]["vars"]: print(result[x]["value"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
最终查询出来的结果为:
"君不见,黄河之水天上来,奔流到海不复回,君不见,高堂明镜悲白发,朝如青丝暮成雪,人生得意须尽欢,莫使金樽空对月,天生我材必有用,千金散尽还复来,烹羊宰牛且为乐,会须一饮三百杯,岑夫子,丹丘生,将进酒,杯莫停,与君歌一曲,请君为我倾耳听,钟鼓馔玉不足贵,但愿长醉不复醒,古来圣贤皆寂寞,惟有饮者留其名,陈王昔时宴平乐,斗酒十千恣欢谑,主人何为言少钱,径须沽取对君酌,五花马,千金裘,呼儿将出换美酒,与尔同销万古愁,"- Apache jena
Apache Jena是一个开源的Java语义网框架,用于构建语义网和链接数据应用,是使用最广泛、文档最全、社区最活跃的一个开源语义网框架。我们会用到的组件有:TDB、Fuseki。- TDB是Apache Jena用于存储RDF的组件,是属于存储层面的技术。在单机情况下,它能够提供非常高的RDF存储性能。
- Apache Jena提供了RDFS、OWL和通用规则推理机。其实Apache Jena的RDFS和OWL推理机也是通过Apache Jena自身的通用规则推理机实现的。
- Fuseki是Apache Jena提供的SPARQL服务器,也就是SPARQL endpoint。其提供了四种运行模式:单机运行、作为系统的一个服务运行、作为web应用运行或者作为一个嵌入式服务器运行。
tdb支持RDF数据,所以需要讲我们的映射文件转为RDF文件。进入D2RQ目录:
$./dump-rdf.bat -o poem_kbqa.nt poem_demo_mapping.ttl poem_demo_mapping.ttl是建模后的映射文件。其支持导出的RDF格式有“TURTLE”, “RDF/XML”, “RDF/XML-ABBREV”, “N3”, 和“N-TRIPLE”。“N-TRIPLE”是默认的输出格式。poem_kbqa.nt就是我们生成的RDF文件。
tdb数据存放,进入apache-jena\bat目录下:
$.\tdbloader.bat --loc="C:\KBQA\apache-jena\tdb" "C:\d2rq-0.8.1\poem_kbqa.nt" --loc为数据存放路径,poem_kbqa.nt为RDF文件。
进入入Fuseki文件夹,运行fuseki-server.bat,然后退出。程序会为我们在当前目录自动创建run文件夹。将我们前面在数据建模时产生的文件poem_kbqa.owl移动到run文件夹下的databases文件夹中,并将owl后缀名改为ttl。在run文件夹下的configuration中,我们创建名为fuseki_conf.ttl的文本文件(取名随意),加入如下内容:
@prefix : <http://base/#> . @prefix tdb: <http://jena.hpl.hp.com/2008/tdb#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix fuseki: <http://jena.apache.org/fuseki#> . <#service3> rdf:type fuseki:Service ; fuseki:name "poem_kbqa" ; # RDF文件表 fuseki:serviceQuery "sparql" ; # SPARQL query service fuseki:dataset <#dataset> ; . <#dataset> rdf:type tdb:DatasetTDB ; tdb:location "C:/KBQA/apache-jena/tdb" ; # tdb数据路径 # Query timeout on this dataset (1s, 1000 milliseconds) ja:context [ ja:cxtName "arq:queryTimeout" ; ja:cxtValue "1000" ] ; # Make the default graph be the union of all named graphs. ## tdb:unionDefaultGraph true ; .
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
再次执行命令:
$ ./fuseki-server.bat
关于jena-fuseki SPARQL query版本问题的解决方案
默认端口是 3030,在浏览器输入“http://127.0.0.1:3030/”, 可以看到如下界面。
实践篇(四):Apache jena SPARQL endpoint及推理这里讲述了规则推理,个人觉得可以不使用,直接利用语句推理即可,各位看官根据自己的喜好来决定。
- KBQA实践
前面讲了这么多理论知识,现在就真是开始我们文章开头的demo。此demo是利用正则表达式来做语义解析。我们需要使用结巴分词完成初步的自然语言处理(分词、实体识别),然后利用支持词级别正则匹配的库来完成后续的语义匹配。
分词和实体识别我们用jieba来完成。为了防止分词错误,我这里将所有的诗人、诗名、诗句提出来作为扩展词并标注词性。分词结束后,可以使用REfO来完成语义匹配。匹配成功后,将其其对应的我们预先编写的SPARQL模板,再向Fuseki服务器发送查询,得到最终结果。
感兴趣的朋友可以去 基于知识图谱的问答系统获取源码,自己试试效果,在跑demo之前,根据代码中是使用D2RQ还是Fuseki启动对应服务。
5. 总结
使用知识图谱,优缺点同样明显,在推理和关系上非常方便,但是如果在实际项目中使用,如果数据有更新,那么就需要重新修改数据库和映射,需要重新走一遍全部流程,反而麻烦,所以下篇博客我会换种方式再次实现一次相同效果的demo。
本博客是根据知识图谱-给AI装个大脑模拟写出来的,在这里非常感谢该博主的无私分享。如果各位看官发现博客中有什么不对的,或者跟自己想法不一样的,可以留信探讨一下,纯属个人观点,不喜勿喷。

