
- 1【论文阅读】2021中国法研杯司法考试数据集研究(CAIL2021)_法研杯2021刑期预测数据集
- 2python的dict理解_对dict项目的理解与支撑思路
- 3StableDiffusion下载部署及相关参数介绍_stable diffusion放大算法下载
- 4不会代码没有Key如何使用中科院学术专用版 ChatGPT的方法(内附免费使用ChatGPT plus网址和论文润色的指令模板)_中科院chatgpt怎么用
- 5分享一个格式化大模型输出的prompt,便于做答案对比_让大模型输出表格,然后填空,怎样提问效果会好
- 6dqn 应用案例_深度强化学习在智能对话上的应用(附实例)
- 7Linux环境使用VSCode调试简单C++代码_linux vscode c++
- 8OpenCV 4基础篇| OpenCV图像的拼接_opencv 拼接
- 9YOLOv4阅读笔记(附思维导图)!YOLOv4: Optimal Speed and Accuracy of Object Detection_yolo efficientnet
- 10保姆级教程!安利一款Kali Linux 安装 + 获取 root 权限 + 远程访问!_kali linux下载
AIGC实战——Transformer模型
赞
踩
AIGC实战——Transformer模型
0. 前言
我们在 GPT (Generative Pre-trained Transformer) 一节所构建的 GPT 模型是一个解码器 Transformer,它逐字符地生成文本字符串,并使用因果掩码只关注输入字符串中的前一个单词。另一些编码器 Transformer,不使用因果掩码,而是关注整个输入字符串以提取有意义的上下文表示。对于一些其他任务,如语言翻译,可以使用编码器-解码器 Transformer,将一个文本字符串翻译为另一个文本字符串,这类模型包含编码器 Transformer 块和解码器 Transformer 块。下表总结了三种类型的 Transformer 模型,其中列出了每种架构的典型模型和用途。
| 类型 | 典型模型 | 应用 |
|---|---|---|
| Encoder | BERT | 文本分类,命名实体识别,抽取式问答 |
| Encoder-Decoder | T5 | 翻译,问答 |
| Decoder | GPT-3 | 文本生成 |
编码器 Transformer 的一个经典模型是 Google 开发的双向编码器自注意力转换 (Bidirectional Encoder Representations from Transformers, BERT)模型,该模型在所有层中使用给定缺失单词前后上下文,来预测文本中的缺失单词。
编码器 Transformer 通常用于需要全面理解输入的任务,例如文本分类和命名实体识别等。
接下来,我们将介绍编码器-解码器 Transformer 的工作原理,并介绍 OpenAI 发布的专门为对话应用设计的 ChatGPT 模型。
1. T5
T5 模型是 Google 提出的使用编码器-解码器结构的 Transformer 模型。该模型将一系列任务重构为文本到文本的框架,包括翻译、句子相似性和文档摘要等。

T5 模型的架构与原始 Transformer 论文中使用的编码器-解码器架构非常相似,如下图所示。主要区别在于 T5 模型是在大规模(包括大约 750G 的数据量)的文本语料库 (Colossal Clean Crawled Corpus,C4) 上进行训练,而原始 Transformer 论文仅专注于语言翻译,因此只使用了 1.4GB 的英汉对应文本对进行训练。

在上图中,可以看到通过堆叠 Transformer 块和位置嵌入来捕捉输入序列的顺序。此模型与 GPT 模型之间的关键区别如下:
- 左侧是为一组编码器
Transformer块,用于对待翻译的序列进行编码。需要注意的是,注意力层上没有应用因果掩码,这是因为我们不需要生成文本来扩展待翻译的序列,只需要学习整个序列的特征表示,以供解码器使用。因此,编码器中的注意力层可以完全不受掩码限制,以捕捉单词之间的所有交叉依赖关系,无论其顺序如何 - 右侧是一组解码器
Transformer块,用于生成翻译文本。初始的注意力层的键、值和查询来自同一输入(称为自引用),并且使用因果掩码来确保将来的符号信息不泄漏到当前要预测的词中。然后,后续的注意力层从编码器中提取键和值,只传递解码器本身的查询,这称为交叉引用注意力,意味着解码器可以关注需要翻译的输入序列的编码器表示
交叉引用注意力如下图所示。解码器层中的两个注意力头能够共同提供正确的德语翻译,以表示 the 这个词在街道上下文中的含义。在德语中,根据名词的性别有三个定冠词 (der、die、das),但 Transformer 之所以能够选择 die,是因为一个注意力头能够关注到街道这个词,而另一个注意力头关注的是要翻译的词 (the)。

2. GPT-3 和 GPT-4
自 2018 年发布 GPT 以来,OpenAI 已经发布了多个对原始模型进行改进的更新版本。
| 模型 | 时间 | 网络层数 | 注意力头数 | 单词嵌入长度 | 上下文窗口大小 | 参数量 | 训练数据集 |
|---|---|---|---|---|---|---|---|
| GPT | 2018 | 12 | 12 | 768 | 512 | 120000000 | BookCorpus (4.85GB) |
| GPT-2 | 2019 | 48 | 48 | 1600 | 1024 | 1500000000 | WebText (40GB) |
| GPT-3 | 2020 | 96 | 96 | 12888 | 2048 | 175000000000 | CommonCrawl, WebText, English Wikipedia, book corpora (570GB) |
| GPT-4 | 2023 | - | - | - | - | - | - |
GPT-3 的模型架构与原始 GPT 模型相似,只是规模更大,训练数据更多。关于 GPT-4,OpenAI 尚未公开发布有关该模型结构和规模的详细信息,但它能够接受图像作为输入,因此是一个多模态模型。GPT-3 和 GPT-4 的模型权重并未开源,但可以通过商业工具或 API 使用这些模型。
GPT-3 还可以针对自己的训练数据进行微调,可以通过提供多个样本,以更新网络的权重,适应特定类型的输入。在多数情况下,这并不必要,因为 GPT-3 只需在输入提示 (prompt) 中提供一些样本就可以告诉它如何对特定类型的输入提示做出反应(称为少样本学习,few-shot learning)。微调的优势是无需每次输入提示时都提供这些样本,从长远来看可以节省成本。
GPT 等语言模型的规模非常易于扩展,包括模型权重数量和数据集大小。目前仍然尚未达到大型语言模型性能的上限,可以通过尝试使用更大的模型和数据集来实现更多可能性。
3. ChatGPT
在 GPT-4 发布的前几个月,OpenAI 推出了 ChatGPT,此工具允许用户通过对话界面与大型语言模型进行互动交流。下图展示了一个 ChatGPT 示例对话,可以看到,机器能够记住对话的上下文信息,并理解第二个问题中提到的"注意力机制"是指 Transformer 中的注意力机制,而不是指人的注意力。

虽然,ChatGPT 并未开源,但在 ChatGPT 的官方博客文章中了解到,它使用了人类反馈强化学习 (Reinforcement Learning From Human Feedback, RLHF)的技术来微调 GPT-3.5 模型。
ChatGPT 的训练过程如下:
- 监督微调 (
Supervised Fine-tuning):收集人类的对话输入(提示)和期望输出的示例数据集。使用监督学习来微调底层语言模型 (GPT-3.5) - 奖励模型 (
Reward Modeling):向标注人员展示一些提示示例和模型生成的多个输出,并要求他们对输出从最佳到最差进行排序。训练奖励模型,该模型可以根据给定对话历史预测每个输出的得分 - 强化学习 (
Reinforcement Learning):将对话视为强化学习环境,其中策略是底层语言模型,从第一步微调模型开始初始化。给定当前状态(对话历史),策略输出一个动作(一系列符号),该动作由在第二步训练的奖励模型评分。然后,通过调整语言模型的权重,使用强化学习算法——近似策略优化算法 (Proximal Policy Optimization,PPO),以最大化奖励
RLHF 的过程如下图所示。
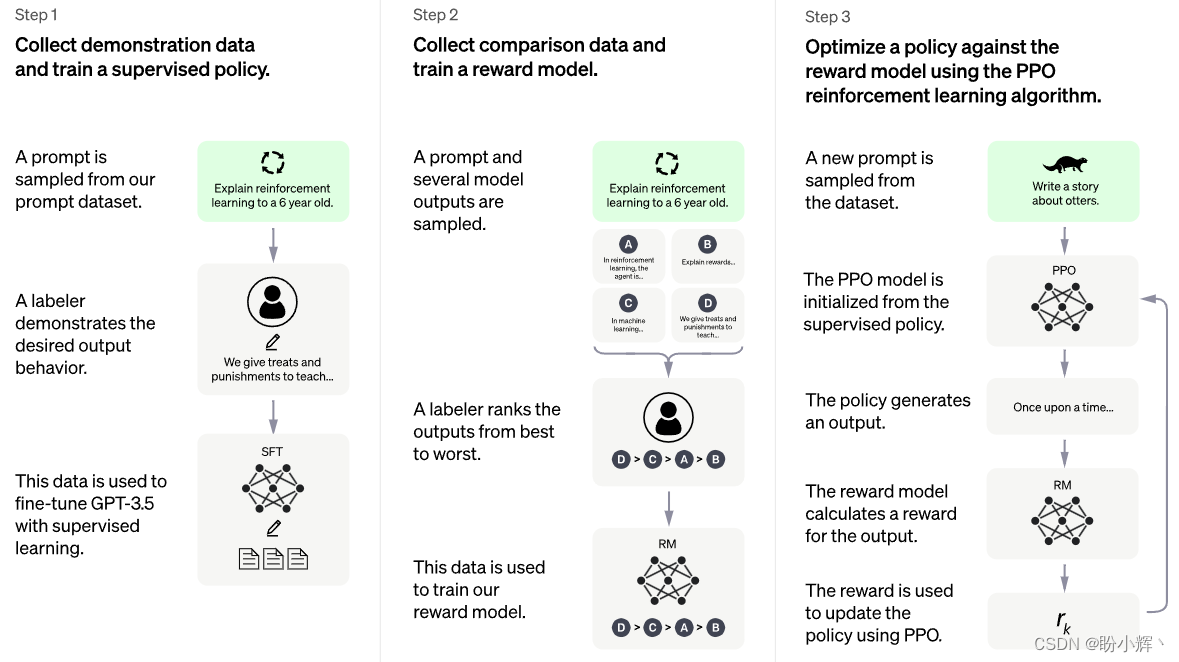
虽然 ChatGPT 仍然有许多限制,但展示了 Transformer 如何构建生成模型,生成复杂、新颖的输出。类似 ChatGPT 这样的模型充分证明了人工智能的强大潜力以及其变革性影响。
基于 AI 的通信和交互将继续快速发展,类似 Visual ChatGPT 这样的项目正在将 ChatGPT 的语言能力与 Stable Diffusion 等视觉模型相结合,使用户不仅可以通过文本与 ChatGPT 的交互,还可以使用图像进行交互,融合语言和视觉功能的人工智能模型,有望开启人机交互新时代。
小结
本节中,介绍了三类 Transformer 模型(编码器、解码器和编码器-解码器)及其应用,最后,还介绍了其他大型语言模型(如 Google 的 T5 和 OpenAI 的 ChatGPT )的结构和训练过程。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)
AIGC实战——归一化流模型(Normalizing Flow Model)
AIGC实战——能量模型(Energy-Based Model)
AIGC实战——扩散模型(Diffusion Model)
AIGC实战——GPT(Generative Pre-trained Transformer)

