- 1通过pycharm创建Django新项目_pycharm创建django app
- 2GitHub的原理及应用详解(一)
- 3word中装订线位置_Word教程:文档”双面打印“全攻略,解决打印难题!
- 4使用SwitchHosts和GitHub520自动更新 github.com的hosts_switchhosts 自动更新google地址
- 5初阶数据结构之双向链表详解
- 6Android Studio 解决编译报错 Could not download aapt2-windows.jar
- 7堆排序
- 8二分查找最坏查找次数_快速入门二分查找
- 9NLP学习笔记(四) Seq2Seq基本介绍_seq2seq模型说的时间步是什么意思
- 10初学者必须弄懂的一些基本FPGA设计概念(1)_fpga 设计
第6章 Elasticsearch,分布式搜索引擎_elasticsearch6 9200
赞
踩
6.1 Elasticsearch入门


https://www.elastic.co
- 6.0之后索引对应表,文档对应行,字段对应列
# 6.0 之前
ES索引、类型、文档、字段和MySQL中的 数据库、表、行、列相对应。
ES中文档的数据通常采用的是JSON,JSON中的每一种属性叫字段。
但是在 ES6.0 之后的版本当中,这些关系逐渐要发生变化,主要集中在前两个部分,主要是它想废弃类型的这个概念,那么谁对应表呢:索引。所以,6.0 之后一个索引对应一张表,文档还是对应行,字段还是对应列。6.0 之后仍保留了类型,只不过类型一个固定的单词,而不是表名了,7.0之后就彻底废弃掉了。
- 1
- 2
- 3
- 4
- 5
-
集群:一台或多台ES服务器组合在一起就是一个集群
-
节点:集群当中的每一台服务器称为节点
-
分片:一个索引也就是一个表,分片指的是对索引进一步的划分,一个索引在存的时候可以拆分成多个分片进
行存储,这样的话并发能力就提高了。
-
副本:副本是对分片的备份,一个分片可以包含多个副本,有了备份以后,万一说某一个副本数据丢了,挂
了,那么还有其他的备份,这样的话提高系统的可用性。
安装ES
https://www.elastic.co/cn/elasticsearch/
将下载好的压缩包解压缩
解压好之后我们需要稍微改一下它的配置
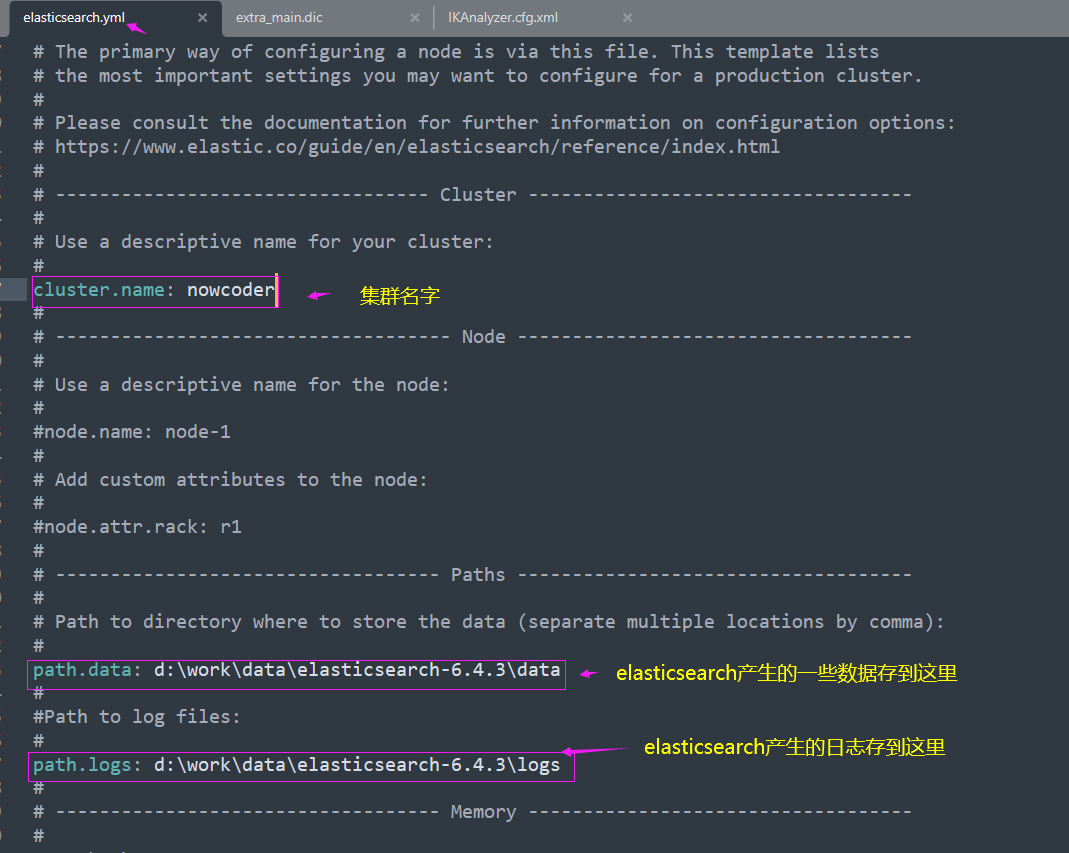
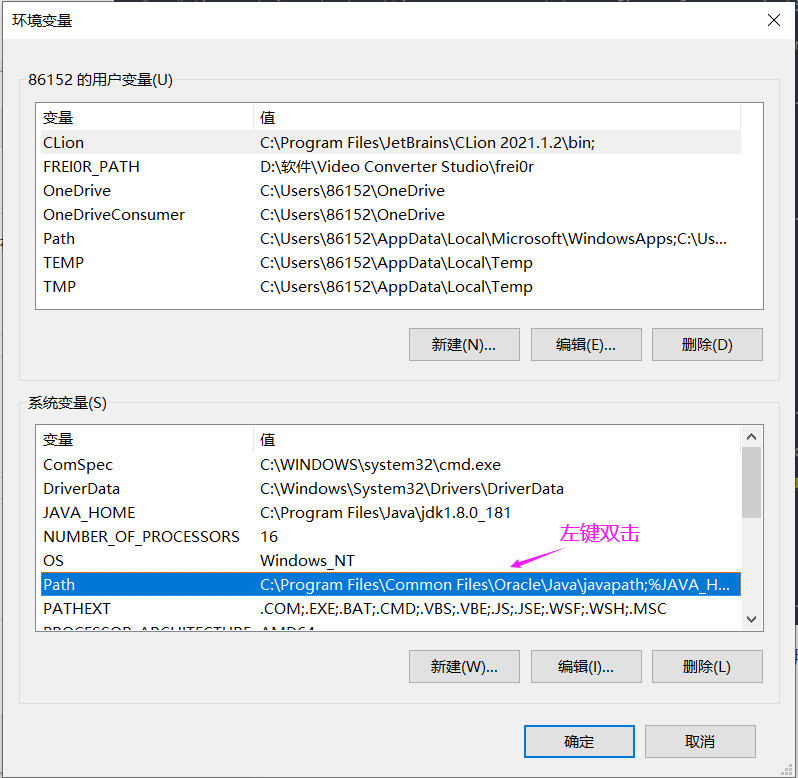
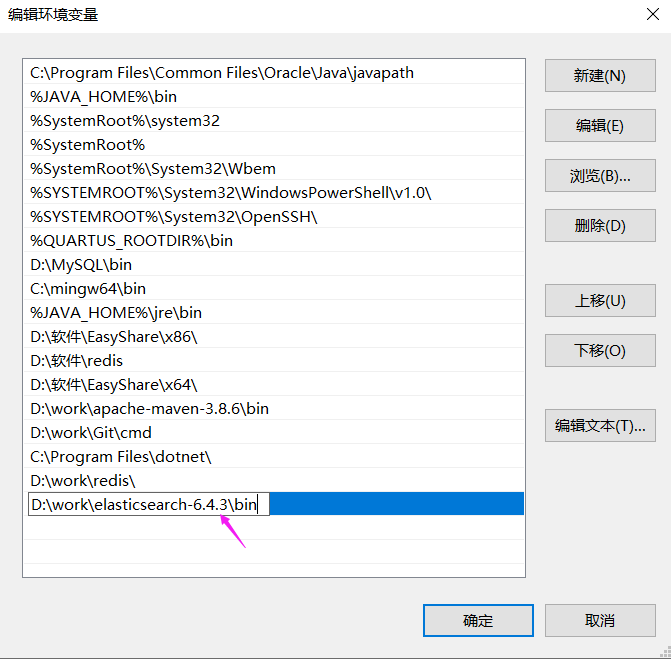
然后我们来配置一下环境变量,因为一会我们会通过命令行的方式运行ES的常用命令,
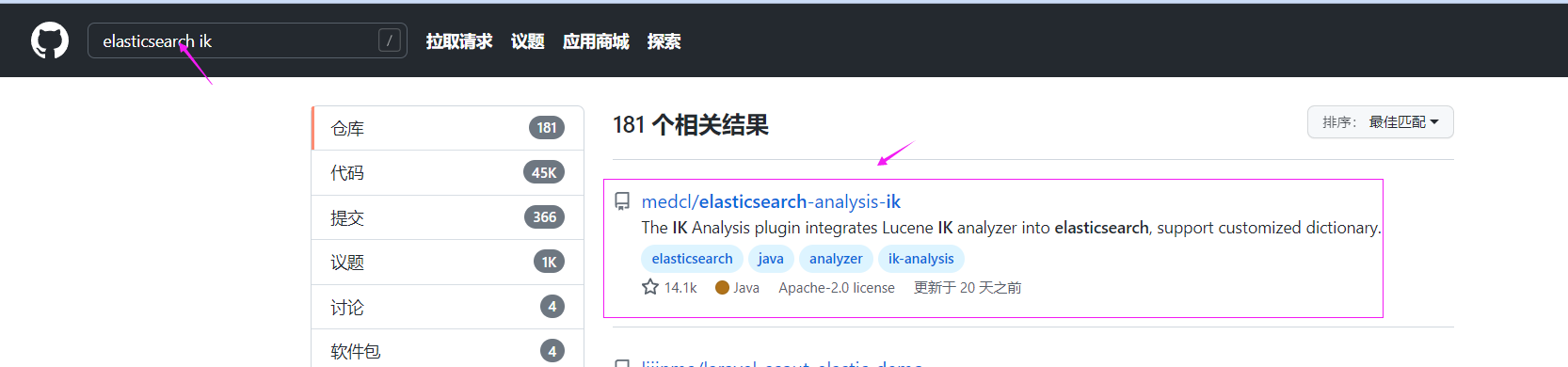
然后我们还要装一个中文的分词插件,为什么呢,比如搜“互联网校招”,肯定是分成“互联网”和“校招”分别查询
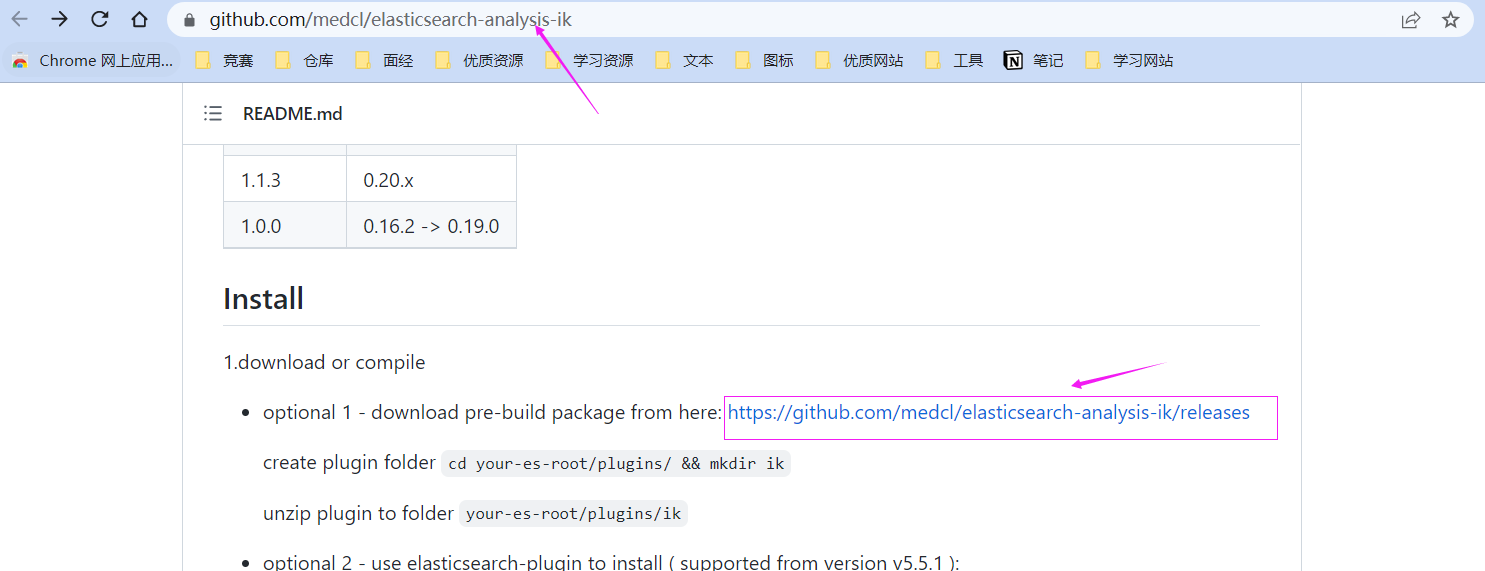
这个分词插件在GitHub上
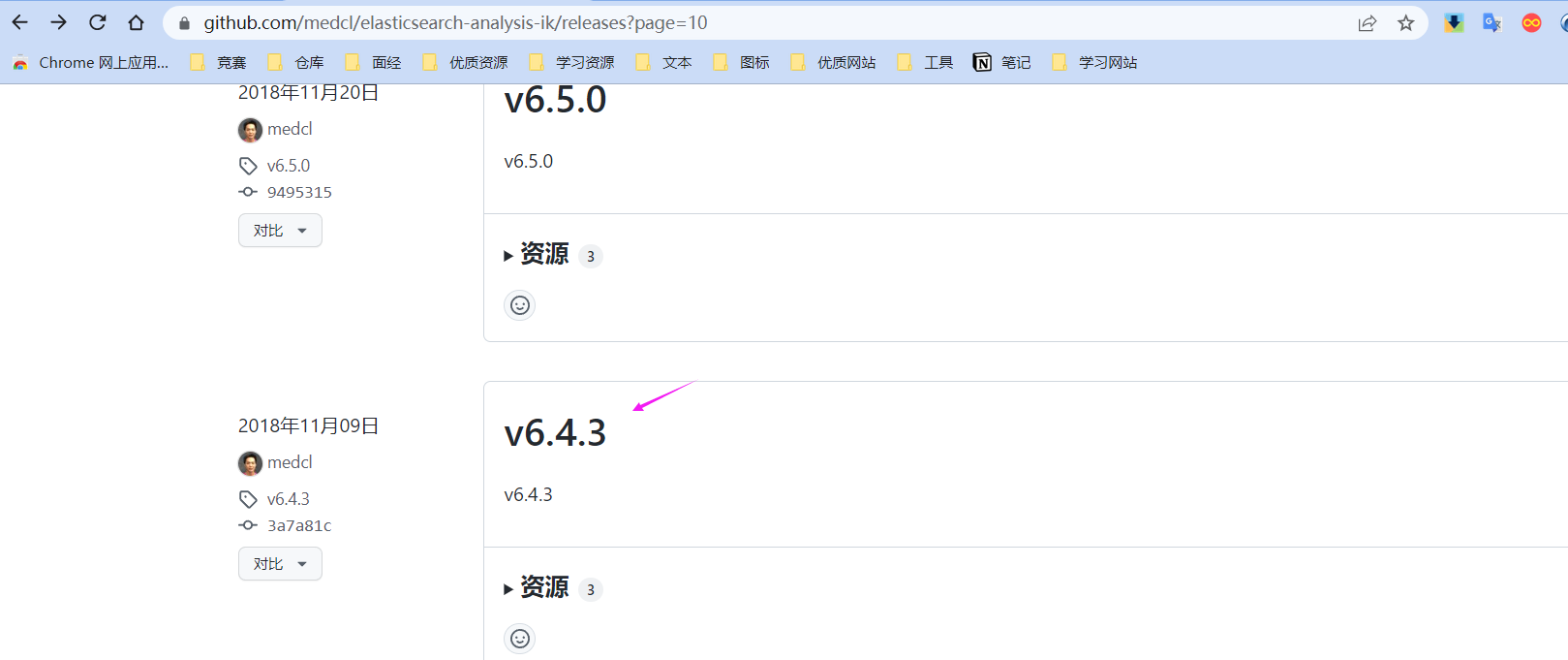
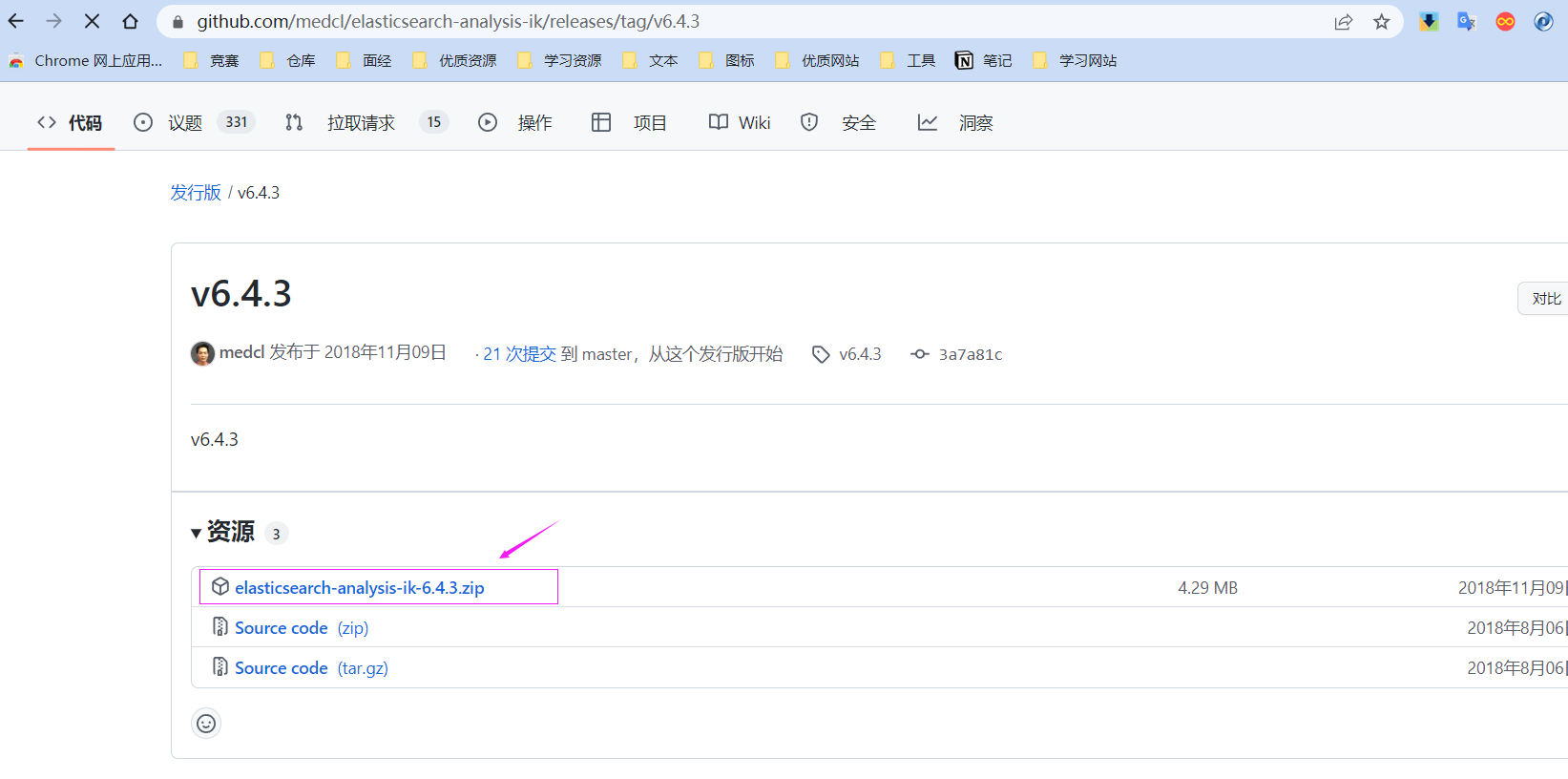
下载链接:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.3/elasticsearch-analysis-ik-6.4.3.zip
- 1
- 2
- 3
下载好压缩包之后必须解压缩到固定的目录下,首先进入elasticsearch-6.4.3\plugins 目录下, 然后自己新建一个ik文件夹 我们在将elasticsearch ik解压到ik文件夹下 记住千万不要 将elasticsearch-analysis-ik-6.4.3这个文件夹放入到ik 我们只需要将 elasticsearch-analysis-ik-6.4.3 里的那些文件放入到 ik 即可
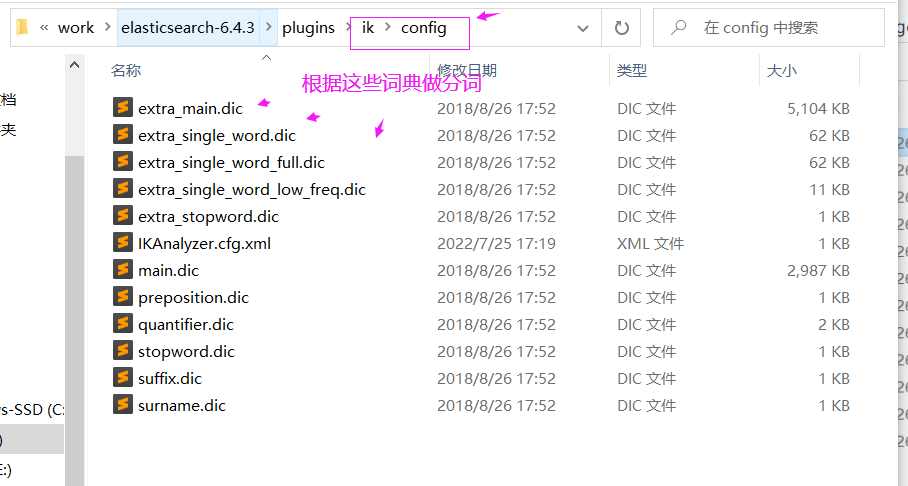
如果有网络新词出现
然后我们再安装一个文件
https://www.getpostman.com/
postman可以模拟web客户端, 说白了可以模仿网页,发送http请求,为什么需要这么一个工具呢,因为其实我们直接通过命令行去访问ES服务器,如果是查询某些东西还好,但是如果要往里面存东西,这个命令太长了,记不住,也很难写,因为ES支持用http方式去访问,如果我们有一个现成的网页,有一个框往里面填数据很方便,但是我们没有这个网页,那么这个 postman 就能替代那个网页,然后可以通过框构造一些数据提交给ES服务器,这样比较方便。即便是我们从ES中搜索数据,如果说我们搜索的规则比较复杂,那个时候命令也很难写,使用postman会比较方便。总之,为了提高入门ES使用的体验,我们使用postman。
演示使用ES
首先我们演示如何通过命令行的方式访问它,当然在访问之前,我们得将 elasticsearch 启动起来
这里我们双击
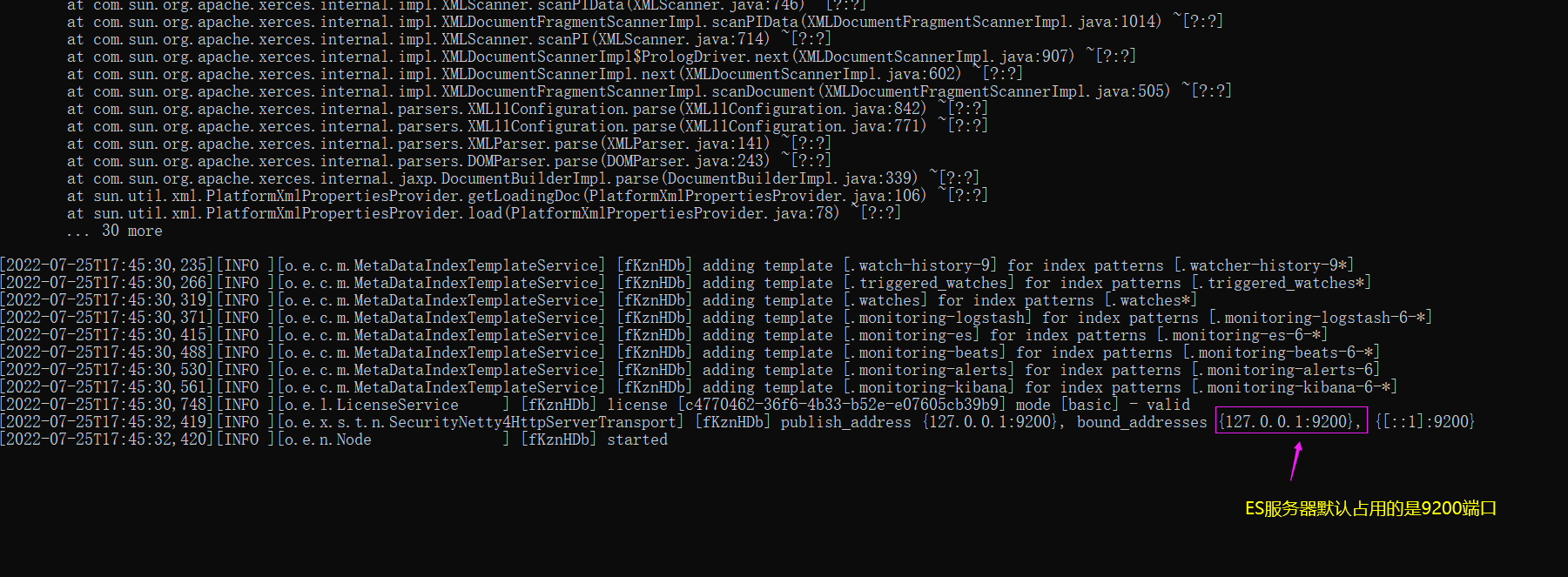
打开命令行工具cmd作为客户端访问一下服务器
# ES命令
查看ES集群的健康状况
curl -X GET "localhost:9200/_cat/health?v"
查看集群中有什么节点
curl -X GET "localhost:9200/_cat/nodes?v"
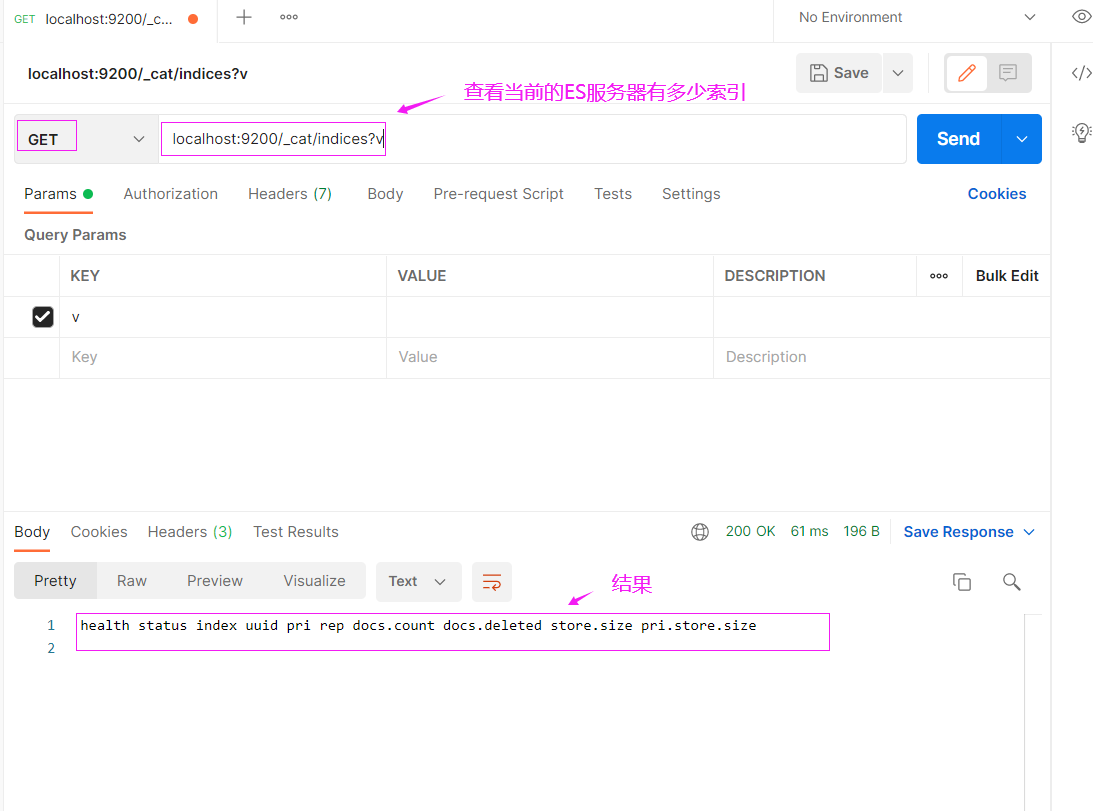
查看当前的ES服务器有多少个索引
curl -X GET "localhost:9200/_cat/indices?v"
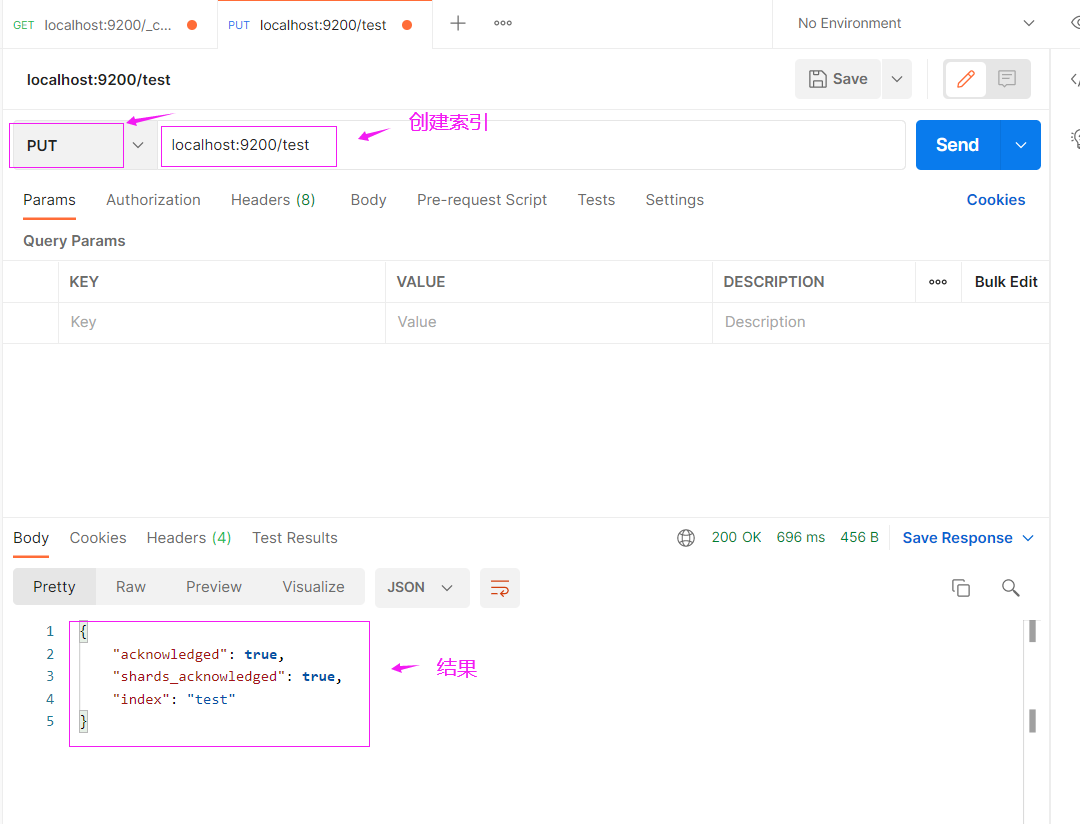
创建索引
curl -X PUT "localhost:9200/test"
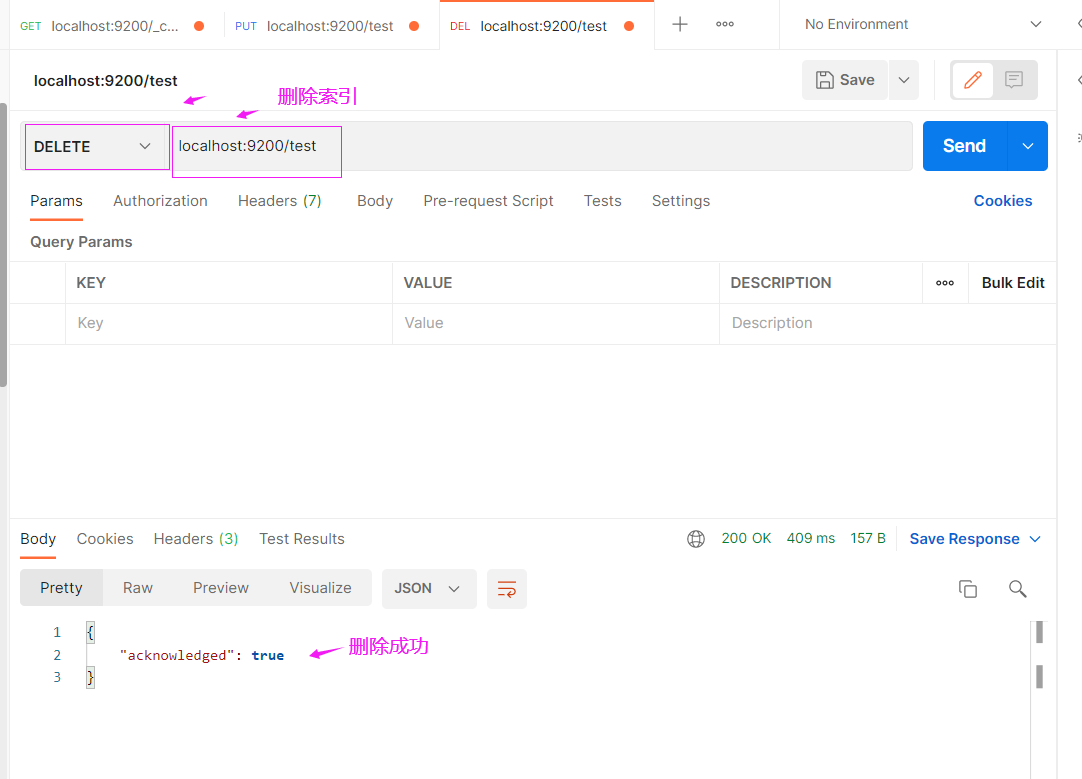
删除索引
curl -X DELETE "localhost:9200/test"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

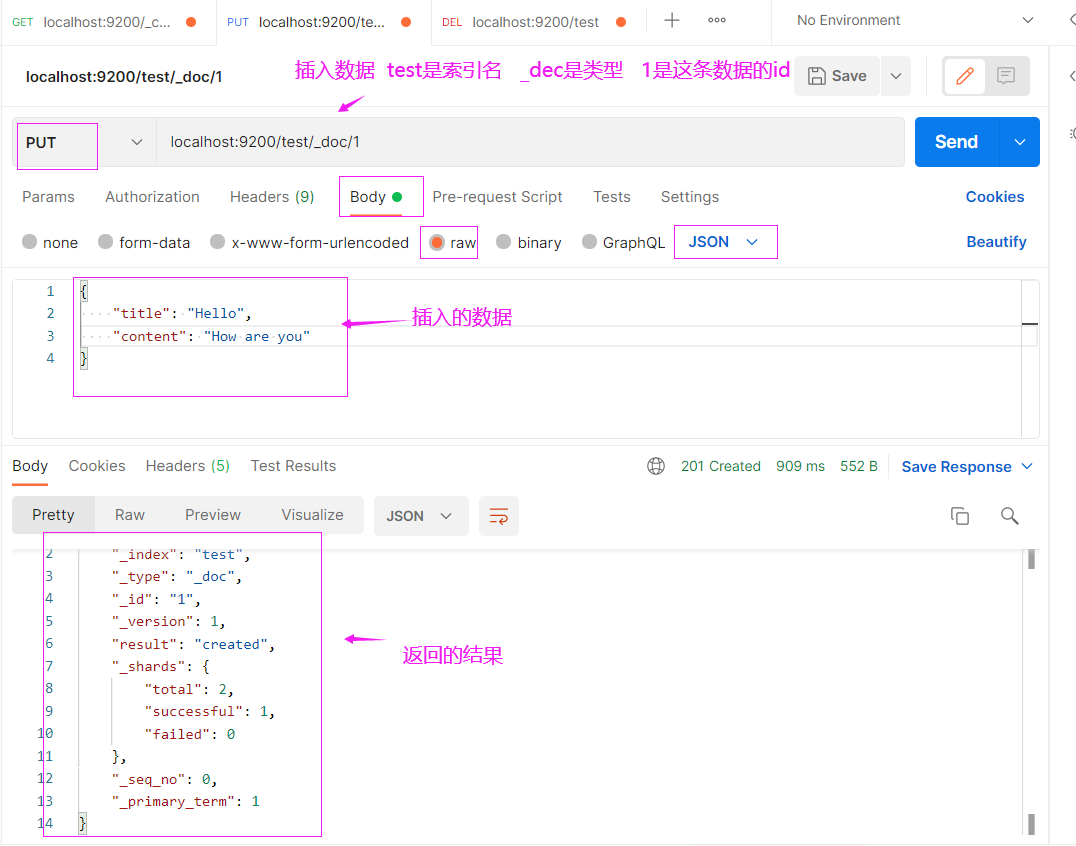
接下来演示一下使用postman来代替web客户端去访问ES
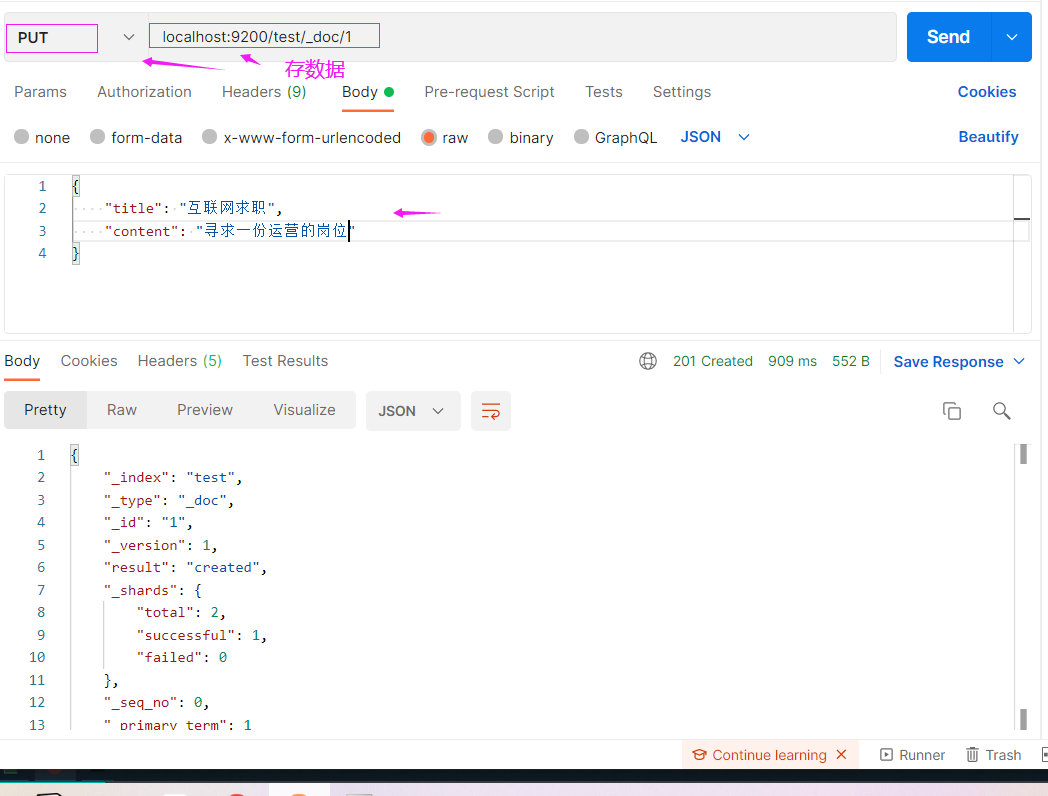
如何往ES里面插入数据,改数据和插入数据是一样的,只不过是把提交的数据修改一下再插入,ES底层会先删再添加
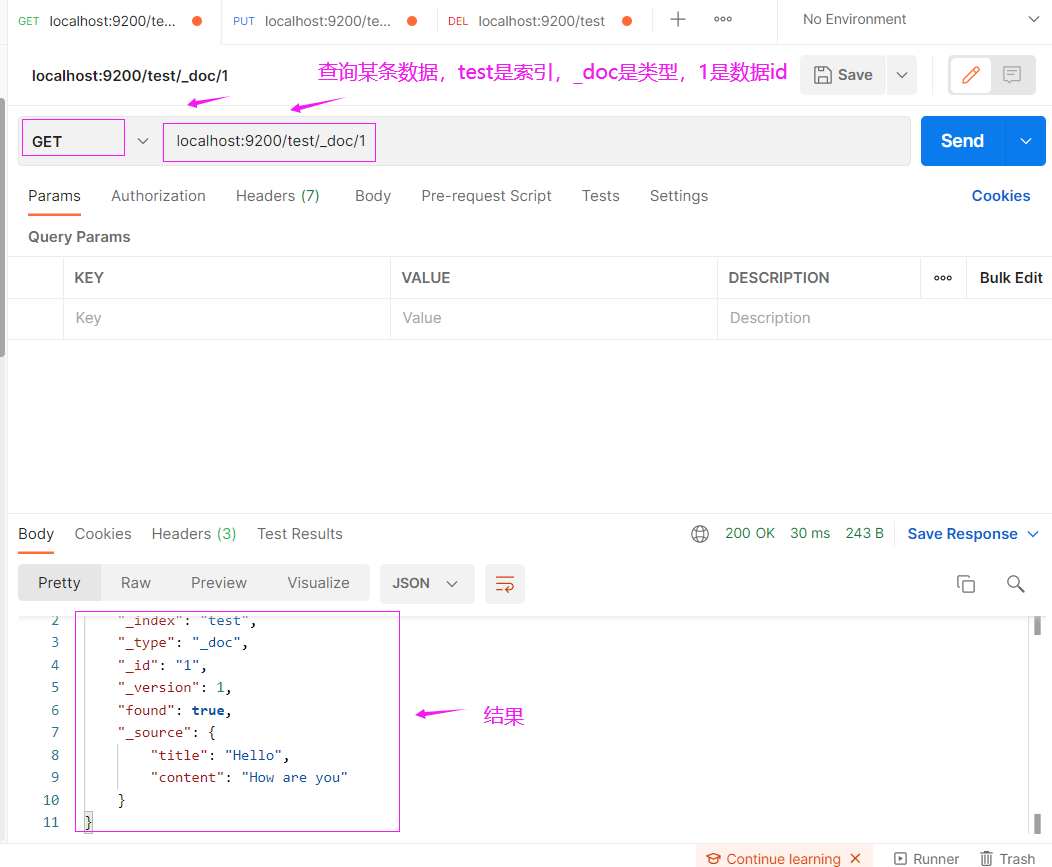
查询某条数据
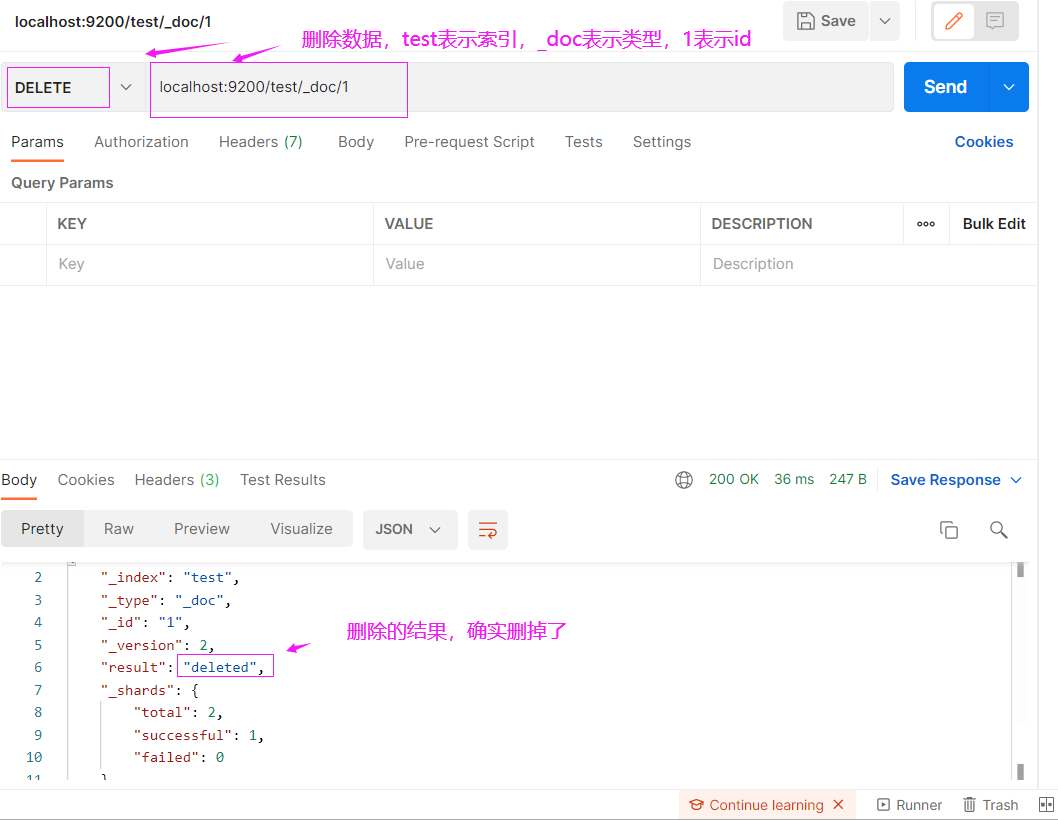
删除某条数据
ES存在的价值在于它里面的数据能够被我们搜索,这个搜索不是像查数据库,而是说提供一句话,需要分词,再去库里去匹配,匹配的时候还不是固定的某一个字段,既想搜title,又想搜content,是全文的匹配,那么数据库这一点是做不到的,它不能分词,接下来演示一下如何实现这种搜索,我们先往里面存三条数据,
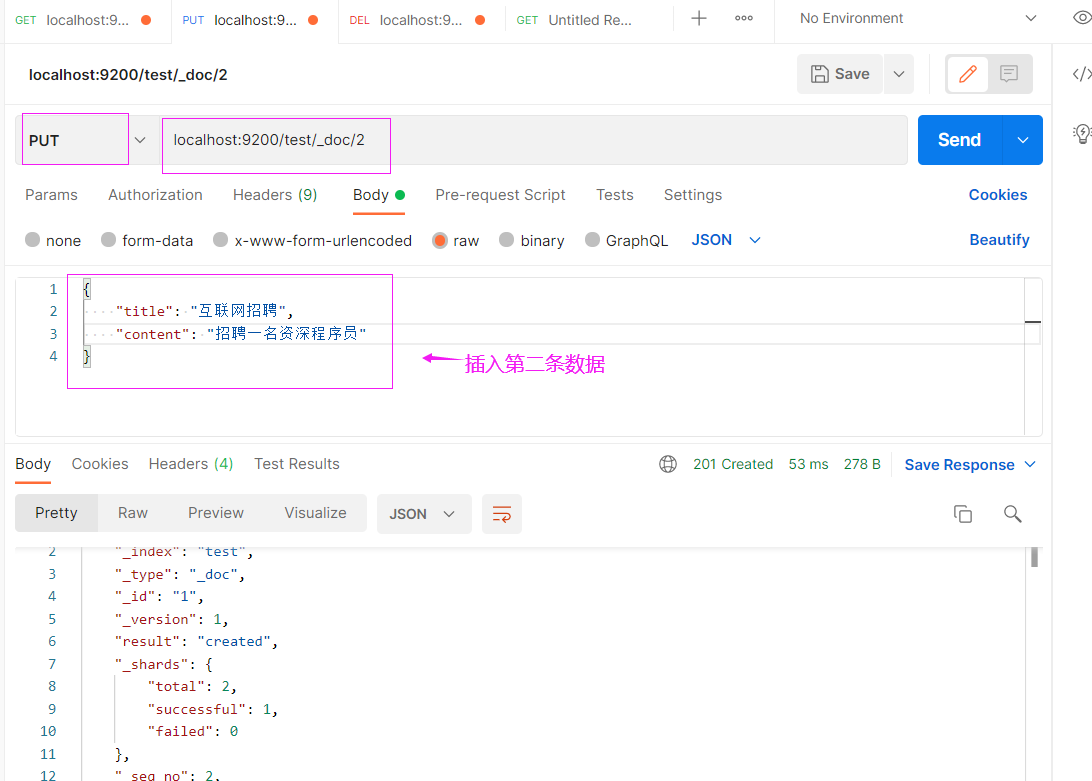
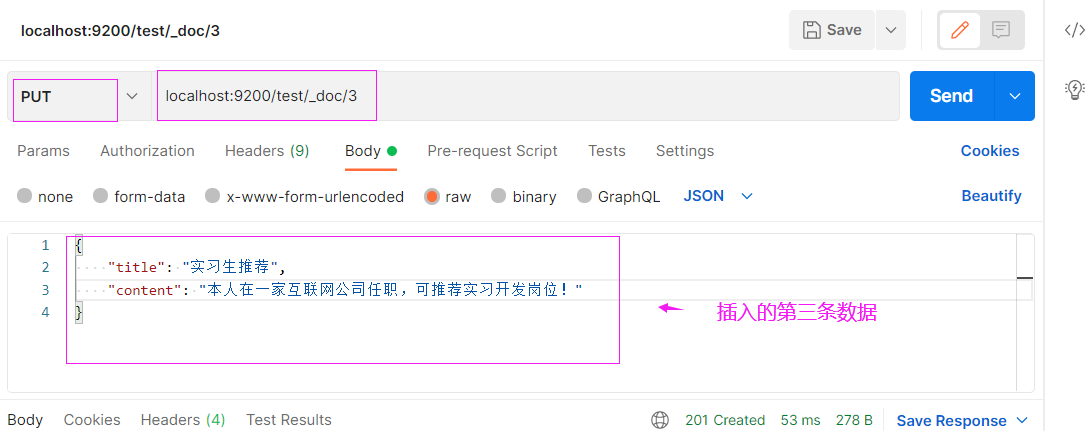
三条数据都插入了,接下来是搜索了
localhost:9200/test/_search
没有加条件就是全部搜索
- 1
- 2
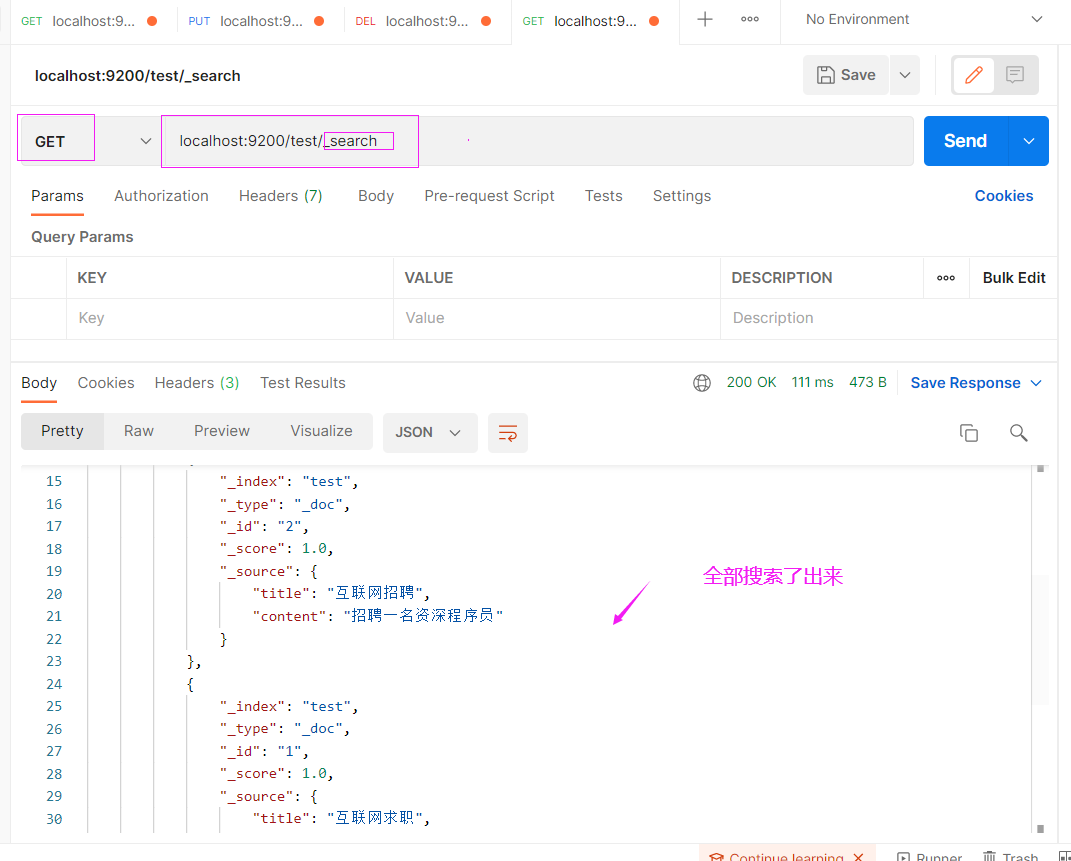
搜索标题title,查询标题有“互联网”字样的
localhost:9200/test/_search?q=title:互联网
- 1
- 2
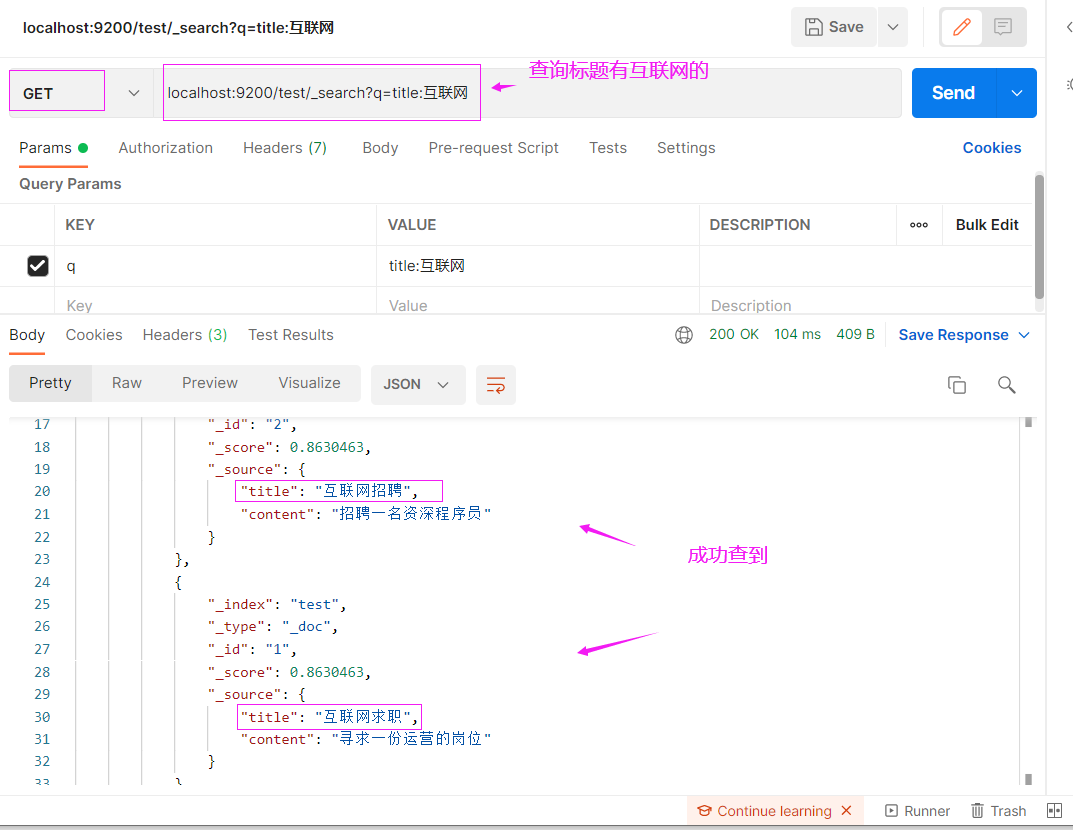
搜索内容中含有"运营实习"字样的
localhost:9200/test/_search?q=content:运营实习
- 1
- 2
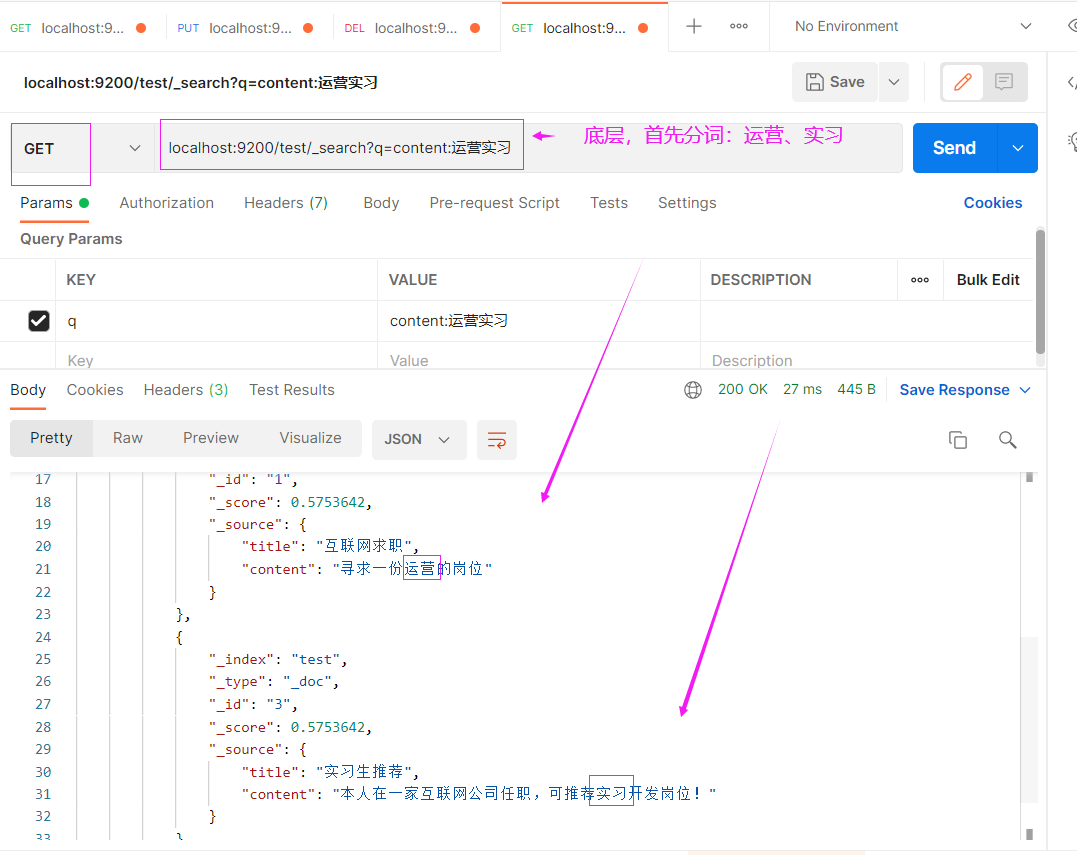
既要搜title又要搜content,只要包含这个词条都显示出来,这时候搜的逻辑就有点复杂了,通过路径搞不定了,
路径
localhost:9200/test/_search
具体的搜索条件在Body中提交
{
"query": {
"multi_match": {
"query": "互联网",
"fields": ["title", "content"]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6.2 Spring整合Elasticsearch
引入依赖
注意:我的SpringBoot父版本是2.1.5.RELEASE,对于高版本的elasticsearch配置可能会有所不同
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 1
- 2
- 3
- 4
配置Elasticsearch
在 application.properties 配置文件中进行配置
注:我这里使用的elasticsearch是低版本的,高版本的配置可能会略有不同。
127.0.0.0 和 localhost 等价
es中9200是http访问的端口,9300是tcp端口也是默认启用的,我们应用服务通常会用9300端口tcp去访问它。
#ElasticsearchProperties
# 配置集群名字,以前我们在es配置文件里改过es集群的名字
spring.data.elasticsearch.cluster-name=nowcoder
# 配置集群中各个结点(当然,我们这里只有一个结点)
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
- 1
- 2
- 3
- 4
- 5
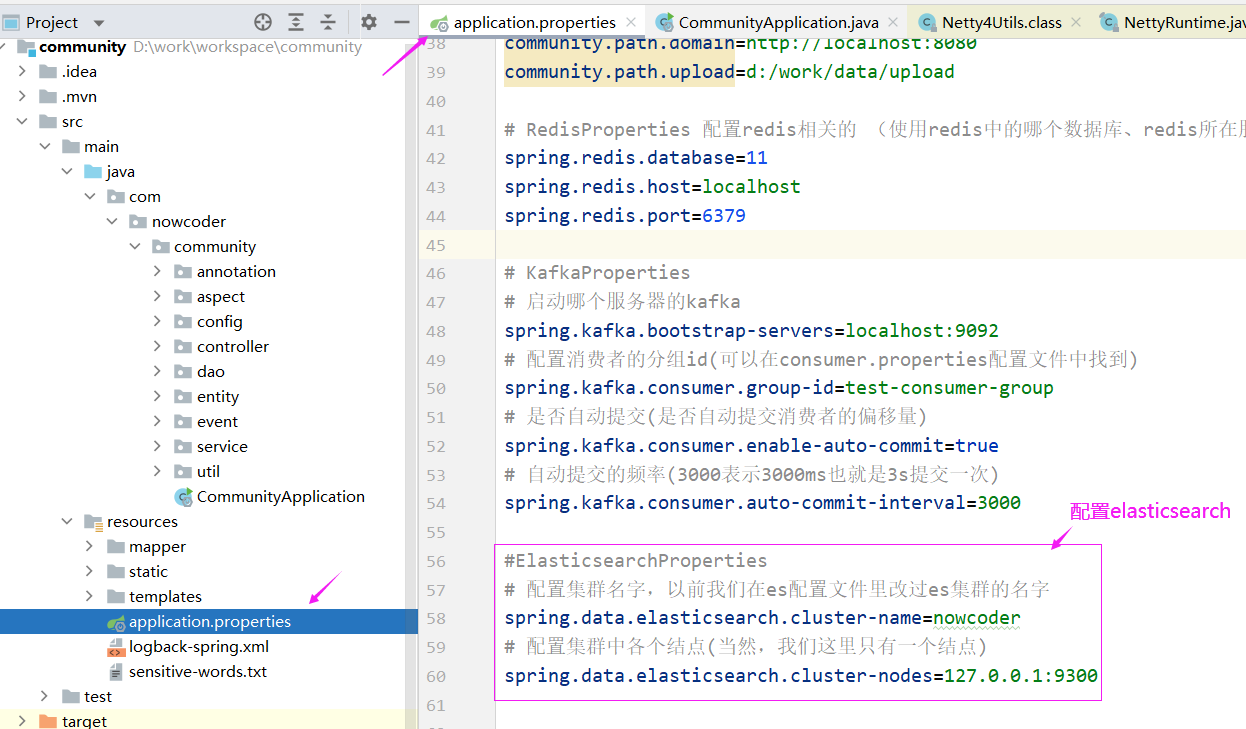
elasticsearch底层是基于netty,我们之前安装的redis底层也是基于netty,这两者在启用netty的时候有冲突,主要体现在es底层代码上,我们需要稍微做一个变通。
在项目的启动入口类CommunityApplication里面
@PostConstruct
public void init(){
// 解决Netty启动冲突问题(看NettyRuntime中setAvailableProcessors方法和Netty4Utils类)
System.setProperty("es.set.netty.runtime.available.processors", "false");
}
- 1
- 2
- 3
- 4
- 5
Spring Data Elasticsearch
我们现在要把数据库里存的帖子存到es服务器里,然后我们去es服务器搜索这个帖子,我们可以使用 ElasticsearchTemplate 或 ElasticsearchRepository 去做这个事情。
ElasticsearchRepository
ElasticsearchRepository简单,我们先用这种方案,当有些需求它不好解决的时候再用ElasticsearchTemplate
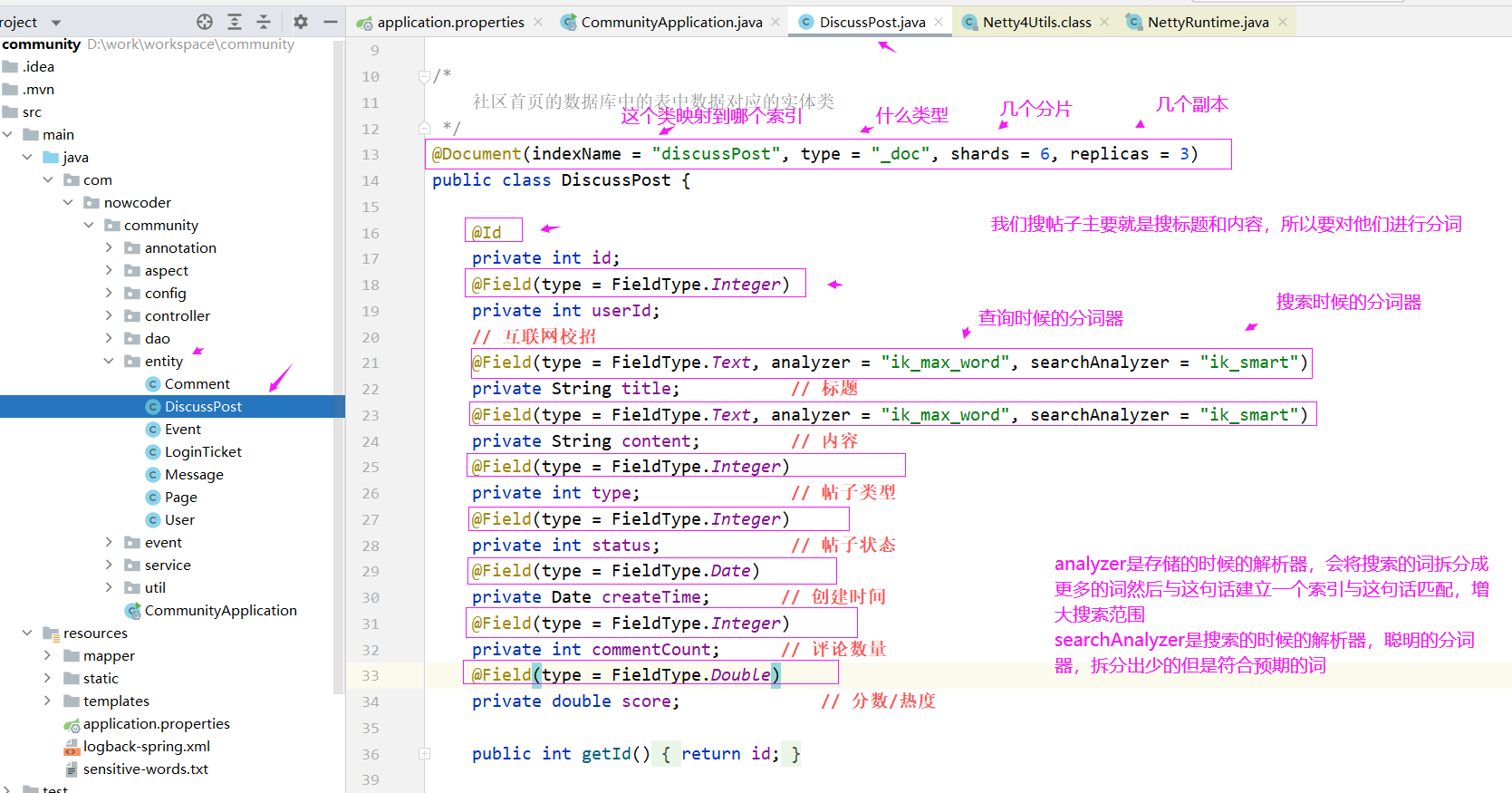
在使用 ElasticsearchRepository 之前我们需要做一个配置,需要告诉它帖子这个表和es里要存的那个索引之间是什么样的对应关系,这个表存到es里变成索引的时候每个字段对应是什么样的类型,用什么方式搜素,这些都要做配置,这个配置呢不需要我们写xml文件,我们通过注解就可以,实体类上要加上这个注解,因为我们是针对帖子的操作。
在类上加上注解,映射到哪个索引上去,映射到什么类型上去,创建几个分片,几个副本,日后调用api时,如果没有索引会自动创建索引,然后没有分片、副本,会自动根据配置创建,然后再往索引里插入数据。然后为了让实体中的属性和索引中的字段对应,所以我们在属性上也需要加上注解配置。
我们搜帖子主要就是搜标题和内容,
analyzer是存储的时候的解析器,会将搜索的词拆分成更多的词然后与这句话建立一个索引与这句话匹配,增大搜索范围
searchAnalyzer是搜索的时候的解析器,聪明的分词器,拆分出少的但是符合预期的词
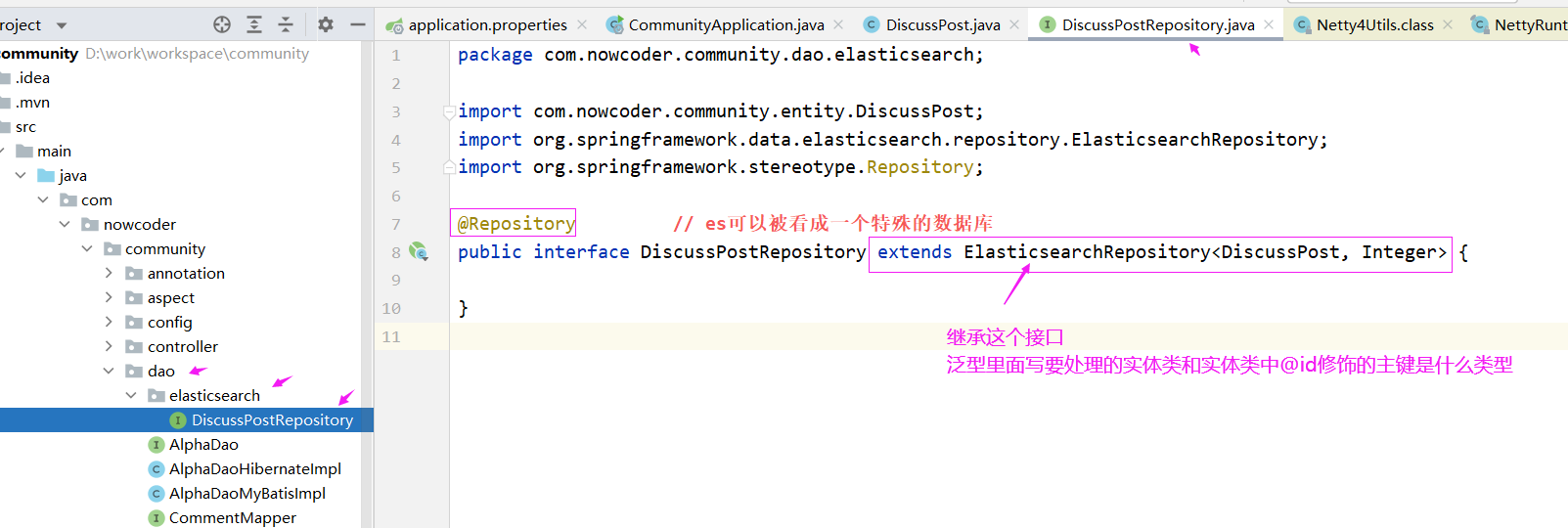
下面我们定义ElasticsearchRepository接口
泛型里面写要处理的实体类和主键是什么类型
@Repository // es可以被看成一个特殊的数据库
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {
}
- 1
- 2
- 3
- 4
接下来我们来测试一下 ElasticsearchRepository 和 ElasticsearchTemplate
注意:测试的时候一定要将 Elasticsearch 服务 和 Kafka(还有zookeeper,因为项目用到了这些服务)打开
测试类:
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class ElasticsearchTests {
@Autowired
private DiscussPostMapper discussMapper; // 先从mysql取出数据
@Autowired
private DiscussPostRepository discussRepository; // 注入刚才的那个接口以便于将数据存到es查询
@Autowired
private ElasticsearchTemplate elasticTemplate; // 有些情况DiscussPostRepository解决不了就用这个
@Test
public void testInsert() {
// 插入数据
discussRepository.save(discussMapper.selectDiscussPostById(241));
discussRepository.save(discussMapper.selectDiscussPostById(242));
discussRepository.save(discussMapper.selectDiscussPostById(243));
}
@Test
public void testInsertList() {
discussRepository.saveAll(discussMapper.selectDiscussPosts(101, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(102, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(103, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(111, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(112, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(131, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(132, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(133, 0, 100));
discussRepository.saveAll(discussMapper.selectDiscussPosts(134, 0, 100));
}
@Test
public void testUpdate() {
DiscussPost post = discussMapper.selectDiscussPostById(231);
post.setContent("我是新人,使劲灌水.");
discussRepository.save(post);
}
@Test
public void testDelete() {
//discussRepository.deleteById(231);
discussRepository.deleteAll();
}
// 搜索功能
@Test
public void testSearchByRepository() {
// 构造搜索条件:要不要排序、分页并且搜索结果要不要高亮显示等
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))//搜索的关键词并且在哪搜
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)) // 排序方式:倒序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC)) // 排序方式:倒序
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC)) // 排序方式:倒序
.withPageable(PageRequest.of(0, 10)) // 分页方式
.withHighlightFields( // 指定哪些字段要高亮显示,怎么高亮显示
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"), // 高亮显示
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>") // 高亮显示
).build();
// elasticTemplate.queryForPage(searchQuery, class, SearchResultMapper)
// 底层获取得到了高亮显示的值, 但是没有返回.
// 这个Page不是我们自己写的那个实体类,而是java提供的
Page<DiscussPost> page = discussRepository.search(searchQuery);
System.out.println(page.getTotalElements()); // 一共有多少条数据匹配
System.out.println(page.getTotalPages()); // 一共有多少页
System.out.println(page.getNumber()); // 当前处在第几页
System.out.println(page.getSize()); // 每一页最多显示几条数据
for (DiscussPost post : page) { // 查看查询到的数据
System.out.println(post);
}
}
@Test
public void testSearchByTemplate() {
// 构造搜索条件:要不要排序、分页并且搜索结果要不要高亮显示等
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))//搜索的关键词并且在哪搜
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)) // 排序方式:倒序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC)) // 排序方式:倒序
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC)) // 排序方式:倒序
.withPageable(PageRequest.of(0, 10)) // 分页方式
.withHighlightFields( // 指定哪些字段要高亮显示,怎么高亮显示
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"), // 高亮显示
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>") // 高亮显示
).build();
// 参数1:搜索条件 参数2:实体类型 参数3:SearchResultMapper接口(实现一个匿名内部类或者传一个实现类)
Page<DiscussPost> page = elasticTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override // queryForPage得到结果然后交给mapResults处理,然后通过SearchResponse参数处理
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits(); // 先取到这次搜索命令的数据(里面可以是多条数据)
if (hits.getTotalHits() <= 0) { // 判断有没有数据
return null;
}
// 执行到这里说明有数据
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) { // 遍历命中的数据将其放在集合里
DiscussPost post = new DiscussPost(); // 将命中的数据包装到实体类中
// hit里面是将数据封装成了map并且里面key和value都是String类型,我们可以从中取值
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.valueOf(id)); // 将字符类型的数转成整数存入实体类的id属性
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.valueOf(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setContent(content);
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.valueOf(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.valueOf(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.valueOf(commentCount));
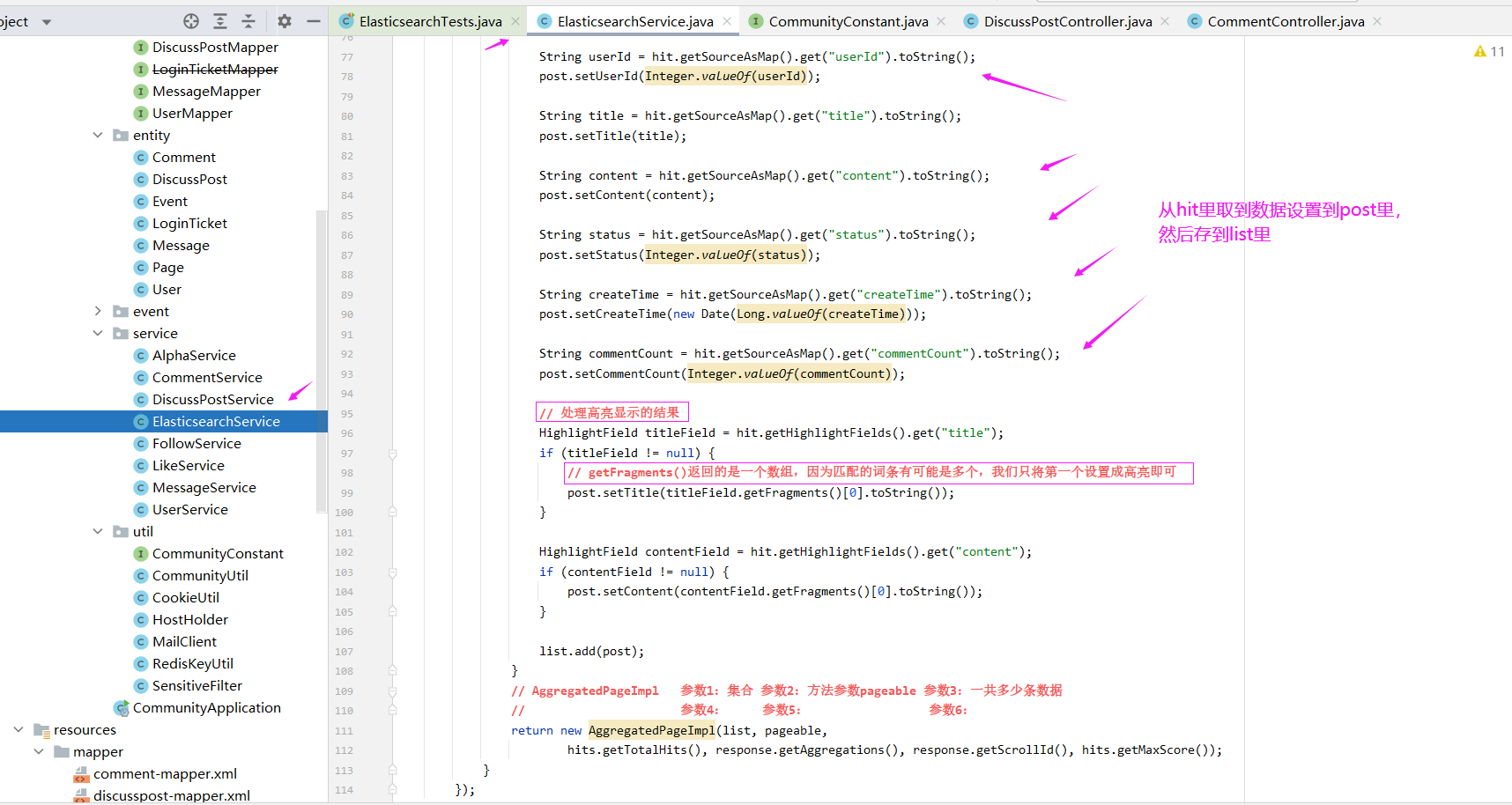
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");
if (titleField != null) {
// getFragments()返回的是一个数组,因为匹配的词条有可能是多个,我们只将第一个设置成高亮即可
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);
}
// AggregatedPageImpl 参数1:集合 参数2:方法参数pageable 参数3:一共多少条数据
// 参数4: 参数5: 参数6:
return new AggregatedPageImpl(list, pageable,
hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());
}
});
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
System.out.println(page.getNumber());
System.out.println(page.getSize());
for (DiscussPost post : page) {
System.out.println(post);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
6.3 开发社区搜索功能

业务层:
发布一个帖子的时候应该1.将帖子存到Elasticsearch服务器,2.删帖子我们也应该从Elasticsearch服务器删去(当然现在删帖的功能还没有实现,但是我们在开发搜索服务的时候先把从Elasticsearch服务器删除帖子的方法先准备好,以后呢可以直接调用),然后重点就是我们要在组件里提供搜索的服务去3.搜索帖子。
表现层:
-
发布帖子时,采用异步的方式将帖子提交到Elasticsearch服务器
-
增加评论时,帖子的评论数量就会发生变化,这个时候我们也将帖子异步地提交到Elasticsearch服务器,相当于这是修改帖子
-
异步的方式主要是为了提高性能,当发了帖子以后,只要把事件丢到消息队列里,我们就可以继续处理下一个类似的请求,不用等待,所以说异步可以并行的处理一些事情,这样比较好。既然是异步的话,我们在发布帖子时、增加评论时触发了这样一个事件,我们需要在消费者组件里加一个方法来消费这个事件
当把数据同步到了ES服务器以后,剩下的就是查询了,查询的时候我们要想显示出搜索结果,我们需要在controller里处理搜索请求,然后在对应的html里显示结果。
首先先解决一个之前遗留的小问题
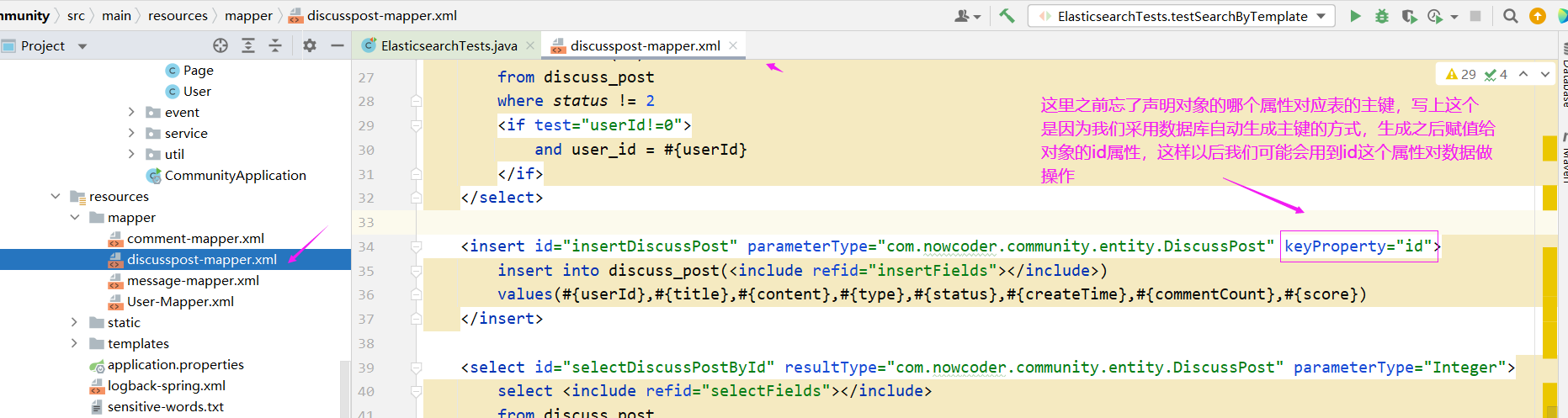
然后正式开发刚才所述内容
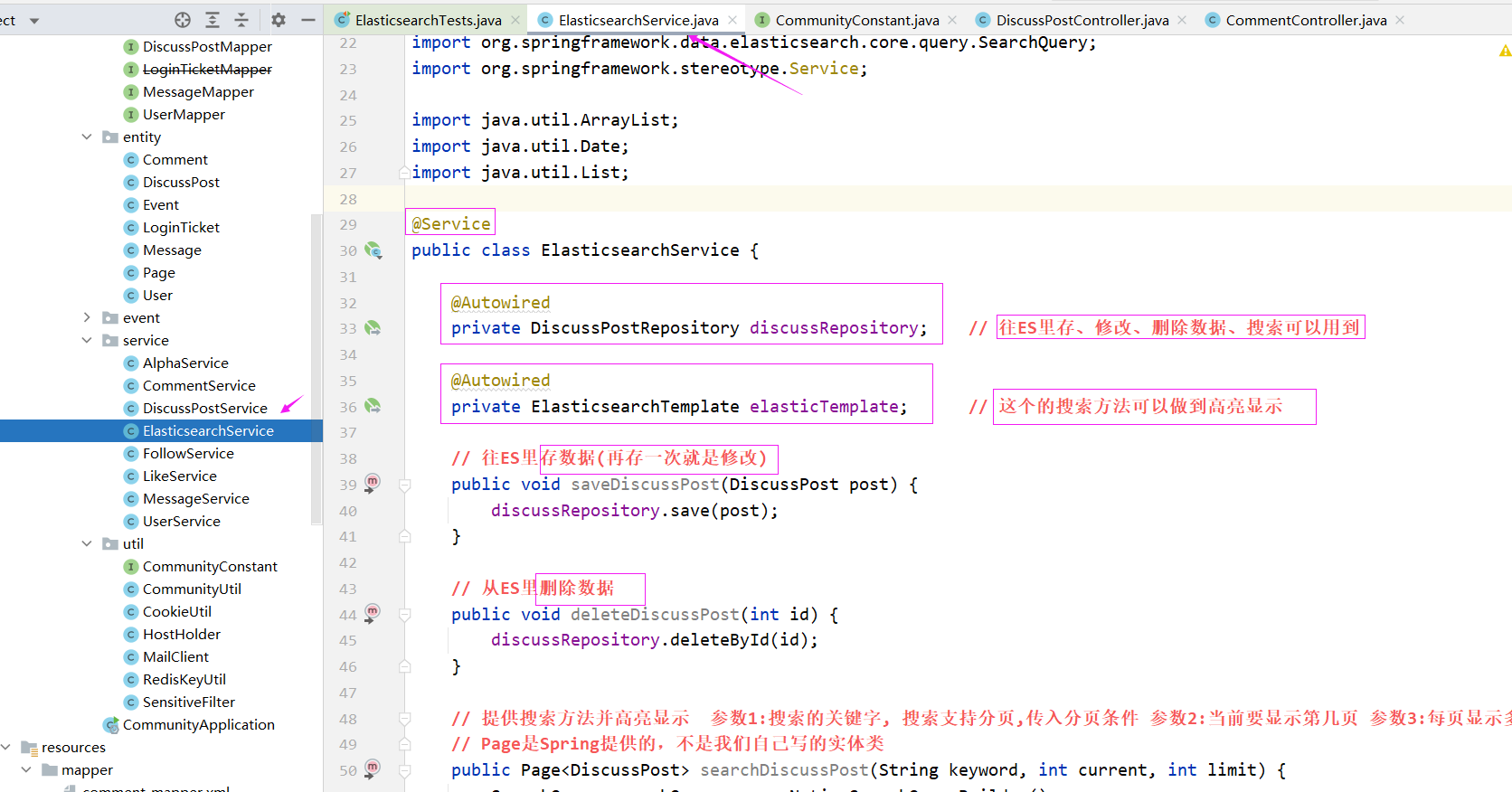
事务层(Service)
新建一个 ElasticsearchService 处理业务层
@Service
public class ElasticsearchService {
@Autowired
private DiscussPostRepository discussRepository; // 往ES里存、修改、删除数据、搜索可以用到
@Autowired
private ElasticsearchTemplate elasticTemplate; // 这个的搜索方法可以做到高亮显示
// 往ES里存数据(再存一次就是修改)
public void saveDiscussPost(DiscussPost post) {
discussRepository.save(post);
}
// 从ES里删除数据
public void deleteDiscussPost(int id) {
discussRepository.deleteById(id);
}
// 提供搜索方法并高亮显示 参数1:搜索的关键字, 搜索支持分页,传入分页条件 参数2:当前要显示第几页 参数3:每页显示多少条数据
// Page是Spring提供的,不是我们自己写的实体类
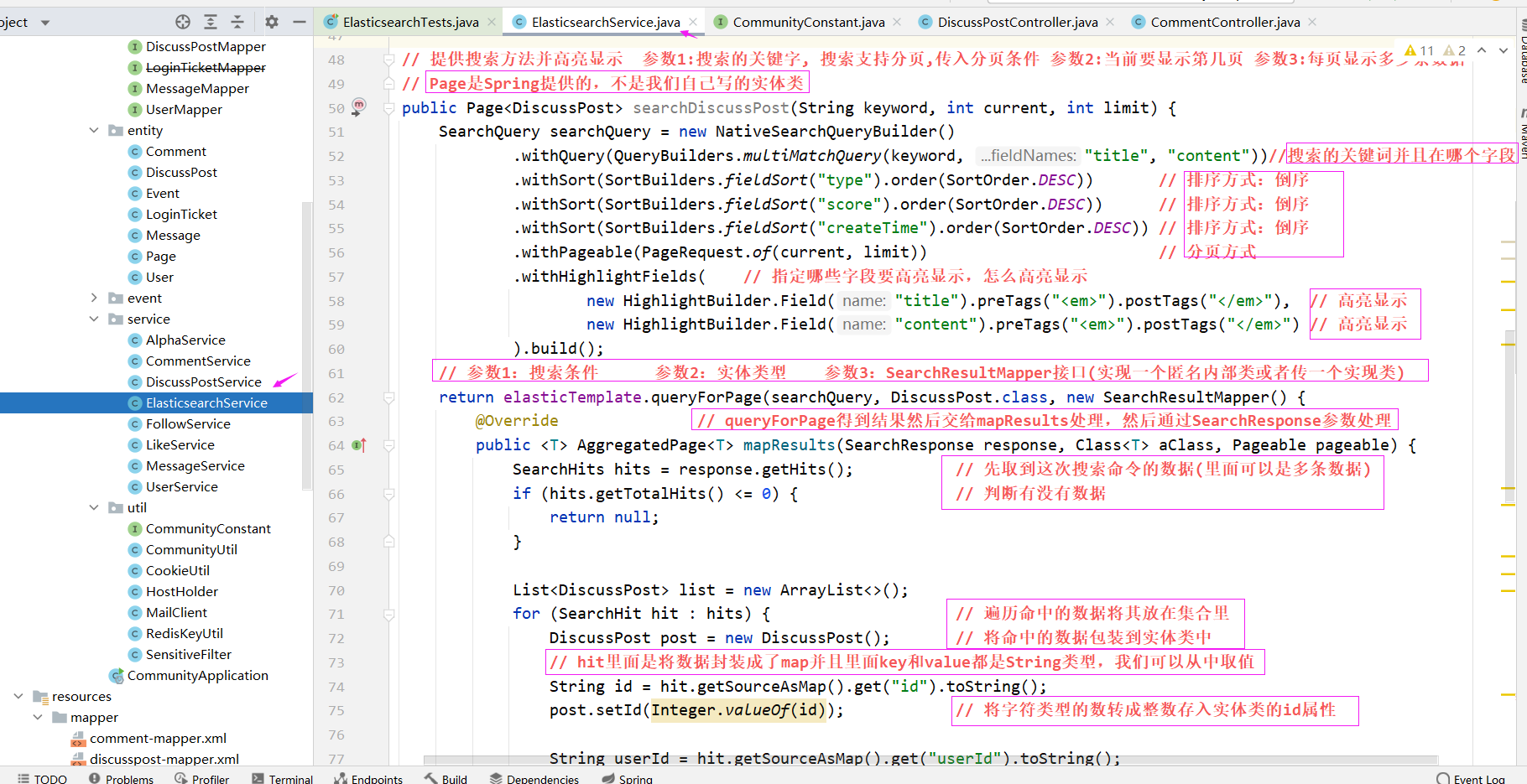
public Page<DiscussPost> searchDiscussPost(String keyword, int current, int limit) {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery(keyword, "title", "content"))//搜索的关键词并且在哪个字段搜
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)) // 排序方式:倒序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC)) // 排序方式:倒序
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC)) // 排序方式:倒序
.withPageable(PageRequest.of(current, limit)) // 分页方式
.withHighlightFields( // 指定哪些字段要高亮显示,怎么高亮显示
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"), // 高亮显示
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>") // 高亮显示
).build();
// 参数1:搜索条件 参数2:实体类型 参数3:SearchResultMapper接口(实现一个匿名内部类或者传一个实现类)
return elasticTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override // queryForPage得到结果然后交给mapResults处理,然后通过SearchResponse参数处理
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits(); // 先取到这次搜索命令的数据(里面可以是多条数据)
if (hits.getTotalHits() <= 0) { // 判断有没有数据
return null;
}
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) { // 遍历命中的数据将其放在集合里
DiscussPost post = new DiscussPost(); // 将命中的数据包装到实体类中
// hit里面是将数据封装成了map并且里面key和value都是String类型,我们可以从中取值
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.valueOf(id)); // 将字符类型的数转成整数存入实体类的id属性
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.valueOf(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setContent(content);
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.valueOf(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.valueOf(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.valueOf(commentCount));
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");
if (titleField != null) {
// getFragments()返回的是一个数组,因为匹配的词条有可能是多个,我们只将第一个设置成高亮即可
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);
}
// AggregatedPageImpl 参数1:集合 参数2:方法参数pageable 参数3:一共多少条数据
// 参数4: 参数5: 参数6:
return new AggregatedPageImpl(list, pageable,
hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());
}
});
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
触发事件(生产者)
用异步的方式去向ES服务器当中同步数据,我们是在发布帖子和增加评论这两个地方同步数据(删除帖子目前还没做),我们在这两个点触发一个发帖事件,
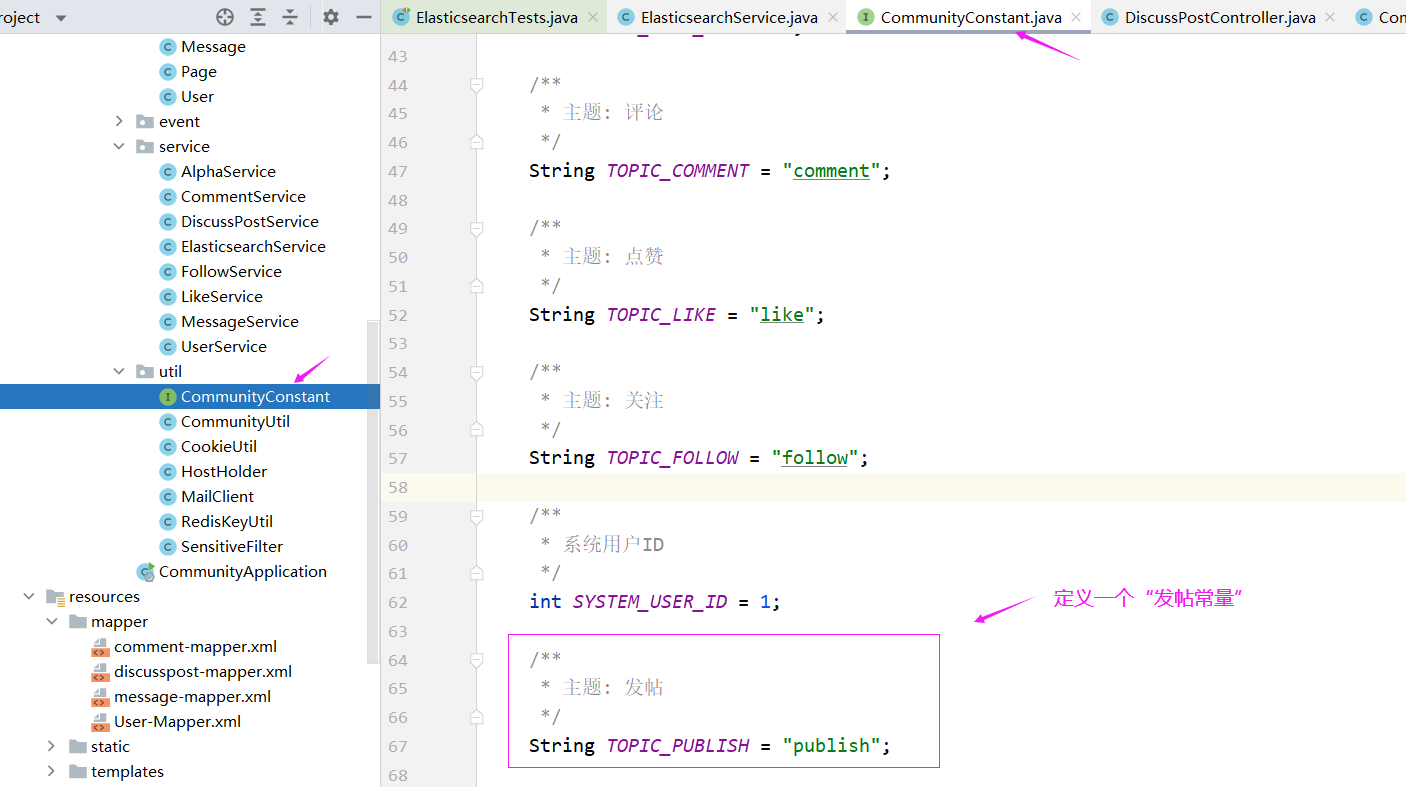
发帖事件先定义一个常量
CommunityConstant:
/**
* 主题: 发帖
*/
String TOPIC_PUBLISH = "publish";
- 1
- 2
- 3
- 4
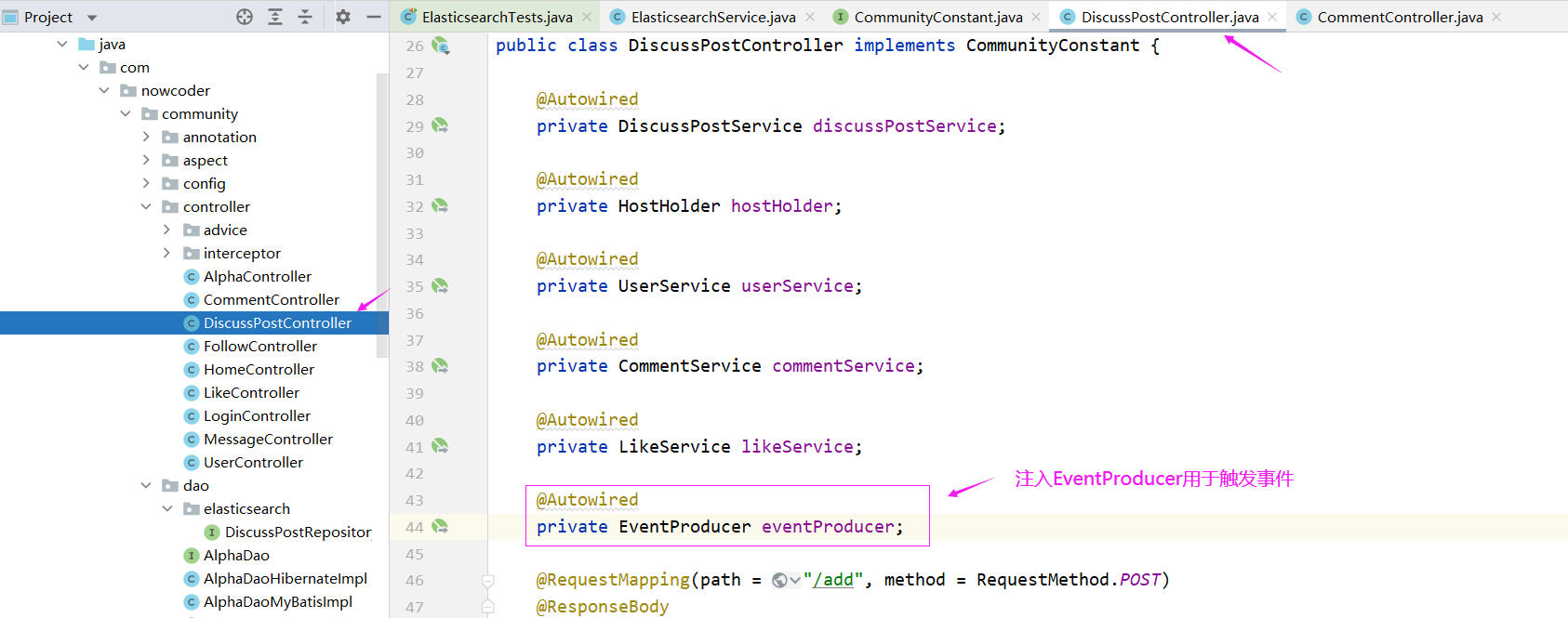
发布帖子时:
DiscussPostController
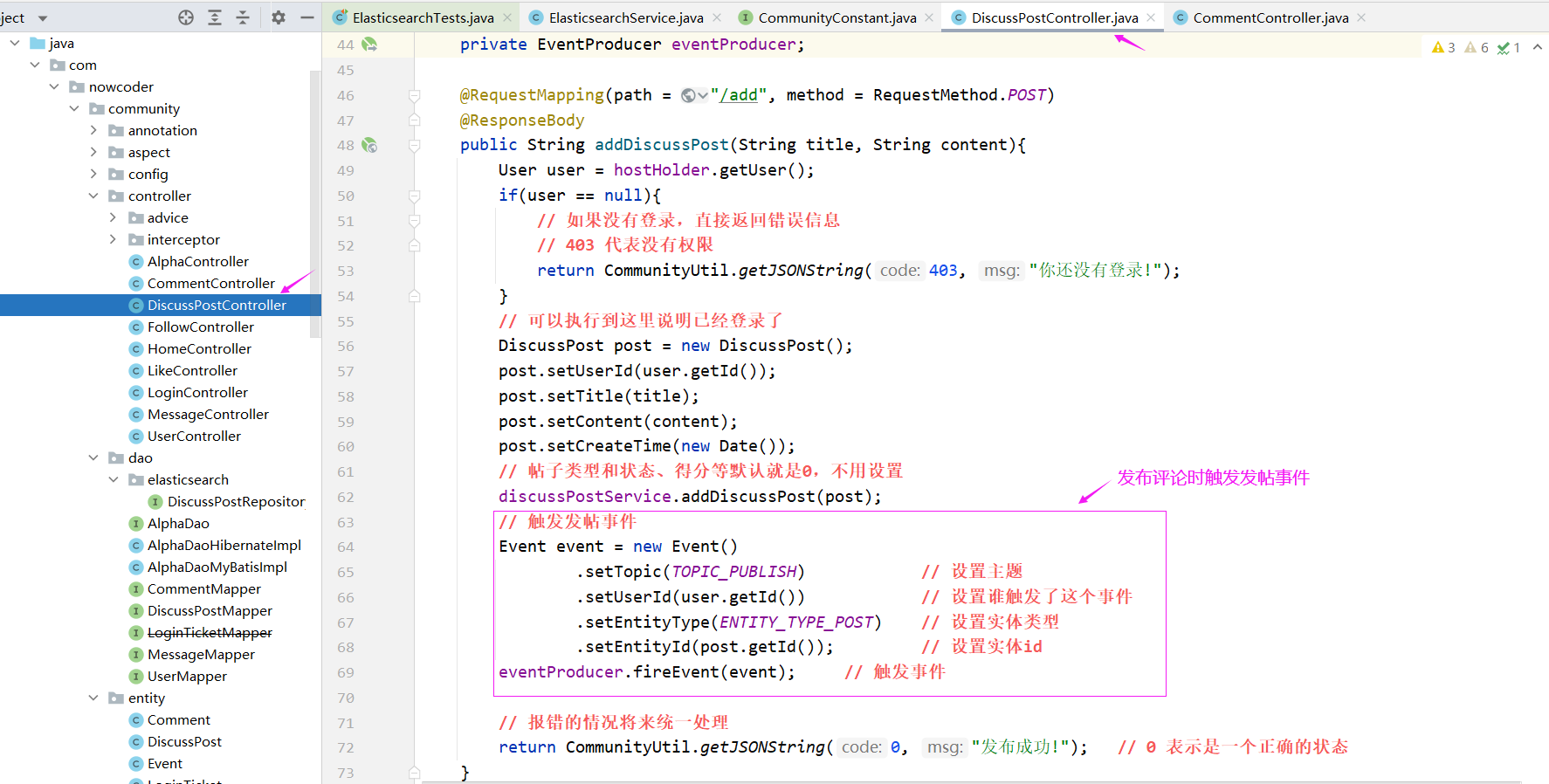
发布评论时
CommentController
评论帖子以后帖子的评论数量,帖子就变了,这个时候需要触发一次事件把ES里的数据覆盖掉,其实是一个修改的行为。
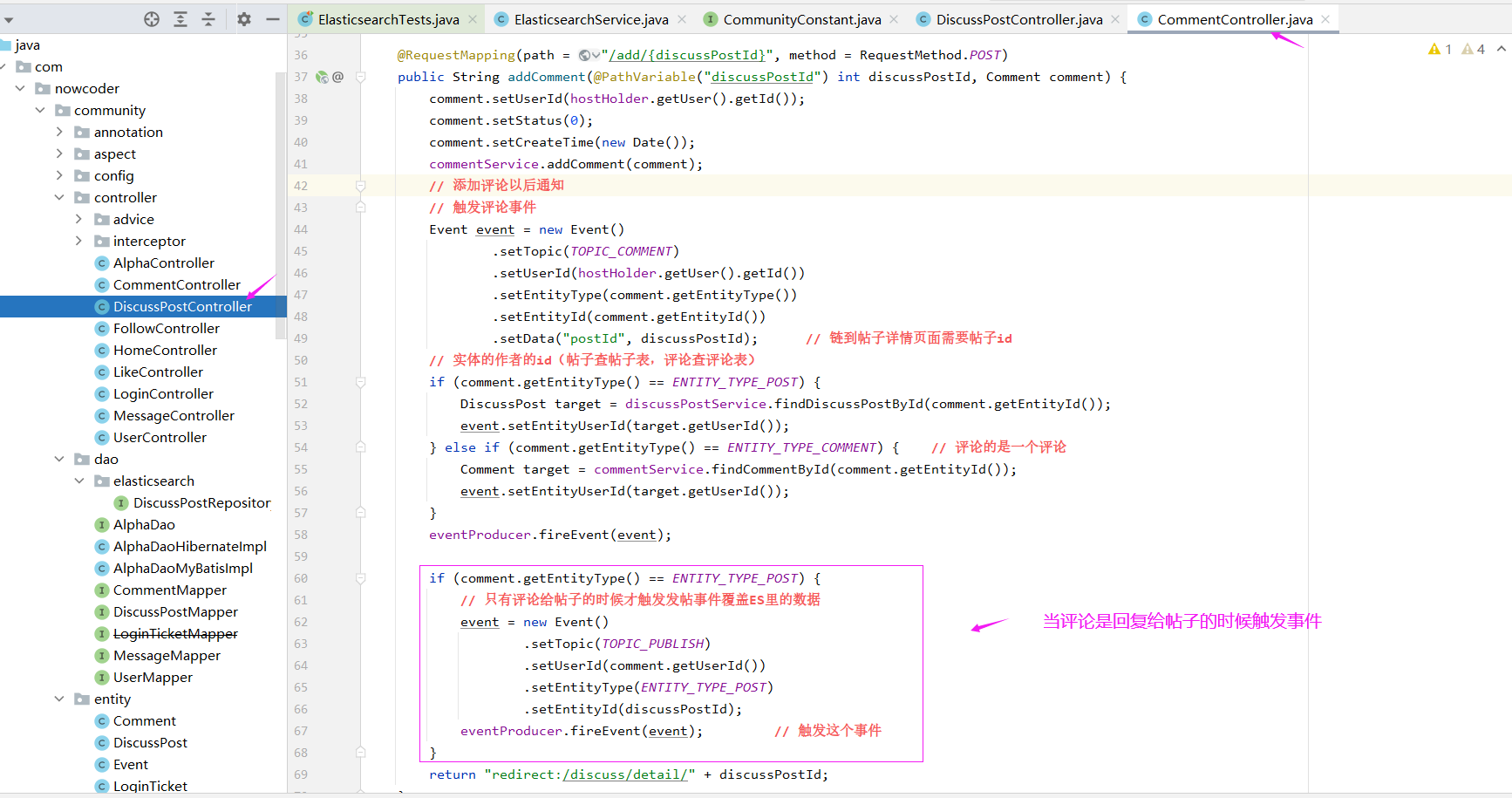
接下来我们需要去做的事情就是去消费这个事件
EventConsumer
消费者
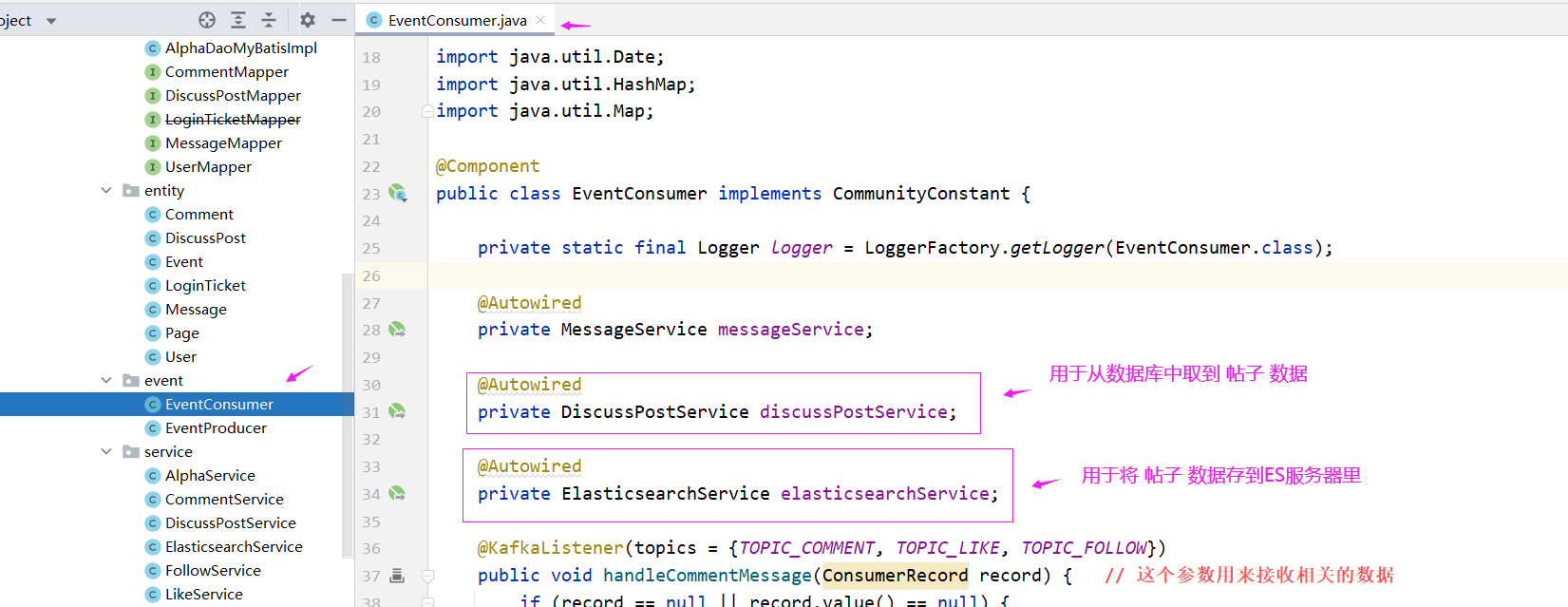
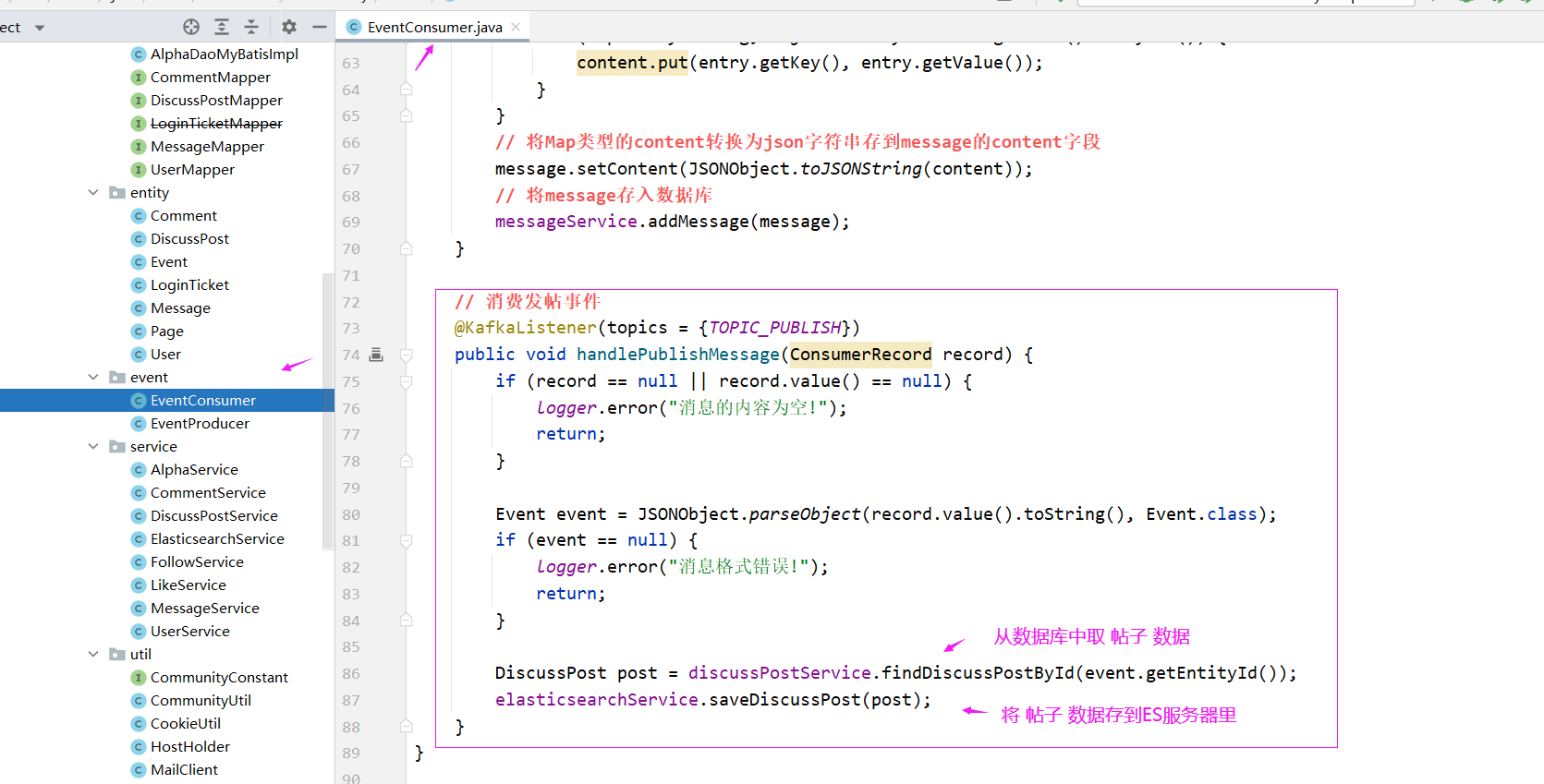
表现层
最后就是展现,当我发一个帖子,这个帖子能够同步到ES服务器里,那就能搜到它,下面我们做的就是展现
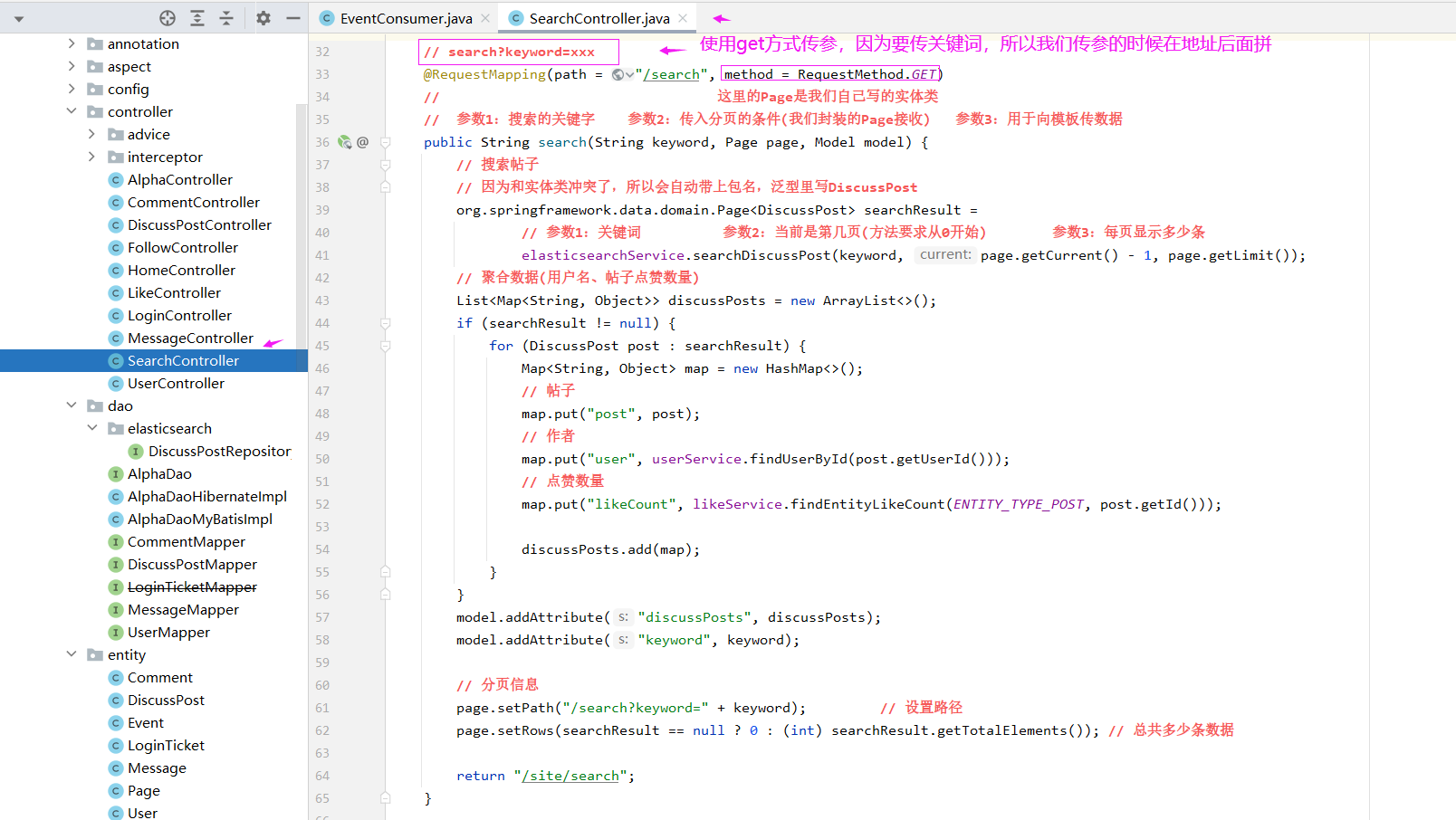
新建一个 SearchController
@Controller
public class SearchController implements CommunityConstant {
@Autowired
private ElasticsearchService elasticsearchService; // 用于查询
@Autowired
private UserService userService; // 搜到帖子以后还要展现作者
@Autowired
private LikeService likeService; // 搜到帖子以后还要展现帖子点赞的数量
// search?keyword=xxx
@RequestMapping(path = "/search", method = RequestMethod.GET)
// 这里的Page是我们自己写的实体类
// 参数1:搜索的关键字 参数2:传入分页的条件(我们封装的Page接收) 参数3:用于向模板传数据
public String search(String keyword, Page page, Model model) {
// 搜索帖子
// 因为和实体类冲突了,所以会自动带上包名,泛型里写DiscussPost
org.springframework.data.domain.Page<DiscussPost> searchResult =
// 参数1:关键词 参数2:当前是第几页(方法要求从0开始) 参数3:每页显示多少条
elasticsearchService.searchDiscussPost(keyword, page.getCurrent() - 1, page.getLimit());
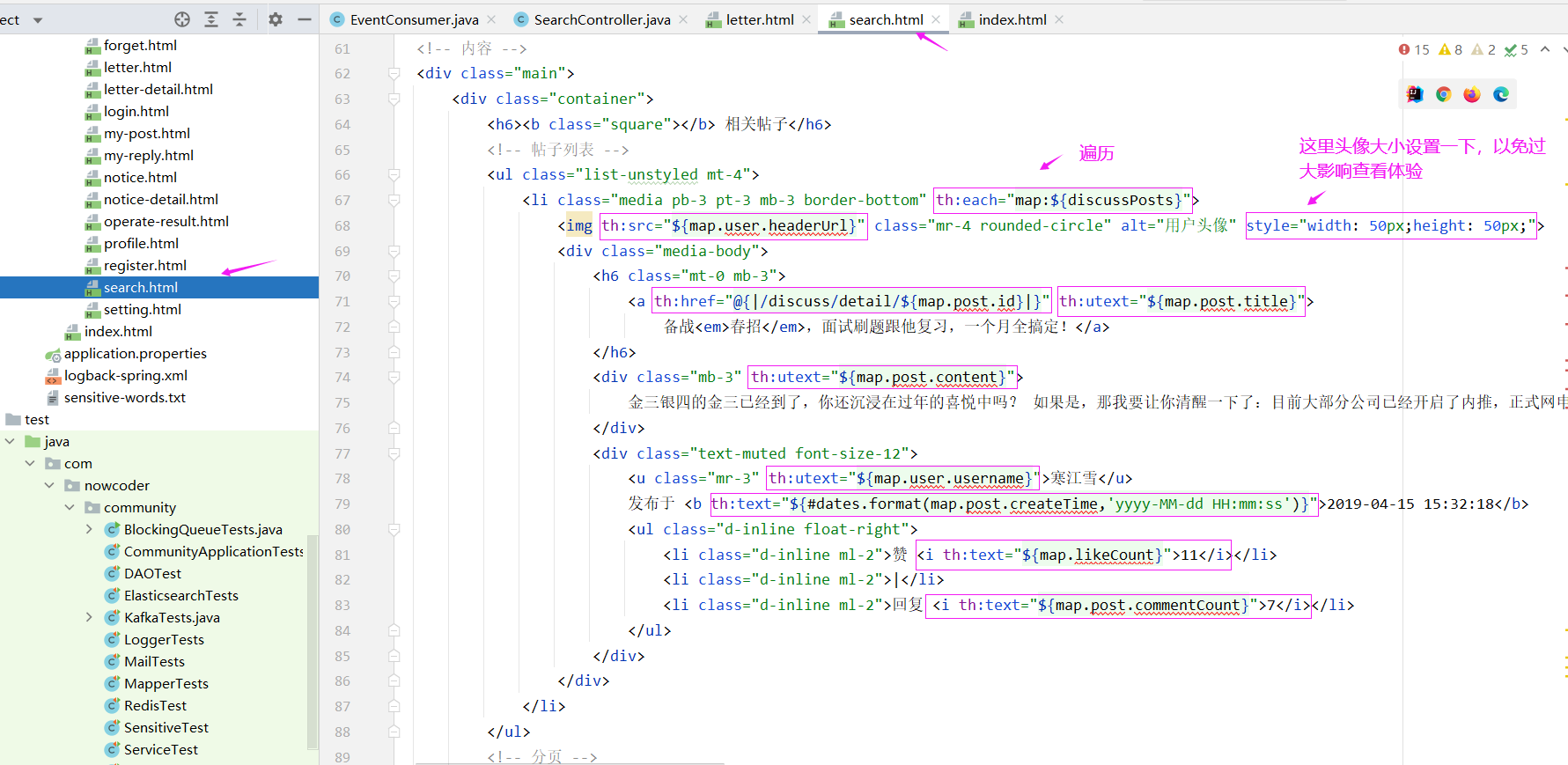
// 聚合数据(用户名、帖子点赞数量)
List<Map<String, Object>> discussPosts = new ArrayList<>();
if (searchResult != null) {
for (DiscussPost post : searchResult) {
Map<String, Object> map = new HashMap<>();
// 帖子
map.put("post", post);
// 作者
map.put("user", userService.findUserById(post.getUserId()));
// 点赞数量
map.put("likeCount", likeService.findEntityLikeCount(ENTITY_TYPE_POST, post.getId()));
discussPosts.add(map);
}
}
model.addAttribute("discussPosts", discussPosts);
model.addAttribute("keyword", keyword);
// 分页信息
page.setPath("/search?keyword=" + keyword); // 设置路径
page.setRows(searchResult == null ? 0 : (int) searchResult.getTotalElements()); // 总共多少条数据
return "/site/search";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
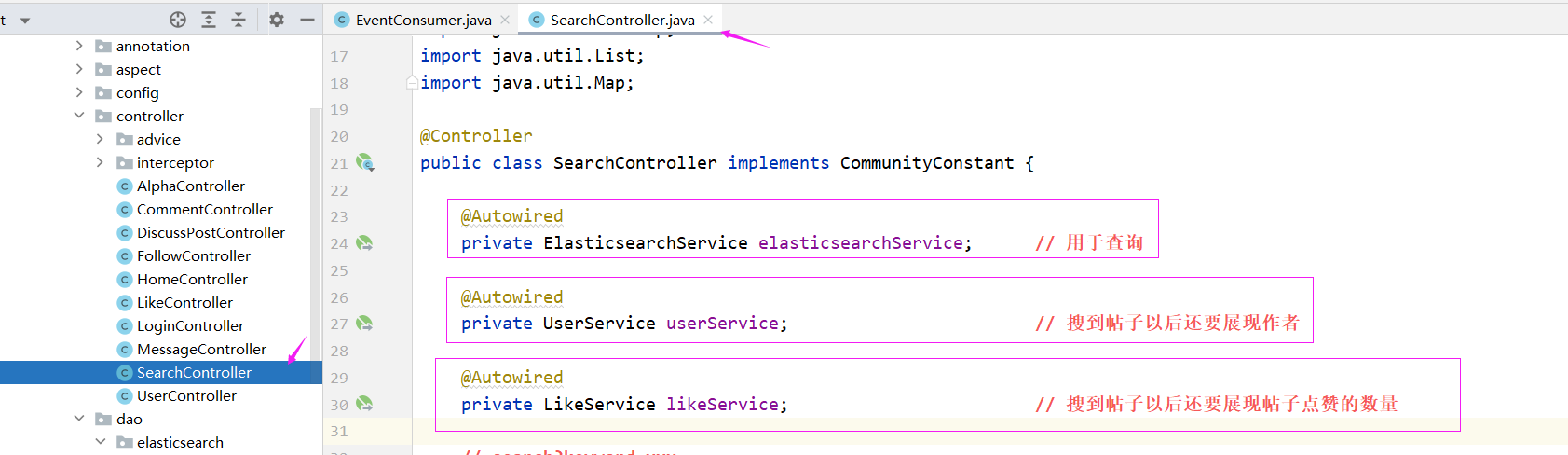
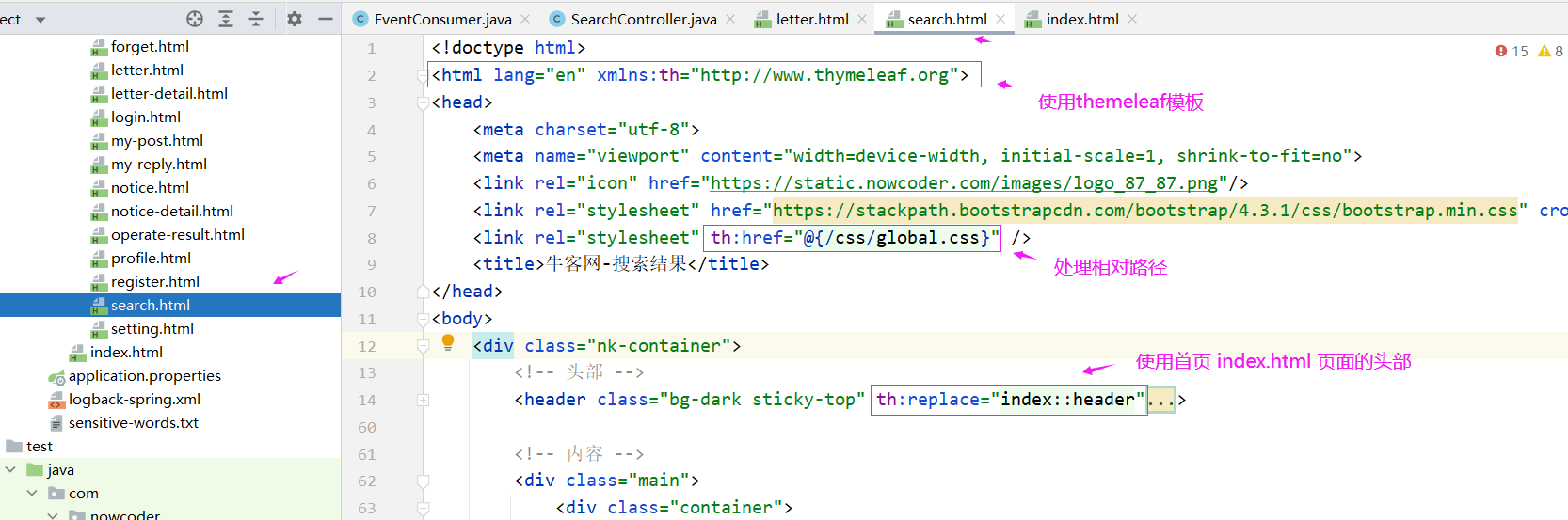
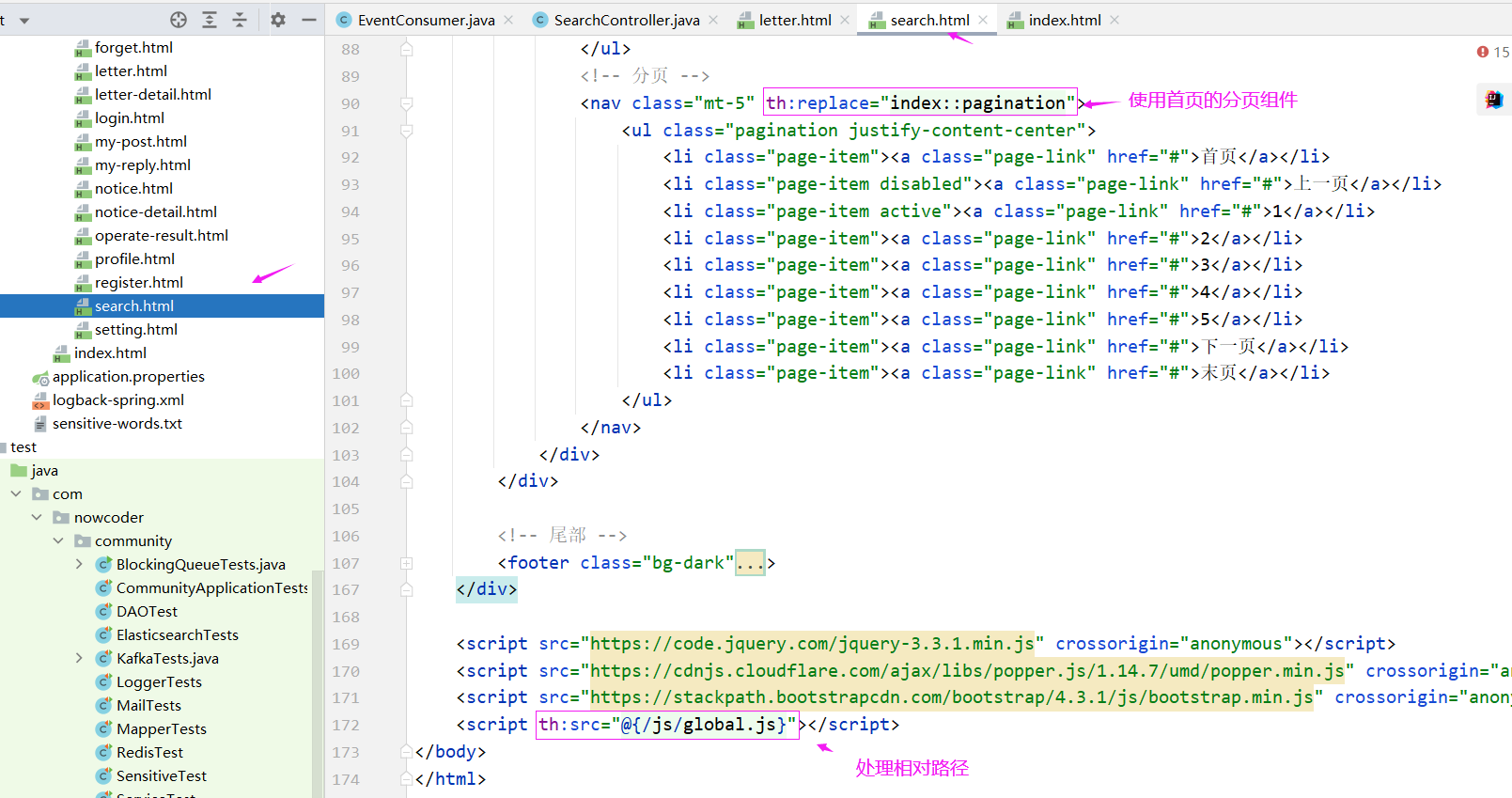
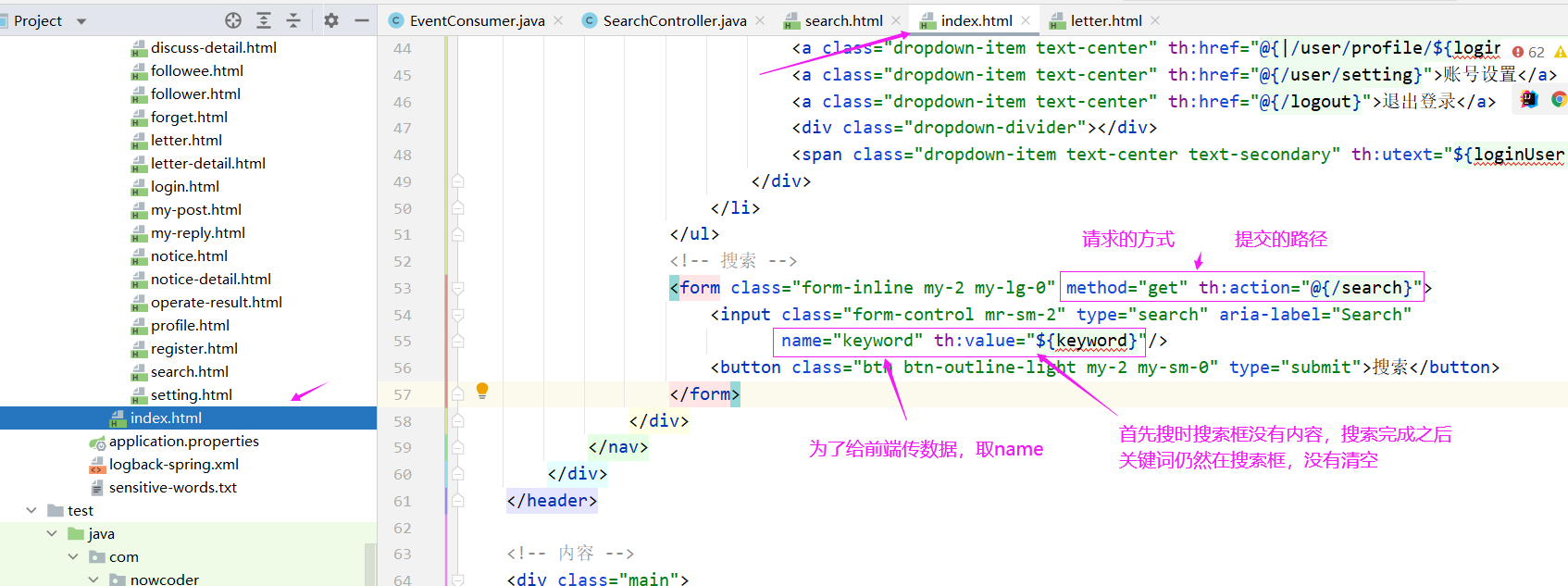
最后就是处理 html 了,首先我们需要处理的是搜索框,我们可以处理 首页index.html 的搜索框,其他页面复用这个index.html的header就可以复用这个代码了,所以我们首先要处理index.html
最后是 search.html 好显示搜索的结果