
- 1PostgreSQL 14安装和配置_postgresql14
- 2四元数和欧拉角转换_四元数转欧拉角公式
- 3实习|基于SSM的实习管理系统设计与实现(源码+数据库+文档)_实习管理系统的数据库设计
- 4ChatGPT 之 B2B 转化策略
- 5axios 请求拦截器&响应拦截器_axios请求拦截器和响应拦截器
- 6[面经] 5年前端 - 历时1个月收获7个offer
- 7Day:007(3) | Python爬虫:高效数据抓取的编程技术(scrapy框架使用)
- 8ubuntu虚拟机与windows之间实现复制粘贴功能_windows与ubuntu复制粘贴
- 9Git学习笔记之Git安装、创建版本库以及远程仓库_git安装、创建版本库、版本控制、远程仓库、分支管理、标签管理、连接及使用、组
- 10Jieba分词模式详解、词库的添加与删除、自定义词库失败的处理
python使用bs模块爬取小说数据_运用python中bs模块的相关方法小说url爬取。
赞
踩
目录
一、BS模块介绍
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
详细的BS模块介绍(参考网友):
Python中BeautifulSoup库的用法_阎_松的博客-CSDN博客_python beautifulsoup
业务需求:通过BS模块来抓取某小说里面的数据内容
二、分析页面架构
通过bs模块可以抓取到网站源代码的数据,然后分析抓取网站代码架构。首先可以看到网站每一章的标签都是div class="book-mulu"标签下面,只要搜索到标签值就可以抓到里面数据。
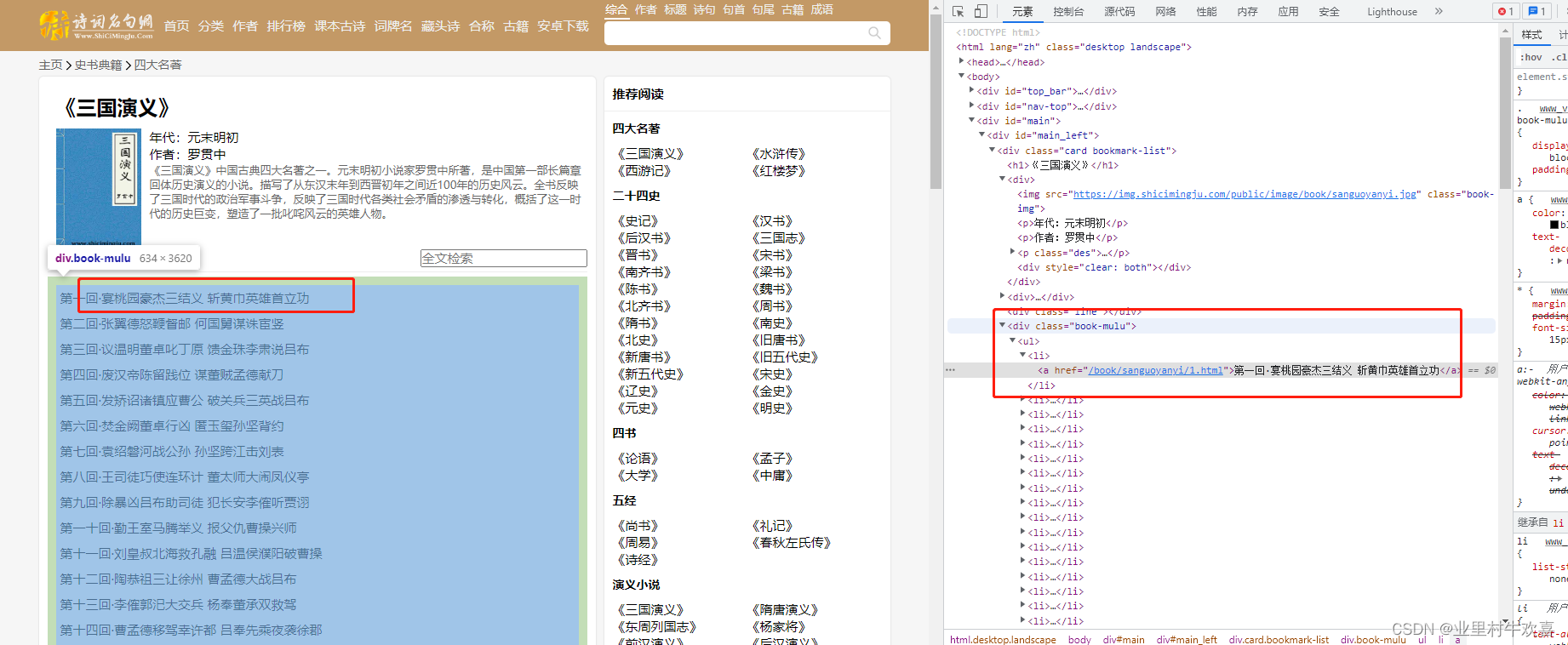
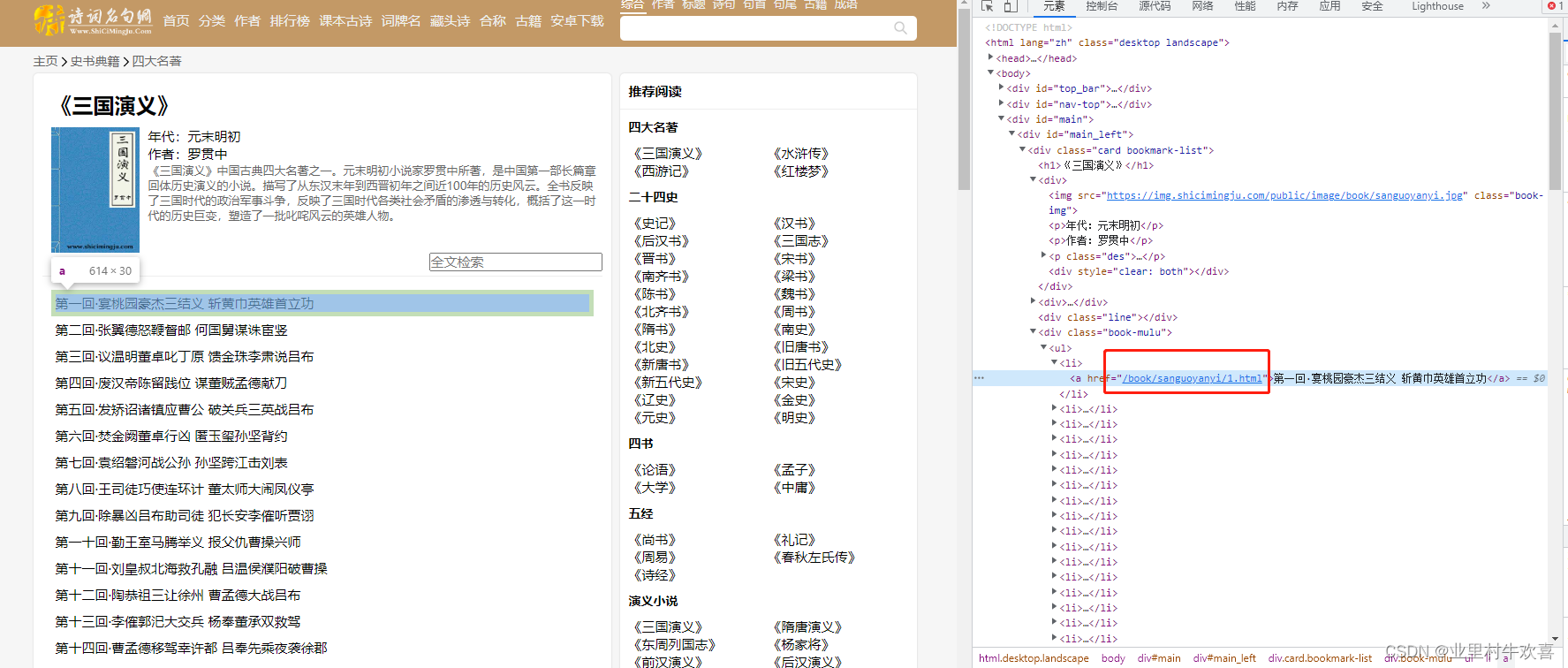
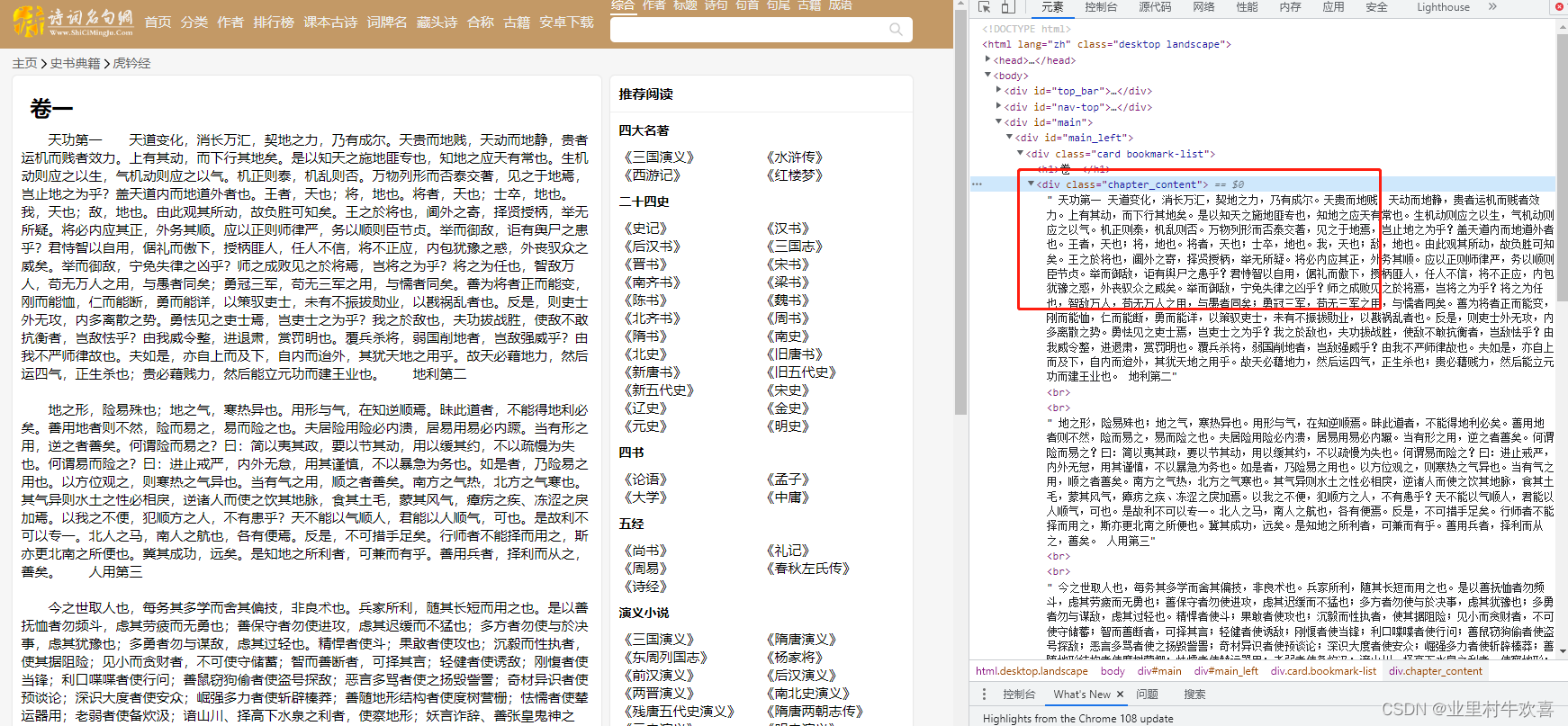
第二是内容的url是藏在a href标签里面的数据, 每个章节的sanguoyanyi/x.html来代替,x是章节数。通过一个for循环可以把数据赋值到每个列表中,在通过get方法抓取每个url中的内容,刚好每个章节的内容藏在chapter_content的标签下面,用select模块就可以抓到标签下面内容。
三、代码实现
每个代码详细功能写在注释里面了,不懂留言沟通。
- # -*- coding:UTF-8 -*-
- import requests
- import json
- from bs4 import BeautifulSoup
- import cchardet#字符编码格式化模块包
- if __name__ == "__main__":
- #浏览器请求标识符
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
- #爬取url的地址
- url='http://www.shicimingju.com/book/sanguoyanyi.html'
- #使用requests方法抓取书
- page_test = requests.get(url=url,headers=headers)
- #用cchardet的detect方法将content编码化
- page_test_coding = cchardet.detect(page_test.content)['encoding']
- #print(page_test.content.decode(page_test_coding))
- #给一个变量赋值到抓取下来的内容
- new_page_test = page_test.content.decode(page_test_coding)
- #使用bs模块的lxml方法进行解析
- soup = BeautifulSoup(new_page_test,'lxml')
- # print(soup)
- #用select方法搜索book-mulu标签下ul标签下li标签
- li_list= soup.select('.book-mulu > ul > li')
- #新建对象保存
- fp = open('./sanguo.txt','w',encoding='utf-8')
- for li in li_list:
- #标题用string字符串保存
- title = li.a.string
- #内容方面的url
- detail_url = 'http://www.shicimingju.com'+li.a['href']
- #继续抓取内容url的赋值
- detai_page_text = requests.get(url=detail_url,headers=headers).content
- #创建对象,括号中的参数是html文档(可以打开外部存储html文档的文件BeautifulSoup(open("index.html")),或者直接使用当前文件中的html字符串对象)和解析器名称
- detail_soup = BeautifulSoup(detai_page_text,'lxml')
- #查找标签chapter_content的内容
- div_tag = detail_soup.find('div',class_='chapter_content')
- #将内容使用text方法赋予新对象
- content = div_tag.text
- #写入文本中title和content加换行符
- fp.write(title+':'+content+'\n')
- #打印爬取结果
- print(title,'爬取成功!')
四、结果展示
编译结果显示正常,每个章节都抓取到了数据。
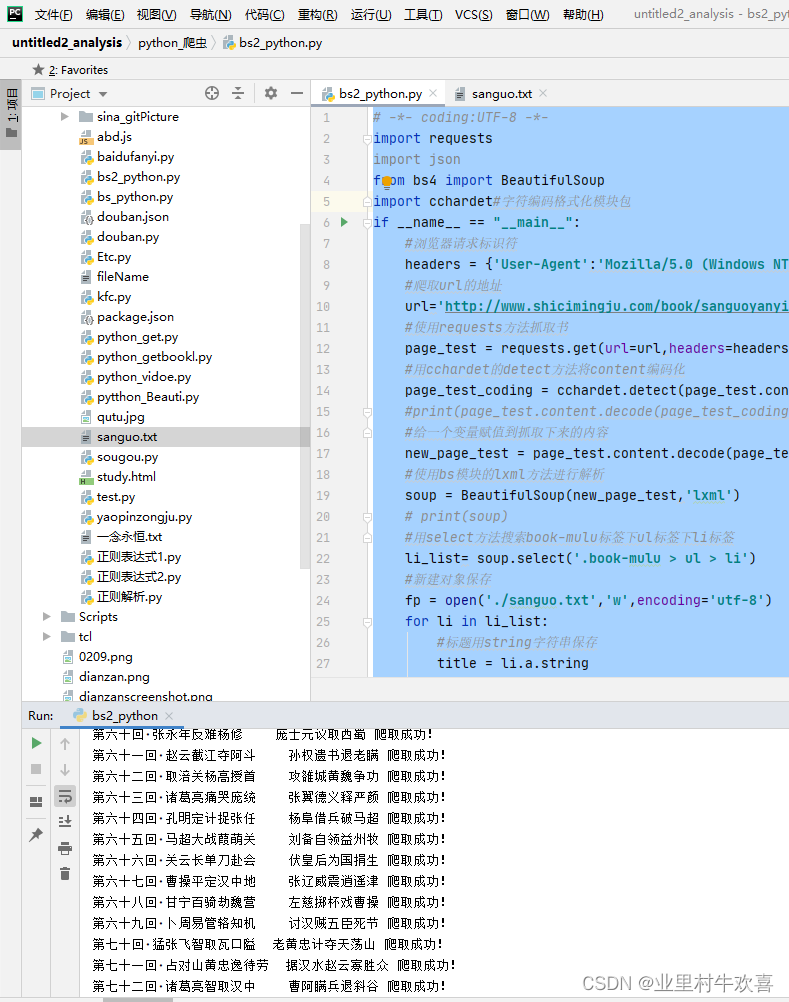
查看保存的text文档
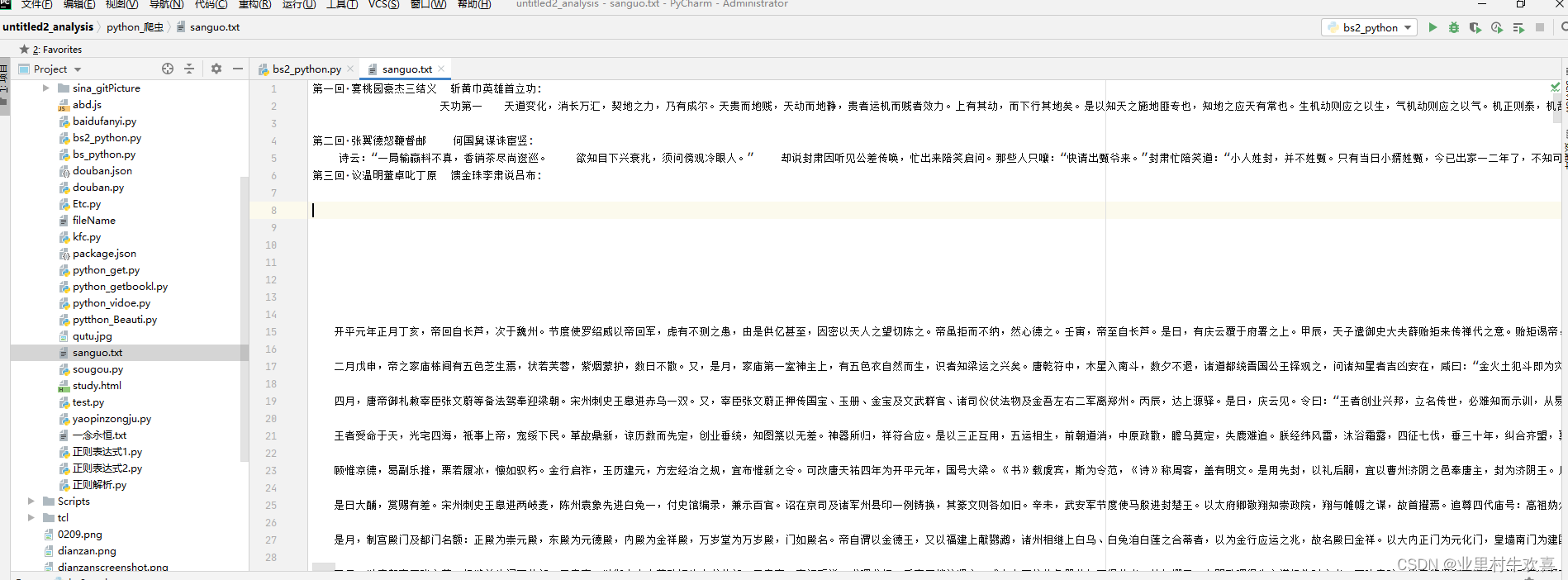
五、总结思路
requests抓取下来的数据是有带.content或者.text标签的数据,尝试了很多用.text标签抓下来的数据是乱码。后面怎么用utf-8格式变通都不行,原来response.text这个是str的数据(unicode),是requests库将response.content进行解码后的字符串。(而我们在解码的时候需要指定一个编码方式,requests在进行自动解码的时候需要猜测编码的方式,所以避免不了判断失误,就会导致解码产生乱码.)后面用content就可以行的通了。为了以防万一,使用cchardet模块来解决编码问题。Python requests乱码的五种解决办法_小龙在山东的博客-CSDN博客_python requests 乱码)
参考文献:
Python中BeautifulSoup库的用法_阎_松的博客-CSDN博客_python beautifulsoup
requests.text和requests.content的区别_、Lu的博客-CSDN博客_requests.text

