
- 1Failed toconnect to github.com port 443: 拒绝连接 Could not resolve host: github.com_github 443拒绝连接
- 2cubemx移植事件标志组These IPs still have some not configured or wrong parameter values:[FREERTOS]_- main config: these peripherals still have some n
- 3Python全栈笔记(一)_python全栈学习笔记
- 4【科普】-求素数为什么只需要求到平方根就行?_数论求素数 平方根
- 5HTML:常用标签
- 6[manifest_router.cpp(GetPagePath)-(0)] [Engine Log] can‘t find this page pages/AuthPage path
- 7文本离散表示(二):新闻语料的one-hot编码
- 8基于docker的wekan部署
- 9图解最常用的 10 个机器学习算法!
- 10Idea 插件下载缓慢,无法下载的解决方式_jetbrains插件安装缓慢
【自然语言处理】微调 Fine-Tuning 各种经典方法的概念汇总_指令微调和提示微调区别
赞
踩
【自然语言处理】微调 Fine-Tuning 各种经典方法的概念汇总
- 前言请看此
- 微调 Fine-Tuning
- SFT 监督微调(Supervised Fine-Tuning)
- 概念:监督学习,无监督学习,自监督学习,半监督学习,强化学习的区别
- 概念:下游任务
- 概念:再利用(Repurposing),全参微调(Full Fine-Tuning)和部分参数微调(Partial Fine-tuning)
- 线性探测(Linear Probing)微调策略
- 其他一些简单的微调策略
- 概念:提示(Prompt)和指令(Instruction)
- 提示微调(Prompt Tuning)微调技术
- 指令微调(Instruction Tuning)微调技术
- LoRA 低秩自适应(Low-Rank Adaptation)训练技术
- 适配器学习(Adapter Learning)微调技术
- 前缀微调(Prefix-Tuning)微调技术
- P微调(P-Tuning)微调技术
- PEFT 参数高效微调(Parameter-Efficient Fine-Tuning)开源参数高效微调库
- RL 强化学习(Reinforcement Learning)
- RLHF 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback)
前言请看此
(1)一些概念源自LLM(Chatgpt)和网络(百度/知乎等),笔者进行了初步检查。
(2)由于其中的各种知识比较琐碎,为了形成较为结构化的知识体系,且使用最简单的、几乎无公式的介绍,故作此博客。
(3)着重为自然语言处理领域NLP的,CV领域的不是很详细讲述了
上一篇博客:【机器学习与自然语言处理】预训练 Pre-Training 各种经典方法的概念汇总
(4)比较简单或者过于的概念就不介绍了,默认大家都学会了。不然要写的太多了。
比如损失,损失函数,神经网络几个概念,不认识的话单独先去学一下。
微调 Fine-Tuning
- 微调 是指在已经经过预训练的模型基础上,通过使用任务特定的数据集进行额外的训练,以使模型适应特定的任务或领域。通常情况下,微调是在一个相对较小的数据集上进行的,该数据集与模型最初预训练的数据集可能有所不同。
- 迁移学习 是一种机器学习范畴,旨在将从一个任务(源任务)中学到的知识应用到另一个任务(目标任务)上。
- 我们发现,微调的概念和机器学习中的迁移学习概念比较类似,分析一下我们为什么要微调,或者迁移学习。
即【微调的优势】
(1)站在巨人的肩膀上:前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
(2)训练成本可以很低,任务特定的数据集可以几千或者几万条,这远远低于预训练的数据集大小。
(3)适用于小数据集:对于数据集本身很小的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。(减少过拟合现象)
SFT 监督微调(Supervised Fine-Tuning)
- 监督微调 是一种利用带有标签的数据对预训练模型进行进一步训练的方法。
其实就是监督学习在微调阶段的应用
概念:监督学习,无监督学习,自监督学习,半监督学习,强化学习的区别
- 强化学习涉及一个智能体(agent)与环境的交互。智能体通过在环境中采取动作来达到某个目标,通过环境的反馈(奖励或惩罚)来调整其行为。
- 区分其他几个学习方式,可以按照训练阶段 和 标签进行区分分类:
- 无监督学习:预训练阶段,大规模无标签语料
- 监督学习:微调阶段,小规模有标签语料
- 自监督学习:预训练或微调阶段都可,语料本身没有标签,但可以通过算法/神经网络/模型等,去计算出标签
- 半监督学习:在预训练阶段使用大规模无标签语料,在微调阶段使用小规模有标签语料。是横跨两个阶段的
概念:下游任务
- 下游任务是指在迁移学习或微调中,模型在预训练之后,通过额外的训练适应于特定任务或领域的任务。下游任务的选择取决于应用的需求和目标。
- 我们微调肯定是首先得确定下游任务,然后按照具体的任务,使用某些模型、算法与数据集进行微调模型。
- 下面列了一些比较常见的下游任务。
可以看到,基本上分为判别式任务和生成式任务。
(1)文本分类:
对文本进行分类,如情感分析、主题分类、垃圾邮件过滤等。
(2)命名实体识别 (NER):
从文本中标注和提取特定实体的信息,如人名、地名、组织名等。
(3)文本生成:
生成自然语言文本,包括文章摘要、对话生成、文章创作等。
(4)目标检测:
在图像中检测和标注出现的对象,并用边界框表示。
(5)语义分割:
将图像中的每个像素分配给特定的语义类别,以实现像素级的语义分割。
(6)图像分类:
将图像分为不同的类别,通常通过预测图像中出现的主要对象或场景。
(7)机器翻译:
将源语言的文本翻译成目标语言的文本。
(8)问答系统:
回答用户提出的自然语言问题,通常在给定的上下文中查找答案。
(9)语音识别:
将音频信号转换为文本,通常用于语音助手和语音命令的应用。
(10)图像生成:
生成新的图像,如图像合成、风格迁移等。
(11)推荐系统
为用户推荐特定的商品、内容或服务,基于用户行为和兴趣。
概念:再利用(Repurposing),全参微调(Full Fine-Tuning)和部分参数微调(Partial Fine-tuning)
- 在迁移学习中,按照微调模型的全部参数,还是部分参数,我们分为如下两类。
- 全参微调(Full Fine-Tuning)
指在预训练模型的基础上,对整个模型的所有参数进行微调。在这个过程中,模型权重会根据目标任务的数据进行全面调整,而不仅仅是最后几层或最后一层的权重。
这意味着预训练模型的所有层都能够适应新任务,但可能需要较大的目标任务数据集来防止过拟合 - 部分参数微调(Partial Fine-tuning)
只对模型的部分参数进行微调,通常是最后几层或最后一层的参数。这种方式在目标任务数据较少的情况下更常见,以防止过拟合并提高模型的泛化能力。 - 重新利用(Repurposing)或者叫再利用
指的是将预训练模型应用于一个新的任务,而这个过程可能包括对模型的一部分参数进行微调。
再利用可以分为全参微调和部分参数微调。
线性探测(Linear Probing)微调策略
- 在自然语言处理(NLP)领域中,“linear probing” 是一种用于微调预训练模型的方法。该方法的目标是通过 添加一个简单的线性层(线性分类器) 来微调模型,以适应特定的任务。这个线性层是一个全连接层,它的输出维度等于目标任务的类别数(对于分类任务)或任务特定的输出维度。
- **它冻结之前的所有参数,只训练该线性分类器层的参数。**所以是部分参数微调。
注:区别与hash碰撞检测的线性探测法。
其他一些简单的微调策略
- Prompt Tuning
- Partial-k
只微调模型的最后k层,冻结其他层 - MLP-k
增加一个k层的MLP(多层感知机)作为分类器 - Side-Tuning
训练一个 side 网络,添加和调整辅助任务(side tasks)来提高模型性能。

- Bias
只微调网络的 bias 参数
- Partial-k
概念:提示(Prompt)和指令(Instruction)
- ChatGPT/InstructGPT详解
实话实说,这是两个非常令人搞混的概念,弄清他们,有助于弄明白后面的提示微调和指令微调技术。 - 提示(Prompt)和指令(Instruction)都是用户对LLM的输入的详细上下文的描述。
区别在于- 提示:类似于MLM技术,构造好提示后,把用户希望获得的内容变成MLM中[MASK]的token或留白,让模型去回答补全。类似于完型填空。
例子:给女朋友买了这个项链,她很喜欢,这个项链太____了。 - 指令:即通过指令或命令, 告诉模型需要做什么,我需要得到什么。
例子:请告诉我一个英语双关冷笑话。
- 提示:类似于MLM技术,构造好提示后,把用户希望获得的内容变成MLM中[MASK]的token或留白,让模型去回答补全。类似于完型填空。
- 注意:有时候人们提到的 prompt 的概念包含了 instruction 的概念
但最好还是分清这两个概念,毕竟不大一样。
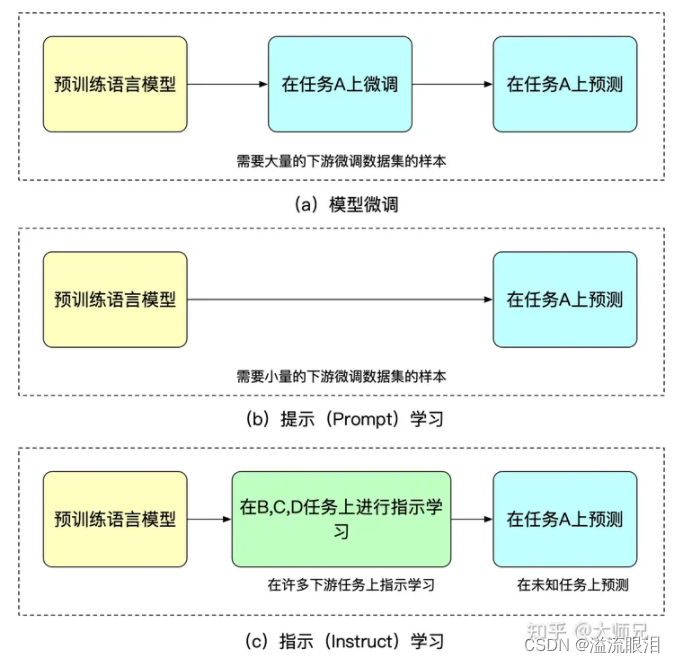
提示微调(Prompt Tuning)微调技术
- 实际案例说明AI时代大语言模型三种训练技术及其区别——Prompt-Tuning、Instruction-Tuning和Chain-of-Thought
- 由于BERT的预训练使用了MLM,所以这类模型对于提示微调训练来说比较合适
- 我们发现,比如BERT它本来就是做完形填空比较合适的,预训练中也没有做比如情感分析之类的任务。
但是当我们构建出今天天气真好。这句句子的情感是 __ 的。的 prompt 之后,BERT 根据完形填空的方法,自然倾向于填入积极的/正面的,就可以迁移到情感分析的下游任务去了! - 比较重要的是如何构建 prompt,以及如何构建好的prompt
但我们发现跟如何构建好的instruction方法是类似的,所以统一写在这里了。
如何构建好的 prompt 或 instruct
(1)清晰和简洁
Prompt 应该明确和简洁,避免模糊或复杂的语言。清晰的 prompt 有助于模型正确理解任务。
糟糕的 prompt:请解释一下这个问题的背景和相关内容,以及它的历史。
好的 prompt:简要解释这个问题的背景和历史。
(2)任务导向
prompt 应该明确指导模型执行特定的任务,避免过于开放式的描述。任务导向的 prompt 有助于模型集中精力解决特定问题。
糟糕的 prompt:谈谈你对这个主题的看法。
好的 prompt:根据给定的数据,预测下个月的销售额。
(3)关键词和实体
使用关键词和实体有助于引导模型关注任务的核心内容。这可以通过在 prompt 中强调关键词或提到实体来实现。
糟糕的 prompt:介绍一下这个产品。
好的 prompt:描述这个产品的特性和优势,特别关注 [产品名称] 的创新点。
(4)多样性和变化性
为了提高模型的鲁棒性,可以设计多样性的 prompt,涵盖任务的不同方面,以及各种可能的输入方式。
不同形式的好 prompts:
给定一段文本,总结其中的关键观点。
在给定的图像上标记出所有出现的物体。
用简短的话语回答:[问题]。
(5)验证和调整
在应用 prompt 前,可以通过试验和验证来不断调整。观察模型对不同 prompt 的表现,以确保 prompt 对任务的影响是积极的。
尝试不同的 prompt 表达方式,比如在问句中加入否定词、使用不同的关键词等,观察模型的响应。
指令微调(Instruction Tuning)微调技术
- 对于指令微调,就感觉是提示微调的一个进一步的版本。
从简单的完形填空上升到了基于单个或多个指令,让模型进行复杂操作。
即,指令微调可以应对多个下游任务,而不是单单的一个简单任务。 - 对于训练集,我们可以这样构建:
- 准备一组指令集,比如 “该文本的情感是正面的还是负面的?”
- 准备带标签数据集,比如 情感分类任务的标签可以是“正面”或“负面”
- 把指令集和数据集的提问进行拼合,比如 “该文本的情感是正面的还是负面的?这家餐厅的食物很好吃。”
- 若回答效果比较差,则对指令进行微调。之后进行模型训练即可。
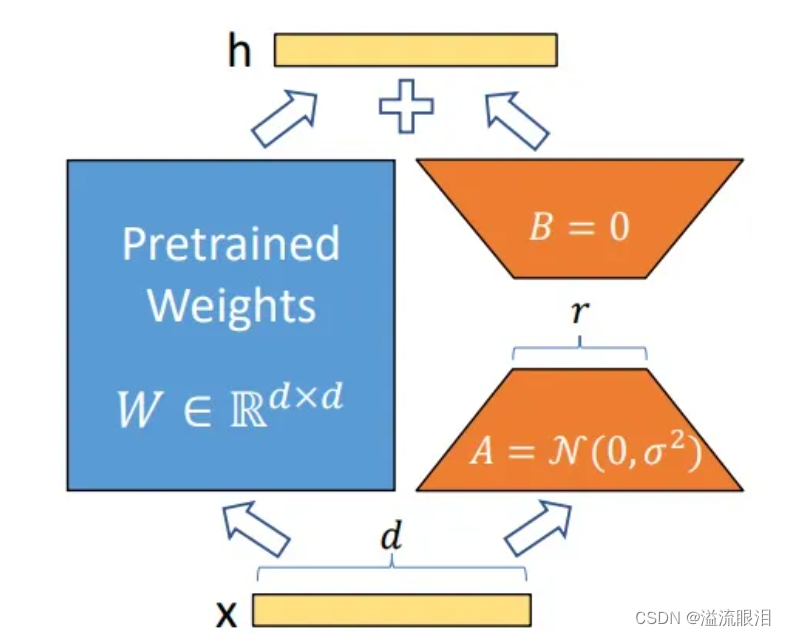
LoRA 低秩自适应(Low-Rank Adaptation)训练技术
- 大模型微调(finetune)方法总结-LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning
- LoRA认为,随着LLM参数不断增多,全参微调的消耗时间和资源较多,而其他一些微调效果不佳
LoRA还认为,LLM过度参数化了,可以通过其内在的低纬度参数进行任务适配
LoRA允许我们通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。 - 在原始预训练语言模型PLM(Pertrained Language Model)旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的内在秩。
- 训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。
- 模型的输入输出维度不变,输出时将BA与PLM的参数叠加。
- 用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵
- 因此,LoRA 的训练成本很低,且比较通用,也有一定的效果(但是想要很好的效果还得全参微调或者其他方法)
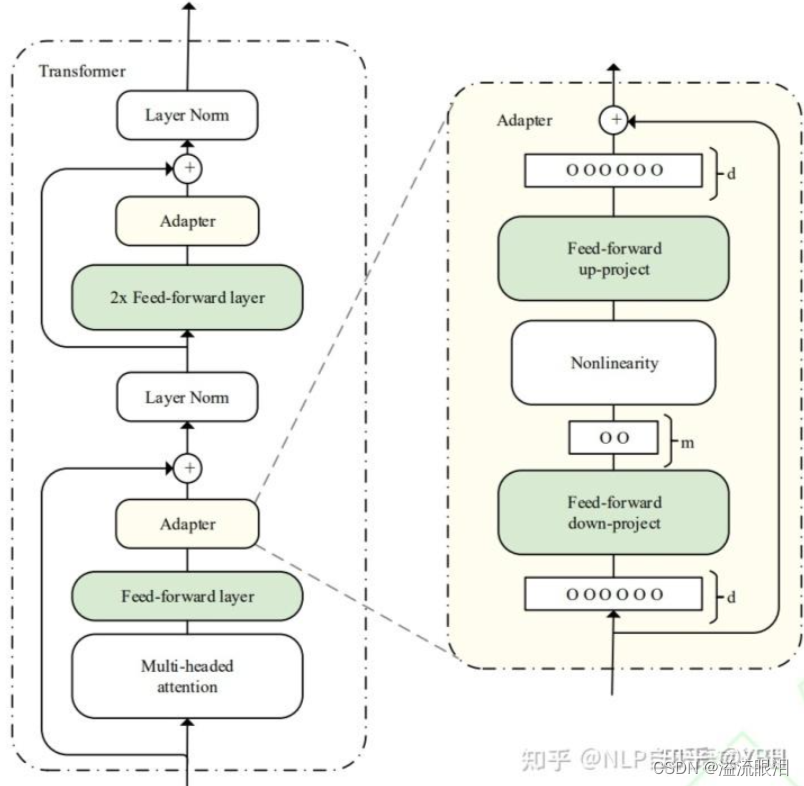
适配器学习(Adapter Learning)微调技术
- Parameter-efficient transfer learning系列之Adapter
更详细介绍了 adapter 与 adapter fusion。 - Adapter引入NLP领域,作为全模型微调的一种替代方案。
在预训练模型每一层(或某些层)中添加Adapter模块,微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。 - 每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度d投影到m,通过控制m的大小来限制Adapter模块的参数量,通常情况下m<<d。在输出阶段,通过第二个前馈子层还原输入维度,将m重新投影到d,作为Adapter模块的输出。通过添加Adapter模块来产生一个易于扩展的下游模型,每当出现新的下游任务,通过添加Adapter模块来避免全模型微调与灾难性遗忘的问题。Adapter方法不需要微调预训练模型的全部参数,通过引入少量针对特定任务的参数,来存储有关该任务的知识,降低对模型微调的算力要求。
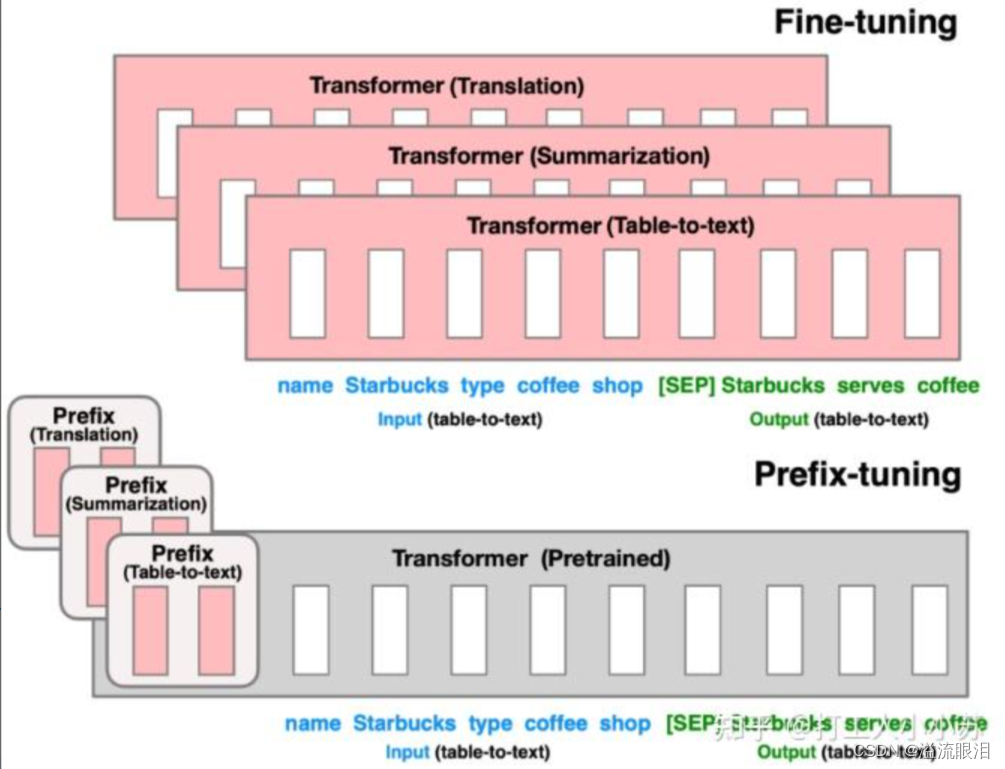
前缀微调(Prefix-Tuning)微调技术
- 深入理解Prefix Tuning
LLM微调方法:Prompt Tuning And Prefix Tuning - 相比与离散的
prompt,需要人工寻找比较合适的提示
为何不提出连续的prompt? - 前缀微调在输入token之前构造一段任务相关的virtual tokens作为Prefix
然后,在训练的时候只更新Prefix部分的参数,而 PLM 中的其他部分参数固定。
不同任务就对应不同的 Prefix - 这样的话,需要在 transformer 中的每层稍作修改,不同任务就可以获得不同的 Prefix 头了。

P微调(P-Tuning)微调技术
- 大模型参数高效微调技术实战(三)-P-Tuning
该方法将 Prompt 转换为可以学习的 Embedding 层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。 - 相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。

PEFT 参数高效微调(Parameter-Efficient Fine-Tuning)开源参数高效微调库
- HF-PEFT
详细操作看HF社区吧。 - PEFT 是 Huggingface 开源的一个参数高效微调库,它提供了最新的参数高效微调技术,并且可以与 Transformers 和 Accelerate 进行无缝集成。
- PEFT 目前支持
LoRA
Prefix Tuning & P-Tuning v2
P-Tuning
Prompt Tuning
AdaLoRA
IA3
RL 强化学习(Reinforcement Learning)
- 一般强化学习在博弈、游戏、棋类中,比较常见
但是在自然语言处理领域用到语言模型微调中, 使用则不大相同了。 - 在模型微调阶段,一般使用SFT监督微调
但现在有一些人提出了基于强化学习的一些微调方式,且有一些浪潮迹象。
目前最火的就是RLHF
RLHF 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback)
- 一文读懂ChatGPT中的强化学习
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
这一篇比较推荐阅读。 - RLHF是为了引入人类反馈,使用人类偏好数据进行训练,让模型产生符合人类喜好的回答。
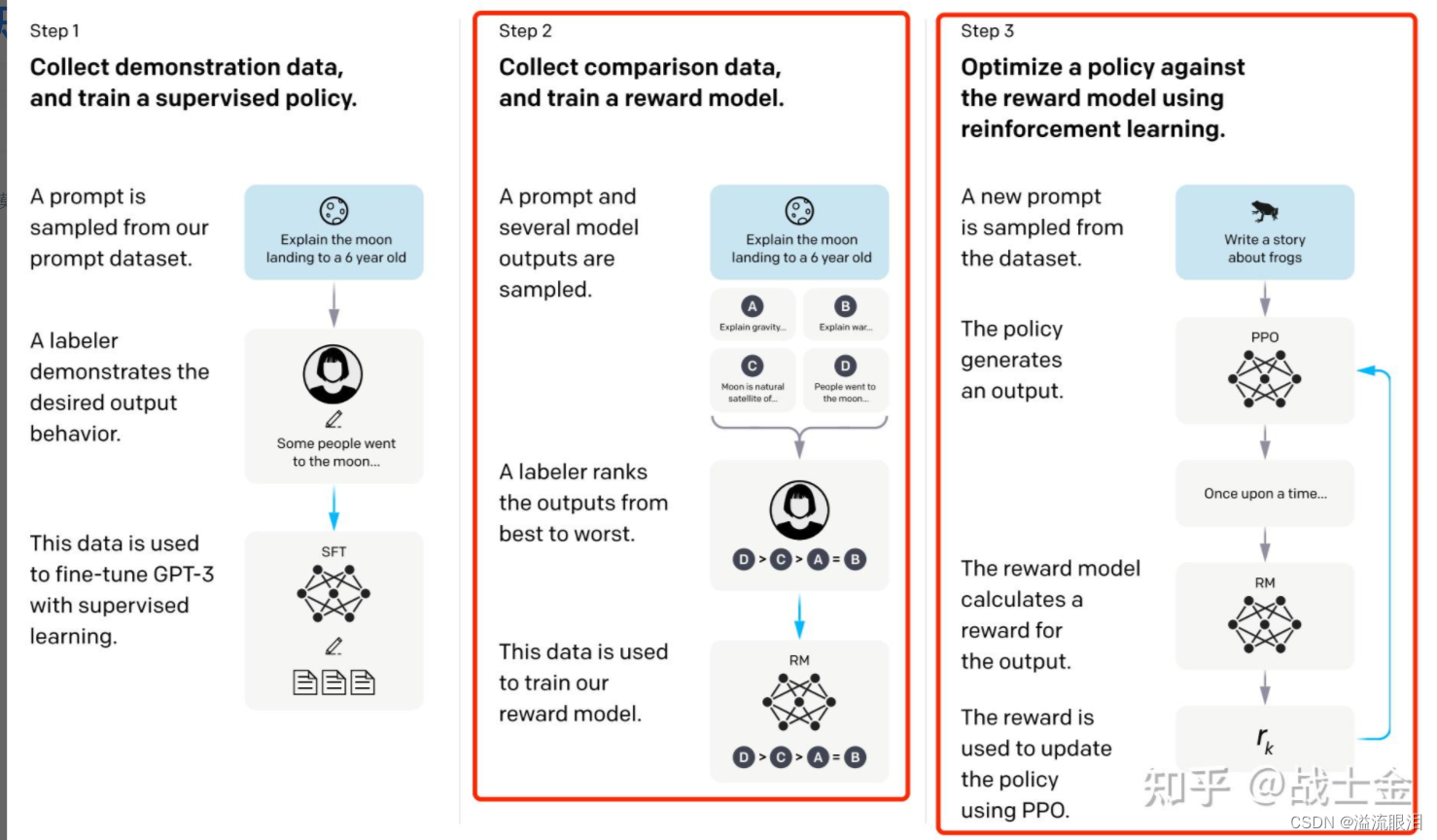
- 经典RLHF一般就如下图所示三个阶段
- 第一步,收集带标签数据,训练一个SFT模型,这里也被叫做策略(Policy)
- 第二步,收集偏好数据,训练一个RM奖励模型(Reward Model)
- 第三步,用一个强化学习的算法来微调该SFT模型,比如经典的PPO算法。
- RL中,有经典概念 智能体、环境、状态、动作
在NLP语境下,如何对应呢
智能体:指语言模型
环境:指上下文
状态:指语言模型已经输出的前文
动作:指接下来选择输出的内容
总收益:语言模型输出完后,人们对该文本的偏好程度
即时收益:语言模型输出下一个token的暂时收益。 - 在RLHF-PPO中,一共有四个主要模型
Actor Model:演员模型,这就是我们想要训练的目标语言模型
Critic Model:评论家模型,它的作用是预估总收益
Reward Model:奖励模型,它的作用是计算即时收益
Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差) - 其中,Actor/Critic Model(在RLHF阶段是需要训练的)
在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic) - 而 Reward/Reference Model 是参数冻结的。
再次说明下,其中的各种复杂的损失函数可以在上述提到的博文中阅读。 - 现在PPO已经出了很多新的替代方案了(由于RLHF-PPO运用起来比较复杂),比如DPO等。更新的内容需要阅读相关论文。

