
- 1移动云助力智慧交通数智化升级_移动云在公交安全、出行、物流配送、停车监管等场景提供大链接算力支撑的应用案例
- 2[STM32] Keil MDK 新建工程编译不通过(warning: #2803-D和Error: L6218E)解决方法备忘
- 3《2023金融科技·校园招聘白皮书》新鲜出炉|牛客独家_校招白皮书
- 4最近读的AIGC相关论文思路解读_paint by example
- 5gradle mysql jdbc_在 Gradle 中使用 MyBatis Generator
- 615个优质的源码下载
- 7【机试题(实现语言:python3)】图片整理-字符串按ascii排序输出_本题目要求输入n个字符串,按照ascii码值排序后,依次输出。 输入格式: 一行输入整
- 8linux centos 7 服务器指令,Linux命令ntpdate
- 9Python + ESP32 DIY自动感应智能皂液器 避免触摸更安全_自动皂液器电路图
- 10linux入门---制作进度条_printf打印进度条
一文读懂湖仓一体,什么是数据仓库和数据糊_数据湖 数据仓库
赞
踩
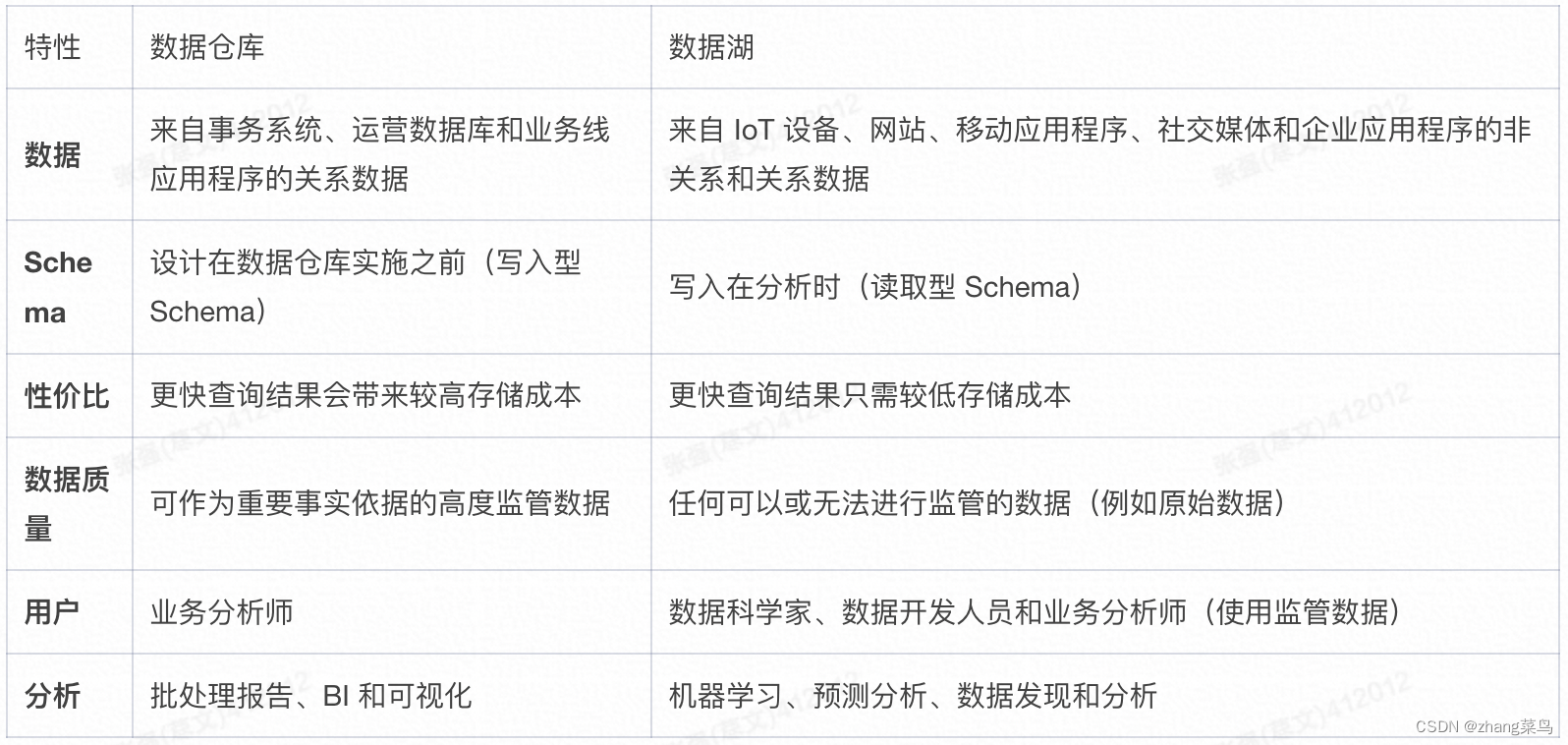
一、数仓和数据湖的对比
二、数据湖特征
数据湖具有以下特点:
a) 容量大
数据湖汇 聚吸收各个业务数据源流,容纳散落在各处的数据,理论上,存储空间巨大。
b) 格式多
数据湖架构面向多数据源的信息存储,可以快 速高效地采集、存储、处理大量来源不同、格式不同 的原始数据,这其中包括文本、图片、视频、音频、网 页等各类无序的非结构化数据,能把不同种类的数 据汇聚存储在一起,并对汇聚后的数据进行管理, 建立数据之间的关联关系,具有很强的兼容性。
c) 处理速度快
数据湖技术能将各类原始数据快速转化为可 以直接提取的、分析、使用的标准格式,统一优化数 据结构并对数据进行分类存储,根据业务需求,对 存储的数据进行快速的查询、挖掘、关联和处理,并实时传输给末端用户。
d) 体系结构
由于Hadoop也能基于分布式文件系统来存储处理多类型数据,因此许多人认为Hadoop的工作机理就是数据湖的处理机制。当然,Hadoop基于其分布式、可横向扩展的文件系统架构,可以管理和处理海量数据,但是它无法提供数据湖所需要的复杂元数据管理功能,最直观的表现是,数据湖的体系结构表明数据湖是由多个组件构成的生态系统,而Hadoop仅仅提供了其中的部分组件功能。
三、未来的发展趋势
说了这么多的数据湖的特点和好处,那是不是就可以完全摒弃数据仓库转而搞数据湖了呢?其实结果并不尽然,当下数据湖的概念还处在多方研究探索阶段,但是当下有一个比较火的方案可以参考建设,那就是数据仓库和数据湖合起来建设,统一称之为“湖仓一体”。
四、什么是“湖仓一体”
Data Lakehouse(湖仓一体)是新出现的一种数据架构,它同时吸收了数据仓库和数据湖的优势,数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能为公司进行数据治理带来更多的便利性。那么何为Data Lakehouse呢,它具备些什么特性呢?
一直以来,我们都在使用两种数据存储方式来架构数据:
数据仓库:数仓这样的一种数据存储架构,它主要存储的是以关系型数据库组织起来的结构化数据。数据通过转换、整合以及清理,并导入到目标表中。在数仓中,数据存储的结构与其定义的schema是强匹配的。
数据湖:数据湖这样的一种数据存储结构,它可以存储任何类型的数据,包括像图片、文档这样的非结构化数据。数据湖通常更大,其存储成本也更为廉价。存储其中的数据不需要满足特定的schema,数据湖也不会尝试去将特定的schema施行其上。相反的是,数据的拥有者通常会在读取数据的时候解析schema(schema-on-read),当处理相应的数据时,将转换施加其上。
现在许多的公司往往同时会搭建数仓、数据湖这两种存储架构,一个大的数仓和多个小的数据湖。这样,数据在这两种存储中就会有一定的冗余。
Data Lakehouse的出现试图去融合数仓和数据湖这两者之间的差异,通过将数仓构建在数据湖上,使得存储变得更为廉价和弹性,同时lakehouse能够有效地提升数据质量,减小数据冗余。在lakehouse的构建中,ETL起了非常重要的作用,它能够将未经规整的数据湖层数据转换成数仓层结构化的数据。
Data Lakehouse概念是由Databricks提出的,在提出概念的同时,也列出了如下一些特性:
●事务支持:Lakehouse可以处理多条不同的数据管道。这意味着它可以在不破坏数据完整性的前提下支持并发的读写事务。
●Schemas:数仓会在所有存储其上的数据上施加Schema,而数据湖则不会。Lakehouse的架构可以根据应用的需求为绝大多数的数据施加schema,使其标准化。
●报表以及分析应用的支持:报表和分析应用都可以使用这一存储架构。Lakehouse里面所保存的数据经过了清理和整合的过程,它可以用来加速分析。同时相比于数仓,它能够保存更多的数据,数据的时效性也会更高,能显著提升报表的质量。
●数据类型扩展:数仓仅可以支持结构化数据,而Lakehouse的结构可以支持更多不同类型的数据,包括文件、视频、音频和系统日志。
●端到端的流式支持:Lakehouse可以支持流式分析,从而能够满足实时报表的需求,实时报表在现在越来越多的企业中重要性在逐渐提高。
●计算存储分离:我们往往使用低成本硬件和集群化架构来实现数据湖,这样的架构提供了非常廉价的分离式存储。Lakehouse是构建在数据湖之上的,因此自然也采用了存算分离的架构,数据存储在一个集群中,而在另一个集群中进行处理。
●开放性:Lakehouse在其构建中通常会使Iceberg,Hudi,Delta Lake等构建组件,首先这些组件是开源开放的,其次这些组件采用了Parquet,ORC这样开放兼容的存储格式作为下层的数据存储格式,因此不同的引擎,不同的语言都可以在Lakehouse上进行操作。
Lakehouse的概念最早是由Databricks所提出的,而其他的类似的产品有Azure Synapse Analytics。Lakehouse技术仍然在发展中,因此上面所述的这些特性也会被不断的修订和改进。
五、湖仓一体化有什么好处?
湖仓一体能发挥出数据湖的灵活性与生态丰富性,以及数据仓库的成长性与企业级能力。帮助企业建立数据资产、实现数据业务化、进而推进全线业务智能化,实现数据驱动下的企业数据智能创新,全面支撑企业未来大规模业务智能落地。其主要优势主要有以下几个方面:
数据重复性:如果一个组织同时维护了一个数据湖和多个数据仓库,这无疑会带来数据冗余。在最好的情况下,这仅仅只会带来数据处理的不高效,但是在最差的情况下,它会导致数据不一致的情况出现。湖仓一体的结合,能够去除数据的重复性,真正做到了唯一。
高存储成本:数据仓库和数据湖都是为了降低数据存储的成本。数据仓库往往是通过降低冗余,以及整合异构的数据源来做到降低成本。而数据湖则往往使用大数据文件系统和Spark在廉价的硬件上存储计算数据。湖仓一体架构的目标就是结合这些技术来最大力度降低成本。
报表和分析应用之间的差异:数据科学倾向于与数据湖打交道,使用各种分析技术来处理未经加工的数据。而报表分析师们则倾向于使用整合后的数据,比如数据仓库或是数据集市。而在一个组织内,往往这两个团队之间没有太多的交集,但实际上他们之间的工作又有一定的重复和矛盾。而当使用湖仓一体架构后,两个团队可以在同一数据架构上进行工作,避免不必要的重复。
数据停滞:在数据湖中,数据停滞是一个最为严重的问题,如果数据一直无人治理,那将很快变为数据沼泽。我们往往轻易的将数据丢入湖中,但缺乏有效的治理,长此以往,数据的时效性变得越来越难追溯。湖仓一体的引入,对于海量数据进行治理,能够更有效地帮助提升分析数据的时效性。
潜在不兼容性带来的风险:数据分析仍是一门兴起的技术,新的工具和技术每年仍在不停地出现中。一些技术可能只和数据湖兼容,而另一些则又可能只和数据仓库兼容。湖仓一体的架构意味着为两方面做准备。

