
热门标签
热门文章
- 1如何在Android中使用正则表达式_android pattern compile
- 2Python Turtle有趣的作品_turtle作品
- 3gradle迁移到gradle.kts(复制可用)_build.gradle 转换 build.gradle.kts
- 4【MatLab】之:Simulink安装
- 5gradle导入项目timeout_importing 'studentdormitory' gradle project 超时
- 6Vue this.$router.push传递参数的2种方式_router.push 传参数
- 7手把手教你基于SVM的数字识别( C++/opencv)(逐曦战队算法组寒假自学实战1装甲板数字识别讲解)_opencv c++ svm
- 8jieba分词算法总结
- 9Vue中传递自定义参数到后端、后端获取数据(使用Map接收参数)_后端调接口 参数擦传递 用hashmap吗
- 10AndroidStudio找不到BuildConfig但是可以运行_android buildconfig缺少
当前位置: article > 正文
LSTM实战:基于PyTorch的新冠疫情确诊人数预测
作者:2023面试高手 | 2024-03-07 13:56:20
赞
踩
LSTM实战:基于PyTorch的新冠疫情确诊人数预测
目录
引言
在 Python 中使用 LSTM 预测新型冠状病毒每日确诊病例。参考原文
一、探索数据集
确诊人数数据网址下载该文件 time_series_covid19_confirmed_global.csv
1、导入相关库文件
- import torch # 导入PyTorch库,用于构建和训练深度学习模型
- import os # 导入os库,用于与操作系统交互
- import numpy as np # 导入NumPy库,用于数值计算
- import pandas as pd # 导入Pandas库,用于数据处理和分析
- from tqdm import tqdm # 导入tqdm库,用于显示进度条
- import seaborn as sns # 导入Seaborn库,用于数据可视化
- from pylab import rcParams # 导入rcParams对象,用于设置图形参数
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- from matplotlib import rc # 导入rc对象,用于自定义Matplotlib的默认配置
- from sklearn.preprocessing import MinMaxScaler # 导入MinMaxScaler,用于数据标准化
- from pandas.plotting import register_matplotlib_converters # 导入register_matplotlib_converters,用于处理时间序列数据
- from torch import nn, optim # 导入神经网络和优化器模块
-
- # 设置Matplotlib使用的后端为TkAgg
- import matplotlib
- matplotlib.use('TkAgg')
-
- # 设置Seaborn的样式和调色板
- sns.set(style='whitegrid', palette='muted', font_scale=1.2)
-
- # 自定义颜色调色板
- HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#93D30C", "#8F00FF"]
-
- # 设置Seaborn的调色板
- sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
-
- # 设置Matplotlib图形的大小
- rcParams['figure.figsize'] = 14, 10
-
- # 注册Matplotlib转换器
- register_matplotlib_converters()
-
- # 设置随机种子,以确保结果可复现
- RANDOM_SEED = 42
- np.random.seed(RANDOM_SEED)
- torch.manual_seed(RANDOM_SEED)

2、导入每日确诊人数数据集
读取COVID-19全球累计确诊病例数据集
- # 数据集包含省、国家/地区、纬度和经度以及病例数是累积的。
- df = pd.read_csv('./data/time_series_covid19_confirmed_global.csv')
- print(df.head())
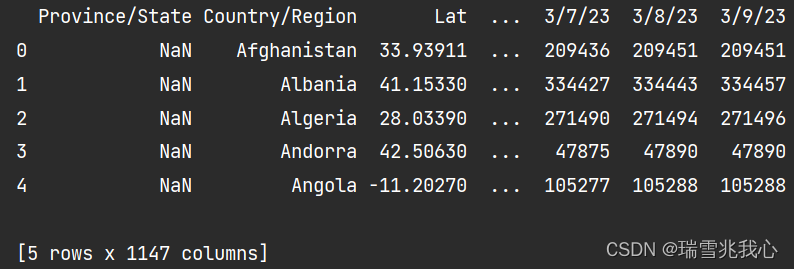
3、清洗每日确诊人数数据集
去除前四列无用数据,保留每日累计确诊病例数据
- # 去掉前四列我们不需要的数据,通过切片直接获取第五列之后的数据
- df = df.iloc[:, 4:]
- print(df.head())
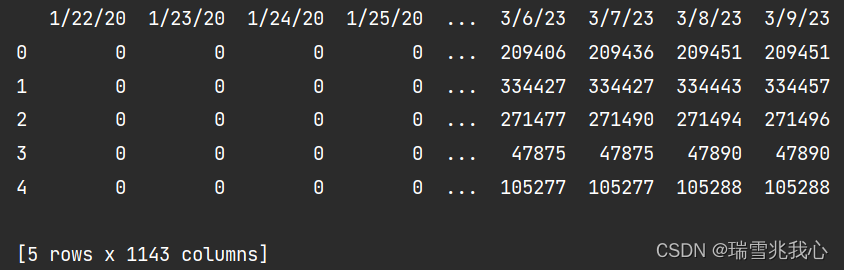
4、每日累计确诊的人数及其数据集可视化
对每日累计确诊病例进行求和,转换索引为日期时间格式
- # 我们对所有行求和,这样就得到了每日累计案例
- daily_cases = df.sum(axis=0)
- daily_cases.index = pd.to_datetime(daily_cases.index)
- print(daily_cases.head())

- plt.plot(daily_cases)
- plt.title("Cumulative daily cases")
- plt.show()
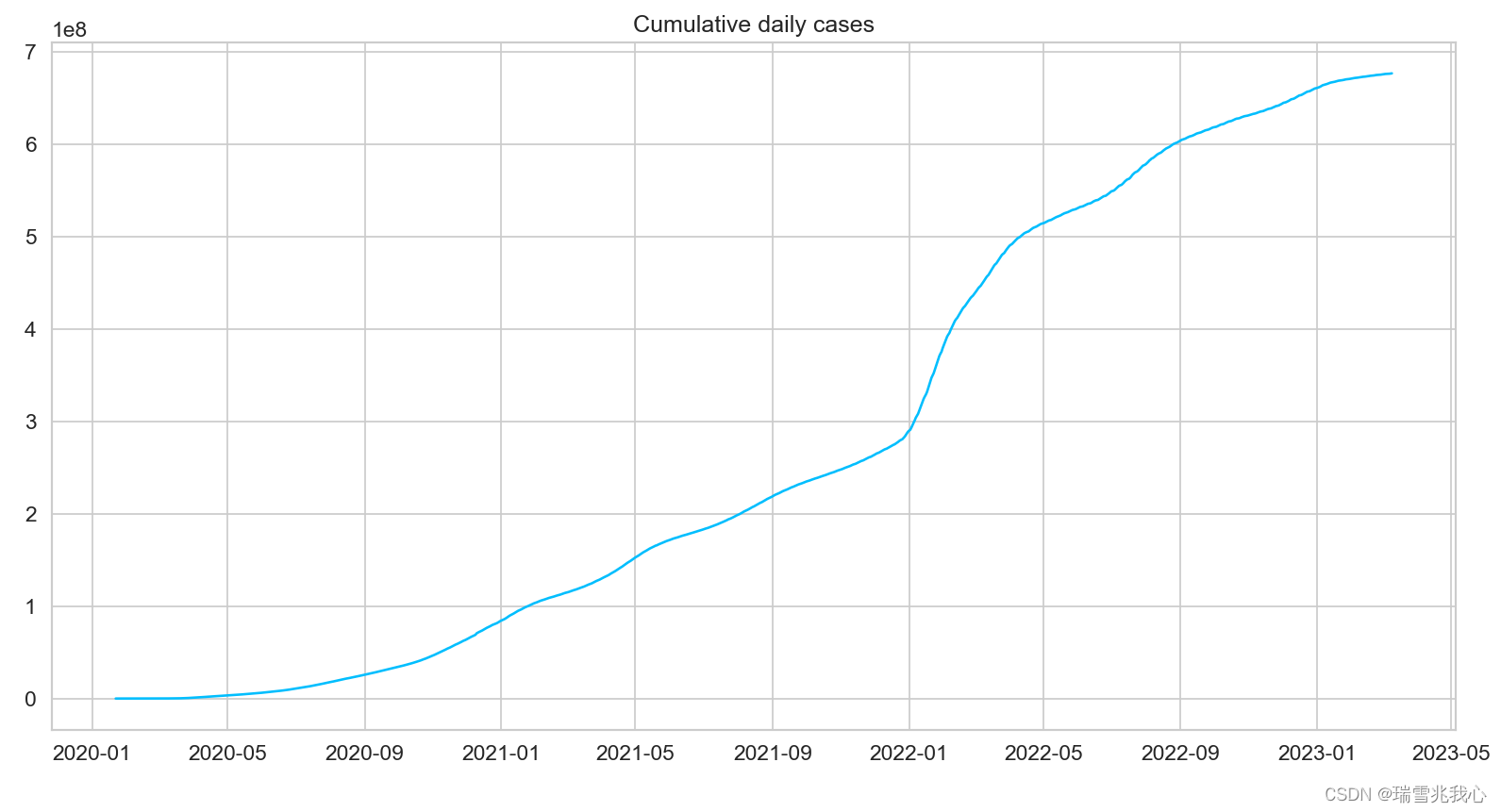
5、每日撤消累计后的确诊人数及其数据集可视化
计算每日新增确诊病例数
- # 我们通过当前值减去前一个值来撤消累加并保留序列的第一个值。
- daily_cases = daily_cases.diff().fillna(daily_cases[0]).astype(np.int64)
- print(daily_cases.head())

- plt.plot(daily_cases)
- plt.title("Daily cases")
- plt.show()
下图中有一个巨大的峰值主要是由于中国患者检测标准的变化。
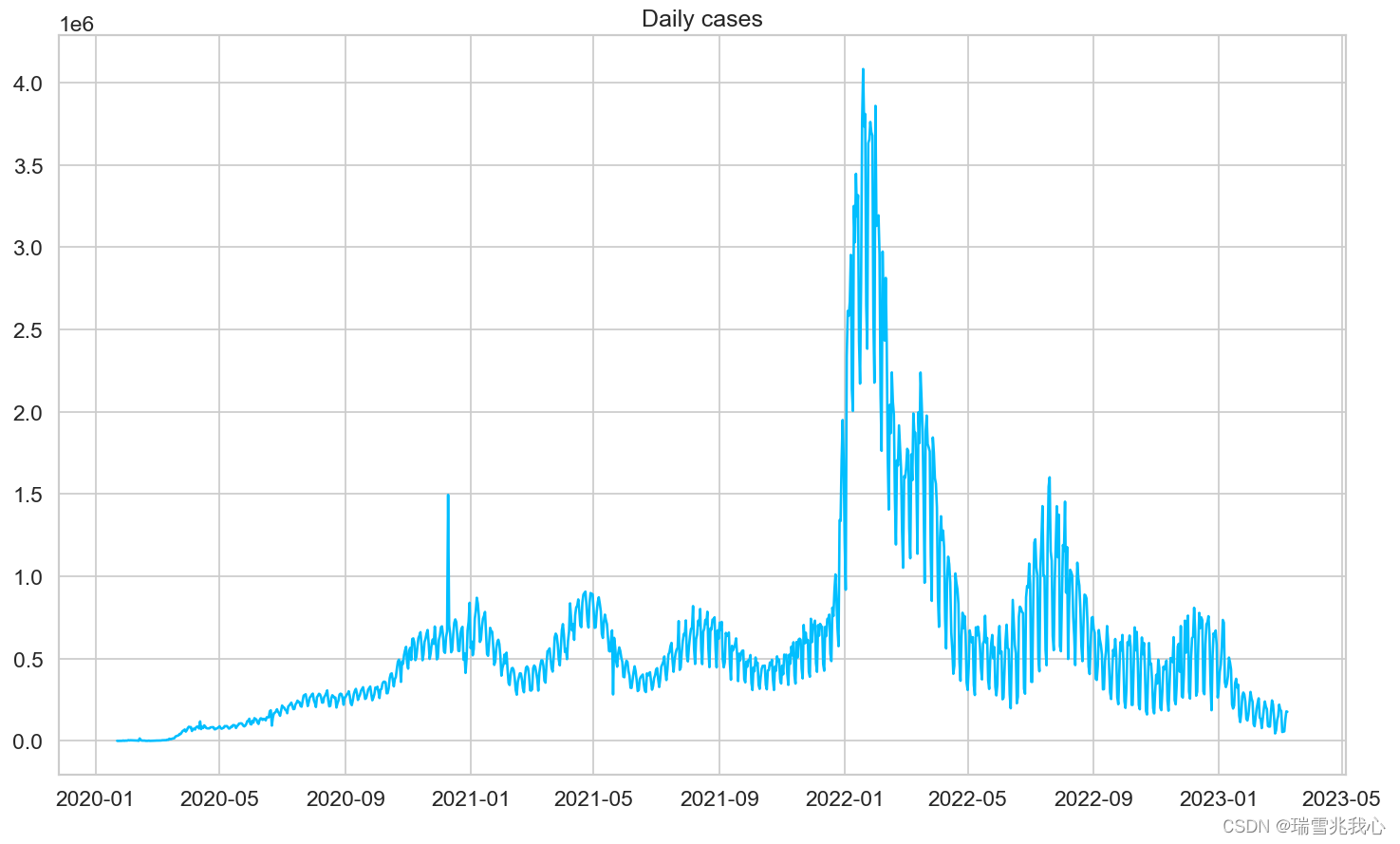
6、查看总共有多少数据量
- # 查看一下我们拥有的数据量。
- print(daily_cases.shape)
![]()
二、数据预处理
1、训练和测试数据集
设置训练集和测试集的大小
- # 我们将保留前 889 天用于训练,其余的 254 天用于测试。
- test_data_size = 889
- train_data = daily_cases[:-test_data_size]
- test_data = daily_cases[-test_data_size:]
- print(train_data.shape)
- print(test_data.shape)

2、数据放缩
对数据进行标准化,将数值缩放到0到1之间
- # 为了提高模型的训练速度和性能,我们必须缩放数据(值将在 0 和 1 之间)。
- scaler = MinMaxScaler()
- scaler = scaler.fit(np.expand_dims(train_data, axis=1))
-
- train_data = scaler.transform(np.expand_dims(train_data, axis=1))
- test_data = scaler.transform(np.expand_dims(test_data, axis=1))
定义创建序列的函数
- def create_sequences(data, seq_length):
- xs = []
- ys = []
-
- for i in range(len(data) - seq_length - 1):
- x = data[i:(i + seq_length)]
- y = data[i + seq_length]
- xs.append(x)
- ys.append(y)
-
- return np.array(xs), np.array(ys)
-
- # 设置序列长度
- seq_length = 9
-
- # 创建训练集和测试集的序列数据
- X_train, y_train = create_sequences(train_data, seq_length)
- X_test, y_test = create_sequences(test_data, seq_length)
-
- # 将数据转换为PyTorch张量
- X_train = torch.from_numpy(X_train).float()
- y_train = torch.from_numpy(y_train).float()
- X_test = torch.from_numpy(X_test).float()
- y_test = torch.from_numpy(y_test).float()
-
- print(X_train.shape)
- print(X_train[:2])
- print(y_train.shape)
- print(y_train[:2])
每个训练示例包含 9 个历史数据点序列和 1 个标签,该标签表示我们的模型需要预测的真实值。接下来看看我们转换后的数据的样貌。


三、建立模型
1、封装训练模型
定义 COVID-19 预测模型
- # 把模型封装到一个自torch.nn.Module的类中
- class CoronaVirusPredictor(nn.Module):
-
- def __init__(self, n_features, n_hidden, seq_len, n_layers=2):
- super(CoronaVirusPredictor, self).__init__()
-
- self.n_hidden = n_hidden
- self.seq_len = seq_len
- self.n_layers = n_layers
-
- self.lstm = nn.LSTM(
- input_size=n_features, # 输入特征维数:特征向量的长度,如 889
- # hidden_size 只是指定从LSTM输出的向量的维度,并不是最后的维度,因为LSTM层之后可能还会接其他层,如全连接层(FC),因此hidden_size对应的维度也就是FC层的输入维度。
- hidden_size=n_hidden, # 隐层状态的维数:每个 LSTM 单元或者时间步的输出的 h(t) 的维度,单元内部有权重与偏差计算
- # num_layers 为隐藏层的层数,官方的例程里面建议一般设置为1或者2。
- num_layers=n_layers, # RNN 层的个数:在竖直方向堆叠的多个相同个数单元的层数
- dropout=0.5 # 是否在除最后一个 LSTM 层外的 LSTM 层后面加 dropout 层
- )
-
- self.linear = nn.Linear(in_features=n_hidden, out_features=1)
-
- # 重置隐藏状态: 使用无状态 LSTM,需要在每个示例之后重置状态。
- def reset_hidden_state(self):
- self.hidden = (
- torch.zeros(self.n_layers, self.seq_len, self.n_hidden),
- torch.zeros(self.n_layers, self.seq_len, self.n_hidden)
- )
-
- # 前向传播: 获取序列,一次将所有序列通过 LSTM 层。采用最后一个时间步的输出并将其传递给我们的线性层以获得预测。
- def forward(self, sequences):
- lstm_out, self.hidden = self.lstm(
- sequences.view(len(sequences), self.seq_len, -1),
- self.hidden
- )
- last_time_step = \
- lstm_out.view(self.seq_len, len(sequences), self.n_hidden)[-1]
- y_pred = self.linear(last_time_step)
- return y_pred
2、辅助训练模型
定义训练模型的辅助函数
- # 构建一个用于训练模型的辅助函数
- def train_model(
- model,
- train_data,
- train_labels,
- test_data=None,
- test_labels=None
- ):
- loss_fn = torch.nn.MSELoss(reduction='sum')
-
- optimiser = torch.optim.Adam(model.parameters(), lr=1e-3)
- num_epochs = 100
-
- train_hist = np.zeros(num_epochs)
- test_hist = np.zeros(num_epochs)
-
- for t in range(num_epochs):
- model.reset_hidden_state()
- y_pred = model(X_train)
- loss = loss_fn(y_pred.float(), y_train)
-
- if test_data is not None:
- with torch.no_grad():
- y_test_pred = model(X_test)
- test_loss = loss_fn(y_test_pred.float(), y_test)
- test_hist[t] = test_loss.item()
-
- if t % 10 == 0:
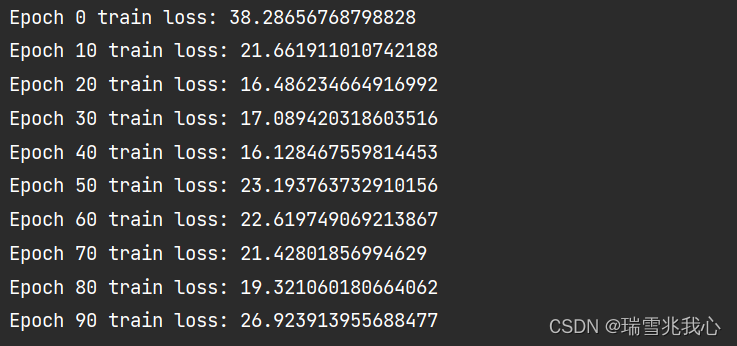
- print(f'Epoch {t} train loss: {loss.item()} test loss: {test_loss.item()}')
- elif t % 10 == 0:
- print(f'Epoch {t} train loss: {loss.item()}')
-
- train_hist[t] = loss.item()
- optimiser.zero_grad()
- loss.backward()
- optimiser.step()
-
- return model.eval(), train_hist, test_hist
四、训练模型
创建并训练COVID-19预测模型
- model = CoronaVirusPredictor(
- n_features=1,
- n_hidden=512,
- seq_len=seq_length,
- n_layers=2
- )
- model, train_hist, test_hist = train_model(
- model,
- X_train,
- y_train,
- X_test,
- y_test
- )
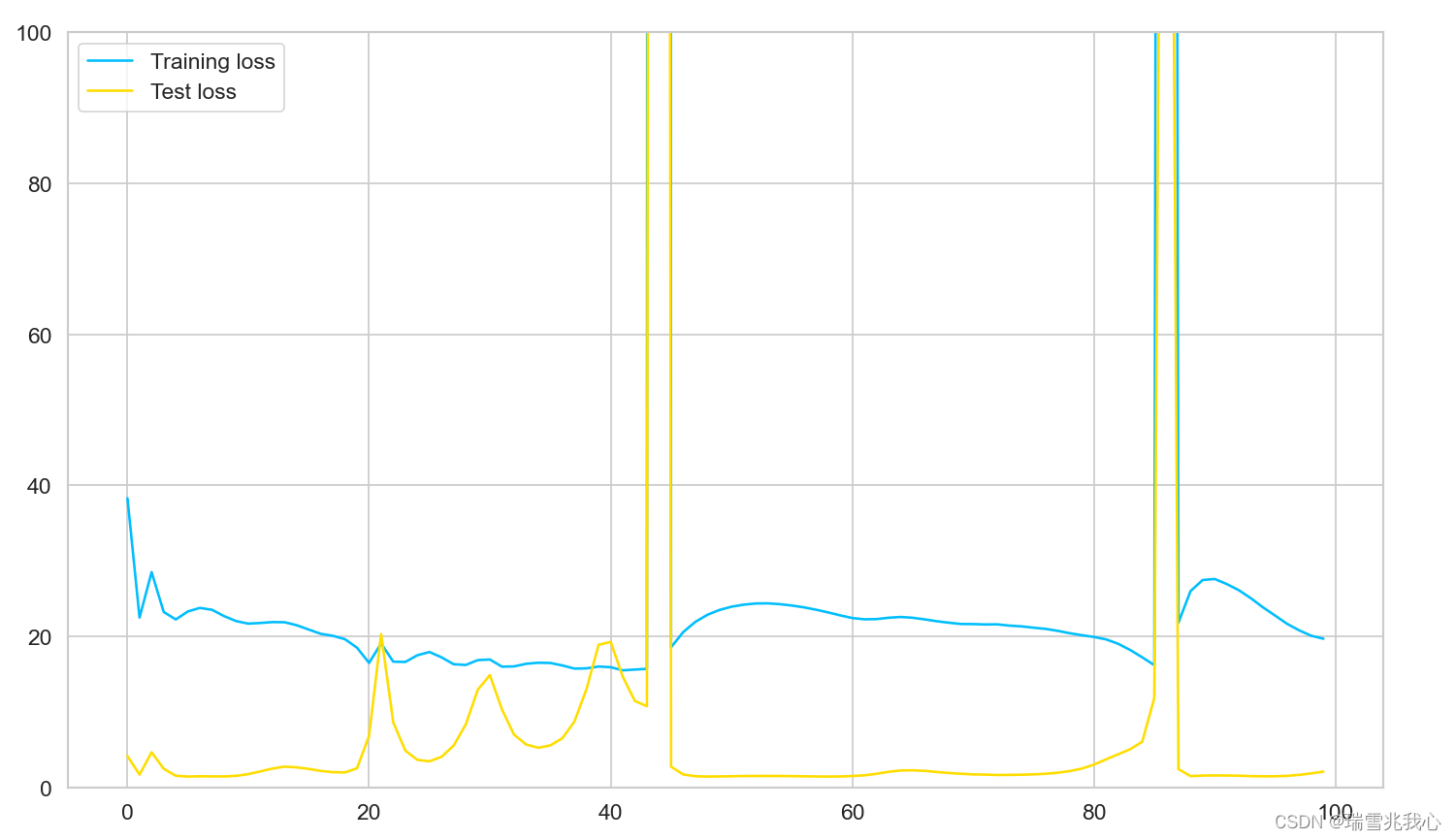
- plt.plot(train_hist, label="Training loss")
- plt.plot(test_hist, label="Test loss")
- plt.ylim((0, 100))
- plt.legend()
- plt.show()
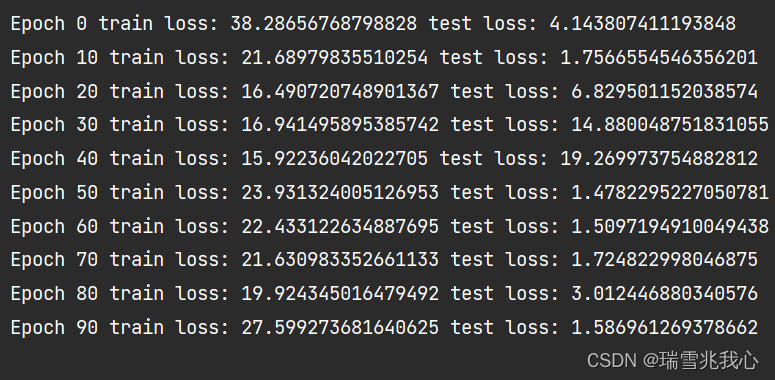
查看训练和测试损失过程可视化:
五、预测模型
1、局部数据预测
将训练数据、测试数据及预测数据绘制在同一张画布上,一起比较下预测结果。
- with torch.no_grad():
- test_seq = X_test[:1]
- preds = []
- for _ in range(len(X_test)):
- y_test_pred = model(test_seq)
- pred = torch.flatten(y_test_pred).item()
- preds.append(pred)
- new_seq = test_seq.numpy().flatten()
- new_seq = np.append(new_seq, [pred])
- new_seq = new_seq[1:]
- test_seq = torch.as_tensor(new_seq).view(1, seq_length, 1).float()
-
- true_cases = scaler.inverse_transform(
- np.expand_dims(y_test.flatten().numpy(), axis=0)
- ).flatten()
-
- predicted_cases = scaler.inverse_transform(
- np.expand_dims(preds, axis=0)
- ).flatten()
-
- plt.plot(
- daily_cases.index[:len(train_data)],
- scaler.inverse_transform(train_data).flatten(),
- label='Historical Daily Cases')
-
- plt.plot(
- daily_cases.index[len(train_data):len(train_data) + len(true_cases)],
- true_cases,
- label='Real Daily Cases')
-
- plt.plot(
- daily_cases.index[len(train_data):len(train_data) + len(true_cases)],
- predicted_cases,
- label='Predicted Daily Cases')
-
- plt.legend()
- plt.show()
-
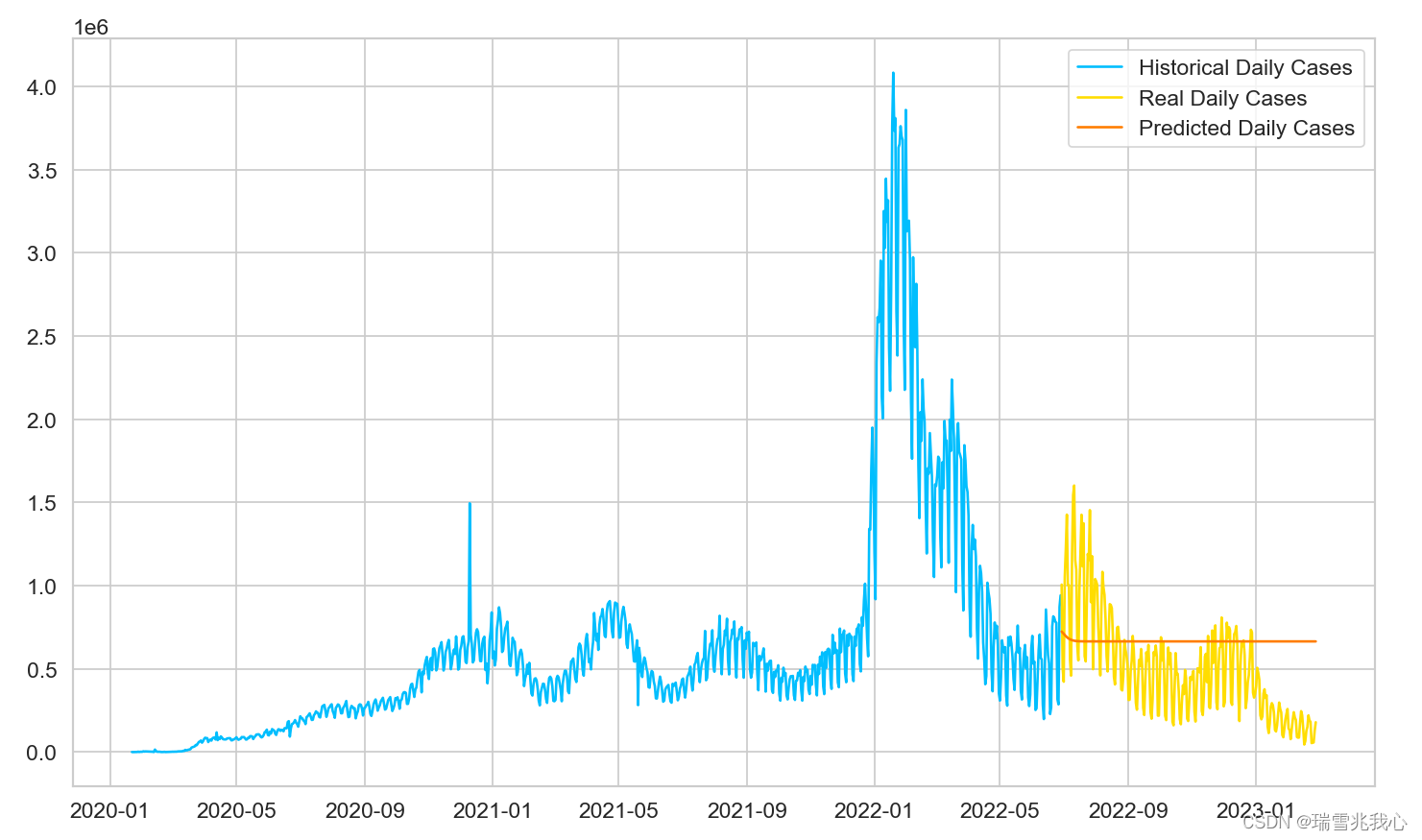
正如预期的那样,我们的模型效果表现不佳。
2、全部数据预测
使用所有数据来训练相同的模型,预测未来 30 天的确诊病例。
- # 现将使用所有可用数据来训练相同的模型。
- scaler = MinMaxScaler()
-
- scaler = scaler.fit(np.expand_dims(daily_cases, axis=1))
- all_data = scaler.transform(np.expand_dims(daily_cases, axis=1))
- print(all_data.shape)
-
- # 预处理和训练步骤相同。
- X_all, y_all = create_sequences(all_data, seq_length)
-
- X_all = torch.from_numpy(X_all).float()
- y_all = torch.from_numpy(y_all).float()
-
- model = CoronaVirusPredictor(
- n_features=1,
- n_hidden=512,
- seq_len=seq_length,
- n_layers=2
- )
- model, train_hist, _ = train_model(model, X_all, y_all)
-
- # 定义预测天数:使用“完全训练”的模型来预测未来 60 天的确诊病例
- DAYS_TO_PREDICT = 60
-
- # 使用训练好的模型进行预测
- with torch.no_grad():
- test_seq = X_all[:1]
- preds = []
- for _ in range(DAYS_TO_PREDICT):
- y_test_pred = model(test_seq)
- pred = torch.flatten(y_test_pred).item()
- preds.append(pred)
- new_seq = test_seq.numpy().flatten()
- new_seq = np.append(new_seq, [pred])
- new_seq = new_seq[1:]
- test_seq = torch.as_tensor(new_seq).view(1, seq_length, 1).float()
-
- # 将预测结果反向转换为原始数据范围
- predicted_cases = scaler.inverse_transform(
- np.expand_dims(preds, axis=0)
- ).flatten()
-
- # 构建预测日期范围:要使用历史和预测案例创建一个很酷的图表,我们需要扩展数据框的日期索引。
- predicted_index = pd.date_range(
- start=daily_cases.index[-1],
- periods=DAYS_TO_PREDICT + 1,
- inclusive="right"
- )
-
- # 创建预测结果Series对象
- predicted_cases = pd.Series(
- data=predicted_cases,
- index=predicted_index
- )
-
- # 绘制预测结果图表
- fig1 = plt.figure('Figure1')
- plt.plot(predicted_cases, label='Predicted Daily Cases')
-
- fig2 = plt.figure('Figure2')
- plt.plot(daily_cases, label='Historical Daily Cases')
- plt.plot(predicted_cases, label='Predicted Daily Cases')
- plt.legend()
- plt.show()
参与训练的全部数据。
![]()
预测未来 30 天确诊病例的数据
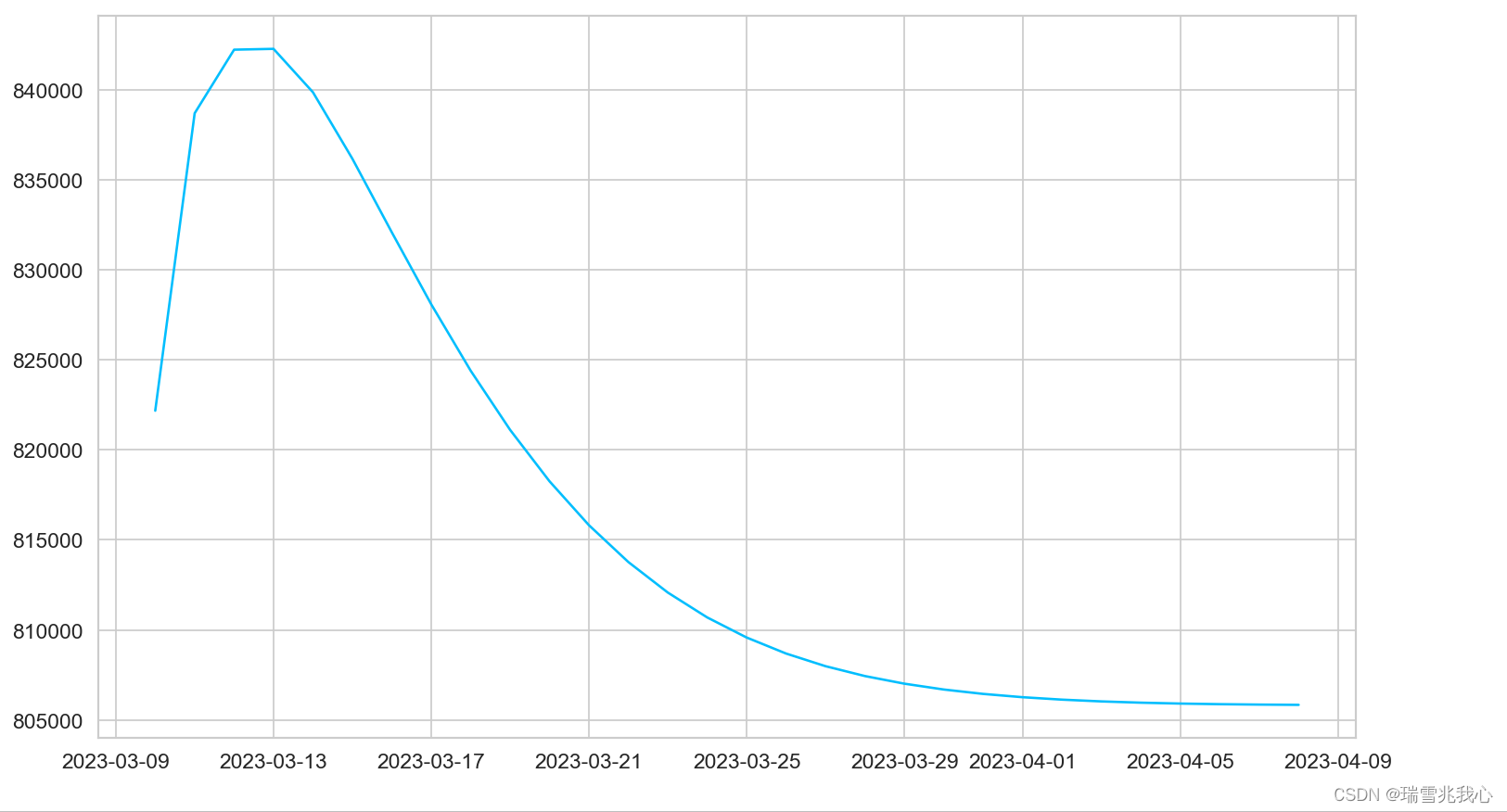
将历史和预测的确诊人数在一个图表中显示
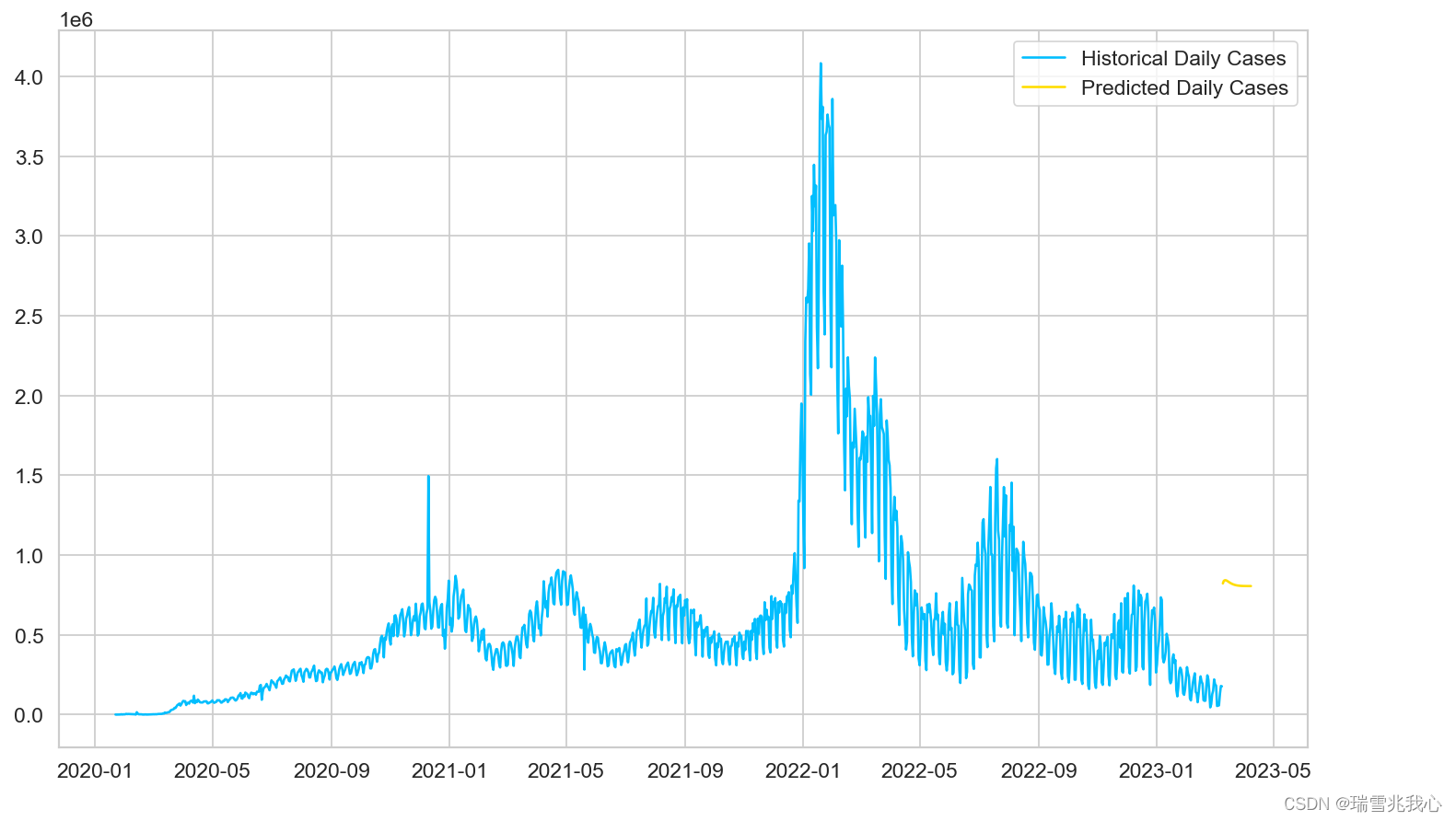
模型性能不是很好,但考虑到数据量很少,这是可以预期的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/206003
推荐阅读
相关标签

