- 115、PGP协议
- 2AlexNet_加载ImageNet上的预训练模型_tensorflow版本_alexnet imagenet预训练模型
- 3kafka rebalance故障的处理策略_修改时钟后consumer group is reblancing
- 4OpenGL ES与EGL的关系(二十一),android高级面试_libglesv2
- 5Unity快速入门教程-手机游戏开发前的准备(手机模拟器Simulator)_unity simulator
- 6yolov4口罩目标检测识别_yolov4识别数字模型
- 7python中range和len
- 8微信小程序:tabbar、事件绑定、数据绑定、模块化、模板语法、尺寸单位_微信小程序 tabbar
- 9消息队列RabbitMQ-使用过程中面临的问题与解决思路
- 10axios的最新封装,解决类型AxiosRequestConfig不能赋值给InternalAxiosReqe;CreateAxiosDefaults不能赋值给AxiosRequestConfig_类型“(config: axiosrequestconfig) => axiosrequestcon
大模型框架LangChain开发实战(一)_langchain应用流程图
赞
踩
一、概述
在大模型应用中,通常是基于框架来呼叫模型的,大模型提供了两个最重要的功能,一是提供了具体的intermediate steps(即做事情的中间步骤,模型作为reasoning engine),二是提供了evaluation的能力(模型作为evaluation tool),在此基础上,对于用户来说,重要的是写好你的prompt,通过它下指令让模型做一些事情。除了模型之外,还有agent(智能体),它本身会不断地进行循环,基于模型产生的步骤以及对效果的评估,不断地调整agent的执行,这个调整可能是与第三方工具进行交互,也可能是与第三方数据进行交互(不是指模型的数据,而是用户自己的私有数据,譬如类似profile的数据)。从企业级开发的角度来说,最重要的是要有一个类似代理的智能体(agent),负责与模型进行交互(agent会不断循环查看模型中间执行的一些结果),并且如果有必要,agent会根据模型的信息调用第三方工具或者访问用户私有数据,另外也可以跟tools进行交互。从业界的最佳实践看,一般都会把上述agent的这些功能封装进framework,目前最流行的framework就是LangChain,这是开源界公认的最好的大模型框架,也是工业界采用最广泛的大模型框架,同时也是学术界认可度最高的大模型框架。
二、企业级大模型框架LangChain解析
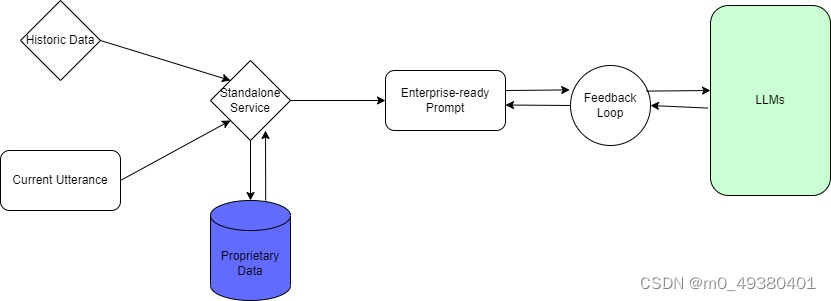
通常在一段对话流中,会包括历史会话信息(historic data),当前的对话信息(current utterance),历史会话信息会影响到当前的对话(作为上下文存在),历史会话信息不是简单地追加到当前会话输入后面来传给模型,因为这样做会使模型需要处理的输入tokens越来越多,导致效率和成本的问题,更致命的是会导致prompt的质量问题(当historic data较多时,可能current utterance输入根本不起什么作用)。prompt首先是从你的用词中找出隐性或者显性的patterns,然后基于patterns来提取关键信息,如果只是简单的追加(appended to historic data),可能就会导致模型使用prompt时忽略当前的输入信息,从而表现出用户与模型对话时模型不会给到用户相应的反馈,因此需要在生成prompt之前添加一个standalone service,它会突出当前的用户输入信息(因为模型要回答当前的问题),同时又基于historic data或者系统的设定提供相应的上下文。另外,由于存在企业私有数据,standalone service也需要和这些数据进行交互。历史数据,当前用户输入和企业私有数据三者结合形成了企业级的prompt,然后才与大模型进行交互(中间存在一个循环的过程)。基于以上分析得到下面的对话流程图:
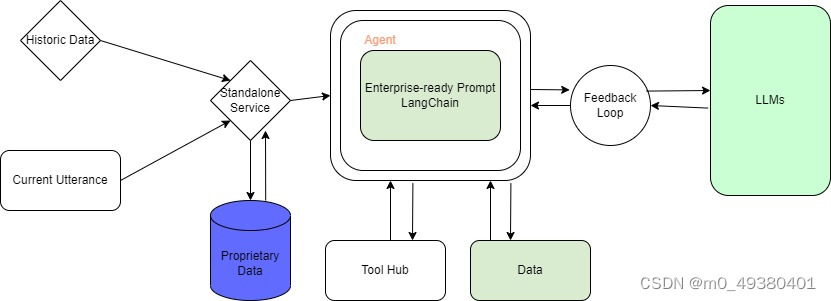
以上流程图所展示的内容还不足以构成企业级的基于大模型的应用程序开发,因为在这个流程图中还缺少两个重要的元素:工具和第三方数据,举个例子来说,如果我们针对学生做一个阅读理解方面的应用(阅读理解本身是文字,但是应用开发可能涉及到多模态),那可能需要访问wikipedia或者其它的一些(学校的)系统的数据来增强学生的理解,也有可能是转换为音频的方式,也有可能是补充图片或者视频的方式,这就涉及到工具和数据。我们需要一个容器来完成模型、工具和数据的交互,而这就是LangChain,你可以认为LangChain是大模型开发时代的operating system,因为它驱动了所有模块和数据的相互交互。在这样的一个框架中,有这样一个东西称作agent,目前来看agent还是一个很开放的领域,其本身的作用是基于模型驱动的做事情的具体过程,来在适当的时候使用工具或者本地数据,或者第三方数据来完成模型设定的步骤,这样的一个agent具有动态调整的过程,可以把它看成一个loop,它既能与模型,数据,工具进行交互,又能处理异常,以及评估整个系统的行为。一句话来总结LangChain,它就是一个service,一个framework,或者一个platform,它通过模型驱动来整合数据和工具,从而完成大模型应用的开发。
以下是更新后的基于LangChain来开发的大模型对话应用流程图: