
- 1基于Java+SpringBoot+Vue前后端分离婚纱影楼管理系统设计和实现_springboot vue婚纱影楼系统
- 2保姆级教程-如何使用LLAMA2 大模型_如何调用 llama 的 api
- 3Jenkins忘记密码解决方案_jenkins忘记用户名和密码
- 4《Python编程:从入门到实践》第12章:武装飞船_python入门到实践中的 ship.bmg
- 52023美赛E题_2023美赛e题 背景 光污染是用来描述任何过度或不良的使用人工光。一些我们称之为
- 6MYSQL 8 UNDO 表空间 你了解多少
- 7vs code解决无法识别已安装python库的问题(Mac版)
- 8初始MyBatis,w字带你解MyBatis
- 9video 标签设置样式_video标签样式
- 10如何在论文中画出漂亮的插图?
【SwinFusion:通用网络框架 :Swin Transformer】
赞
踩
SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
(SwinFusion:基于Swin Transformer的跨域远程学习通用图像融合)
提出了一种基于跨域远程学习和Swin Transformer的通用图像融合框架SwinFusion。一方面,设计了注意引导的跨域模块,以实现互补信息和全局交互的充分整合。更具体地说,所提出的方法涉及一个基于自我注意力的域内融合单元和基于交叉注意力的跨域融合单元,挖掘和整合在同一个领域和跨域的长依赖关系。通过远程依赖建模,网络能够充分实现特定领域的信息提取和跨领域的互补信息集成,以及从全局角度保持适当的表观强度。特别地,我们将移位窗口机制引入到自注意和交叉注意中,这使得我们的模型能够接收任意大小的图像。另一方面,多场景图像融合问题被推广到一个统一的框架与结构保持,细节保护,并适当的强度控制。此外,一个精心设计的损失函数,包括SSIM损失,纹理损失和强度损失,驱动网络保留丰富的纹理细节和结构信息,以及呈现最佳的表观强度。多模态图像融合和数码摄影图像融合的大量实验证明,我们的SwinFusion与最先进的统一图像融合算法和特定任务替代方案相比具有优越性。
INTRODUCTION
由于硬件设备的限制,由单一类型的传感器或单一拍摄设置捕获的信息不能全面表征成像场景。一方面,不同类型的传感器通常从多个角度捕获特定信息。例如,红外传感器收集热辐射信息,这强调突出的目标。可见光传感器通过捕捉反射光信息生成具有丰富纹理细节的数字图像。近红外传感器可以捕获可能在可见光图像中丢失的补充细节。此外,在医学成像领域,结构系统(例如,磁共振成像(MRI)和计算机断层扫描(CT))通常提供结构和解剖信息。相比之下,诸如正电子发射断层扫描(PET)的功能系统可以提供关于血流和代谢变化的功能信息。另一方面,具有不同拍摄设置的传感器通常从成像场景获取有限的信息。更具体地,具有变化的ISO和曝光时间的相机仅捕获动态范围内的信息,并且不可避免地错过动态范围外的信息。同样,具有特定焦距的相机仅捕获景深(DOF)内的对象。值得一提的是,由不同传感器或在多种拍摄设置下拍摄的图像一般都包含互补信息,这鼓励我们将这些互补特征融入到单个图像中。因此,图像融合技术应运而生。根据成像设备的不同,图像融合可分为多模态图像融合和数字摄影图像融合。这两种类型的图像融合场景的示意图在图1中展示。融合后的单幅图像具有更好的场景表示和视觉感知能力,有利于后续的实际视觉应用,如目标检测、跟踪、语义分割、场景理解等。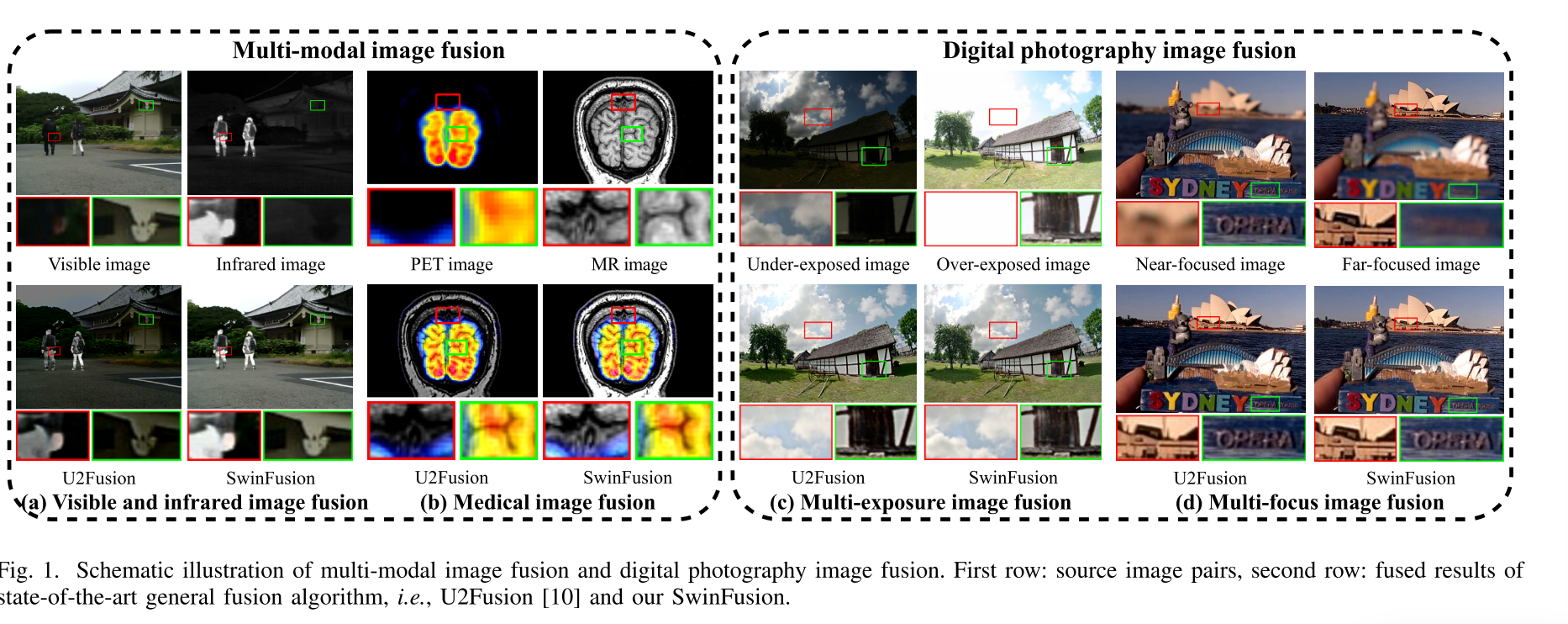
在过去的几十年中,已经提出了许多图像融合技术,其可以大致分为两类,即,任务特定图像融合方案和一般图像融合算法。任务特定图像融合和一般图像融合都可以进一步分为四类,包括传统框架,基于卷积神经网络(CNN)的框架,基于自动编码器(AE)的框架,以及基于生成对抗网络(GAN)的框架。虽然上述框架可以产生相当多的融合结果,但没有一个框架可以充分挖掘和整合领域内和跨领域的全局背景。特别是,我们假设由不同的传感器或多个光学设置下拍摄的图像属于不同的域在本文中。一方面,传统的框架通常在空间域或变换域中实现互补信息聚合,但它们都不能在不相邻的像素之间交换信息。因此,传统的框架无法感知全局环境。另一方面,基于CNN、AE和GAN的框架的基本组件是卷积层,它们只能挖掘感受野内的交互。然而,在利用图像融合的局部信息的同时,这些框架不能利用域内或域间的长程依赖性来进一步改善融合结果。
作为CNN的替代方案,Transformer设计了一种自我注意机制来捕获上下文之间的全局交互,并在几个视觉问题中表现出有希望的性能。特别是,图像融合社区还引入了Transformer来对域间长程依赖性进行建模,并提供了有竞争力的融合结果。然而,仍然存在一些需要解决的缺点。首先,现有的基于Transformer的方法只探索域内的相互作用,但不能集成跨域的背景下,这是必不可少的图像融合任务。第二,用于图像融合的视觉Transformer通常请求可以被整形为固定大小的输入图像(例如,256 × 256),这导致融合图像中的失真场景。第三,现有的融合Transformer被设计用于特定的融合场景,而不考虑不同的融合任务之间的内在联系。
为了解决上述挑战,我们设计了一个通用的图像融合框架的基础上跨域远程学习和Swin Transformer的多模态图像融合和数字摄影图像融合。我们的设计主要从以下几个方面展开。一方面,我们模型的所有图像融合的情况下,结构维护,纹理保存,和适当的强度控制。特别是,我们统一的损失函数的形式,包括SSIM损失,纹理损失,强度损失,所有融合问题。所有子损失项遵循不同融合任务的相同建模方式,除了强度损失,这是定制的特定融合使命更合适的强度感知。另一方面,我们设计了一个联合CNN-Transformer图像融合框架,充分挖掘源图像中的局部和全局依赖关系。基于CNN的浅层特征提取单元挖掘源图像中的局部信息。基于Transformer的深度特征提取单元探索浅层特征之间的全局交互,并生成包含高级语义信息的深度特征。然后,精心设计的注意力引导的跨域融合模块有效地集成了深层特征中的域内和域间交互。具体地,域内融合单元经由自注意机制聚合相同域中的全局上下文。域间融合单元对多个源图像之间的长程依赖关系进行建模,通过交换来自不同域的查询、键和值来实现全局特征融合。最后,基于Transformer的深度特征重建单元和基于CNN的融合图像重建单元利用全局和局部信息来重建具有上级视觉感知的融合图像。值得注意的是,自我注意和交叉注意都是通过移位窗口机制(即,Swin Transformer),它允许我们的框架处理任意大小的输入图像。
综上所述,本工作的主要贡献可概括如下:
1)我们提出了一个联合CNN-Transformer融合框架,用于多模态图像融合和数字摄影图像融合。所提出的框架可以充分利用本地和全球信息,以实现更好的互补特征集成。
2)设计了一个基于自注意的域内融合单元和一个基于交叉注意的域间融合单元,分别对同一域内和跨域的长程依赖关系进行建模和集成。
3)多模态图像融合和数字摄影图像融合都被推广到结构保持、纹理保持和适当的强度控制。特别地,定义了统一的损失函数形式来约束所有的图像融合问题。
4)大量的实验表明,我们的框架比目前最先进的特定任务和一般的融合算法的多模态图像融合和数字摄影图像融合还要好。
RELATED WORK
图像融合和视觉变换是两个最相关的技术,我们在这里回顾一些代表性的研究,介绍他们的发展。
Task-specific Image Fusion Methods
图像融合作为一种重要的图像增强技术,近年来受到越来越多的关注。主流的图像融合方案,特别是针对特定任务的图像融合,可以分为以下四种类型的框架。
Traditional Image Fusion Framework: 传统的融合框架通常在空间域和变换域实现图像融合。一方面,在空间域中整合像素级信息是传统图像融合的主要类型之一。GTF 将红外和可见光图像融合定义为空间域中的整体强度保持和纹理结构保持,并通过优化目标函数来产生融合图像。Awad等人开发了一种空间域中的自适应近红外和可见光融合方案,用于可见光图像细节增强。此外,Liu等人设计了一种基于形态成分分析(CS-MCA)的卷积稀疏模型,以实现像素级的医学图像融合。他们还引入了局部特征描述符(即,Dense SIFT)到多焦点图像融合任务中,以执行活动水平测量并匹配不同源图像之间的未配准像素。另一方面,研究人员也尝试通过相关的数学变换将源图像映射到变换域,并在变换域中手工设计融合规则来实现图像融合。Ma等人采用结构路径分解技术将源图像变换成三个概念上独立的分量,即,信号强度、信号结构和平均强度。然后,分别对这三个分量进行融合,实现多曝光图像的融合。此外,Li等人提出了一种基于变换域的多聚焦图像融合算法,结合稀疏特征矩阵分解和形态滤波技术。
CNN-based Image Fusion Framework: 近年来,卷积神经网络(CNN)逐渐成为图像融合的主要主力,并表现出显着的优势。参与图像融合的CNN的一种形式采用预先训练的网络来实现活动水平测量并为手工制作的特征生成权重图。但整个融合过程仍然基于传统的融合框架,如拉普拉斯金字塔和引导滤波。另一种类型的基于CNN的图像融合框架是利用CNN以端到端的方式学习源图像和融合图像(或聚焦图)之间的直接映射。各种研究将特定任务的先验信息集成到基于CNN的框架中,以设计损失函数和网络结构。具体地,Ma等人提出了一种α-matte边界散焦模型,以精确模拟散焦扩散效应,并为多聚焦图像融合网络的训练生成真实数据。为了解决聚焦/散焦边界周围的模糊水平估计的困难,Li等人引入了深度回归对学习,直接将整个图像转换为二进制掩码,而无需任何补丁操作。Zhao等人提出了一种通过考虑深度线索的深度蒸馏多聚焦图像融合方法。他们还专注于特征的多样性,以提高融合性能。此外,Han 等人设计了一个用于多曝光图像融合的深度感知增强网络,其中包含两个单独的模块,分别用于收集内容细节和校正颜色失真。对于可见光和红外图像融合,Long等人在CNN的基础上设计了一个聚合的残差密集网络,结合了ResNet和DenseNet的结构优势。此外,SeAFusion首次将语义约束纳入图像融合建模中,并提出了梯度残差密集块,以提高对细粒度细节的描述能力。
AE-based Image Fusion Framework: 同时,研究人员也探索了基于自动编码器的图像融合框架。具体地说,采用在大规模数据集上预训练的自动编码器作为特征提取器和图像重建器,然后针对深度特征设计专门的融合策略以实现图像融合。DeepFuse是这种融合框架的先驱。之后,Li等人引入了密集连接和嵌套连接以增强编码器的特征提取能力。此外,Jian等人将注意力机制注入到基于AE的融合框架中,以加强编码器提取的显著特征。为了提取具有更大可解释性的特征,Xu等人将解纠缠表示定制为基于AE的融合框架。然而,所有上述方法采用手工制作的融合策略,例如,元素加法、元素加权求和和元素最大值,以合并深度特征,这阻碍融合模型实现其最佳性能。为此,Xu等人基于像素分类显著性和可解释重要性评估设计了一个可学习的融合规则。
GAN-based Image Fusion Framework: 生成式对抗网络(GAN)可以在没有监督信息的情况下有效地对数据分布进行建模,这与图像融合任务不谋而合。Ma等人将图像融合问题定义为生成器和鉴别器之间的博弈。然后,他们将GAN应用于一系列融合任务,例如红外和可见光图像融合,多曝光图像融合,多聚焦图像融合和泛锐化。然而,单个鉴别器未能考虑多个域的数据分布。因此,Xu等人提出了双鉴别器条件生成对抗网络(DDcGAN),它利用两个鉴别器来约束融合结果的分布。随后,Hung等人设计了用于医学图像融合的多生成器多鉴别器条件生成对抗网络(MGMDcGAN)。此外,Li等人将多尺度注意力机制注入到基于GAN的融合框架中,以鼓励生成器和鉴别器更多地关注有意义的区域。
General Image Fusion Methods
特定任务的融合算法能够利用相关的先验知识来提高融合性能,但它们忽略了不同图像融合任务之间的内在关联。因此,越来越多的研究人员致力于开发统一的图像融合框架。MST-SR是第一个通用的图像融合框架,它通过结合多尺度变换(MST)和稀疏表示(SR)技术来实现互补信息聚合。随后,Zhang 等人参考DeepFuse 设计了第一个用于通用图像融合的卷积神经网络。此外,PMGI将不同的图像融合问题视为梯度和强度的比例保持,以及设计统一形式的损失函数。在PMGI的基础上,Zhang 等人提出了一个挤压和分解网络和一个自适应决策块,以进一步提高融合性能。此外,Zhao 等人通过学习特定领域和一般领域的特征表示,开发了一个多领域图像融合的通用框架。特别地,考虑到不同的融合场景可以相互促进,Xu等人通过结合可学习信息测量和弹性权重合并,开发了一种用于多融合任务的统一无监督图像融合模型。
值得强调的是,无论是特定于任务的融合方法还是一般的融合方法都不能充分利用图像的长距离相互作用。换句话说,这些算法仅从局部角度合并互补信息,而不能实现全局信息聚合。
Vision Transformer
最近,自然语言处理模型,即,Transformer 在计算机视觉界受到了广泛关注。有许多基于Transformer的模型在各种视觉任务中取得了令人印象深刻的性能,例如视觉识别,对象检测,跟踪,分割和图像恢复。由于其强大的远程建模能力,Transformer也被引入图像融合。基于CNN的融合框架,VS等人。设计了一种基于Spatio-Transformer的多尺度融合策略,这是一个局部和全局语境。此外,在基于AE的融合框架的基础上,Fu等人用Patch Pyramid Transformer替换CNN架构,从整个图像中提取非局部信息。然而,仅由Transformer组成的自动编码器无法有效地提取局部信息。为此,Zhao等人提出了一种顺序DenseNet和双Transformer架构,称为DNDT,以提取局部和全局信息,其中双Transformer在融合层之前加强了特征中的全局信息。此外,Qu等人开发了TransMEF,它将并行Transformer和CNN架构注入到基于AE的融合框架中,并利用自监督多任务学习来实现多曝光图像融合。随后,Li 等人提出了用于可见光和红外图像融合的卷积引导Transformer框架(即,CGTF),旨在联合CNN的局部特征和Transformer的长程依赖特征,以生成更令人满意的融合结果。此外,Rao 等人还将Transformer引入到基于GAN的融合框架中,以实现可见光和红外图像融合。
然而,上述融合Transformer仅从同一域挖掘远程依赖性(或全局交互)。事实上,跨域的长程相关性与图像融合问题更相关。此外,这些基于Transformer的融合算法中的大多数,例如IFT、DNDT、TransMEF和CGTF,只能处理具有固定大小的输入图像(例如,256 × 256)。此外,现有的图像融合视觉变换器仅解决特定的图像融合问题,但未能在统一的融合框架中解决多模态图像融合和数字摄影图像融合场景。因此,我们充分探索不同的图像融合场景之间的共性。然后,将多模态图像融合和数字摄影图像融合统一建模为结构保持、纹理保持和适当的强度控制。此外,设计了一个注意力引导的跨域融合模块,有效地挖掘和整合融合过程中域内和域间的全局交互。
METHODOLOGY
在这一部分中,将多模态图像融合和数字摄影图像融合推广到结构信息保持、纹理细节保持和适当的强度控制。首先,我们给出了总体框架。接下来,给出了统一损失函数的设计。
Overall Framework
令I1 ∈
R
H
×
W
×
C
i
n
R^{H×W×Cin}
RH×W×Cin和I2 ∈
R
H
×
W
×
C
i
n
R^{H×W×Cin}
RH×W×Cin表示来自不同域的两幅对齐的源图像,If ∈
R
H
×
W
×
C
o
u
t
R^{H×W×Cout}
RH×W×Cout是具有完整场景表示的融合图像。H、W和Cin是输入图像的高度、宽度和通道数。Cout是融合图像的通道数。所提出的SwinFusion旨在通过合并源图像I1、I2中的局部和全局互补信息来生成融合图像If。如图2所示,SwinFusion可分为三个部分:特征提取、注意力引导的跨域融合和重建。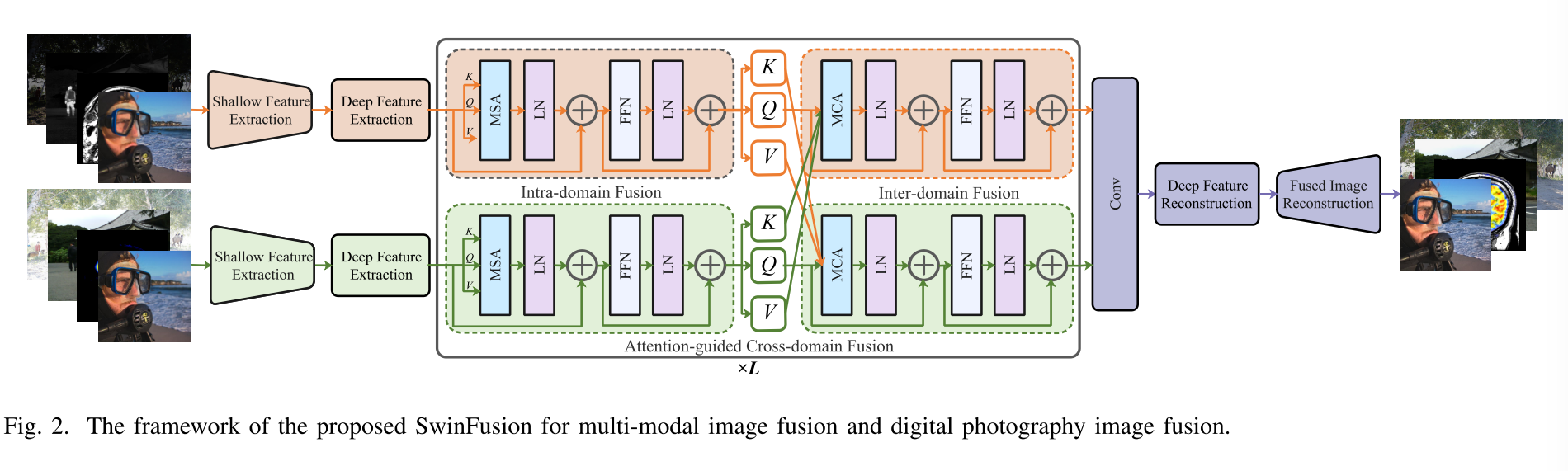
Feature Extraction:
首先,我们通过多个卷积层HSE(·)从源图像I1和I2中提取浅层特征
F
1
F^1
F1SF和
F
2
F^2
F2SF,其可以表示为: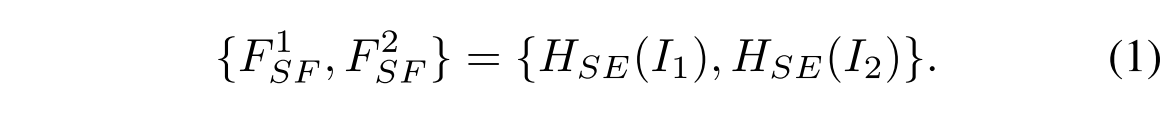
卷积层擅长早期视觉处理,从而实现更稳定的优化和更好的结果。它还提供了一种简单而有效的方法来提取局部语义信息,并将这些信息映射到高维特征空间。浅层特征提取模块由两个卷积层组成,具有Leaky Relu激活函数,其内核大小为3 × 3,步长为1。
之后,我们从
F
1
F^1
F1SF和
F
2
F^2
F2SF提取深度特征
F
1
F^1
F1DF和
F
2
F^2
F2DF,如下: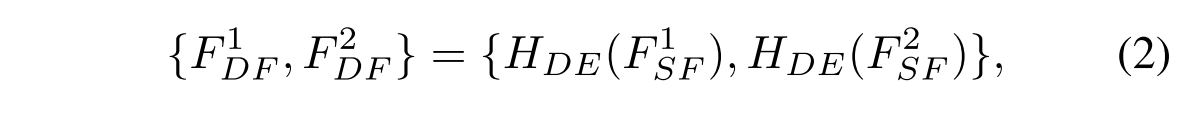
其中HDE(·)是包含N个Swin Transformer层的深度特征提取单元。Swin Transformer层的核心架构与域间融合单元一致,这将在下面详细描述。在本工作中,N被设置为4。
Attention-guided Cross-domain Fusion: 在提取具有足够全局语义信息的深度特征后,我们设计了一个注意力引导的跨域融合模块(ACFM)来进一步挖掘和聚合域内和域间全局上下文。
首先,我们设计了一个基于自注意力的域内融合单元,有效地整合了同一域中的全局交互。基于移窗机制的注意力是设计域内融合单元的基本组成部分。给定具有H ×W × C大小的特征F,移位窗口机制首先通过将输入分割成不重叠的M × M个局部窗口来将输入重新整形为HW/
M
2
M^2
M2 ×
M
2
M^2
M2×C特征,其中HW/
M
2
M^2
M2是窗口的总数。接下来,它分别为每个窗口执行标准的自我注意。对于局部窗口特征X ∈
R
M
2
×
C
R^{M2×C}
RM2×C,采用跨不同窗口共享的三个可学习权重矩阵
W
Q
W^Q
WQ ∈
R
C
×
C
R^{C×C}
RC×C、
W
K
W^K
WK ∈
R
C
×
C
R^{C×C}
RC×C和
W
V
W^V
WV ∈
R
C
×
C
R^{C×C}
RC×C,通过以下方式将其投影到查询Q、键K和值V中: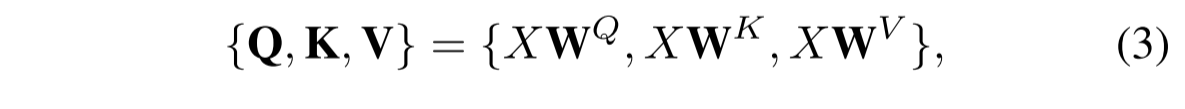
然后,注意力函数基本上计算查询与所有键的点积,然后使用softmax运算符对其进行归一化以产生注意力分数。注意机制定义为:
其中dk是键的维度,B是可学习的相对位置编码。我们将自注意扩展为多头自注意(MSA),使注意机制能够考虑各种注意力分布,使模型从不同的角度捕获信息。在实践中,我们并行执行h次注意函数,并将多个头部自注意的结果连接起来,其中h在我们的工作中设置为6。接下来,一个前馈网络(FFN),由两个多层感知器(MLP)层与GELU激活层被部署到细化MSA产生的特征令牌。层归一化(LN)总是在MSA和FFN之后执行,并且剩余连接被应用于两个模块。因此,针对局部窗口特征X的域内融合单元的全过程被公式化为:
其中Z是域内融合单元的输出,其中X作为输入。前馈网络(FFN)如下:
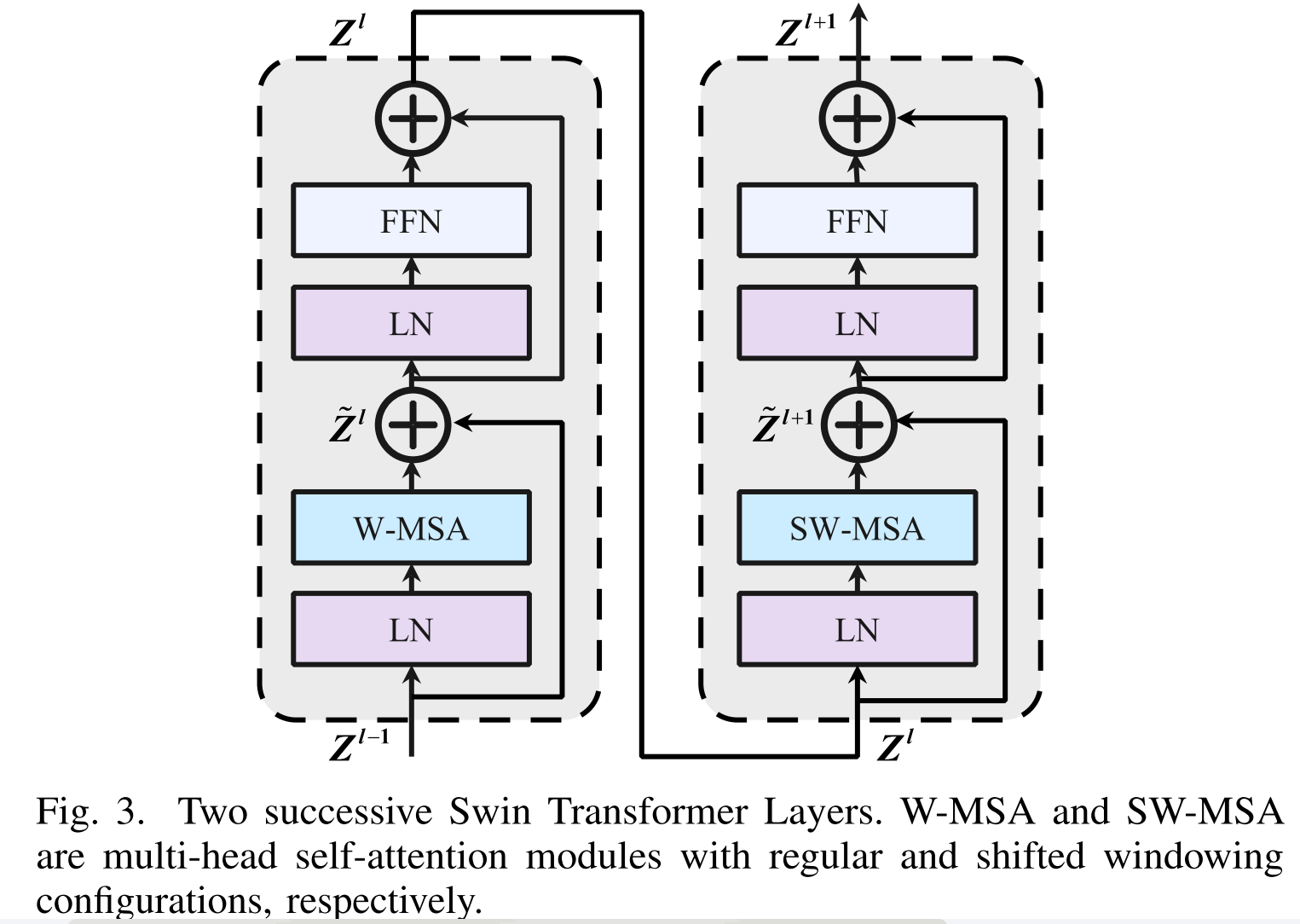
其中GELU是高斯误差线性单位。特别地,SwinTransformer层遵循与域内融合单元相同的处理过程。我们还在图3中呈现了两个连续SwinTransformer层的框架,以清楚地说明它们的处理过程。值得注意的是,如果不同层的分区是固定的,则不存在跨本地窗口的连接。因此,根据文献[33],[38],我们交替使用常规和移位窗口分区来实现跨窗口连接,其中移位窗口分区意味着在分区之前将特征移位(M/2,M/2)个像素。图4示出了用于计算SwinTransformer层和域内融合单元中的注意力的移位窗口机制的示例。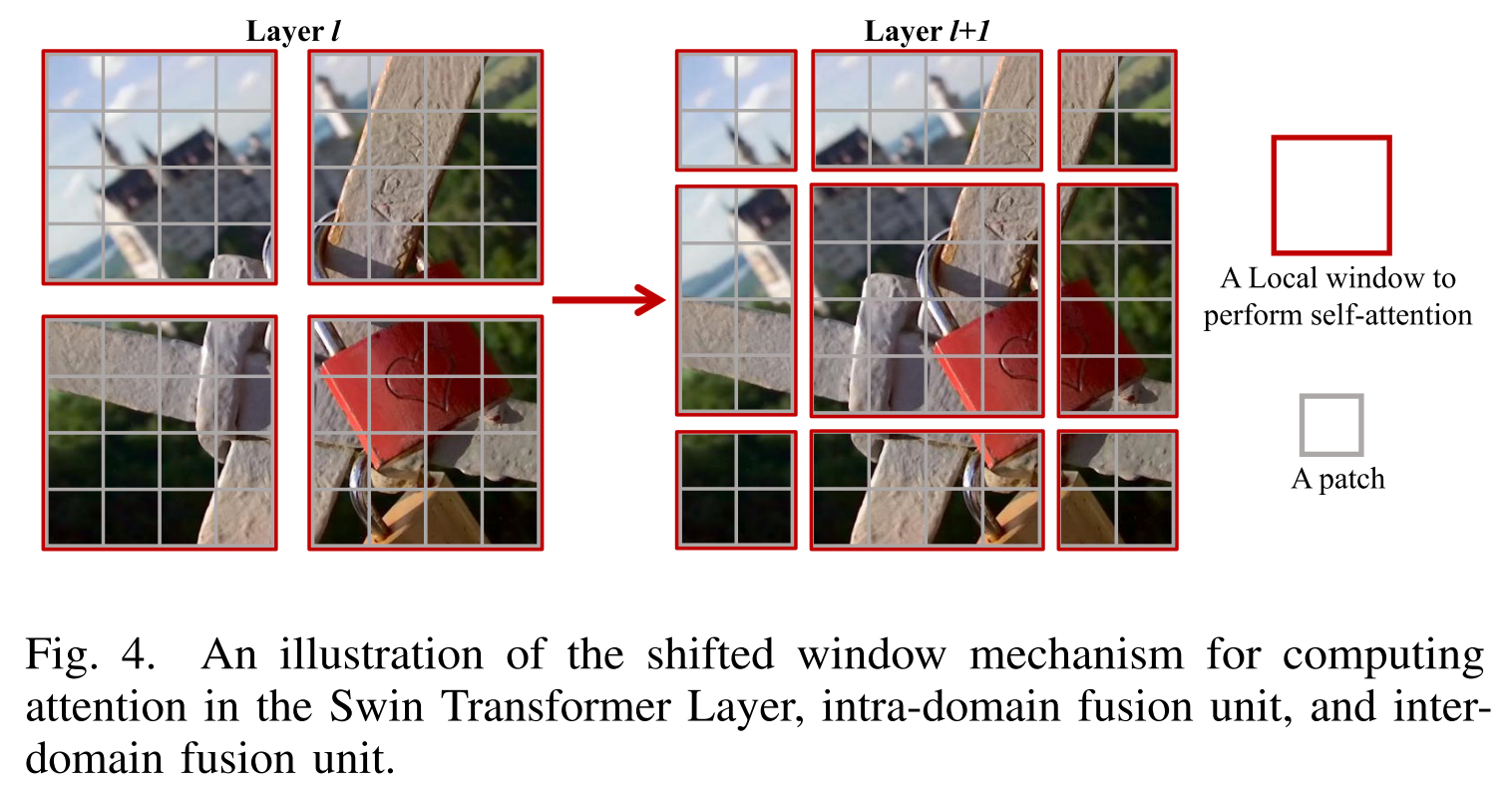
可以看出,在层l中,采用常规窗口划分方案,并且在每个窗口内计算注意力。在下一层(即,层l + 1),窗口分割被移位,这导致新的窗口。因此,新窗口中的注意力计算跨越层1中的窗口的边界,从而提供它们之间的连接。
在域内融合单元的基础上,我们还设计了一个基于交叉注意的域间融合单元,以进一步整合不同域之间的全局交互。域内融合单元和域间融合单元都遵循类似的基线。主要区别在于域间融合单元采用多头交叉关注(MCA)而不是MSA来实现跨域的全局上下文交换。因此,给定来自不同域的两个局部窗口特征X1和X2,域间融合单元的整个过程被定义为: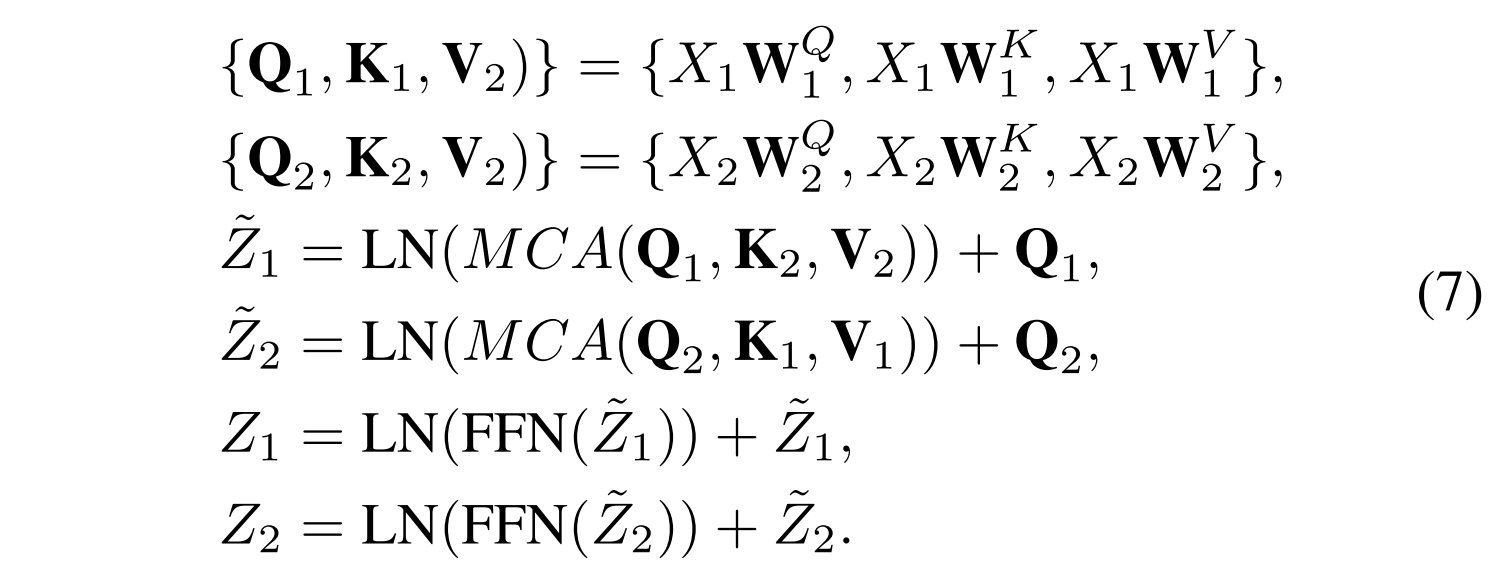
如Eq.(7)对于来自域1的Q1,它通过用来自域2的K2和V2执行注意力加权来合并跨域信息,同时通过残差连接保留域1中的信息,反之亦然。我们的模型部署了L个注意力引导的跨域融合模块,由级联的域内融合单元和域间融合单元组成,交替集成全局域间和跨域交互。为了平衡计算效率和融合性能,我们将L设置为2。
在注意力引导的跨域融合模块之后,部署具有空间不变滤波器的卷积层以聚合不同域中的局部信息并增强我们的SwinFusion的平移等方差,其可以用公式表示为:
Reconstruction: 在完全合并不同域中的互补信息之后,我们设计了基于Transformer的深度特征重建单元和基于CNN的图像重建单元,以将融合的深度特征映射回图像空间。首先,部署包含P个Swin Transformer层的深度特征重构单元HDR(·)以从全局角度细化融合的深度特征并恢复融合的浅层特征。该过程可以表示为: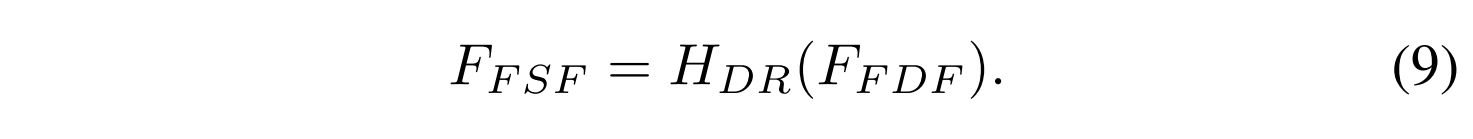
为了充分利用深层特征中的全局上下文来恢复融合的浅层特征,P被设置为4。然后,部署基于CNN的图像重建单元HIR(·)以减少通道的数量并生成融合图像If,其表示为:
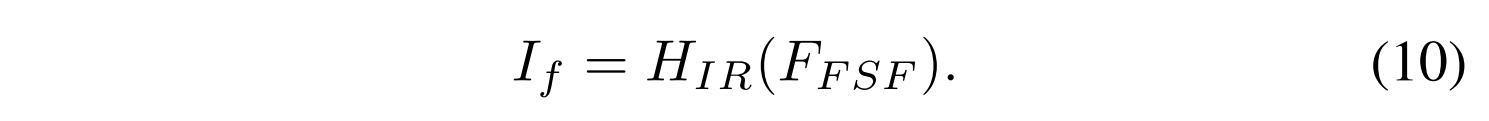
融合图像重建单元包含三个卷积层,核大小为3 × 3,步长为1,其中前两层后面是Leaky Relu激活函数。
Loss Function
为了统一建模多模态图像融合和数字摄影图像融合,我们将不同的图像融合问题归纳为结构保持,纹理保持和适当的强度控制。因此,我们设计SSIM损失,纹理损失和强度损失来约束网络。
SSIM Loss: 考虑到结构相似性(SSIM)指标是最广泛使用的度量,其从三个方面反映图像失真,即,光、对比度和结构,我们采用SSIM损失Lssim来约束If与I1、I2之间的结构相似性。具体地,SSIM损耗被定义为: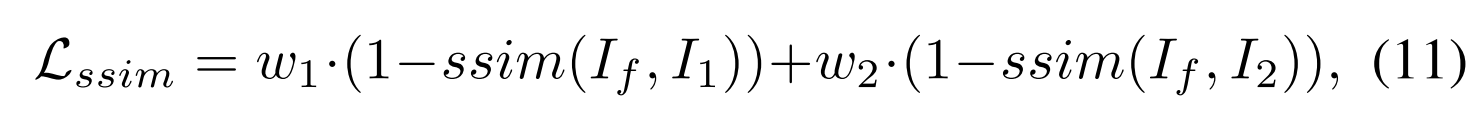
其中ssim(·)表示结构相似性操作,其测量两个图像的相似性。我们认为,这两个源图像有相同的贡献,融合结果的结构信息。因此,我们在这项工作中设置w1 = w2 = 0.5。
Texture Loss: 图像融合的目标之一是将源图像中的纹理细节整合到单个融合图像中。我们观察到,在源图像的纹理细节可以有效地聚合的最大选择策略。因此,纹理损失Ltext,在等式(12)中呈现,旨在引导网络尽可能多地保留纹理细节。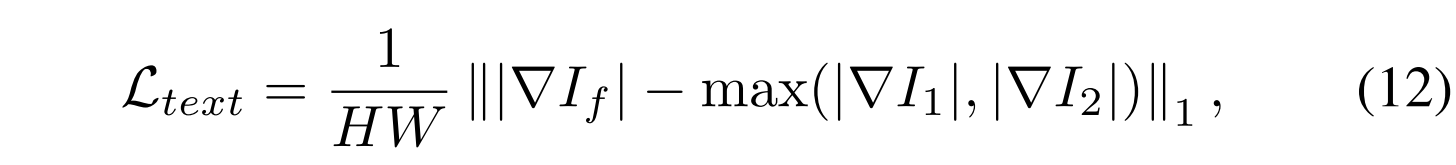
其中▽表示Sobel梯度算子,其可以测量图像的纹理信息。|·|表示绝对运算,||·||1表示l1范数,max(·)表示逐元素最大值选择。
Intensity Loss: 一个优秀的图像融合算法应该能够根据源图像的全局表观亮度信息生成具有合适亮度的融合图像。为此,我们设计了以下强度损失Lint来指导我们的融合模型捕获适当的强度信息: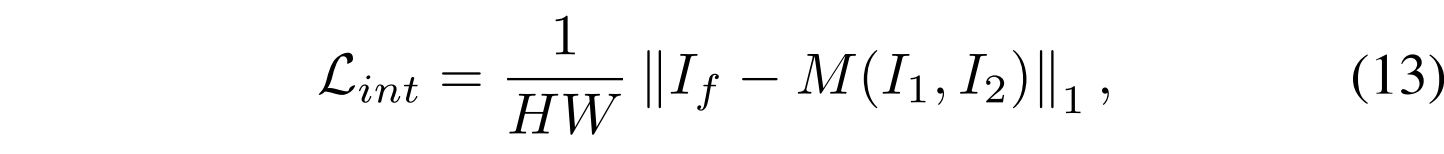
其中M(·)是逐元素聚合运算,其与特定融合场景相关联。受IFCNN的启发,逐元素最大值选择,即,max(·)用于可见光和红外图像融合(VIF)、医学图像融合(Med)和多焦点图像融合(MFF)。此外,我们利用逐元素平均聚合,即,可见光和近红外图像融合(VIS-NIR)和多曝光图像融合(MEF)的mean(·)。
最后,我们的融合模型的完整目标函数是来自等式(11)到(13)的所有子损失项的加权和:

