
- 1【物联网应用案例】智能农业的 9 个技术用例
- 2tcp、http中的保活机制keep-alive_tcp连接多久会自动断开
- 3linux传输数据包丢失,pcap_next偶尔会丢失Linux上的数据包
- 4第27期:索引设计(全文索引原理)_mysql 无符号 int64
- 5web开发之即时通讯数据库设计_web im数据库设计
- 6JAVA300第四章作业_3、编写 java 程序,用于显示人的姓名和年龄。定义一个学生类student。 该类中应该
- 7dell服务器怎么看硬件状态,DELL服务器硬件报错解决方法对照表.pdf
- 8RTSP客户端接收H264的RTP包并解析遇到的问题_rtsp流无法解析出pps信息怎么办
- 9Html基本结构、语法规则、常用标记/标签_请列出与创建标记语言文档相关的文档技术、网页组件、组织程序和指南的五条规则?
- 10常见的服务器操作系统和工作站操作系统_电脑、工作站、服务器正版系统有哪些
Docker与k8s的恩怨情仇(三)—后浪Docker来势汹汹_k8s 下发pod 镜像下载太慢,导致端口被docker-proxy占用了
赞
踩
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
上一节我们为大家介绍了Cloud Foundry等最初的PaaS平台如何解决容器问题,本文将为大家展示Docker如何解决Cloud Foundry遭遇的一致性和复用性两个问题,并对比分析Docker和传统虚拟机的差异。
Docker相比于Cloud Foundry的改进
利用“Mount Namespace”解决一致性问题
在本系列文章的第一节中,我们提到Docker通过Docker 镜像(Docker Image)功能迅速取代了Cloud Foundry,那这个Docker镜像到底是什么呢,如何通过为不同的容器使用不同的文件系统以解决一致性问题?先卖个关子,我们先来看看上一节中说过隔离功能和Namespace机制。
Mount Namespace,这个名字中的“Mount”可以让我们想到这个机制是与文件挂载内容相关的。Mount Namespace是用来隔离进程的挂载目录的,让我们可以通过一个“简单”的例子来看看它是怎么工作的。

(用C语言开发出未实现文件隔离的容器)
上面是一个简单的的C语言代码,内容只包括两个逻辑:
1.在main函数中创建了一个子进程,并且传递了一个参数CLONE_NEWNS,这个参数就是用来实现Mount Namespace的;
2.在子进程中调用了/bin/bash命令运行了一个子进程内部的shell。
让我们编译并且执行一下这个程序:
gcc -o ns ns.c
./ns
这样我们就进入了这个子进程的shell中。在这里,我们可以运行ls /tmp查看该目录的结构,并和宿主机进行一下对比:

(容器内外的/tmp目录)
我们会发现两边展示的数据居然是完全一样的。按照上一部分Cpu Namespace的结论,应该分别看到两个不同的文件目录才对。为什么?
容器内外的文件夹内容相同,是因为我们修改了Mount Namespace。Mount Namespace修改的是进程对文件系统“挂载点”的认知,意思也就是只有发生了挂载这个操作之后生成的所有目录才会是一个新的系统,而如果不做挂载操作,那就和宿主机的完全一致。
如何解决这个问题,实现文件隔离呢?我们只需要在创建进程时,在声明Mount Namespace之外,告诉进程需要进行一次挂载操作就可以了。简单修改一下新进程的代码,然后运行查看:

(实现文件隔离的代码和执行效果)
此时文件隔离成功,子进程的/tmp已经被挂载进了tmpfs(一个内存盘)中了,这就相当于创建了完全一个新的tmp环境,因此子进程内部新创建的目录宿主机中已经无法看到。
上面这点简单的代码就是来自Docker镜像的实现。Docker镜像在文件操作上本质是对rootfs的一次封装,Docker将一个应用所需操作系统的rootfs通过Mount Namespace进行封装,改变了应用程序和操作系统的依赖关系,即原本应用程序是在操作系统内运行的,而Docker把“操作系统”封装变成了应用程序的依赖库,这样就解决了应用程序运行环境一致性的问题。不论在哪里,应用所运行的系统已经成了一个“依赖库”,这样就可以对一致性有所保证。
利用“层”解决复用性问题
在实现文件系统隔离,解决一致性问题后,我们还需要面对复用性的问题。在实际使用过程中,我们不大可能每做一个镜像就挂载一个新的rootfs,费时费力,不带任何程序的“光盘”也需要占用很大磁盘空间来实现这些内容的挂载。
因此,Docker镜像使用了另一个技术:UnionFS以及一个全新的概念:层(layer),来优化每一个镜像的磁盘空间占用,提升镜像的复用性。
我们先简单看一下UnionFS是干什么的。UnionFS是一个联合挂载的功能,它可以将多个路径下的文件联合挂载到同一个目录下。举个“栗子”,现在有一个如下的目录结构:

(使用tree命令,查看包含A和B两个文件夹)
A目录下有a和x两个文件,B目录下有b和x两个文件,通过UnionFS的功能,我们可以将这两个目录挂载到C目录下,效果如下图所示:
mount -t aufs -o dirs=./a:./b none ./C

(使用tree命令查看联合挂载的效果)
最终C目录下的x只有一份,并且如果我们对C目录下的a、b、x修改,之前目录A和B中的文件同样会被修改。而Docker正是用了这个技术,对其镜像内的文件进行了联合挂载,比如可以分别把/sys,/etc,/tmp目录一起挂载到rootfs中形成一个在子进程看起来就是一个完整的rootfs,但没有占用额外的磁盘空间。
在此基础上,Docker还自己创新了一个层的概念。首先,它将系统内核所需要的rootfs内的文件挂载到了一个“只读层”中,将用户的应用程序、系统的配置文件等之类可以修改的文件挂载到了“可读写层”中。在容器启动时,我们还可以将初始化参数挂载到了专门的“init层”中。容器启动的最后阶段,这三层再次被联合挂载,最终形成了容器中的rootfs。
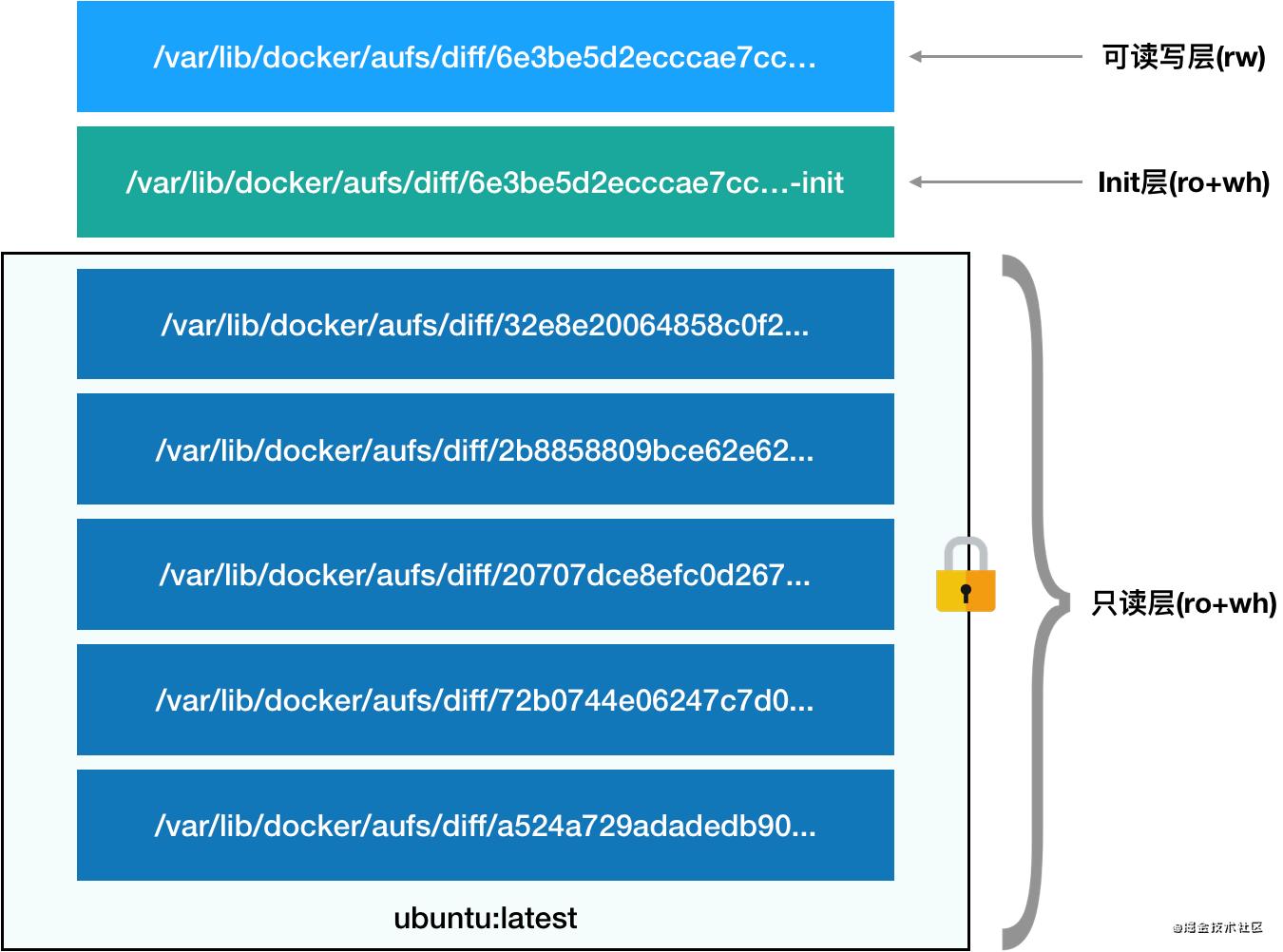
(Docker的只读层、可读写层和init层)
从上面的描述中,我们可以了解到只读层最适合放置的是固定版本的文件,代码几乎不会改变,才能实现最大程度的复用。比如活字格公有云是基于.net core开发的,我们将其用到的基础环境等都会设计在了只读层,每次获取最新镜像时,因为每一份只读层都是完全一样的,所以完全不用下载。
Docker的“层”解释了为什么Docker镜像只在第一次下载时那么慢,而之后的镜像都很快,并且明明每份镜像看起来都几百兆,但是最终机器上的硬盘缺没有占用那么多的原因。更小的磁盘空间、更快的加载速度,让Docker的复用性有了非常显著的提升。
Docker容器创建流程
上面介绍的是Docker容器的整个原理。我们结合上一篇文章,可以总结一下Docker创建容器的过程其实是:
- 启用Linux Namespace配置;
- 设置指定的Cgroups参数;
- 进程的根目录
- 联合挂载各层文件
题外:Docker与传统虚拟机的区别
其实Docker还做了很多功能,比如权限配置,DeviceMapper等等,这里说的仅仅是一个普及性质的概念性讲解,底层的各种实现还有很复杂的概念。具体而言,容器和传统的虚拟机有啥区别?
其实容器技术和虚拟机是实现虚拟化技术的两种手段,只不过虚拟机是通过Hypervisor控制硬件,模拟出一个GuestOS来做虚拟化的,其内部是一个几乎真实的虚拟操作系统,内部外部是完全隔离的。而容器技术是通过Linux操作系统的手段,通过类似于Docker Engine这样的软件对系统资源进行的一次隔离和分配。它们之间的对比关系大概如下:
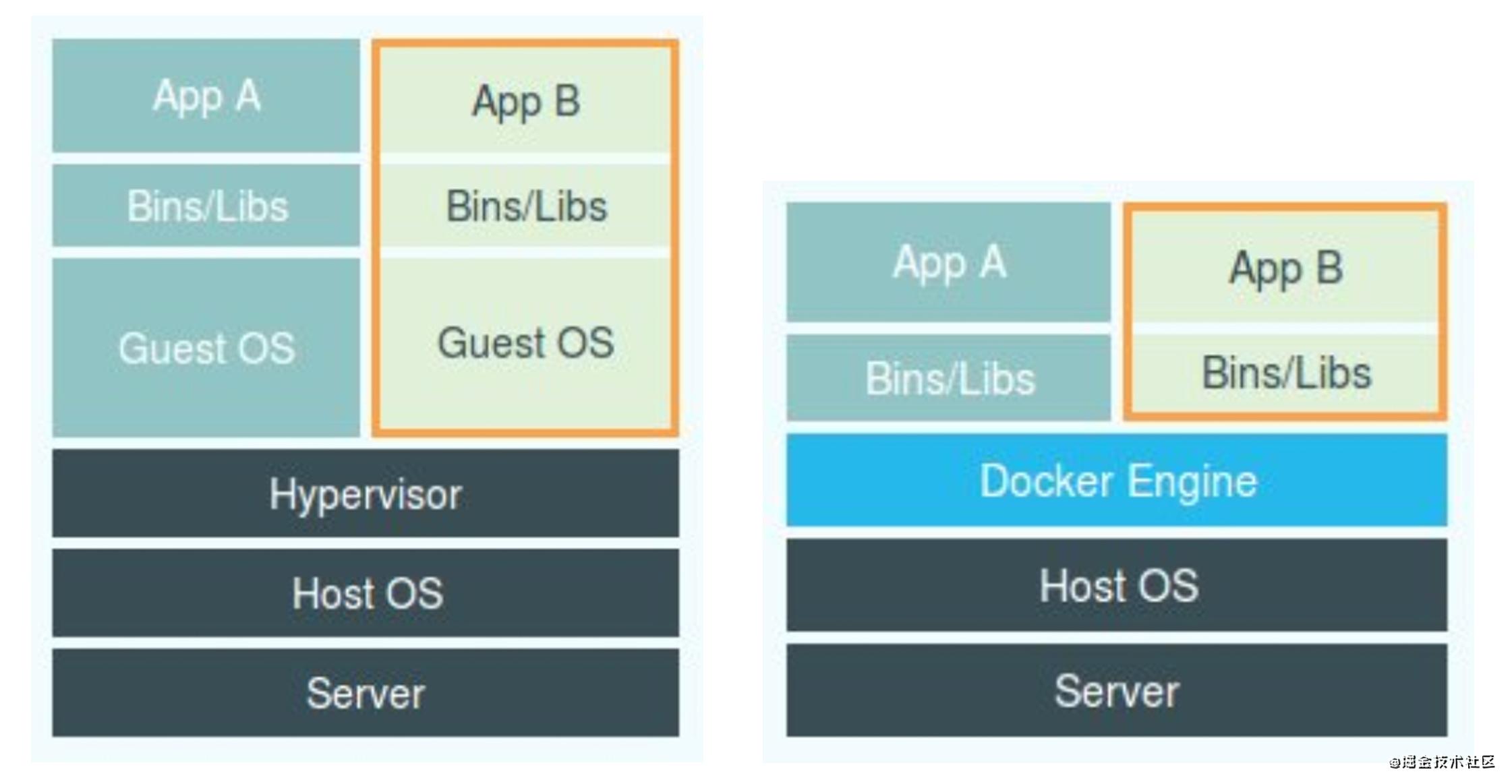
(Docker vs 虚拟机)
虚拟机是物理隔离,相比于Docker容器来说更加安全,但也会带来一个结果:在没有优化的情况下,一个运行CentOS 的 KVM 虚拟机启动后自身需要占用100~200MB内存。此外,用户应用也运行在虚拟机里面,应用系统调用宿主机的操作系统不可避免需要经过虚拟化软件的拦截和处理,本身会带来性能损耗,尤其是对计算资源、网络和磁盘I/O的损耗非常大。
但容器与之相反,容器化之后的应用依然是一个宿主机上的普通进程,这意味着因为虚拟化而带来的损耗并不存在;另一方面使用Namespace作为隔离手段的容器并不需要单独的Guest OS,这样一来容器额外占用的资源内容几乎可以忽略不计。
所以,对于更加需要进行细粒度资源管理的PaaS平台而言,这种“敏捷”和“高效”的容器就成为了其中的佼佼者。看起来解决了一切问题的容器。难道就没有缺点吗?
其实容器的弊端也特别明显。首先由于容器是模拟出来的隔离性,所以对Namespace模拟不出来的资源:比如操作系统内核就完全无法隔离,容器内部的程序和宿主机是共享操作系统内核的,也就是说,一个低版本的Linux宿主机很可能是无法运行高版本容器的。还有一个典型的栗子就是时间,如果容器中通过某种手段修改了系统时间,那么宿主机的时间一样会改变。
另一个弊端是安全性。一般的企业,是不会直接把容器暴露给外部用户直接使用的,因为容器内可以直接操作内核代码,如果黑客可以通过某种手段修改内核程序,那就可以黑掉整个宿主机,这也是为什么我们自己的项目从刚开始自己写Docker到最后弃用的直接原因。现在一般解决安全性的方法有两个:一个是限制Docker内进程的运行权限,控制它值能操作我们想让它操作的系统设备,但是这需要大量的定制化代码,因为我们可能并不知道它需要操作什么;另一个方式是在容器外部加一层虚拟机实现的沙箱,这也是现在许多头部大厂的主要实现方式。
小结
Docker凭借一致性、复用性的优势战胜了前辈Cloud Foundry。本文介绍了Docker具体对容器做的一点改变,同时也介绍了容器的明显缺点。下一篇文章,我们会为大家介绍Docker又是如何落寞,而后Docker时代,谁又是时代新星。敬请期待。

