
- 1多线程进阶:volatile的作用以及实现原理_多线程共享变量volatile
- 2Vue3-Axios二次封装与Api接口统一管理_vue3 axios 接口
- 3java-简易计算器设计_java简易计算器设计
- 4C语言求定积分_c语言求定积分的代码
- 5节省时间的分层测试,到底怎么做?_分层测试思路怎么写
- 6如何理解Vue_对vue的理解
- 7ERROR: your rosdep installation has not been initialized yet
- 8虚拟机Ubuntu20.04安装Anaconda3_虚拟机安装anaconda3
- 9tp5框架防止xss攻击_tp5 xss过滤代码
- 10一文搞懂大模型RAG应用(附实践案例)_大模型中 rag是什么
rk3588部署yolov5
赞
踩
总体流程:
YOLOv5 训练得到pt文件
pt-->onnx
onnx-->rknn
使用rknn进行推理
一、YOLOv5 训练得到pt文件:
去瑞芯微官网下载他们的YOLOv5,不要用YOLOv5官网的。
用这里面的train.py训练,训练方法和官网一样,这里就不多说了,最后得到一个best.pt权重文件。
有几个地方要注意:
numpy改成1.22版本,否则会报一个numpy.int找不到的错
pillow改成9.5版本
opencv-python改成改成与python对应的版本
如果要使用GPU加速的话,需要安装GPU版本的torch,cuda和cudnn,自己电脑的cuda版本可以在cmd中输入nvidia-smi查看。
CUDA安装地址:CUDA
cudnn安装地址:cudnn
torch安装地址:PyTorch
等这些都安装完成后,再安装requirements.txt中的包。安装成功后,可以输入
- import torch
- print(torch.cuda.is_available())
输出为True则GPU版的安装成功
如果不小心先安装了requirements,需要在更换版本之前删除掉之前安装的版本,torch要特别注意删掉torch、torchvision、torchaudio三个包,可以通过pip list查看
二、pt文件转化onnx文件
在yolov5文件夹中,执行export.py文件:(onnx需要自己安装,记住安装的版本,后面要用)
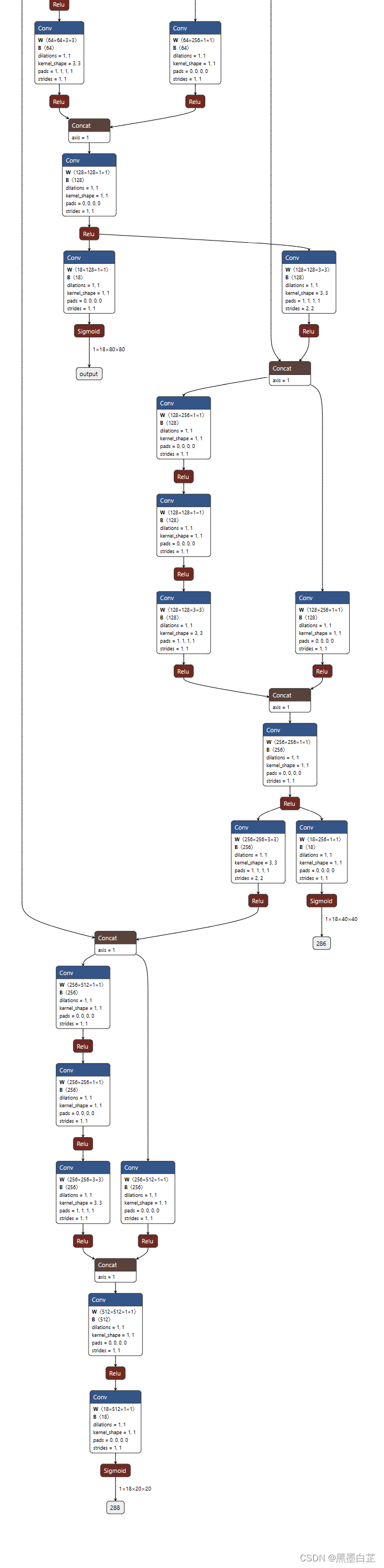
python export.py --weights best.pt --img 640 --batch 1 --include onnx --rknpu RK3588得到best.onnx,可以使用Netron查看网络结构,末端样子应该是这样有三个输出的。
三、onnx文件转化rknn文件
前面的两步的环境是windows或者linux都可以,但是这一步只能在linux环境下进行。
这里建议建立一个新的环境,python版本为3.10,下载rknn-toolkit2,进入rknn-toolkit2/packages/目录下,根据自己的情况,安装requirement和rknn_toolkit2,因为这里的环境大概率和yolo的环境不一样,所以建议新建环境。也可以第二步和第三步共用这一个环境,防止onnx版本不一样的报错。
下载rknn_model_zoo,进入./models/CV/object_detection/yolo/RKNN_model_convert目录下,修改yolo_ppyolo.yml。
注意:pt转化onnx的环境和onnx转化rknn的环境下onnx的版本必须是一样的。

例如下面我写的文件:
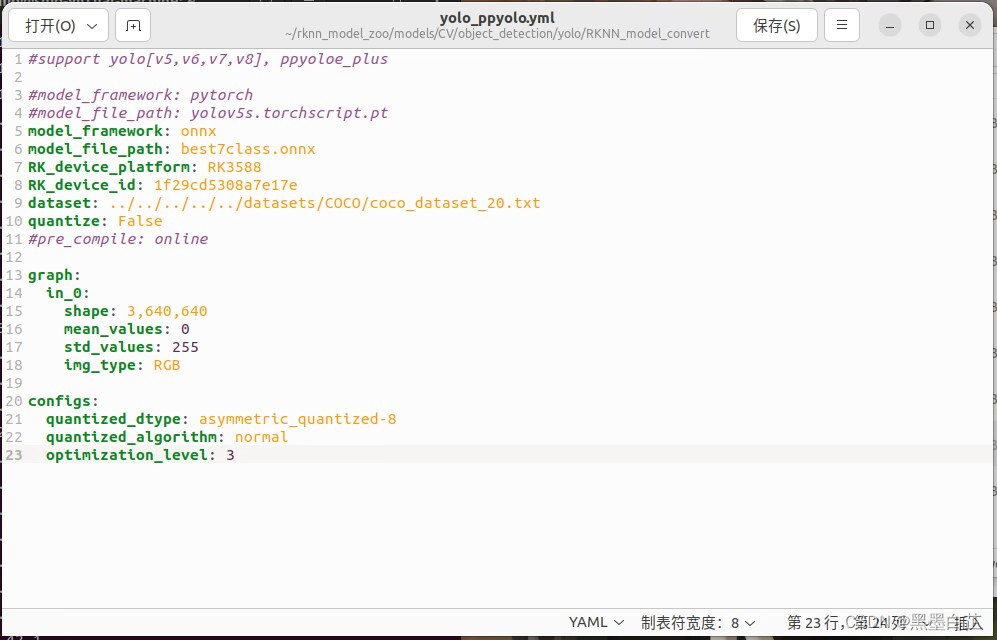
修改完成后,在当前目录下输入指令转化rknn模型:
python ../../../../../common/rknn_converter/rknn_convert.py --yml_path ./yolo_ppyolo.yml --python_api_test --capi_test执行完后再当前目录下会生成一个model_cvt文件夹,里面就是转好的模型。使用量化得到的模型文件名带有i8,没量化的文件名带有fp。
四、在rk3588上使用npu进行推理
注:本节全部在rk3588上进行,不是在上位机上编译然后推过来的
下载RKNN_toolkit_2(从这里git)到rk3588上,在下面路径中把标签数量改成自己的:
/rknn_model_zoo/models/CV/object_detection/yolo/RKNN_C_demo/RKNN_toolkit_2/rknn_yolo_demo/include/yolo.h在下面路径中把标签改成自己的 (编译之前改):
rknn_model_zoo/models/CV/object_detection/yolo/RKNN_C_demo/RKNN_toolkit_2/rknn_yolo_demo/model/coco_80_labels_list.txt或者也可以在编译之后改,在下面的路径里:(这条和上面一条二选一)
/rknn_model_zoo/models/CV/object_detection/yolo/RKNN_C_demo/RKNN_toolkit_2/rknn_yolo_demo/install/rknn_yolo_demo_Linux/model/coco_80_labels_list.txt编译前需要进入下面这个路径,然后下载两个依赖库:
- # 路径
- /rknn_model_zoo/libs/rklibs
-
- # 两个依赖库
- # RK3566/RK3568/RK3588/RV1106/RV1103 NPU 依赖库
- git clone https://github.com/rockchip-linux/rknpu2
- # RGA调用依赖库,不区分硬件平台
- git clone https://github.com/airockchip/librga
然后编译:
./build-linux_RK3588.sh会生成两个文件夹,分别是build和install,我们需要进入到install文件夹中,找到rknn_yolo_demo这个可执行文件,cd到这个路径下输入
- export LD_LIBRARY_PATH=./lib
- # best.rknn是转换后得到的rknn文件,inputimg.jpg是待识别的图片
- ./rknn_yolo_demo yolov5 fp ./best.rknn ./inputimg.jpg
识别完成后会输出一张out.bmp,就是识别的结果。
五、视频推理
视频推理官方给了另一个方法rknpu2
整体流程与上面基本相同,可以从上面的第二步继续做(得到onnx之后)。
首先来转换rknn模型,这里的rknn不能和上面的混用,进入以下路径:
rknpu2/tree/master/examples/rknn_yolov5_demo/convert_rknn_demo/yolov5在onnx2rknn.py进行修改,将platform改为rk3588,onnx路径改成自己文件的路径。
然后直接执行该文件:
python onnx2rknn.py会得到一个文件夹,里面是转化后的模型。
然后进入下面的路径:
rknpu2/examples/rknn_yolov5_demo修改model/coco_80_labels_list.txt中的标签为自己训练集的标签。
修改include/postprocess.h中的OBJ_CLASS_NUM 为自己训练集标签的数目。
修改rknpu2/examples/3rdparty/mpp/Linux/aarch64路径中的so库,因为程序里调用的是一个名字为librockchip_mpp.so的东西,但是这个东西里面没有内容,他最终是指向librockchip_mpp.so.0的,直接编译会报错,所以需要把librockchip_mpp.so这个文件删掉,然后把librockchip_mpp.so.0重命名为librockchip_mpp.so。
编译完成后会生成一个build和install文件夹,里面有单张图片的推理demo和video的demo,使用时可以通过以下指令调用:
- # 我提前把rknn、jpg、h264放在同一级下了
- # 测试单张图片,rknn名字为best,图片名字为bus
- ./rknn_yolov5_demo best.rknn bus.jpg
-
- # 测试视频
- ./rknn_yolov5_video_demo best.rknn video.h264 264
-
- # 如果只有mp4,需要先转换成h264,可以用ffmpeg进行转换

