
- 1基于Python的电影票房爬取与可视化系统的设计与实现_基于python的电影票房获取与可视化系统的设计与实现注册毕设
- 2hive —— struct 复合结构_hive struct合并
- 3Pycharm输出中文乱码_pytorch中文数据集乱码
- 4Python之字符串常用操作_python字符串常见操作
- 5Windows PowerShell命令大全
- 6回文日期(蓝桥杯第十一届省赛B组)(C/C++)_蓝桥杯 2020年省赛b组 回文日期
- 7ts 引入 js后,tsconfig.json 文件报错_corresponding file is not included in tsconfig.jso
- 8Stable Diffusion ubuntu 部署,问题记录_a tensor with all nans was produced in unet. this
- 9本地SD+python直接生成虚拟数字人(附代码链接)_python数字人搭建
- 10WTG--让我们随时随地封装系统!_wtg作用
超级agent的端语言模型Octopus v2: On-device language model for super agent
赞
踩
大型语言模型(LLMs)在函数调用方面展现出卓越的应用潜力,特别是针对Android API的定制应用。与那些需要详尽描述潜在函数参数、有时甚至涉及数万个输入标记的检索增强生成(RAG)方法相比,Octopus-V2-2B在训练和推理阶段均采用了独树一帜的功能标记策略。这一创新不仅令Octopus-V2-2B的性能可与GPT-4比肩,更在推理速度上实现了显著提升,远超基于RAG的方法,因此,它特别适用于边缘计算设备,展现出强大的实用价值。
论文地址:https://arxiv.org/pdf/2404.01744.pdf
模型地址:https://huggingface.co/NexaAIDev/Octopus-v2
以下为论文节选翻译:
摘要
语言模型在各种软件应用程序中显示出有效性,特别是在与自动工作流相关的任务中。这些模型具有调用函数的关键能力,这对于创建 AI 代理至关重要。尽管大规模语言模型在云环境中具有高性能,但它们通常与对隐私和成本的担忧有关。当前用于函数调用的设备端模型面临着延迟和准确性问题。我们的研究提出了一种新方法,该方法使具有 20 亿个参数的设备端模型在准确性和延迟方面都超过了 GPT-4 的性能,并将上下文长度减少了 95%。与具有基于RAG的函数调用机制的Llama-7B相比,我们的方法将延迟提高了35倍。此方法将延迟降低到适合在生产环境中的各种边缘设备上部署的水平,与实际应用程序的性能要求保持一致。
引言
端模型面临着延迟和准确性问题。我们的研究提出了一种新方法,该方法使具有 20 亿个参数的设备端模型在准确性和延迟方面都超过了 GPT-4 的性能,并将上下文长度减少了 95%。与具有基于RAG的函数调用机制的Llama-7B相比,我们的方法将延迟提高了35倍。此方法将延迟降低到适合在生产环境中的各种边缘设备上部署的水平,与实际应用程序的性能要求保持一致。
研究表明,对于 10 亿个参数模型,每个token的能耗达到 0.1J(Liu et al. (2024))。因此,使用传统的检索增强方法对函数调用采用 7B 参数模型,每次调用将消耗 700J,大约是 50kJ iPhone 电池的 1.4%,限制为大约 71 个函数调用。ps,一度电等于3.6×10^6焦耳。
较小的模型通常无法完成推理任务,并且需要大量调整才能有效地调用函数。为了解决这些问题,我们开发了一种方法来提高设备上 2B 参数模型函数调用的准确性和延迟,从而获得最先进的 (SOTA) 结果。此方法涉及标记核心函数的名称,并使用函数标记微调模型。使用这些token进行微调,使模型能够使用额外的特殊token来理解软件应用程序功能,从而学习将功能描述映射到特定token。在推理阶段,与 GPT-4 相比,该模型使用函数token在函数调用中实现更好的性能。我们提出了一个从 Gemma 2B 微调的 2B 参数模型(Gemma Team,Google DeepMind (2023)),在模型推理过程中节省了超过 95% 的上下文长度。对于 iPhone 使用,这可以在相同的电池下实现 37 倍的函数调用,并将每次函数调用的延迟减少约 35 倍。
相关著作
部署设备端语言模型 由于内存限制和较低的推理速度,在 PC 或智能手机等边缘设备上部署更大的模型具有挑战性。尽管如此,将较小规模的大型语言模型 (LLMs) 部署到边缘设备的努力正在进行中。引入了可管理大小的开源模型,例如 Gemma-2B、Gemma-7B、StableCode-3B (Pinnaparaju et al. (2023)) 和 Llama-7B (Touvron et al. (2023))。为了提高这些模型在设备上的推理速度,已经开发了像 Llama cpp (llama.cpp team (2023)) 这样的研究计划。MLC LLM 框架(团队 (2023))允许在手机和其他边缘设备上运行 7B 语言模型,展示了跨各种硬件(包括 AMD、NVIDIA、Apple 和 Intel GPU)的兼容性。
方法论:
用因果语言模型作为分类模型
要成功调用函数,必须从所有可用选项中准确选择适当的函数并生成正确的函数参数。这需要两个阶段的过程:功能选择阶段和参数生成阶段。第一步涉及了解函数的描述及其参数,使用用户查询中的信息为可执行函数创建参数。直接策略可以将分类模型与因果语言模型相结合。我们可以将 N 可用的函数设想为一个选择池,将选择挑战转换为 softmax 分类问题。
一种简单的分类方法可能是基于检索的文档选择,通过语义相似性识别与用户查询最接近的函数。或者,我们可以使用分类模型将查询映射到特定的函数名称。或者,自回归模型(如 GPT 模型)可以在潜在函数的上下文中从用户的查询中预测正确的函数名称。这两种方法基本上都将任务分为两部分,可能需要两个模型, π1 并且 π2 :
其中 q 表示查询, f 表示所选函数名称,params 表示所选函数的参数。在多任务学习/元学习(Caruana (1997))原则的驱动下,为了实现更快的推理速度和系统便利性,我们追求统一的GPT模型策略,设置 π1=π2=π 。因此,我们将目标重新定义为:
对于 P(f|q;π) ,传统方法涉及检索相关函数并提供有关多个相关函数的上下文以推断出最佳函数名称。在大多数用例中,可能的函数名称集是固定的。使用语言模型来表述函数名称时,必须生成多个标记才能形成一个函数名称,这可能会导致不准确。为了减少此类错误,我们建议将函数指定为唯一的功能令牌。例如,在 N 可用函数池中,我们分配了从 到 的标记名称 来符号化这些函数。这将函数名称的预测任务转换为 N 函数令牌之间的单标记分类,从而提高了函数名称预测的准确性,同时减少了所需的标记数量。为了实现这一点,我们在分词器中引入了新的特殊标记, 并修改了预训练模型的架构,以将语言头扩展为额外的 N 单元。因此,对于函数名称预测,我们利用语言模型通过argmax概率选择在 N 函数标记中精确定位正确的函数。
若要选择正确的功能标记,语言模型必须掌握与该标记关联的含义。我们决定将函数描述合并到训练数据集中,使模型能够了解这些专用标记的重要性。我们设计了一个提示模板,可以容纳三种不同的响应方式,便于并行和嵌套函数调用。附录中提供了数据集的详细示例。
- Below is the query from the users, please choose the correct function and generate the
- parameters to call the function.
- Query: {query}
- # for single function call
- Response: <nexa_i>(param1, param2, ...)<nexa_end>
- # for parallel function call
- Response:<nexa_i>(param1, param2, ...);<nexa_j>(param1, param2,
- ...)<nexa_end>
- # for nested function call
- Response:<nexa_i>(param1, <nexa_j>(param1, param2, ...),
- ...)<nexa_end>
- Function description: {function_description}
这种方法还有一个关键的好处。在对模型进行微调以理解功能令牌的意义后,它可以通过使用添加的特殊令牌<nexa_end>作为早期停止标准来进行推理。此策略消除了从函数描述中分析令牌的必要性,删除了相关函数的检索和对其描述的处理。因此,这大大减少了准确识别函数名称所需的标记数量。传统的基于检索的方法与我们目前提出的模型之间的差异如下图所示。
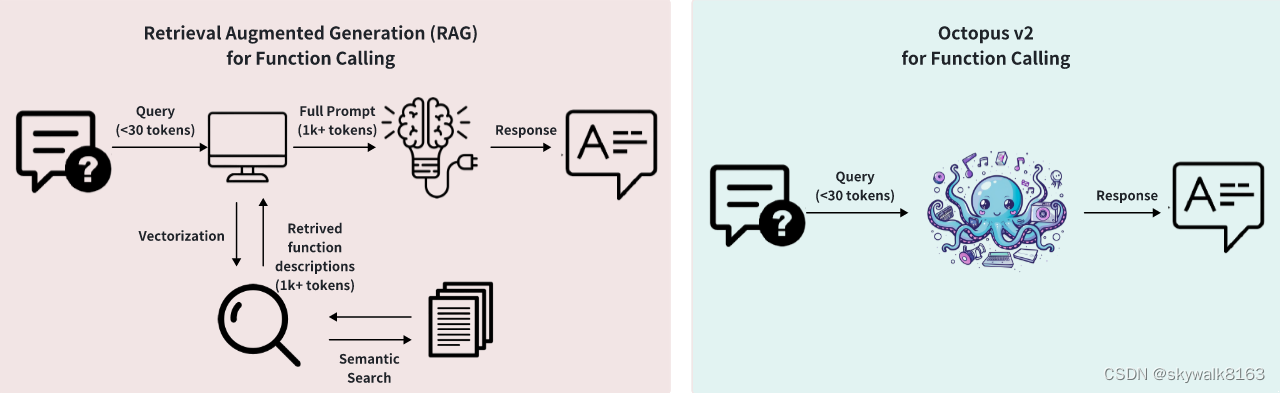
图2
数据集收集
API 集合
例如,我们从 Android API 开始。我们的选择标准包括可用性、使用频率和技术实施的复杂性。我们最终收集了 20 个 Android API,并将它们分为三个独立的类别,确保每个功能都可以通过 Android 应用程序开发在设备上实际执行,前提是开发人员拥有必要的系统权限。此外,我们还编译了车辆中可用的 API。更多例子可以在附录中找到。
1. Android 系统 API 此类别包括用于基本移动操作所必需的系统级功能的 API,例如拨打电话、发短信、设置闹钟、修改屏幕亮度、创建日历条目、管理蓝牙、启用请勿打扰模式和拍照。我们排除了高度敏感的任务,例如访问系统状态信息或更改辅助功能设置。
2. Android 应用程序 API 我们的研究检查了 Android 设备上预装的 Google 应用程序(例如 YouTube、Google Chrome、Gmail 和 Google 地图)的 API。我们探索了访问热门新闻、检索天气更新、搜索 YouTube 内容和地图导航等功能。
3. Android 智能设备管理 API 我们的重点延伸到 Google Home 生态系统,该生态系统包括具有重要市场占有率的各种智能家居设备。我们的目标是通过 API 改善智能设备管理,涵盖调节 Nest 恒温器、管理 Google Nest 设备上的媒体播放以及使用 Google Home 应用程序控制门锁等功能。
数据集生成
我们的方法如图 (3) 所示,展示了组装数据集所涉及的步骤。数据集的创建涉及三个关键阶段:(1)生成相关查询及其关联的函数调用参数;(2)开发不相关的查询,并附有合适的功能机构;(3)通过Google Gemini实现二进制验证支持。
1. Google Gemini 生成的查询和函数调用 创建高质量的数据集取决于制定定义良好的查询和准确的函数调用参数。我们的策略强调生成单个 API 可以解决的正面查询。有了查询和预先确定的 API 描述,我们利用后续的 Google Gemini API 调用来生成所需的函数调用参数。
2. 负样本 为了提高模型的分析能力和实际应用,我们结合了来自正负数据集的示例。这些集合之间的平衡由图 3 中的比率 MN 表示,这是我们实验方法的基础。具体来说,我们选择 M 相等的 和 N ,每个都分配一个值 1000。
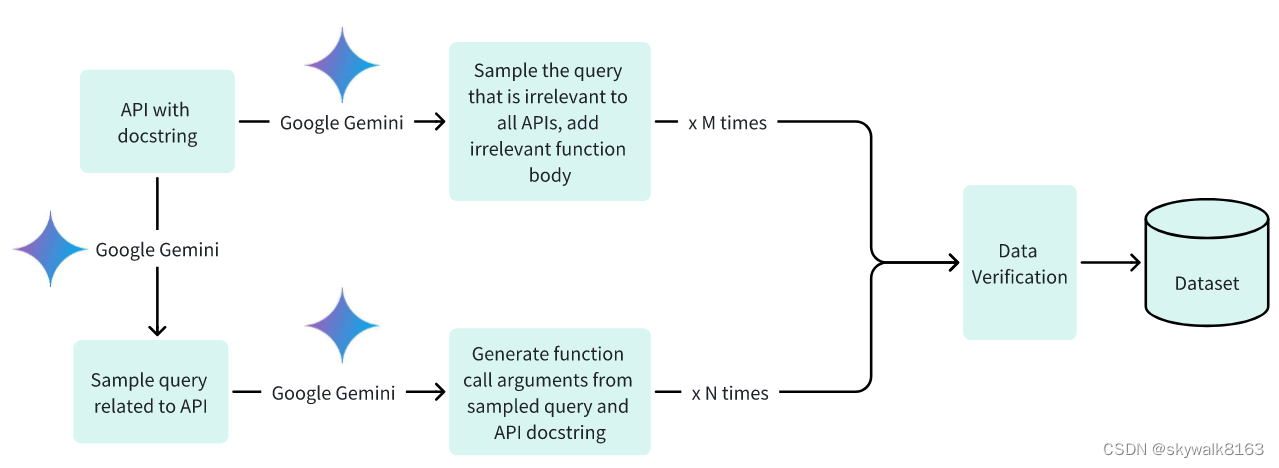
图3
数据集生成过程:这涉及两个关键阶段:(1) 创建特定于某些 API 的可解查询并为其生成适当的函数调用,以及 (2) 创建不可解的查询,并辅以不相关的函数体。结合二进制验证机制进行严格验证,可确保收集优化的训练数据集,从而显著改善模型功能。
数据集验证
尽管 OpenAI 的 GPT-4 和 Google 的 Gemini 等大型语言模型具有先进的功能,但错误率仍然很高,尤其是在函数调用参数的生成方面。这些错误可能表现为缺少参数、不正确的参数类型或对预期查询的误解。为了减轻这些缺点,我们引入了一种核查机制。该系统允许 Google Gemini 评估其生成的函数调用的完整性和准确性,如果发现输出不足,它会启动重新生成过程。
模型开发和训练
我们采用 Google Gemma-2B 模型作为框架中的预训练模型。我们的方法结合了两种不同的训练方法:完整模型训练和 LoRA 模型训练。对于完整的模型训练,我们使用一个 AdamW 优化器,其学习速率设置为 5e-5,预热步骤为 10,以及线性学习速率调度器。相同的优化器和学习率配置应用于 LoRA 训练。我们将 LoRA 等级指定为 16,并将 LoRA 应用于以下模块:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。LoRA alpha 参数设置为 32。对于两种训练方法(完整模型和 LoRA),我们将 epoch 数设置为 3。
实验
我们的研究通过广泛的基准测试方法对语言模型功能进行了全面评估,旨在评估它们在生成准确函数调用方面的有效性。最初,我们将模型的准确性和响应时间与该领域的主要模型进行比较,即 GPT-4(检查点:gpt-4-0125-preview)和 GPT-3.5(检查点:gpt-3.5-turbo-0125)。
Octopus章鱼模型 Android 系统函数
为了说明模型的应用,我们选择了 Android 系统函数调用作为案例研究,重点关注函数调用生成的准确性和延迟。最初,我们选择了 20 个 Android API 作为我们的数据集基础。我们采用了两种不同的方法来生成函数调用命令。有关 API 设计的详细信息,请参阅附录。第一种方法涉及 RAG 方法,用于根据用户查询识别排名靠前的相似函数描述,然后语言模型使用该方法与用户查询一起生成预期的函数调用命令。我们详细介绍了本次评估中采用的各种模型。
现在,我们介绍章鱼模型,每个 API 采样 1000 个数据点。我们在评估数据集中观察到 99.524% 的准确率。此外,用于此方法的提示非常简单:
- "Below is the query from the users, please call the correct function and generate the parameters
- to call the function. Query: {user_query} Response:"
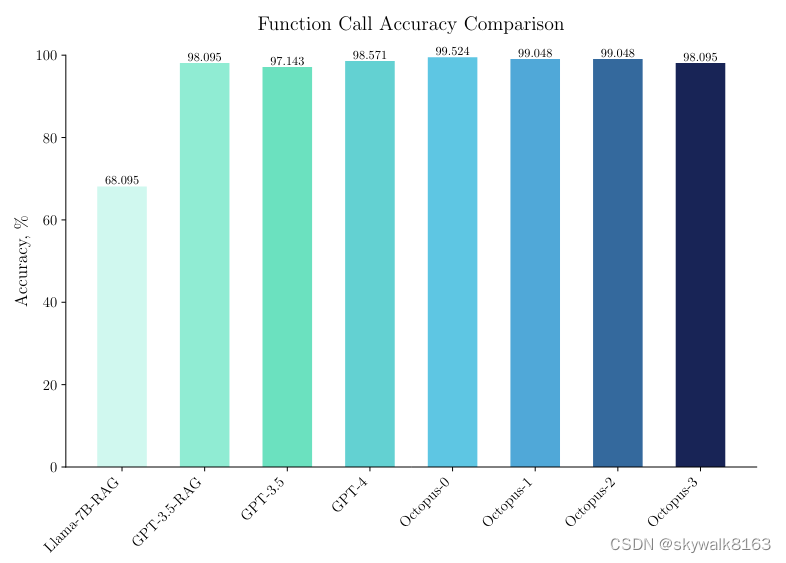
图 5:基准模型的延迟图
此分析包括 Llama-7B with RAG、GPT-3.5 with RAG、GPT-3.5、GPT-4 和 Octopus 系列模型,标记为 Octopus-0、Octopus-1、Octopus-2 和 Octopus-3。Octopus模型之间的区别在于数据集大小和训练方法。最初的 Octopus-0 模型使用完整模型方法进行训练,每个 API 有 1K 个数据点。Octopus-1 虽然每个 API 也利用 1K 个数据点,但使用 LoRA 方法进行训练。Octopus-2 和 Octopus-3 遵循完整的模型训练,但数据点分别减少到 500 和 100。有关这些模型之间的全面差异,请参阅原论文表(1)。
在我们的方法中,将功能信息直接合并到上下文中是不必要的,因为 Octopus 模型已经学会了将功能token映射到相应的功能描述,从而节省了大量用于处理的token。鉴于其紧凑的尺寸和所需上下文的简洁性,Octopus 模型展示了 0.38 秒的延迟减少。为了保持公平的比较,我们坚持使用与Llama7B评估相同的基准设置,例如合并闪光注意力而不使用量化。此外,我们通过量化探索了Octopus 2B模式在移动设备上的部署。通过预计算固定前缀的状态——“下面是用户的查询,请调用正确的函数并生成参数来调用函数。Query:“—我们的设备端模型性能卓越,使用标准 Android 手机在 1.1 到 1.7 秒内完成 20 到 30 个令牌的典型查询的函数调用。
完整和部分训练数据集
Octopus 模型在训练阶段为每个 API 采样了 1,000 个数据点,表现出卓越的性能。但是,对于训练一组新函数,考虑到需要生成训练数据集,成本效益成为一个考虑因素。在我们的分析中,为单个 API 生成 1,000 个数据点会产生 0.0224 美元的成本,这代表了为一个特定功能训练 Octopus-0 模型所需的投资。通过评估八达通-0、八达通-2和八达通-3模型,我们发现,仅对一个API进行100个数据点采样,仍能达到98.095%的准确率,如图(4)所示。因此,对于寻求使用我们的框架训练自己的八达通模型的个人,我们建议数据集大小从 100 到 1,000 个数据点不等。
全面训练和LoRA训练
LoRA 在我们的框架中起着至关重要的作用,尤其是在将 Octopus 模型集成到多个应用程序以确保流畅计算时。我们没有为每个 API 集采用完整的模型,而是选择针对不同应用程序的特定功能设置量身定制的各种 LoRA 培训。如图 (4) 所示, 切换到 Lora 训练会导致准确性略有下降.尽管如此,保持的高精度水平对于生产部署来说已经足够强大了。
并行和嵌套函数调用
对于上面的基准测试,我们指出它们适用于单个函数调用。为了启用并行函数调用和嵌套函数调用,我们需要为每个 API 准备 4K 数据点,以便准确率达到与单个函数调用相同的水平。
特殊token的加权损失函数
我们方法的一个独特方面是将许多特殊标记合并到分词器中,并扩展语言模型的头部。损失函数定义如下:
鉴于 <nexa_0> <nexa_N-1><nexa_end>Gemma-2B 预训练数据集中不存在的特殊标记以及 的不同标记的引入,我们在模型训练过程中面临着不平衡的数据集挑战。为了解决这个问题,我们采用加权交叉熵损失作为替代损失来改善收敛性:
在我们的配置中,非特殊令牌的权重为 1,而特殊令牌的权重则更高。早期训练实验表明,增加代币权重可以加速收敛。基于公式 (3) 的验证损失,具有不同的训练代理损失,如原论文图 (6) 所示。我们的研究结果表明,在训练过程的早期采用替代训练损失有助于收敛。尽管如此,实验显示,微调模型的性能差异不大,挂钟时间也存在显著差异。因此,建议对少量函数令牌使用等权重令牌丢失。在我们的基准测试中,评估的模型由相等的标记权重进行训练。
讨论和未来工作
我们目前的训练计划证明,任何特定功能都可以封装到一个新创造的术语中,即功能token,这是一种无缝集成到分词器和模型中的新型token类型。该模型通过仅两美分的具有成本效益的训练过程,促进了人工智能代理的部署,其特点是具有极低的延迟和高准确性。
我们研究的潜在影响是广泛的。对于应用程序开发人员,包括 DoorDash 和 Yelp 的开发人员,我们的模型为特定于应用程序场景的培训铺平了道路。开发人员可以确定受众最常使用的 API,将这些 API 转换为 Octopus 模型的功能性代币,然后继续部署。这种策略能够完全自动化应用程序工作流程,模拟类似于 Apple Siri 的功能,尽管响应速度和准确性显着提高。
此外,该模型在 PC、智能手机和可穿戴技术操作系统中的应用提供了另一条令人兴奋的途径。软件开发人员可以训练特定于操作系统的小型 LoRA。通过累积多个 LoRA,该模型有助于跨不同系统组件进行高效的函数调用。例如,将该模型整合到 Android 生态系统中将使 Yelp 和 DoorDash 开发人员能够训练不同的 LoRA,从而使该模型也能在移动平台上运行。
展望未来,我们的目标是开发一个专门用于设备推理的模型。我们的雄心壮志是双管齐下的:首先,实现云部署速度的显着提升,在速度指标上远远超过 GPT-4。其次,支持本地部署,为关注隐私或运营成本的用户提供有价值的解决方案。这种双重部署策略不仅将模型的实用性扩展到云和本地环境,而且还满足了用户对速度和效率或隐私和成本节约的偏好。
另一个agent:SWE-agent 处理 GitHub 问题并尝试使用 GPT-4 或您选择的 LM 自动修复它。它解决了 SWE-bench 评估集中 12.29% 的错误,运行时间仅为 1.5 分钟。https://github.com/princeton-nlp/SWE-agent

