- 1[C#] 如何调用Python脚本程序_c#调用python脚本
- 22023年第十四届蓝桥杯省赛JavaB组个人题解(AK)_\。1\.m.?n...? )b9.? b9b;.i bm?bo bbb jj. .. !\。 ?\
- 3fpga如何约束走线_Vivado使用误区与进阶系列(四)XDC约束技巧之I/O篇(上)
- 44、外部中断(STM32)_stm32外部中断程序
- 5查看docker中运行的JVM参数_如何查看pod 的jvm 启动参数
- 6FPGA Verilog UART_通用异步收发器 fpga verilog hdl
- 7代码随想录算法训练营Day59|LeetCode583两个字符串的删除操作、LeetCode72编辑距离
- 8【记录11】前端项目上传至gitee仓库及相关命令_前端项目上传gitee
- 9Git config --global user.email or user.name
- 10十大排序算法详解(java实现)_java排序算法
机器学习之基础知识(全)_机器学习基础
赞
踩
目录
3.2.7 多个坐标系显示-plt.subplots(面向对象的画图方法)
4.1.3 ndarray与Python原生list运算效率对比
1.机器学习概述

1.1 人工智能概述


1.1.1 人工智能使用场景

1.1.2 人工智能小案例

https://quickdraw.withgoogle.com
https://pjreddie.com/darknet/yolo/

https://deepdreamgenerator.com/
1.2 人工智能发展历程



1.2.1 图灵测试


1.2.2 发展历程


1.2.3 小结

1.3 人工智能主要分支
1.3.1 人工智能、机器学习和深度学习
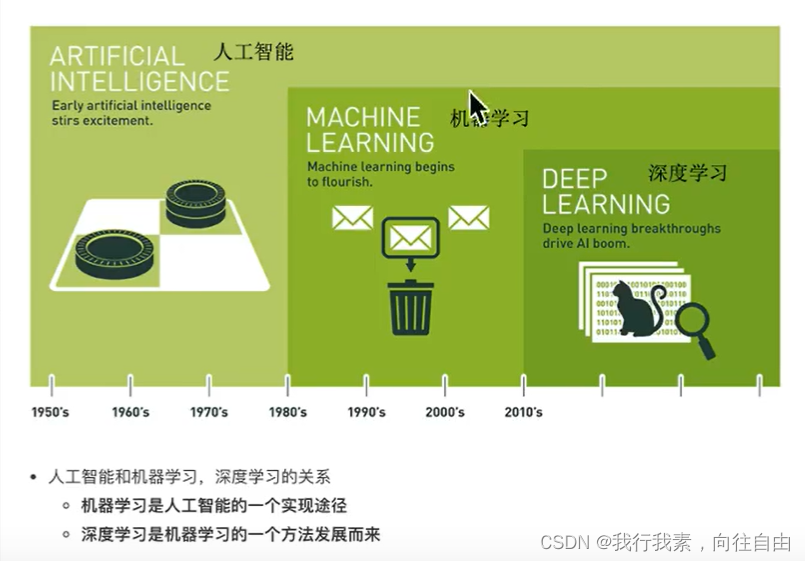
1.3.2 主要分支介绍







1.3.3 人工智能发展必备三要素

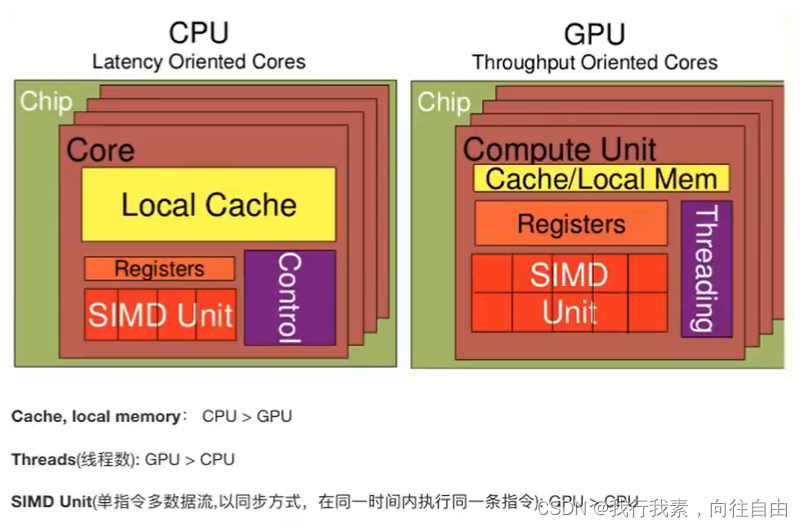
1.3.4 拓展:GPU和CPU对比
CPU擅长IO处理,GPU擅长计算。



1.4 机器学习工作流程


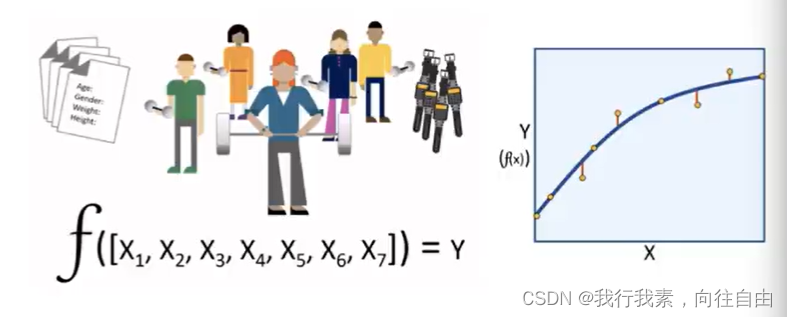
1.4.1 什么是机器学习

1.4.2 机器学习工作流程



1.4.3 获取到的数据集介绍





1.4.4 数据基本处理
即对数进行缺失值、去除异常值等处理。
1.4.5 特征工程
(1)什么是特征工程

(2)为什么需要特征工程(Feature Engineering)

(3) 特征工程包括内容
- 特征提取
- 特征预处理
- 特征降维
特征提取:

特征预处理:

特征降维:

1.4.6 机器学习和模型评估概念
机器学习:选择合适的算法对模型进行训练。
模型评估:对训练好的模型进行评估。
1.5 机器学习算法分类


1.5.1 监督学习
定义: 输入数据是由输入特征值和目标值所组成。
-函数的输出可以每一个连续的值(称为回归);-或是输出是有限个离散值(称作分类)。
(1)回归问题
例如︰预测房价,根据样本集拟合出一条连续曲线。

(2)分类问题
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性"或者“恶性”,是离散的。

1.5.2 无监督学习
定义:输入数据是由输入特征值组成。
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。举例:


1.5.3 半监督学习
定义:即训练集同时包含有标记样本数据和未标记样本数据。
举例:


1.5.4 强化学习
强化学习:实质是,make decisions问题,即自动进行决策,并且可以做连续决策。
强化学习的目标:就是获得最多的累计奖励。
举例:

监督学习与强化学习的对比:

1.5.5 小结

1.6 模型评估

模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
1.6.1 分类模型评估
- 准确率:预测正确的数占样本总数的比例。
- 精确率:正确预测为正占全部预测为正的比例。
- 召回率:正确预测为正占全部正样本的比例。
- F1-score:主要用于评估模型的稳健性。
- AUC指标:主要用于评估样本不均衡的情况。
1.6.2 回归模型评估




1.6.3 拟合
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
在训练过程中,你可能会遇到如下问题:
训练数据训练的很好啊,误差也不大,为什么在测试集上面有问题呢?当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。
(1)欠拟合

(2)过拟合
过拟合((over-fitting)∶所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。
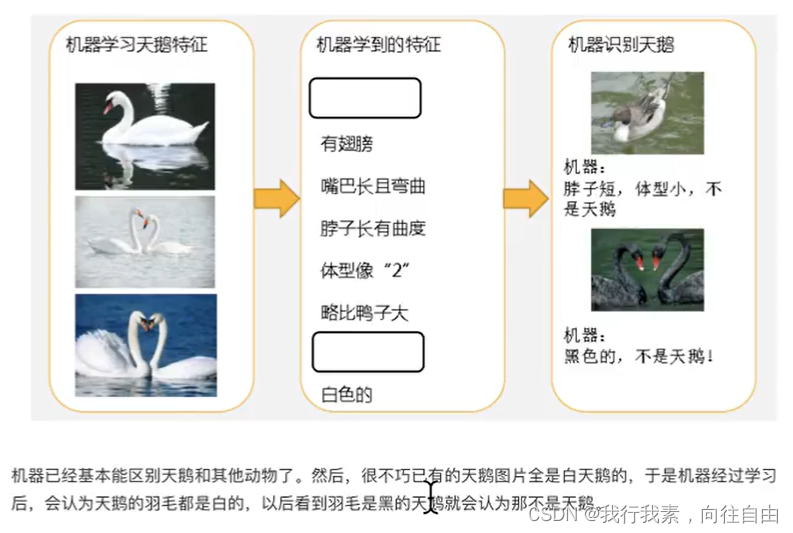
1.7 Azure平台简介

Azure Machine Learning (简称"“AML")是微软在其公有云Azure上推出的基于Web使用的一项机器学习服务,机器学习属人工智能的一个分支,它技术借助算法让电脑对大量流动数据集进行识别。这种方式能够通过历史数据来预测未来事件和行为,其实现方式明显优于传统的离业智能形式。
微软的目标:是简化使用机器学习的过程,以便于开发人员、业务分析师和数据科学家进行广泛、便捷地应用。
这款服务的目的:在于“将机器学习动力与云计算的简单性相结合”。
AML目前在微软的Global Azure云服务平台提供服务,用户可以通过站点: https://studio.azureml.net/申请免费试用。UCI机器学习数据库的网址:http://archive.ics.uci.edu/ml/
1.8 深度学习简介【了解】

1.8.1 深度学习--神经网络简介

深度学习演示链接:http://playground.tensorflow.org
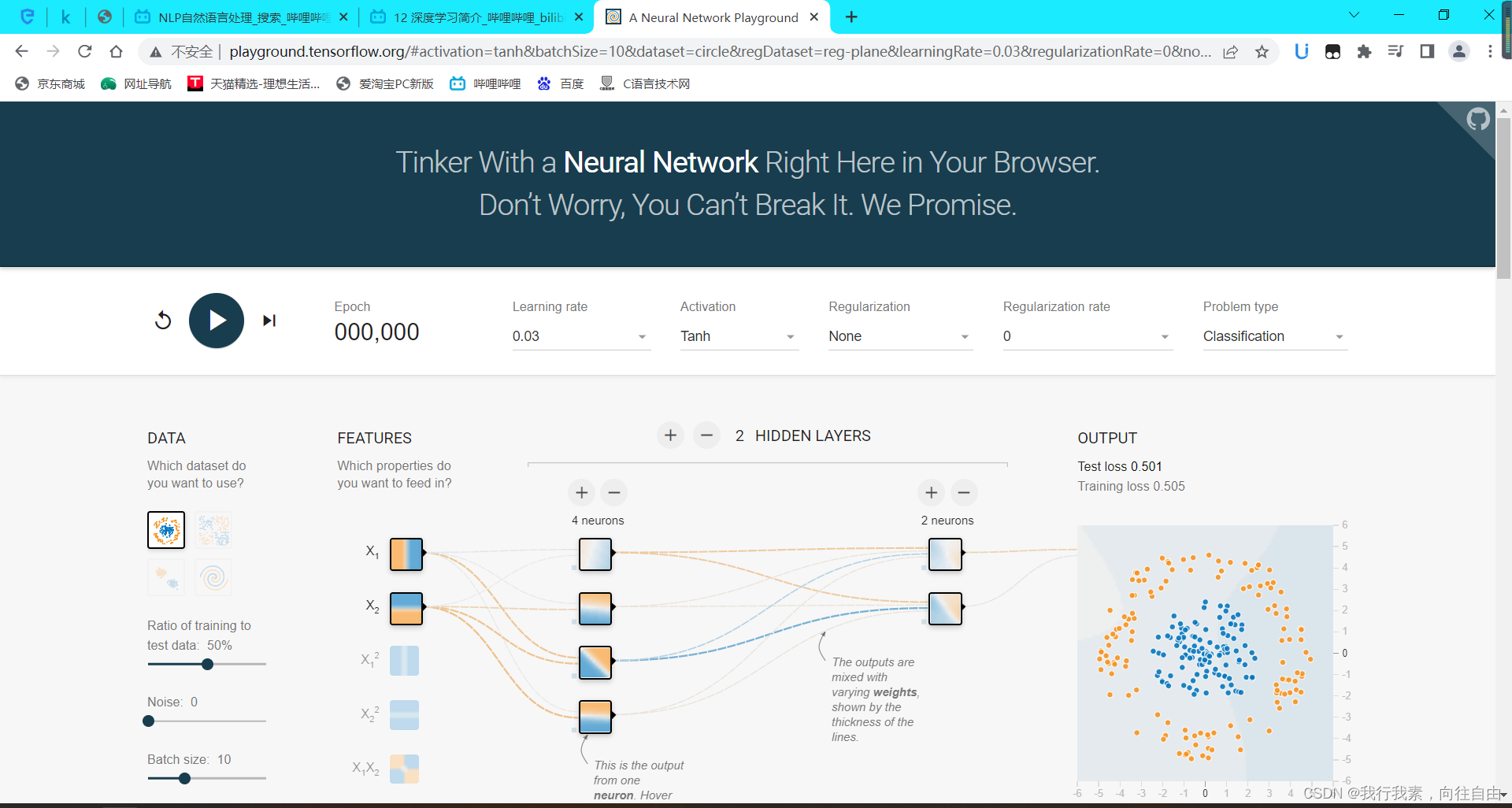
1.8.2 深度学习各层负责的内容





增加层数:通过更抽象的概念识别物体,器官层,分子层,原子层。
增加结点数:增加同一层物质的种类。

2.机器学习基础环境安装与使用


2.1 库的安装
整个机器学习基础阶段会用到Matplotlib、Numpy、Pandas等库
注意:
每个包安装的过程中,尽量指定稳定版本进行安装。
2.2 Jupyter Notebook的使用

2.2.1 Jupyter Notebook介绍

Jupyter项目旨在开发跨几十种编程语言的开源软件,开放标准和用于交互式计算的服务。
2.2.2 为什么使用Jupyter Notebook


总结:Jupyter Notebook相比 Pycharm在画图和数据展示方面更有优势。
2.2.3 简单操作介绍
在cmd中输入jupyter notebook就可以打开。





2.2.4 markdown功能
esc + m

3.Matplotlib详讲

3.1 Matplotlib之HelloWorld
3.1.1 什么是Matplotlib
- 是专门用于开发2D图表(包括3D图表)
- 使用起来及其简单
- 以渐进、交互式方式实现数据可视化
3.1.2 为什么要学 Matplotlib
可视化是在整个数据挖掘的关键辅助工具,可以清晰的理解数据,从而调整我们的分析方法。
- 能将数据进行可视化,更直观的呈现
- 使数据更加客观、更具说服力
例如下面两个图为数字展示和图形展示:

3.1.3 实现一个简单的Matplotlib画图
- import matplotlib.pyplot as plt
-
-
- # 1.创建画布
- plt.figure(figsize=(20,8),dpi=100)
-
- #2.绘制图像
- x=[1,2,3]
- y=[4,5,6]
- plt.plot(x,y)
-
- #3.显示图像
- plt.show()
运行结果:
3.1.4 认识Matplotlib图像结构(拓展,了解)

3.1.5 Matplotlib三层结构(拓展,了解)
(1)容器层
容器层主要由Canvas、Figure、Axes组成。
Canvas是位于最底层的系统层,在绘图的过程中充当画板的角色,即放置画布(Figure)的工具。
Figure是Canvas上方的第一层,也是需要用户来操作的应用层的第一层,在绘图的过程中充当画布的角色。
Axes是应用层的第二层,在绘图的过程中相当于画布上的绘图区的角色。
- Figure:指整个图形(可以通过plt.figure()设置画布的大小和分辨率等)
- Axes(坐标系):数据的绘图区域
- Axis(坐标轴):坐标系中的一条轴,包含大小限制、刻度和刻度标签
特点为∶
- 一个figure(图像)可以包含多个axes(坐标系/绘图区),但是一个axes只能属于一个figure。
- 一个axes(坐标系/绘图区)可以包含多个axis(坐标轴),包含两个即为2d坐标系,3个即为3d坐标系。

(2)辅助显示层
辅助显示层为Axes(绘图区)内的除了根据数据绘制出的图像以外的内容,主要包括Axes外观(facecolor)、边框线(spines)、坐标轴(axis)、坐标轴名称(axis label)、坐标轴刻度(tick)、坐标轴刻度标签(tick label)、网格线(grid)、图例(legend)、标题(title)等内容。
该层的设置可使图像显示更加直观更加容易被用户理解,但又不会对图像产生实质的影响。
(3)图像层
图像层指Axes内通过plot、scatter、bar、histogram、pie等函数根据数据绘制出的图像。
总结:
- Canvas(画板)位于最底层,用户一般接触不到
- Figure (画布)建立在Canvas之上
- Axes(绘图区)建立在Figure之上
- 坐标轴(axis)、图例(legend)等辅助显示层以及图像层都是建立在Axes之上
3.2 折线图(plot)与基础绘图功能


3.2.1 折线图绘制与保存图片
为了更好地理解所有基础绘图功能,我们通过天气温度变化的绘图来融合所有的基础API使用。
(1)matplotlib.pyplot模块
matplotlib.pytplot包含了一系列类似于matlab的画图函数。它的函数作用于当前图形(figure)的当前坐标系。
import matplotlib.pyplot as plt
(2)折线图绘制与显示
展现上海一周的天气,比如从星期一到星期日的天气温度如下:
- import matplotlib.pyplot as plt
- #1.创建画布
- plt.figure(figsize=(10,10))
- #2.绘制折线图(图像层)
- plt.plot([1,2,3,4,5,6,7],[17,17,18,15,11,11,13])
- #3.显示图像
- plt.show()
运行结果:

(3)设置画布属性与图片保存
plt.figure(figsize=(),dpi=)
figsize:指定图的长度
dpi:图像的清晰度
plt.savefig(path)
注意:plt.show()会释放figure资源,如果在显示图像之后保存图片将只能保存空图片。所以,图像保存一定要放到show前面。
3.2.2 完善原始折线图1(辅助显示层)
案例:显示温度变化状况。
需求:画出某城市11点到12点1小时内每分钟的温度变化折线图,温度范围在15度~18度。
- #画出温度变化图
- import random
- import matplotlib.pyplot as plt
-
- #0.准备x、y坐标的数据
- x=range(60)
- y_shanghai=[random.uniform(10,15) for i in x]
-
- #1.创建画布
- plt.figure(figsize=(20,8),dpi=200)
-
- #2.绘制折线图
- plt.plot(x,y_shanghai)
- #2.1 添加x、y轴刻度
- y_ticks=range(40)
- plt.yticks(y_ticks[::5])
- x_ticks_label=['11点{}分'.format(i) for i in x]
- plt.xticks(x[::5],x_ticks_label[::5])
- #plt.xticks(x_ticks_label[::5])#报错 ==> 必须最开始传递进去的是数字
-
-
- #3.显示图像
- plt.show()

运行结果:
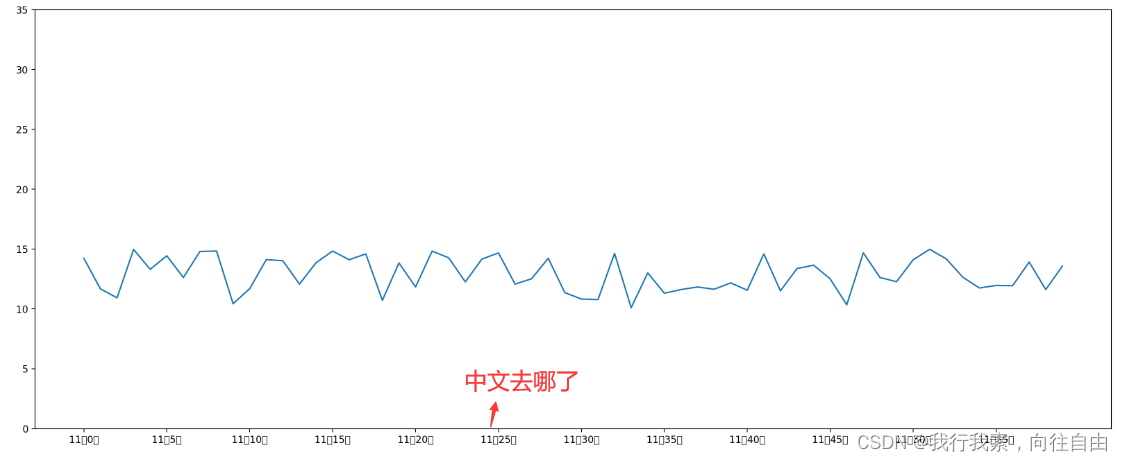
中文显示问题的解决:

SimHei字体下载路径:https://us-logger1.oss-cn-beijing.aliyuncs.com/SimHei.ttf
3.2.3 添加网格显示
为了更加清楚地观察图形对应的值:plt.grid(True,linestyle='--',alpha= 0.5)
参数:
linestyle --绘制网格的方式alpha --透明度
3.2.4 添加描述信息
添加x轴、y轴描述信息及标题。
plt.xlabel('时间',fontsize=20)
plt.ylabel('温度',fontsize=20)
plt.title('xxxxx',fontsize=20)
3.2.5 多次plot
需求:添加一个城市的温度变化。
收集到北京当天温度变化情况,温度在1度到3度。怎么去添加另一个在同一坐标系当中的不同图形,其实很简单只需要再次plot即可,但是需要区分线条,如下:
- y_beijing=[random.uniform(1,3) for i in x]
- plt.plot(x,y_beijing,color='b',linestyle='-.',label='北京')
- #显示图例
- plt.legend(loc='best')
3.2.6 设置图形风格
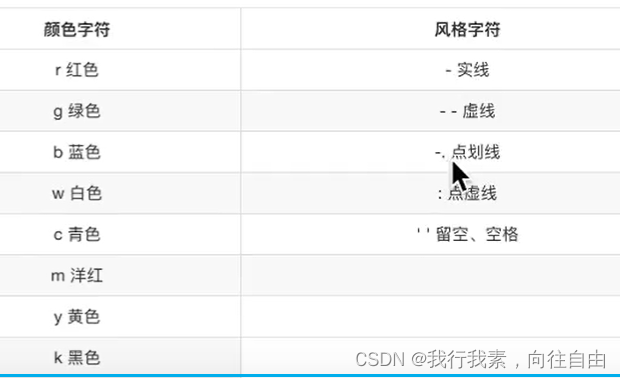
显示图例:plt.legend(loc='best')
注意:如果只在plt.plot()中设置label还不能最终显示出图例,还需要通过plt.legend()将图例显示出来。

3.2.7 多个坐标系显示-plt.subplots(面向对象的画图方法)
matplotlib.pyplot.subplots(nrows=1, ncols=1,**fig_kw)创建一个带有多个axes(坐标系/绘图区)的图。

注意:plt.函数名()相当于面向过程的画图方法,axes.set_方法名()相当于面向对象的画图方法。
- #画出温度变化图
- import random
- import matplotlib.pyplot as plt
-
- #0.准备x、y坐标的数据
- x=range(60)
- y_shanghai=[random.uniform(15,18) for i in x]
- y_beijing=[random.uniform(1,14) for i in x]
-
- #1.创建画布
- fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(20,8),dpi=100)
-
- #2.绘制折线图
- axes[0].plot(x,y_shanghai,color='r',linestyle='--',label='上海')
- axes[1].plot(x,y_beijing,color='g',linestyle='-.',label='北京')
-
- #2.1 添加x、y轴刻度
- x_ticks_label=['11点{}分'.format(i) for i in x]
- y_ticks=range(40)
- axes[0].set_xticks(x[::5])
- axes[0].set_yticks(y_ticks[::5])
- axes[0].set_xticklabels(x_ticks_label[::5])
- axes[1].set_xticks(x[::5])
- axes[1].set_yticks(y_ticks[::5])
- axes[1].set_xticklabels(x_ticks_label[::5])
-
- #2.2 添加网格
- axes[0].grid(True,linestyle='--',alpha=1)
- axes[1].grid(True,linestyle='--',alpha=1)
-
-
- #2.3 添加描述
- axes[0].set_xlabel('时间',fontsize=25)
- axes[0].set_ylabel('温度',fontsize=25)
- axes[0].set_title('上海',fontsize=25)
- axes[1].set_xlabel('时间',fontsize=25)
- axes[1].set_ylabel('温度',fontsize=25)
- axes[1].set_title('北京',fontsize=25)
-
-
- #2.4显示图例
- axes[0].legend(loc='best')
- axes[1].legend(loc='best')
-
- #3.显示图像
- plt.show()
运行效果: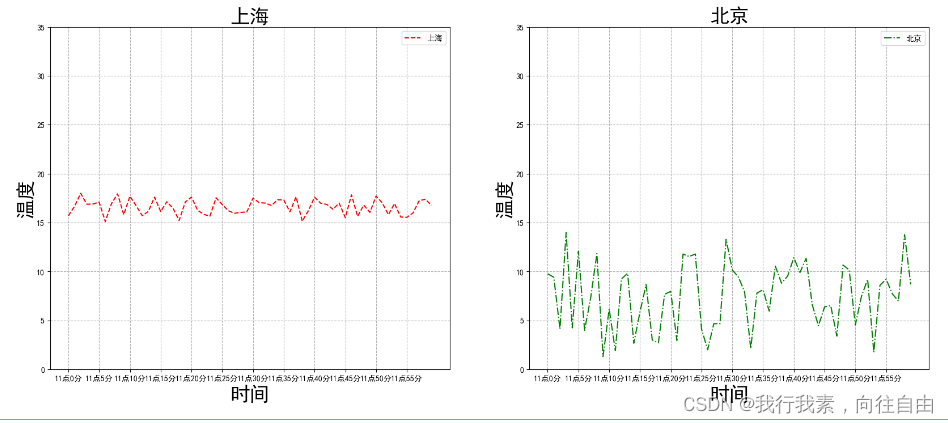
3.2.8 折线图应用场景
- 呈现公司产品(不同区域)每天活跃用户数
- 呈现app每天下载数量
- 呈现产品新功能上线后,用户点击次数随时间的变化
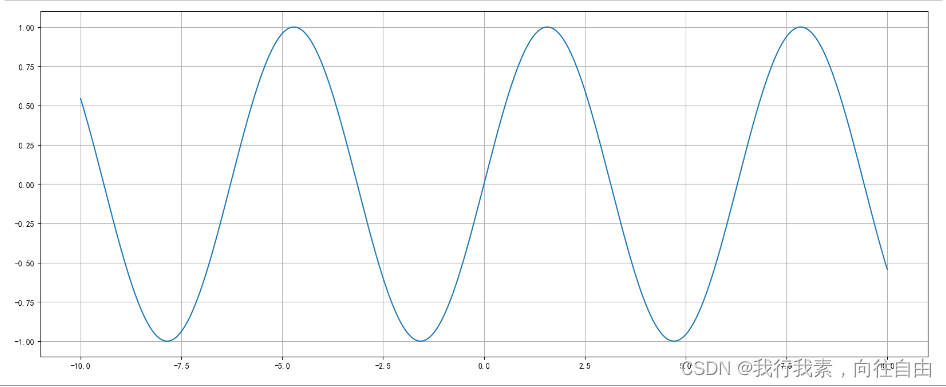
- 拓展:画各种数学函数图像
注意:plt.plot()除了可以画折线图,也可以用于画各种数学函数图像。
- import random
- import matplotlib as mpl
- import matplotlib.pyplot as plt
- import numpy as np
- mpl.rcParams['axes.unicode_minus']=False #解决负号显示问题
-
- #0.准备数据
- x=np.linspace(-10,10,1000)#[-10,10]1000个数据
- y=np.sin(x)
-
- #1.创建画布
- plt.figure(figsize=(20,8),dpi=100)
-
- #2.绘制函数图像
- plt.plot(x,y)
- #2.1显示网格
- plt.grid()
-
- #3.显示图像
- plt.show()
运行结果:
3.3 常见图形绘制


https://matplotlib.org/index.html
3.3.1 常见图形种类及意义
Matplotlib能够绘制折线图、散点图、柱状图、直方图、饼图。
我们需要知道不同的统计图的意义,以此来决定选择哪种统计图来呈现我们的数据。
(1)折线图
折线图:以折线的上升或下降来表示统计数量的增减变化的统计图。
特点:能够显示数据的变化趋势,反映事物的变化情况。(变化)
api:plt.plot(x, y)
(2)散点图
散点图:用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)。api:plt.scatter(x, y)
(3)柱状图
柱状图:排列在工作表的列或行中的数据可以绘制到柱状图中。
特点:绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
api:plt.bar(x, width, align='center' , **kwargs)

(4)直方图
直方图:由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据范围,纵轴表示分布情况。
特点:绘制连续性的数据展示一组或者多组数据的分布状况(统计)
api:matplotlib.pyplot.hist(x, bins=None)

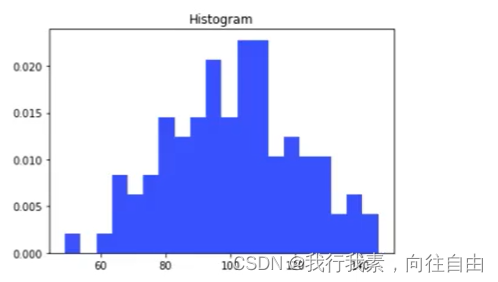
(5)饼图
饼图:用于表示不同分类的占比情况,通过弧度大小来对比各种分类。
特点:分类数据的占比情况(占比)
api:plt.pie(x, labels=,autopct=,colors)


3.3.2 散点图绘制
需求:探究房屋面积和房屋价格的关系。
- import matplotlib.pyplot as plt
-
- #房屋面积数据
- x=[225.98,247.07,253.14,457.85,241.58,301.01,20.67,288.64,163.56,120.06,207.83,342.75,147.9,53.06,224.72,29.51,21.61,483.21,245.25,399.25,343.35]
- #房屋价格数据
- y=[196.63,203.88,210.75,372.74,202.41,247.61,24.9,239.34,140.32,104.15,176.84,288.23,128.79,49.64,191.74,33.1,30.74,400.02,205.35,330.64,283.45]
-
- plt.figure(figsize=(20,8),dpi=100)
- plt.scatter(x,y)
- plt.show()
结果:
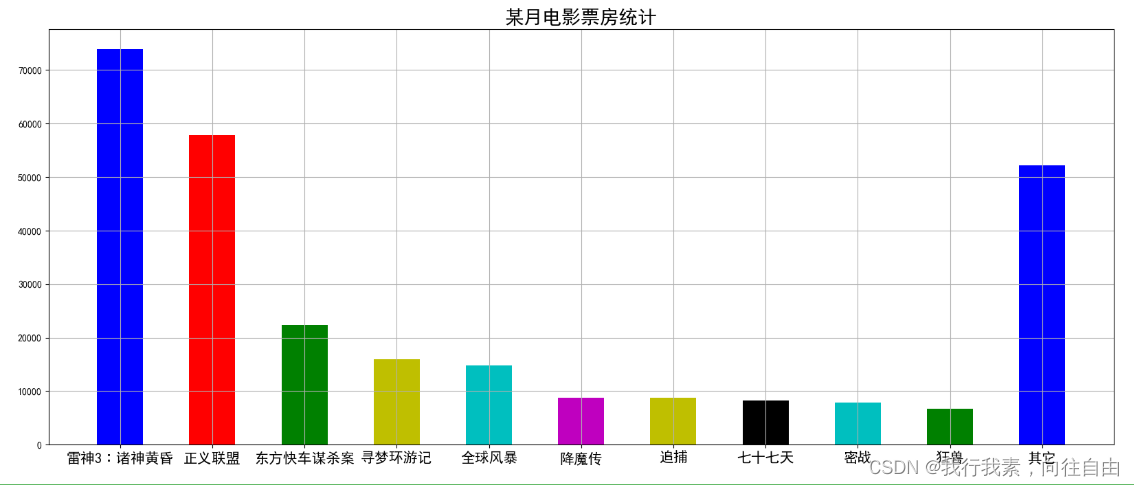
3.3.3 柱状图绘制
- movie_name=['雷神3∶诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','降魔传','追捕','七十七天','密战','狂兽','其它']
- x=range(len(movie_name))
- y=[73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222]
- plt.figure(figsize=(20,8),dpi=100)
- plt.bar(x,y,width=0.5,color=['b','r','g','y','c','m','y','k','c','g','b'])
- plt.xticks(x,movie_name,fontsize=15)
- plt.grid()
- plt.title('某月电影票房统计',fontsize=20)
- plt.show()
结果:
4.numpy

4.1 numpy的优势


4.1.1 numpy介绍
- Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组
- Numpy支持常见的数组和距阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
- Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
4.1.2 ndarray介绍
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。

4.1.3 ndarray与Python原生list运算效率对比
使用Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组,那么为什么还需要使用Numpy的ndarray呢?
在这里我们通过一段代码运行来体会到ndarray的好处:
- import random,time
- import numpy as np
- a=[]
- for i in range(10000):
- a.append(random.random())
- %time sum1=sum(a)
-
- b=np.array(a)
- %time sum2=np.sum(b)

从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。
4.1.4 narray的优势
(1)内存块风格
ndarray到底跟原生python列表有什么不同呢,请看一张图:
从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。

(2)ndarray支持并行化运算(向量化运算)
(3)效率远高于纯Python代码
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,所以,其效率远高于纯Python代码。
4.2 N维数组-ndarray

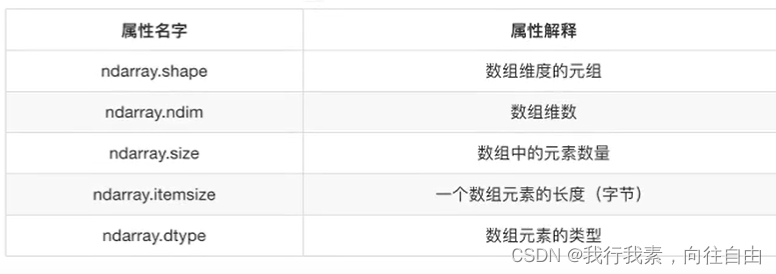
4.2.1 ndarray的属性
数组属性反映了数组本身固有的信息。
4.2.2 ndarray的形状

4.2.3 ndarray的类型
dtype是numpy.dtype类型,先看看对于数组来说都有哪些类型:
注意:若不指定,整数默认int64,小数默认float64。



4.3 基本操作


4.3.1 生成数组的方法
(1)生成0和1的数组


(2)从现有数组生成
生成方式:array为深拷贝,互不影响;asarray是浅拷贝,指向同一空间区域。



(3)生成固定范围的数组
- 生成等间隔的序列:np.linspace (start, stop, num, endpoint)
- 其它的还有:
numpy.arange(start,stop, step, dtype)
numpy.logspace(start,stop, num)




(4)生成随机数组
使用模块:np.random
均匀分布:
- np.random.rand(d0, d1, ... , dn)返回[0.0,1.0)内的一组均匀分布的数。
- np.random.uniform(low=0.0, high=1.0, size=None)
运行结果:
- np.random.randint(low , high=None, size=None, dtype='I')
从一个均匀分布中随机采样,生成一个整数或N维整数数组,取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。



正态分布:
- np.random.randn(d0, d1, ...,dn)
功能:从标准态分布中返回一个或多个样本值。
- np.random.normal(loc=0.0, scale=1.0, size=None)
- np.random.standard_normal(size=None)
返回指定形状的标准正态分布的数组。


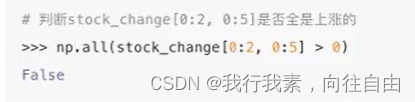
案例:随机生成8只股票2周的交易日涨幅数据。

stock_change = np.random.normal(0, 1,(8,10))
4.3.2 数组的索引、切片

一维、二维、三维的数组如何索引?

4.3.3 形状修改
- ndarray.reshape(shape[, order])
返回一个新结果,原来结果不变。
- ndarray.resize(new_shape[, refcheck])
修改原数组。- ndarray.T数组的转置
将数组的行、列进行互换。

4.3.4 类型修改
- ndarray.astype(type)
- ndarray.tostring([order])或者ndarray.tobytes([order])

4.3.5 数组的去重
- ndarray.unique

4.4 ndarray运算

4.4.1 逻辑运算

4.4.2 通用判断函数
- np.arr()
- np.any()

4.4.3 np.where (三元运算符)
通过使用np.where能够进行更加复杂的运算。
- np.where()
- 复合逻辑需要结合np.logical_and和np.logical_or使用


4.4.4 统计运算
在数据挖掘/机器学习领域,统计指标的值也是我们分析问题的一种方式。
常用的指标如下:
- min(a[, axis, out, keepdims])
- max(a[, axis, out, keepdims])
- median(a[, axis, out, overwrite_input,keepdims]) 中位数
- mean(a, axis, dtype, out, keepdims]) 平均值
- std(a[, axis, dtype, out, ddof, keepdims]) 标准差
- var(a[, axis, dtype, out, ddof, keepdims]) 方差
- np.argmax(a,axis=) 最大值下标
- np.argmin(a,axis=) 最小值下标
进行统计的时候,axis 轴的取值并不一定,Numpy中不同的API轴的值都不一样,在这里,axis=0代表列,axis=1代表行去进行统计。
4.5 数学:矩阵

4.5.1 矩阵和向量
(1)矩阵
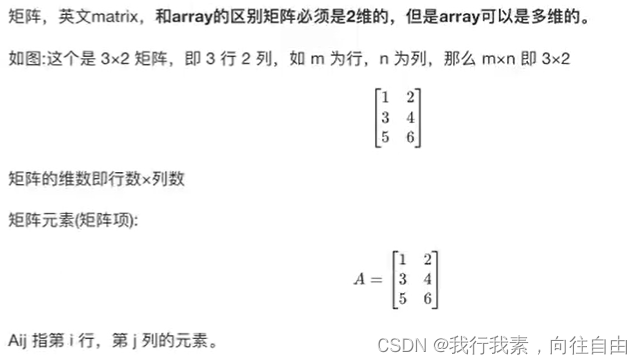
(2)向量

4.5.2 加法和标量乘法

4.5.3 矩阵向量乘法

4.5.4 矩阵乘法

4.5.5 矩阵乘法的性质

4.5.6 逆、转置

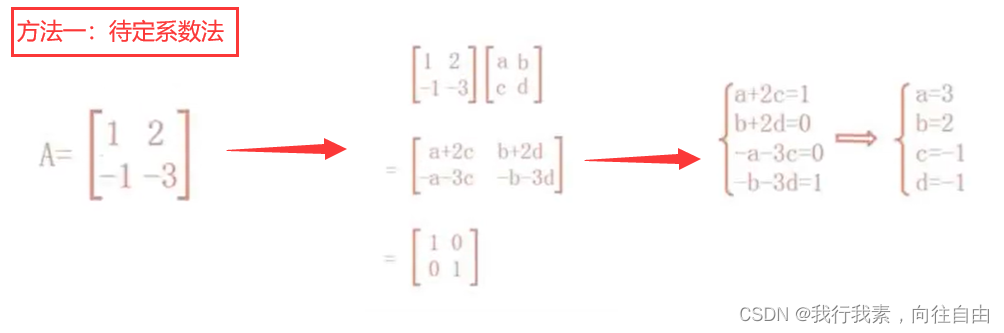


4.6 数组间运算

4.6.1 数组和数的运算

4.6.2 数组与数组的运算:广播机制
执行broadcast的前提在于,两个ndarray执行的是element-wise的运算,Broadcast机制的功能是为了方便不同形状的ndarray (numpy库的核心数据结构)进行数学运算。
当操作两个数组时,numpy会逐个比较它们的shape (构成的元组tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算。
- 维度相等
- shape(其中相对应的一个地方为1)



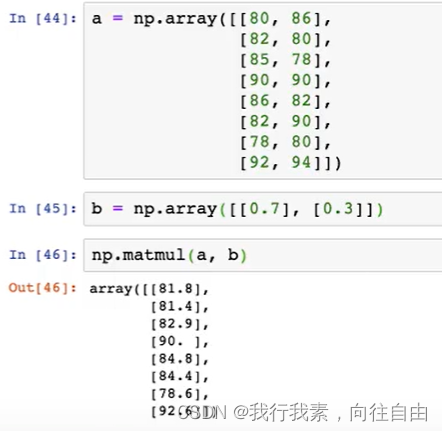
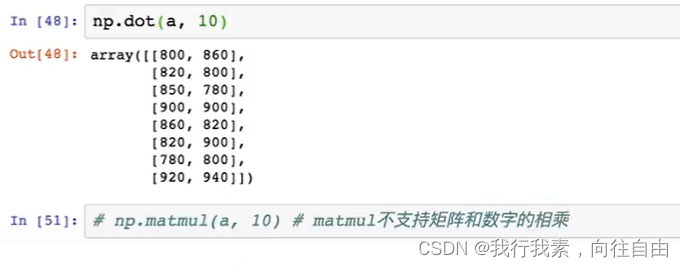
4.6.3 矩阵乘法api
- np.matmul 矩阵乘法
- np.dot 点乘
- 注意:两者之间在进行矩阵相乘时候,没有区别;但是,dot支持矩阵和数字相乘。

5.Pandas

5.1 Pandas介绍

5.1.1 Pandas介绍

- 2008年WesMcKinney开发出的库
- 专门用于数据挖掘的开源python库
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
5.1.2 为什么使用Pandas
Numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢?
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
5.1.3 案例
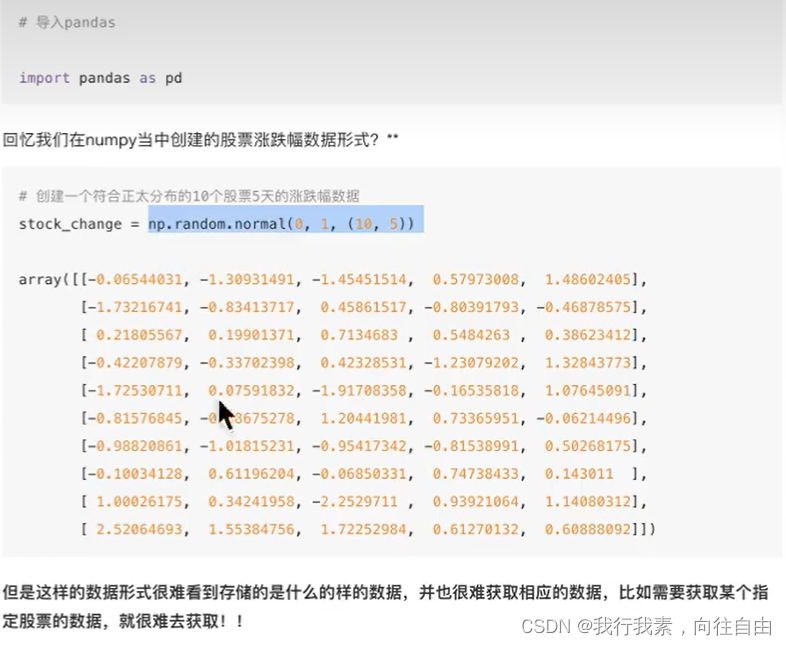



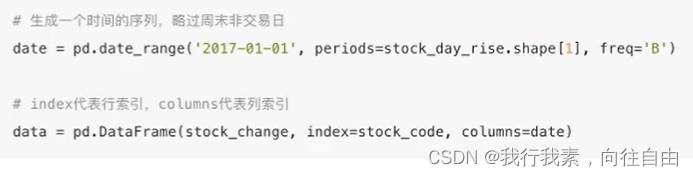
5.1.4 DataFrame
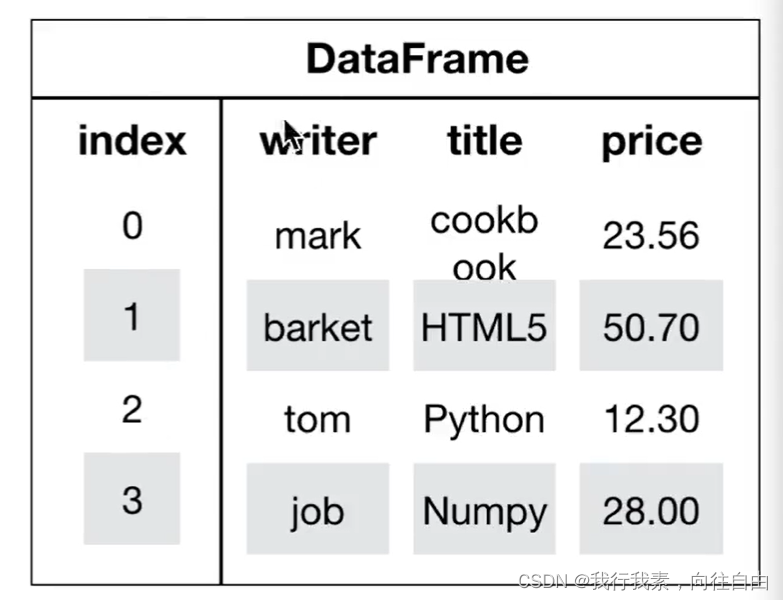
(1)DataFrame结构
DataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
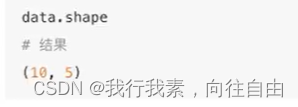
(2)DataFrame属性
- 对象.shape
- 对象.index DataFrame的行索引列表
- 对象.columns DataFrame的列索引列表
- 对象.values 直接获取其中array的值
- 对象.T 转置
- 对象.head(5) 显示前5行的内容
如果不补充参数,默认5行。填入参数N则显示前N行- 对象.tail(5) 显示后5行的内容
如果不补充参数,默认5行。填入参数N则显示后N行


(3)DataFrame索引的设置
1.修改行列索引值:
注意:以下修改方式是错误的
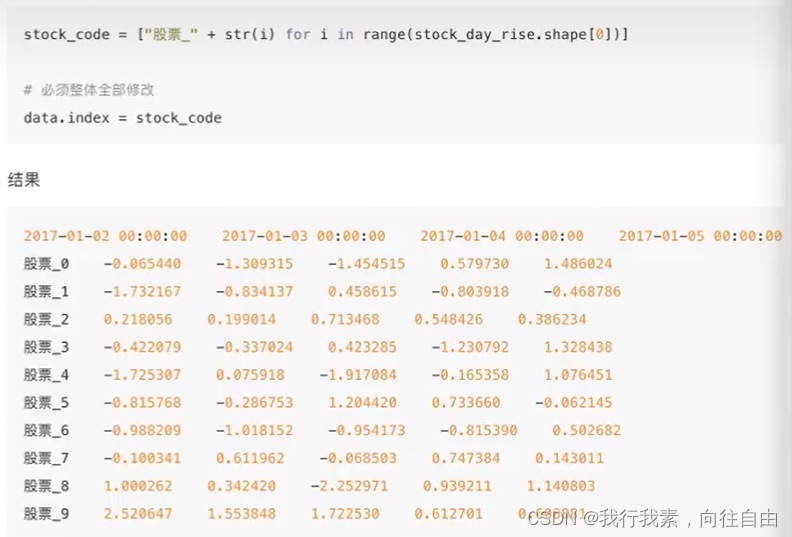

2.重设索引:
- reset_index(drop=False)
-设置新的下标索引。
-drop:默认为False,不删除原来索引,如果为True,删除原来的索引值。- set_index(keys, drop=True)
-keys:列索引名成或者列索引名称的列表。
-drop:boolean, default True。当做新的索引,删除原来的列。
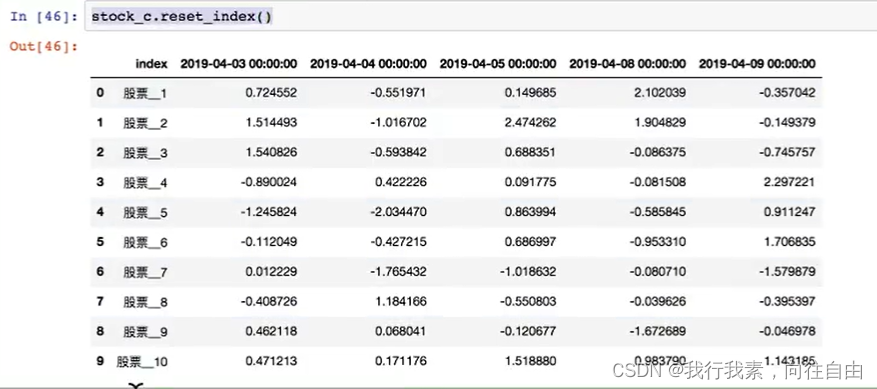

3.设置新索引案例:
- 创建
- 以月份设置新的索引
- 设置多个索引,以年和月份 ==> 其实这就变成三维数组了
注:通过刚才的设置,这样DataFrame就变成了一个具有Multilndex的DataFrame。



5.2 基本数据操作

为了更好的理解这些基本操作,我们将读取一个真实的股票数据。关于文件操作,后面在介绍,这里只先用一下API。

5.2.1 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
(1)直接使用行列索引(先列后行)

(2)结合loc或者iloc使用索引
(3)使用ix组合索引

5.2.2 赋值操作

5.2.3 排序

排序有两种形式,一种对于索引进行排序,一种对于内容进行排序
- 使用df.sort_values(by=, ascending=)
-单个键或者多个键进行排序,默认升序
-ascending=False:降序
-ascending=True:升序
-注意:by这个参数可以接受多个值,优先按照第一个索引排序,如果相同,按照后面的- 使用df.sort_index给索引进行排序
这个股票的日期索引原来是从大到小,现在重新排序,从小到大:- 使用series.sort_values(ascending=True)进行排序
series排序时,只有一列,不需要参数:- 使用series.sort_index()进行排序 与df一样




5.3 DataFrame运算


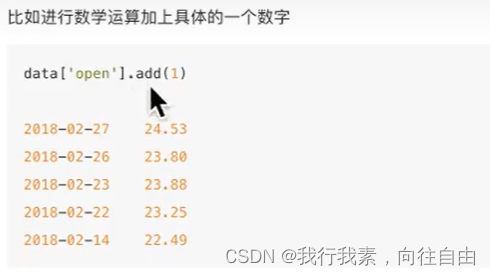
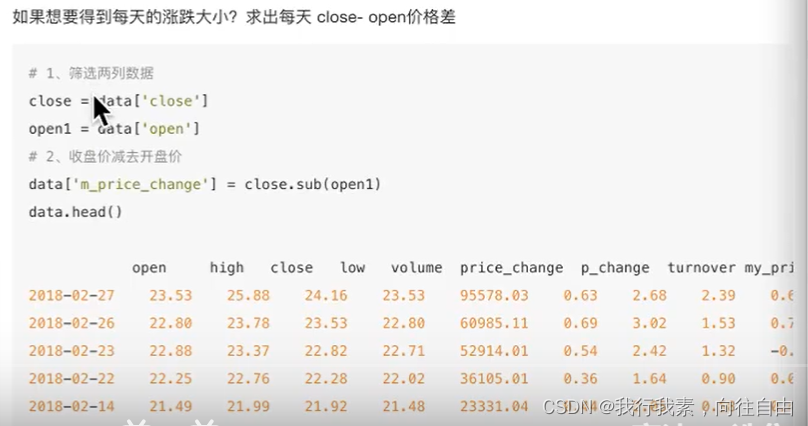
5.3.1 算术运算
直接使用方法add,sub...也可以用符号+-...
- add(other)
- sub(other)
5.3.2 逻辑运算
(1)逻辑运算符号<、>、|、&
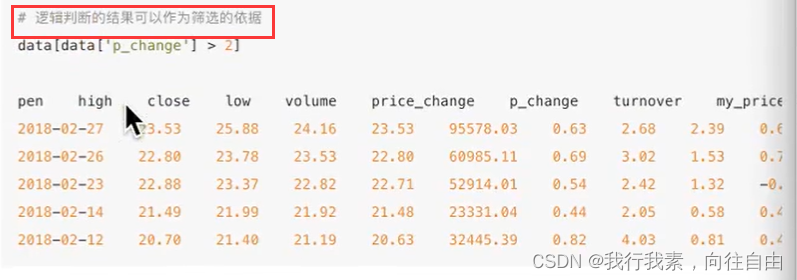
- 例如筛选p_change > 2的日期数据
- 完成一个多个逻辑判断,筛选p_change > 2并且open > 15


(2)逻辑运算函数
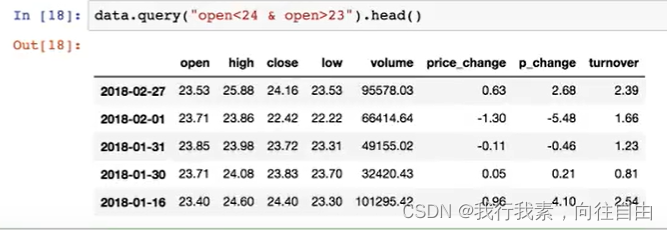
- query(expr)
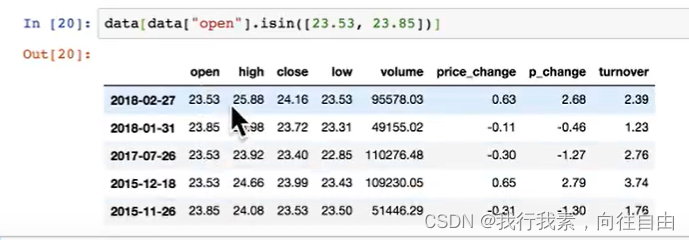
-expr:查询字符串- isin(values)
5.3.3 统计运算
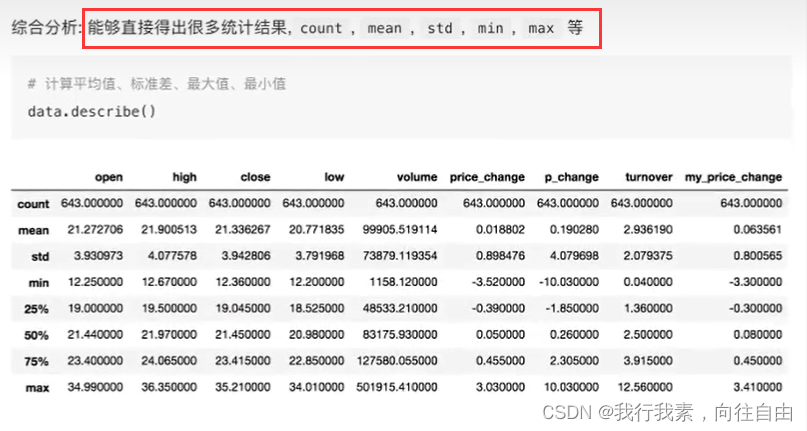
(1)describe()
(2)统计函数
Numpy当中已经详细介绍,在这里我们演示min(最小值), max(最大值), mean(平均值), median(中位数),var(方差), std(标准差),mode(众数)结果:
对于单个函数去进行统计的时候,坐标轴还是按照这些默认为“columns"(axis=0, default),如果要对行"index”需要指定(axis=1)。
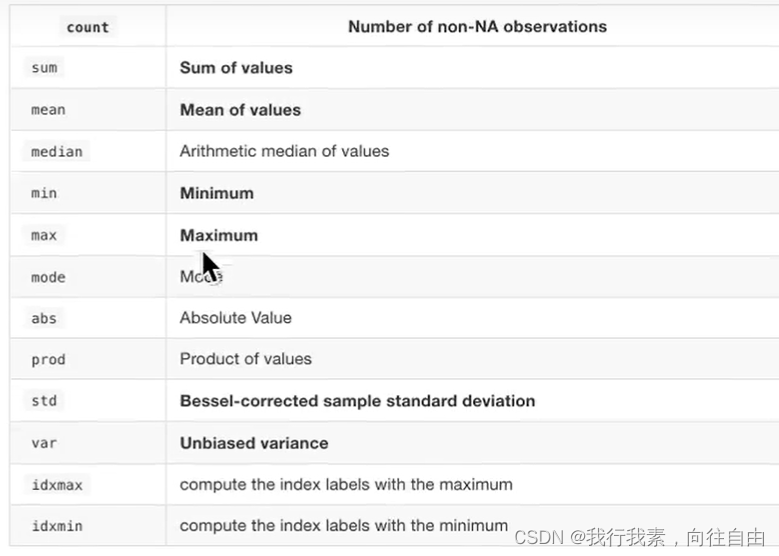
- max()、min()
- std()、var()

- median()
- idxmax()、idxmin() 获取最大/小值的下标





5.3.4 累计统计函数

以上这些函数可以对series和dataframe操作。
5.3.5 自定义函数
- apply(func, axis=0)
func:自定义函数
axis=0:默认是列,axis=1为行进行运算举例:定义一个对列,最大值-最小值的函数

5.4 Pandas画图

pandas.DataFrame.plot

5.5 文件读取与存储

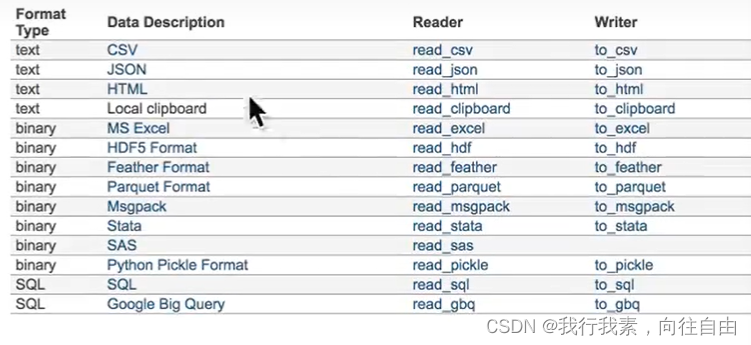
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
注:最常用的HDF5和CSV文件。
5.5.1 CSV
(1)read_csv
pandas.read_csv(filepath_or_buffer,sep =',' )
- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式

(2)to_csv

5.5.2 HDF5
(1)read_hdf和to_hdf


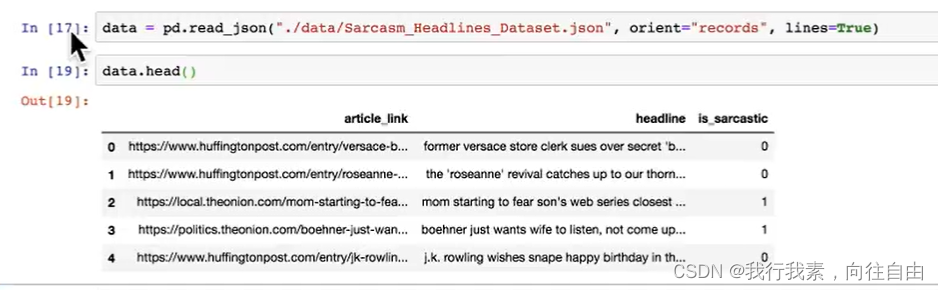
5.5.3 JSON
JSON是我们常用的一种数据交换格式,前面在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
(1)read_json

(2)to_json

5.5.4 拓展
优先选择使用HDF5文件存储:
- HDF5在存储的时候支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面
5.6 高级处理-缺失值处理

5.6.1 如何处理nan

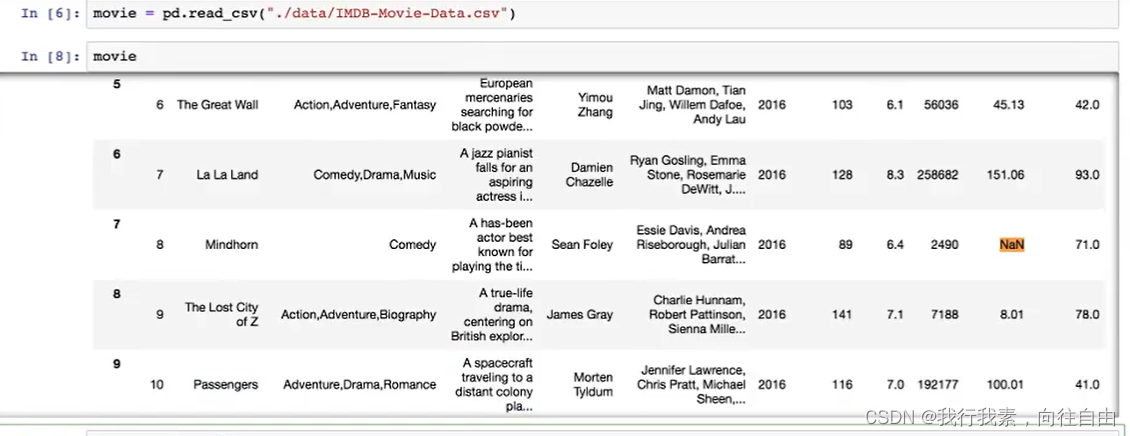




5.6.2 不是缺失值nan,有默认标记的
数据是这样的:

处理思路分析:
- 1.先替换‘?'为np.nan
df.replace(to_replace=, value=)
-to_replace:替换前的值
-value:替换后的值- 2.在进行缺失值的处理
5.7 高级处理-数据离散化


5.7.1 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
5.7.2 什么是数据离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
离散化有很多种方法,这使用一种最简单的方式去操作:
- 原始人的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:150~165,165~180,180~195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个"哑变量"矩阵:

5.7.3 数据分组操作
使用的工具:
- pd.qcut(data, bins):
对数据进行分组将数据分组一般会与value_counts搭配使用,统计每组的个数- series.value_counts():统计分组次数

自定义区间分组:
- pd.cut(data, bins)



5.7.4 分组数据变成one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码。
别名:哑变量,热独编码
把下图中左边的表格转化为使用右边形式进行表示:

pandas.get_dummies(data, prefix=None)
- data:array-like, Series, or DataFrame
- prefix:分组名字

5.8 高级处理-数据合并

如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析。

5.8.1 pd.concat实现数据合并
pd.concat([data1, data2], axis=1)
-按照行或列进行合并,axis=0为列索引,axis=1为行索引
比如我们将刚才处理好的one-hot编码与原数据合并:


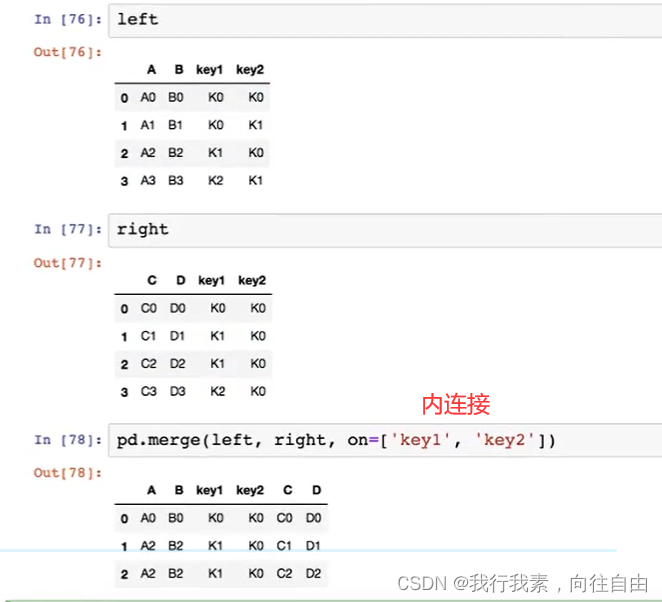
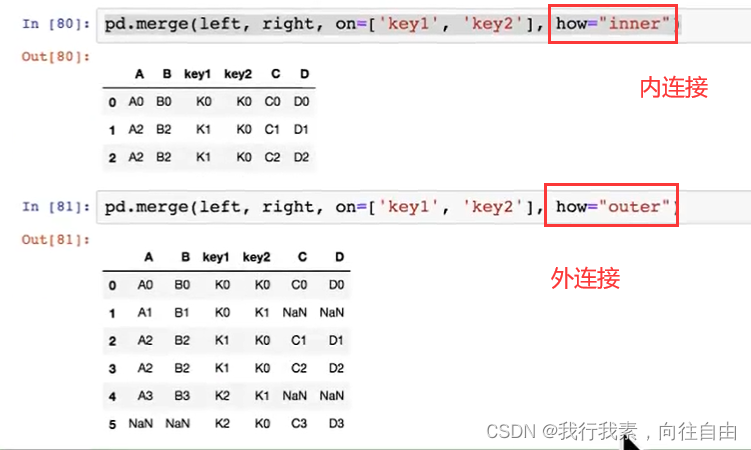
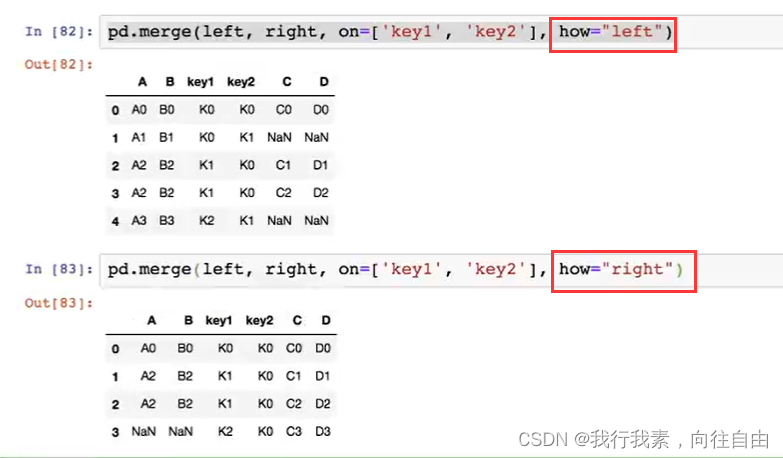
5.8.2 pd.merge实现数据合并
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
- left:A DataFrame object
- right:Another DataFrame object
- on:Columns (names) to join on. Must be found in both the left and right DataFrame objects.
- left_on=None, right_on=None:指定左右键

5.9 高级处理-交叉表与透视表


5.9.1 交叉表与透视表什么作用

5.9.2 使用crosstab(交叉表)实现上图
交叉表:交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系)
- pd.crosstab(value1, value2)
- DataFrame.pivot_table([], index=[])
5.9.3案例-探究股票和星期几之间的关系
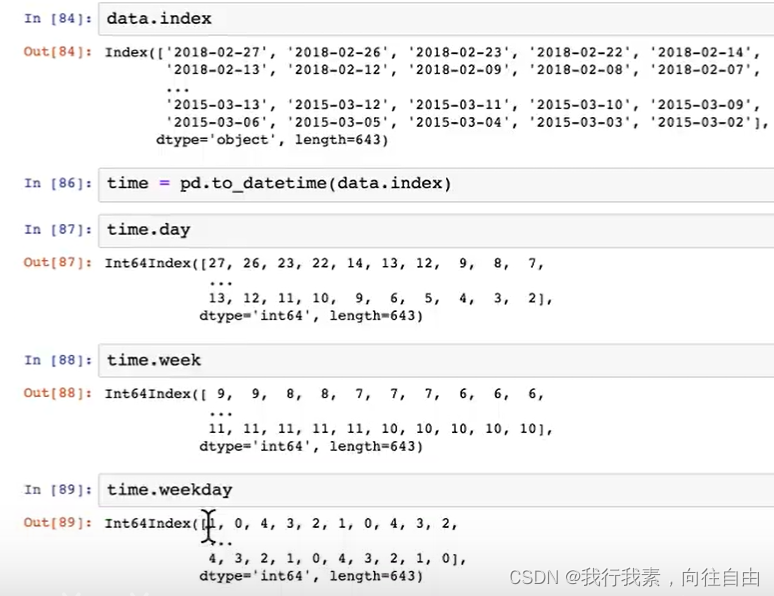



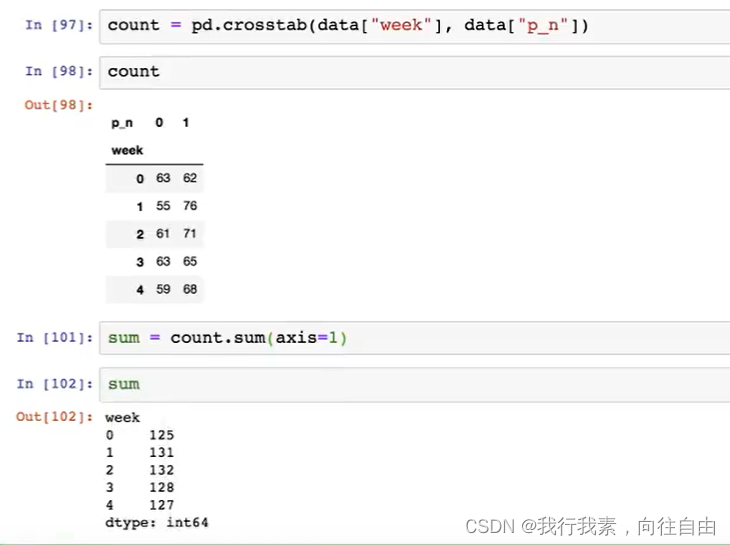
但是我们看到count只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
- 对于每个星期一等的总天数求和,运用除法运算求出比例。
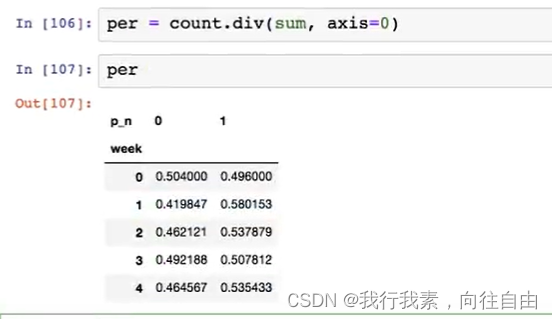
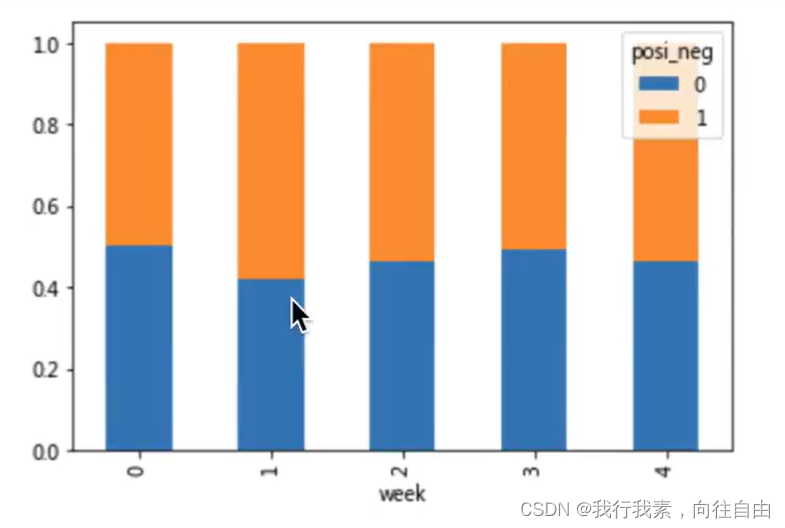
可视化:

5.9.4 使用pivot_table(透视表)实现
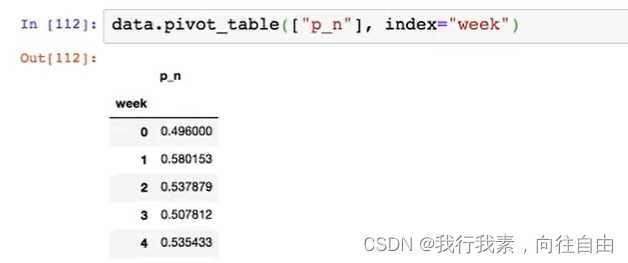
5.10 高级处理-分组与聚合

分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。
想一想其实刚才的交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例!
5.10.1 什么分组和聚合

分组不聚合没有任何意义,所以一般分组和聚合是分不开的。
5.10.2 分组API
DataFrame.groupby(key, as_index=False)
- key:分的列数据,可以多个
案例:不同颜色的不同笔的价格数据
-进行分组,对颜色分组,price进行聚合


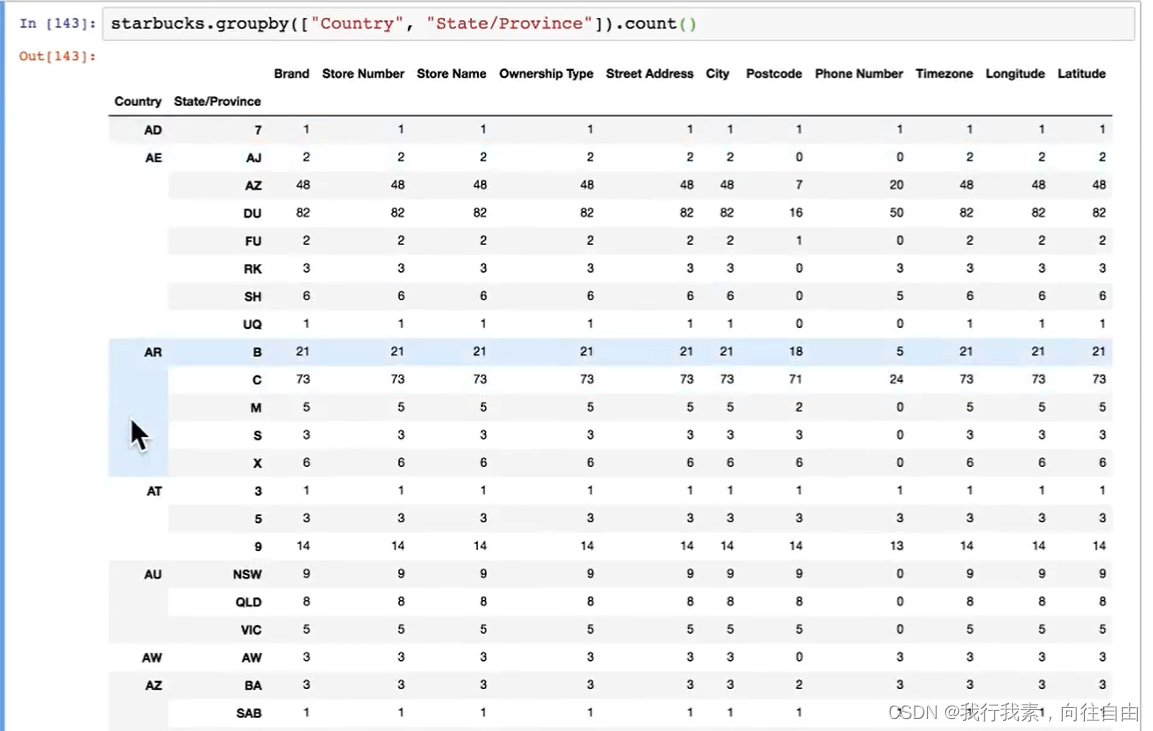
5.10.3 星巴克零售店铺数据




根据多组分组:假设我们加入省市一起进行分组。