
- 1QT设计模式:外观模式
- 2图书目录管理系统(python+mysql数据库)_设计一个图书管理系统数据库mysql
- 3AI视频教程下载:用ChatGPT自动化各种工作任务
- 4第14届蓝桥杯大赛——真题训练第三天_连号区间数是第几题
- 5音频录制(react)_recorder-core是否支持react
- 6尚硅谷大数据Flink1.17实战教程-笔记01【Flink概述、Flink快速上手】_尚硅谷 flink
- 7A_搜索(A Star)算法_a*搜索
- 8Ubuntu 22.04自动挂起后无法唤醒_ubuntu点了挂起怎么打开
- 9【LSTM时间序列预测】贝叶斯优化LSTM时间序列预测(单变量单输出)【含Matlab源码 651期】_贝叶斯时序预测模型
- 10情感分析资源大全(语料、词典、词嵌入、代码)_中文情感分析语料库
Python实现ACO蚁群优化算法优化支持向量机分类模型(SVC算法)项目实战_pyaco
赞
踩
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
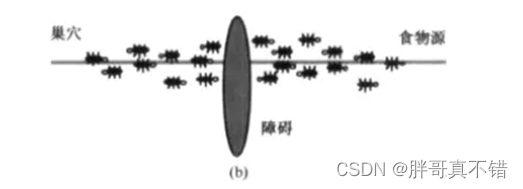
蚁群优化算法(Ant Colony Optimization, ACO)是一种源于大自然生物世界的新的仿生进化算法,由意大利学者M. Dorigo, V. Maniezzo和A.Colorni等人于20世纪90年代初期通过模拟自然界中蚂蚁集体寻径行为而提出的一种基于种群的启发式随机搜索算法"。蚂蚁有能力在没有任何提示的情形下找到从巢穴到食物源的最短路径,并且能随环境的变化,适应性地搜索新的路径,产生新的选择。其根本原因是蚂蚁在寻找食物时,能在其走过的路径上释放一种特殊的分泌物——信息素(也称外激素),随着时间的推移该物质会逐渐挥发,后来的蚂蚁选择该路径的概率与当时这条路径上信息素的强度成正比。当一条路径上通过的蚂蚁越来越多时,其留下的信息素也越来越多,后来蚂蚁选择该路径的概率也就越高,从而更增加了该路径上的信息素强度。而强度大的信息素会吸引更多的蚂蚁,从而形成一种正反馈机制。通过这种正反馈机制,蚂蚁最终可以发现最短路径。
本项目通过ACO蚁群优化算法优化支持向量机分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
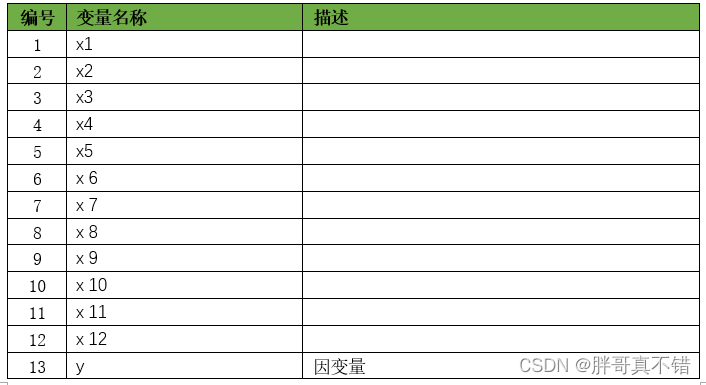
数据详情如下(部分展示):
3.数据预处理
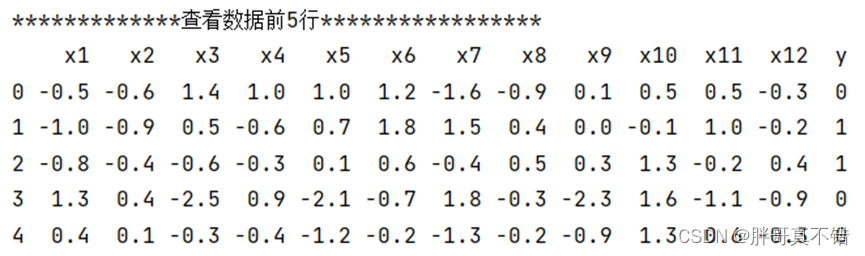
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
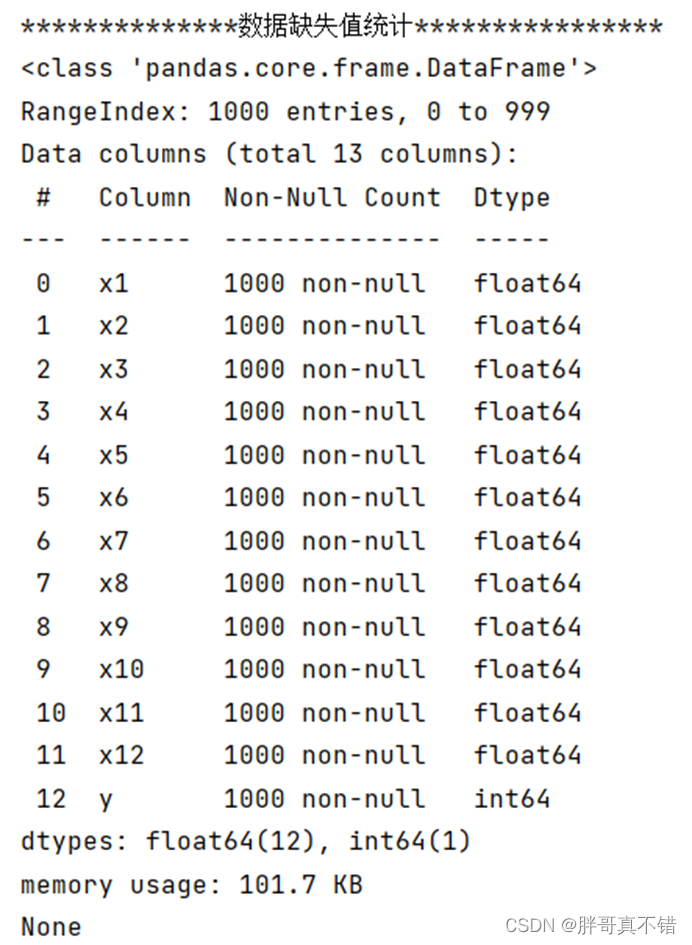
3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有13个变量,数据中无缺失值,共1000条数据。
关键代码:
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:
4.探索性数据分析
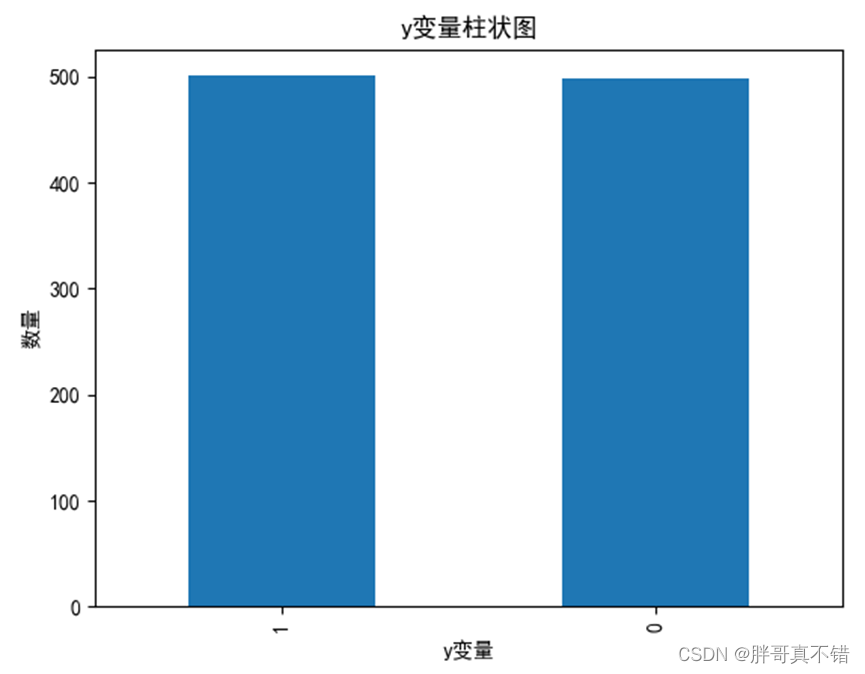
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
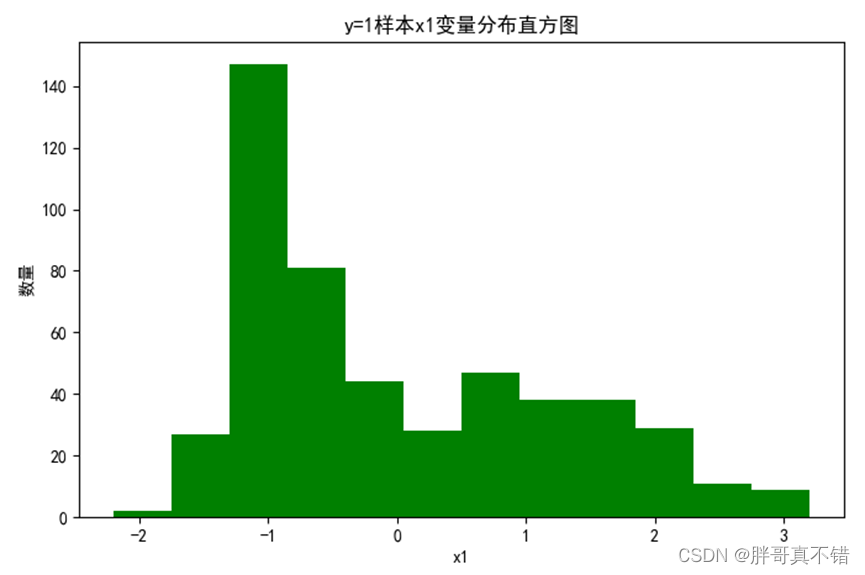
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
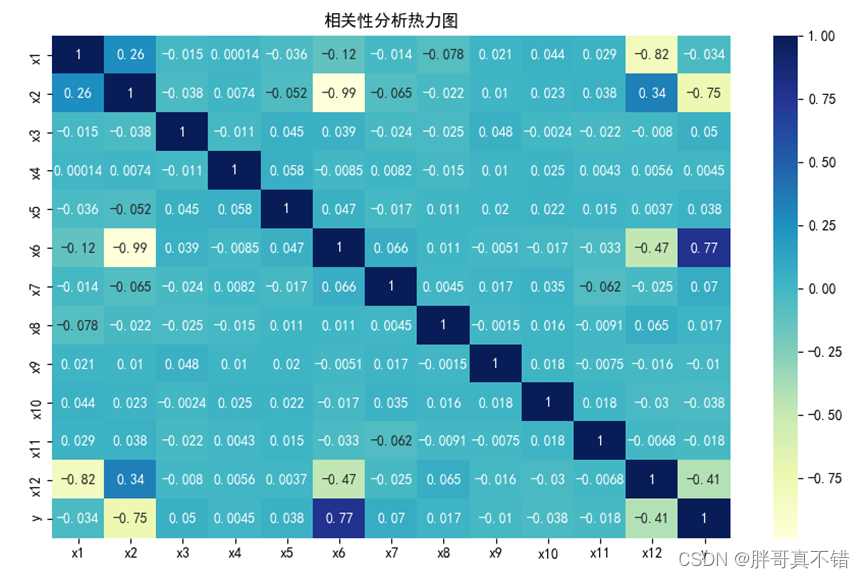
4.3 相关性分析
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:
5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
6.构建ACO蚁群优化算法优化支持向量机分类模型
主要使用ACO蚁群优化算法优化SVC算法,用于目标分类。
6.1 算法介绍
说明:ACO算法介绍来源于网络,供参考,需要更多算法原理,请自行查找资料。
蚁群算法是对自然界蚂蚁的寻径方式进行模拟而得出的一种仿生算法。蚂蚁在运动过程中,能够在它所经过的路径上留下信息素进行信息传递,而且蚂蚁在运动过程中能够感知这种物质,并以此来指导自己的运动方向。因此,由大量蚂蚁组成的蚁群的集体行为便表现出一种信息正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大。
蚁群算法公式:

蚁群算法程序概括:
(1)参数初始化
在寻最短路钱,需对程序各个参数进行初始化,蚁群规模m、信息素重要程度因子α、启发函数重要程度因子β、信息素会发因子、最大迭代次数ddcs_max,初始迭代值为ddcs=1。
(2)构建解空间
将每只蚂蚁随机放置在不同的出发地点,对蚂蚁访问行为按照公式计算下一个访问的地点,直到所有蚂蚁访问完所有地点。
(3)更新信息素
计算每只蚂蚁经过的路径总长Lk,记录当前循环中的最优路径,同时根据公式对各个地点间连接路径上的信息素浓度进行更新。
(4)判断终止
迭代次数达到最大值前,清空蚂蚁经过的记录,并返回步骤2。
6.2 ACO蚁群优化算法寻找最优参数值
关键代码:
适应度迭代曲线图:
最优参数:
6.3 最优参数值构建模型
7.模型评估
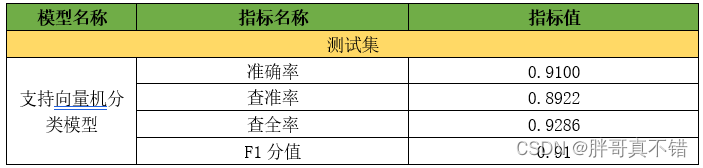
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
从上表可以看出,F1分值为0.91,说明模型效果良好。
关键代码如下:
7.2 查看是否过拟合
从上图可以看出,训练集和测试集分值相当,无过拟合现象。
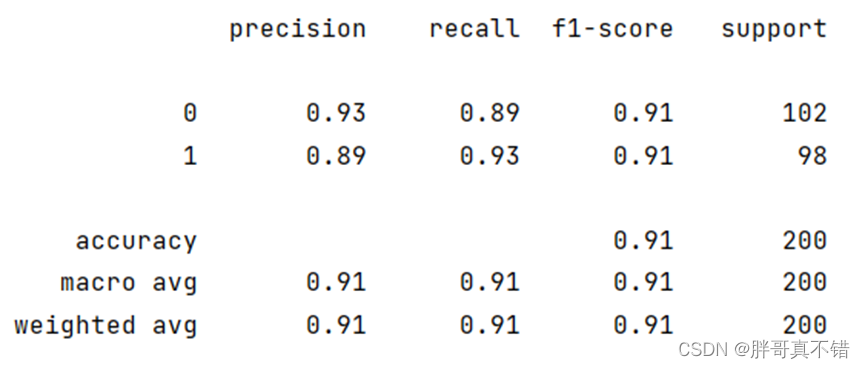
7.3 分类报告
从上图可以看出,分类为0的F1分值为0.91;分类为1的F1分值为0.91。
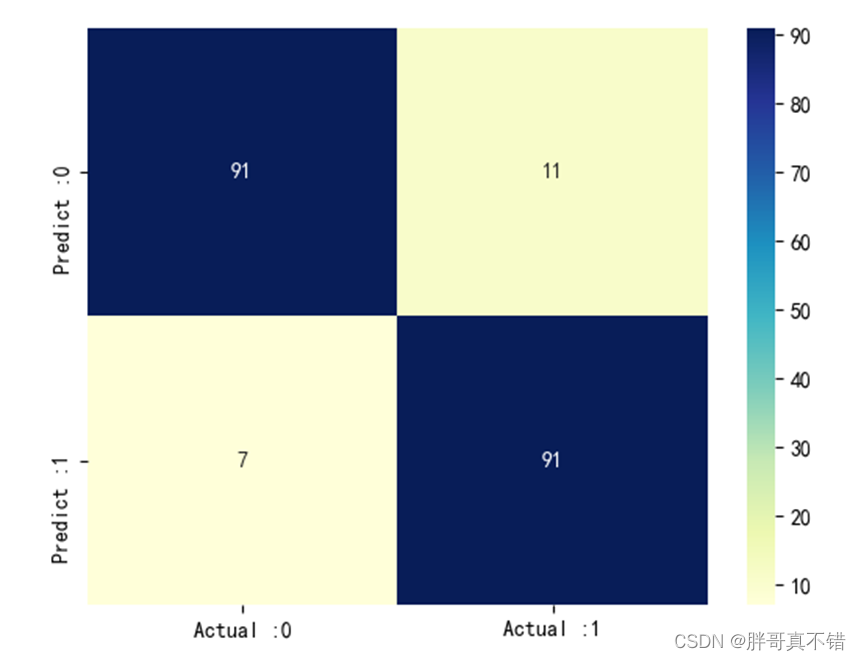
7.4 混淆矩阵
从上图可以看出,实际为0预测不为0的 有7个样本;实际为1预测不为1的 有11个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了ACO蚁群优化算法寻找支持向量机SVC算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。














- # 本次机器学习项目实战所需的资料,项目资源如下:
-
- # 项目说明:
-
- # 链接:https://pan.baidu.com/s/1WkKrFGMUCzICkR9AmvIfpQ
- # 提取码:2u1n
-
- # 查看数据前5行
- print('*************查看数据前5行*****************')
- print(df.head())
-
- # 数据缺失值统计
- print('**************数据缺失值统计****************')
- print(df.info())
-
- # 描述性统计分析
- print(df.describe())
- print('******************************')
-
- # y变量柱状图
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
- plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
- # kind='bar' 绘制柱状图
- df['y'].value_counts().plot(kind='bar')
- plt.xlabel("y变量")
- plt.ylabel("数量")
- plt.title('y变量柱状图')
- plt.show()


