
- 11-基于ArUco码的标记与检测
- 2C++函数参数的默认值_c++函数形参如果有默认值
- 3RabbitMQ优化消息阻塞系列(二)参数调优_rabbit:listener-container 参数
- 4哪个学校计算机每年招不满,这两所211大学,录取分数线低,却常年招不满生,适合考生捡漏...
- 5JsonObject判断是否为空_jsonobject判断为空
- 6java实现中文分词
- 7Git的rebase命令说明_linux git rebase
- 8HTML5期末大作业:甜品奶茶网站设计——甜品奶茶店(19页) HTML5网页设计成品_学生DW静态网页设计_web课程设计网页制作_奶茶网页设计
- 9C++刷题--选择题4_c++ 函数 只用一个默认值
- 10IT运维工程师职业发展与出路
动作分析 姿态估计_关于大片人物特效少不了的人体姿态估计,这里有一份综述文章...
赞
踩
大片中的人物特效如何实现,少不了应用人体姿态估计。这篇博客简介了使用深度学习技术的多人姿态估计方法,及其应用。
人体姿态骨架图 (skeleton) 用图形格式表示人的动作。本质上,它是一组坐标,连接起来可以描述人的姿势。骨架中的每个坐标都被称为这个图的部件(或关节、关键点)。我们称两个部件之间的有效连接为对(pair,或肢)。但是要注意的是,并非所有部件组合 都能产生有效的对。下图是一个人体姿态骨架图的示例。
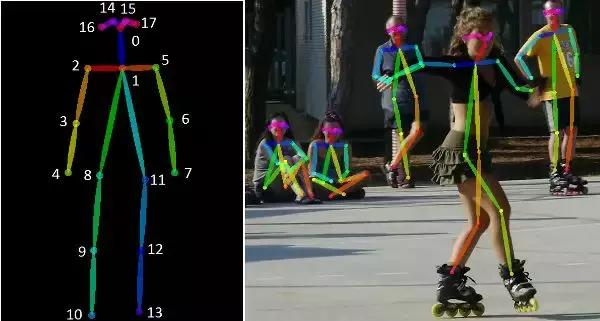
左:人体姿态骨架图的 COCO 关键点格式 ;右:渲染后的人体姿态图(图源:https://github.com/CMU-Perceptual-Computing-Lab/openpose)
人体姿态信息的获取为多个现实应用开辟了道路,本博客的最后也会讨论其中一些应用。近年来,研究人员提出了多种人体姿态估计方法,其中最早(也是最慢)的方法通常是在只有一个人的图像中估计一个人的姿势。这些方法通常先识别出各个部件,然后通过在它们之间形成连接来创建姿势。
当然,如果是在包含多人的现实场景,这些方法就不是很有用了。
多人姿态估计
由于不知道图像中每个人的位置和总人数,因此多人姿态估计比单人姿态估计更困难。通常,我们可以通过以下方法来解决上述问题:
简单的方法是:首先加入一个人体检测器,然后分别估计各个部件,最后再计算每个人的姿态。这种方法被称为「自顶向下」的方法。
另一种方法是:检测图像中的所有部件(即所有人的部件),然后将属于不同人的部件进行关联/分组。这种方法被称为「自底向上」方法。

上部: 传统的自顶向下的方法;下部: 传统的自底向上的方法。
通常,自顶向下的方法比自底向上的方法更容易实现,因为添加人体检测器要比使用关联/分组算法容易得多。整体上很难判断哪种方法性能更好,因为归根结底是对比人体检测器和关联/分组算法哪个更好。
在这篇博客中,我们主要关注使用深度学习技术的多人姿态估计技术。在下一节中,我们将回顾一些流行的自顶向下和自底向上方法。
深度学习方法
1. OpenPose
OpenPose 是最流行的自底向上多人姿态估计方法之一,部分原因在于其 GitHub 实现的文档注释很友好。
与许多自底向上的方法一样,OpenPose 首先检测图像中的部件(关键点),然后将部件分配给不同的个体。下图展示的是 OpenPose 模型的架构。
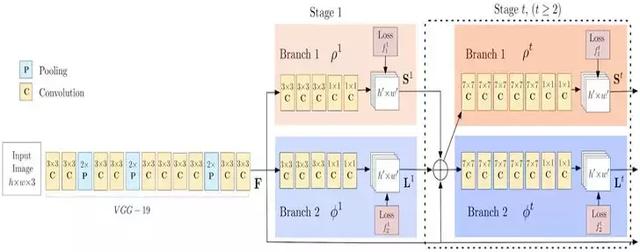
OpenPose 架构的流程图(图源:https://arxiv.org/pdf/1611.08050.pdf)
OpenPose 网络首先使用前几层(上图中是 VGG-19)从图像中提取特征。然后将这些特征输入到卷积层的两个并行分支中。第一个分支预测了一组置信图(18 个),每个置信图表示人体姿态骨架图的特定部件。第二个分支预测另外一组 Part Affinity Field (PAF,38 个),PAF 表示部件之间的关联程度。
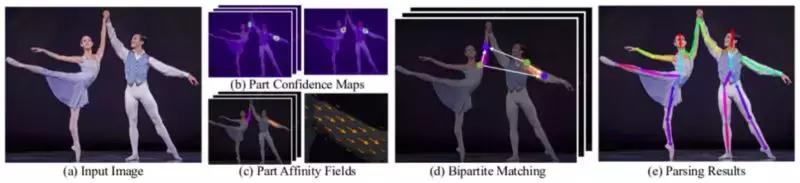
使用 OpenPose 进行人体姿态估计的步骤(图源:https://arxiv.org/pdf/1812.08008.pdf)
OpenPose 其余步骤的作用是细化每个分支做出的预测。利用部件置信图,在部件对之间形成二分图(如上图所示)。然后利用 PAF 值,对二分图中较弱的链接进行剪枝。通过以上步骤,我们可以估计出人体姿态骨架图,并将其分配给图像中的每一个人。
2. DeepCut
DeepCut 是一种自底向上的方法,可用于多人姿态估计。其作者通过定义以下问题来完成这项任务:
- 生成一组身体部件候选项集合 D。这个集合表示图像中所有人身体部位的所有可能位置。从身体部件候选集中选择身体部件的子集。
- 使用身体部件类 C 中的类别标注选中的每个身体部件。身体部件类表示部件的类型,如「手臂」、「腿」、「躯干」等。
- 分配属于同一个人的身体部位。

DeepCut 方法图示(图源:https://arxiv.org/pdf/1511.06645.pdf)
上述问题可以通过建模为整数线性规划问题(Integer Linear Programming,ILP)来解决。使用二元随机变量(binary random variable)的三元组 (x, y, z) 进行建模,二元随机变量的域如下图所示:
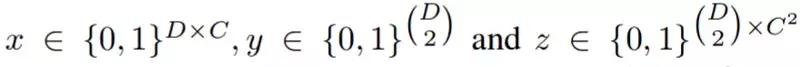
二元随机变量的域(图源:https://arxiv.org/pdf/1511.06645.pdf)
考虑来自身体部件候选项集合 D 的两个身体部件候选项 d 和 d',以及来自类别集 C 的类别 c 和 c',其中身体部件候选项是通过 Faster RCNN 或 Dense CNN 获得的。现在,我们可以开发以下语句集。
- 如果 x(d,c) = 1,则表示身体部件候选项 d 属于类别 c。
- 如果 y(d,d') = 1,则表示身体部件候选项 d 和 d'属于同一个人。
- 他们还定义了 z(d,d』,c,c』) = x(d,c) * x(d』,c』) * y(d,d』)。如果上述值为 1,则表示身体部件候选项 d 属于类别 c,身体部件候选项 d' 属于类别 c',最后身体部件候选项 d,d ' 属于同一个人。
最后一个语句可以用来划分属于不同人的姿势。上述语句显然可以用线性方程表示为 (x,y,z) 的函数。通过这种方法,我们就可以建立整数线性规划 (ILP) 模型,并估计出多人的姿态。完整方程和详细分析参见论文《DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation》。
3. RMPE (AlphaPose)
RMPE 是一种流行的自顶向下的姿态估计方法。其作者认为,自顶向下的方法通常依赖于人体检测器的表现,因为姿态估计是对有人在的区域上执行的。因此,定位误差和重复的边界框预测可能会导致姿态提取算法只能得到次优解。

重复预测的影响(左)和低置信度边界框的影响(右)(图源:https://arxiv.org/pdf/1612.00137.pdf)
为解决这一问题,作者提出利用对称空间变换网络 (Symmetric Spatial Transformer Network, SSTN) 从不准确的边界框中提取高质量的单人区域。在该区域中,利用单人姿态估计器 (SPPE) 来估计这个人的人体姿态骨架图。然后我们再利用空间去变换器网络 (Spatial De-Transformer Network, SDTN) 将估计的人体姿态重新映射回原始图像坐标系。最后,利用参数化姿态非极大值抑制 (parametric pose NMS) 技术解决冗余问题。
此外,作者还介绍了姿态引导的 proposal 生成器(Pose Guided Proposals Generator)来增强训练样本,以更好地帮助训练 SPPE 和 SSTN 网络。RMPE 的显著特点是,这一技术可以扩展为人体检测算法和 SPPE 的任意组合。
4. Mask RCNN
Mask RCNN 是用于执行语义和实例分割的流行架构。该模型可以并行地预测图像中各种对象的边界框位置和对对象进行语义分割的掩码(mask)。而这种基本架构可以轻松地扩展成用于人体姿态估计的方法。
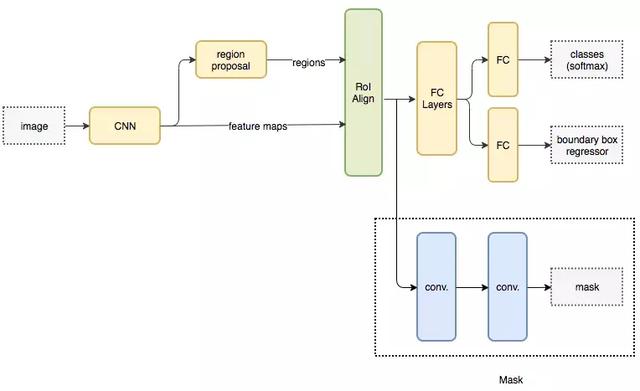
Mask RCNN 架构流程图(图源:https://medium.com/@jonathan_hui/image-segmentation-with-mask-r-cnn-ebe6d793272)
该基本架构首先使用 CNN 从图像中提取特征图。区域候选网络(Region Proposal Network,RPN)使用这些特征图来获取对象的候选边界框。这些候选边界框就是从 CNN 提取的特征图中选择区域(region)而得到的。由于候选边界框可以具有各种尺寸,因此我们使用一个叫作 RoIAlign 的层来减小所提取特征的尺寸,使得它们的大小一致。现在,将提取到的特征传递到 CNN 的并行分支,以最终预测边界框和分割掩码。
现在我们看一下执行分割的分支。首先假设图像中的一个对象属于类别集合 K。分割分支可以输出 K 个大小为 m x m 的二进制掩码(mask),其中每个二进制掩码表示仅属于该类的所有对象。我们可以将每种类型的关键点建模为不同的类,并将其作为分割问题来处理,从而提取出属于图像中每个人的关键点。
同时,我们还可以训练目标检测算法来识别人的位置。通过结合人的位置信息和他们的关键点,我们可以得到图像中每个人的人体姿态骨架图。
这种方法类似于自顶向下的方法,但是人体检测阶段是与部件检测阶段并行执行的。也就是说,关键点检测阶段和人体检测阶段是相互独立的。
其他方法
多人人体姿态估计有很多解决方法。简洁起见,本文仅解释了几种方法。有关更详尽的方法列表,大家可以查看以下资料:
应用
姿态估计在许多领域都有应用,下面列举其中的一些应用。
1. 活动识别
追踪人体在一段时间内姿势的变化也可以用于活动、手势和步态识别。这样的用例有:
- 检测一个人是否跌倒或生病的应用。
- 可以自主地教授正确的锻炼机制、体育技术和舞蹈活动的应用。
- 可以理解全身手语的应用(例如:机场跑道信号、交通警察信号等)。
- 可以增强安全性和用来监控的应用。
追踪人的步态对于安全和监控领域是很有用的(图源:http://www.ee.oulu.fi/~gyzhao/research/gait_recognition.htm)
2. 动作捕捉和增强现实
CGI 应用是一类有趣的应用,它也利用了人体姿态估计。如果可以估计人的姿势,就能够将图、风格、设备和艺术品叠加在人身上。通过追踪这种人体姿势的变化,渲染出的图形可以在人移动时「很自然地适应」人。

CGI 渲染示例(图源:https://i.kym-cdn.com/photos/images/facebook/001/012/571/0a4.jpg)
Animoji 是一个很好的例子。尽管上面的研究只追踪了人脸的结构,但这个思路可以扩展用于人体关键点追踪。同样的概念也可以用来渲染一些模仿人类动作的增强现实 (AR) 元素。
3. 训练机器人
我们可以不通过手动对机器人进行编程来追踪轨迹,而是沿着执行某个动作的人体姿态骨架的轨迹运行。人类教练可以通过演示动作,有效地教机器人这些动作。然后,机器人可以通过计算得知如何移动关节才能执行相同的动作。
4. 控制台动作追踪
姿态估计的另一个有趣的应用是在交互式游戏中追踪人体的运动。通常,Kinect 使用 3D 姿态估计(利用红外传感器数据)来追踪人类玩家的运动,并使用它来渲染虚拟人物的动作。
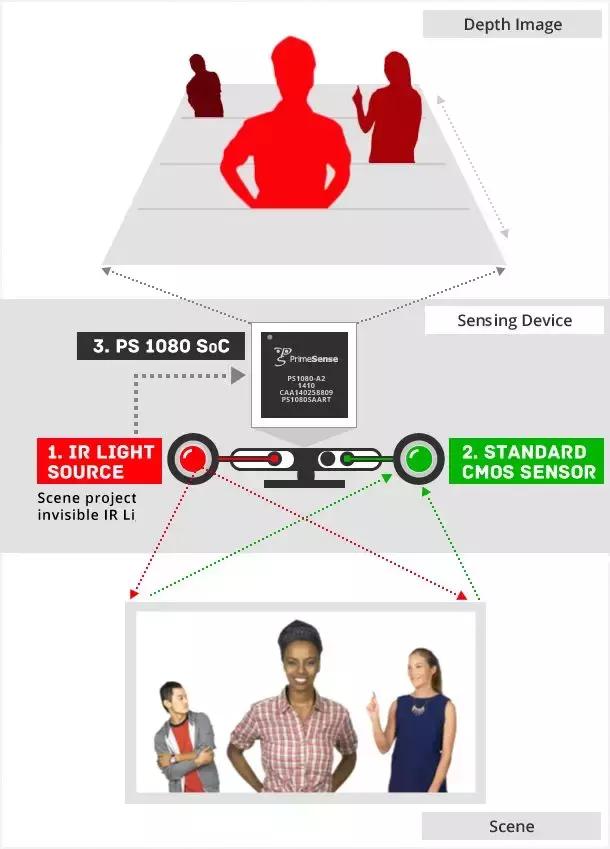
运行中的 Kinect 传感器(图源:https://appleinsider.com/articles/14/07/11/apples-secret-plans-for-primesense-3d-tech-hinted-at-by-new-itseez3d-ipad-app)
结论
当前我们在人体姿态估计领域已经取得了长足进步,这使得我们能够更好地服务大量可能使用这项技术的应用。此外,对姿势追踪等相关领域的研究可以大大提高其在多个领域的生产利用率。
原文链接:https://medium.com/beyondminds/an-overview-of-human-pose-estimation-with-deep-learning-d49eb656739b

