
- 1ScheduledExecutorService执行周期性或定时任务_scheduledexecutorservice实现每个周日执行
- 2深度学习从零开始_安装d21
- 3嵌入式系统Boot Loader启动全过程详解_boot to edload
- 4Docker常用命令(三)
- 5linux把文件从光驱复制到,Linux_在Windows上制作CentOS自动安装的光盘的教程,1 复制光盘文件 1)挂载iso镜 - phpStudy...
- 6探索 Java 8 中的 Stream 流:构建流的多种方式
- 7openfeign实现远程调用_openfeign远程调用
- 8stata回归?固定效应模型(组内变换OR LSDV最小二乘法)_stata固定效应回归命令
- 9U-Net图像语义分割实战:训练自己的数据集_使用u-net分割自己的数据集
- 10PyQt5保姆级入门教程——从安装到使用_pyqt5安装教程
如何用tensorflow实现一个CIFAR10分类准确率94%以上的网络(附完整代码)_cifar10准确率90以上
赞
踩
之前的一些记录
数据集读取的通用流程
(梳理)用Tensorflow实现SE-ResNet(SENet ResNet ResNeXt VGG16)的数据输入,训练,预测的完整代码框架(cifar10准确率90%)
balabalabala
之前的代码感觉还是太乱了,我刚开始学的时候还是用的tensorflow1.2
现在2.5都要出来了,就重新梳理了一下
这次用了Tensorflow1.15,统一使用了tf.keras和tf.data接口
代码看起来简洁了不少
tf.keras的模型model是支持直接传入Numpy数据进行预测
但是在这份代码中我仍然使用了tf.data,方便进行数据预处理和数据增强(主要是数据增强)
ResNet50+SENet轻量级注意力网络
数据增强部分使用随机翻转,随即裁剪等常规操作
另外新加了CutOut数据增强,随机生成几个给定大小的block,来对图片进行遮挡
class Cutout(object): """Randomly mask out one or more patches from an image. Args: n_holes (int): Number of patches to cut out of each image. length (int): The length (in pixels) of each square patch. """ def __init__(self, n_holes, length): self.n_holes=n_holes self.length=length def __call__(self, img): """ Args: img (Tensor): Tensor image of size (C, H, W). Returns: Tensor: Image with n_holes of dimension length x length cut out of it. """ h=img.shape[0] w=img.shape[1] mask=np.ones((h, w), np.float32) for n in range(self.n_holes): y=np.random.randint(h) x=np.random.randint(w) y1=np.clip(y-self.length//2,0,h) y2=np.clip(y+self.length//2,0,h) x1=np.clip(x-self.length//2,0,w) x2=np.clip(x+self.length//2,0,w) mask[y1: y2, x1: x2] = 0. mask=np.expand_dims(mask,axis=-1) img=img*mask return img

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
数据预处理+数据增强
class DatasetReader(object): def __init__(self,data_path,image_size=None): self.data_path=data_path self.img_size=image_size self.img_size.append(3) self.train_path=os.path.join(data_path,"train") self.test_path=os.path.join(data_path,"test") self.TF_path=os.path.join(data_path,"TFRecordData") self.tf_train_path=os.path.join(self.TF_path,"train") self.tf_test_path=os.path.join(self.TF_path,"test") self.classes=os.listdir(self.train_path) self.__Makedirs() self.train_batch_initializer=None self.test_batch_initializer=None self.__CreateTFRecord(self.train_path,self.tf_train_path) self.__CreateTFRecord(self.test_path,self.tf_test_path) def __CreateTFRecord(self,read_path,save_path):#创建TFRecord文件 path=os.path.join(save_path,"data.TFRecord") if os.path.exists(path): print("find file "+(os.path.join(save_path,"data.TFRecords"))) return else: print("cannot find file %s,ready to recreate"%(os.path.join(save_path,"data.TFRecords"))) writer=tf.python_io.TFRecordWriter(path=path) image_path=[] image_label=[] for label,class_name in enumerate(self.classes): class_path=os.path.join(read_path,class_name) for image_name in os.listdir(class_path): image_path.append(os.path.join(class_path,image_name)) image_label.append(label) for i in range(5):image_path,image_label=shuffle(image_path,image_label) bar=Progbar(len(image_path)) for i in range(len(image_path)): image,label=Image.open(image_path[i]).convert("RGB"),image_label[i] image=image.convert("RGB") image=image.tobytes() example=tf.train.Example(features=tf.train.Features(feature={ "label":tf.train.Feature(int64_list=tf.train.Int64List(value=[label])), "image":tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])) })) writer.write(example.SerializeToString()) bar.update(i+1) writer.close() def __Makedirs(self): if not os.path.exists(self.TF_path): os.makedirs(self.TF_path) if not os.path.exists(self.tf_train_path): os.makedirs(self.tf_train_path) if not os.path.exists(self.tf_test_path): os.makedirs(self.tf_test_path) def __parsed(self,tensor): feature=tf.parse_single_example(tensor,features={ "image":tf.FixedLenFeature([],tf.string), "label":tf.FixedLenFeature([],tf.int64) }) image=tf.decode_raw(feature["image"],tf.uint8) image=tf.reshape(image,self.img_size) image=tf.random_crop(image,self.img_size) image=image/255 label=tf.cast(feature["label"],tf.int32) label=tf.one_hot(label,len(self.classes)) return image,label def __parsed_distorted(self,tensor): feature=tf.parse_single_example(tensor,features={ "image":tf.FixedLenFeature([],tf.string), "label":tf.FixedLenFeature([],tf.int64) }) image=tf.decode_raw(feature["image"],tf.uint8) image=tf.reshape(image,self.img_size) image=tf.image.random_flip_left_right(image) image=tf.image.random_flip_up_down(image) image=tf.image.random_brightness(image,max_delta=0.2) image=tf.image.random_hue(image,max_delta=0.2) image=tf.image.random_contrast(image,lower=0.75,upper=1.25) image=tf.image.random_saturation(image,lower=0.75,upper=1.25) image=image/255 random=tf.random_uniform(shape=[],minval=0,maxval=1,dtype=tf.float32) random_shape=tf.random_uniform(shape=[2],minval=32,maxval=48,dtype=tf.int32) croped_image=tf.image.resize_image_with_crop_or_pad(image,40,40) croped_image=tf.image.resize_images(croped_image,random_shape,method=2) croped_image=tf.random_crop(croped_image,[32,32,3]) image=tf.cond(random<0.25,lambda:image,lambda:croped_image) image=tf.reshape(image,[32,32,3]) random=tf.random_uniform(shape=[],minval=0,maxval=1,dtype=tf.float32) cut_image=tf.py_func(Cutout(2,8),[image],tf.float32) image=tf.cond(random<0.25,lambda:image,lambda:cut_image) image=tf.reshape(image,[32,32,3]) image=tf.reshape(image,shape=[32,32,3]) label=tf.cast(feature["label"],tf.int32) label=tf.one_hot(label,len(self.classes)) return image,label def __get_dataset(self,path,parsed,batch_size,buffer_size=10000): filename=[os.path.join(path,name)for name in os.listdir(path)] dataset=tf.data.TFRecordDataset(filename) dataset=dataset.prefetch(tf.contrib.data.AUTOTUNE) dataset=dataset.shuffle(buffer_size=buffer_size,seed=19260817) dataset=dataset.repeat(count=None) dataset=dataset.map(parsed,num_parallel_calls=16) dataset=dataset.batch(batch_size=batch_size) dataset=dataset.apply(tf.data.experimental.prefetch_to_device("/gpu:0")) return dataset def global_variables_initializer(self): initializer=[] initializer.append(self.train_batch_initializer) initializer.append(self.test_batch_initializer) initializer.append(tf.global_variables_initializer()) return initializer def test_batch(self,batch_size): dataset=self.__get_dataset(self.tf_test_path,self.__parsed,batch_size) return dataset def train_batch(self,batch_size): dataset=self.__get_dataset(self.tf_train_path,self.__parsed_distorted,batch_size) return dataset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
这部分代码很长,也是很久前就写好就没动过了hhh
大致流程就是
1.根据图片数据集文件夹创建一个TFRecord文件
数据集文件夹中每个类别分别再建立一个文件夹并放置图片
如下为CIFAR10数据集的文件夹

2.读取TFRecord文件,生成一个dataset对象
然后对于每一个拿去训练的batch,进行数据增强
随机大小变换,随机翻转,随机噪声,CutOut等等,当然训练集需要数据增强,验证集并不需要
3.得到用于训练的dataset对象(tf.data.TFRecordDataset).
tf.keras允许直接传入这个dataset对象(1.15)
1.14的话需要用迭代器(iterator=ds.make_one_shot_iterator())
更早的版本,传入不支持迭代器的话,那就进一步传入一个Tensor,这个Tensor每次调用会得到不同的一个batch的数据(batch=iterator.get_next()),但是印象中这个只能迭代一轮
但是tf.keras的话可以用这个没问题的
多次迭代的话可以使用iterator=dataset.make_initializable_iterator().get_next()
同时使用之前需要先运行sess.run(iterator.initializer)来初始化
4.传入model.fit进行训练,这一步下面说
网络结构
基本结构单元
CBR
Conv-BN-Relu结构,非常经典的结构了
class Convolution2D(object):
def __init__(self,filters,ksize,strides=1,padding="valid",activation=None,kernel_regularizer=None):
self.filters=filters
self.kernel_regularizer=kernel_regularizer
self.ksize=ksize
self.strides=strides
self.padding=padding
self.activation=activation
def __call__(self,x):
x=Conv2D(self.filters,self.ksize,self.strides,padding=self.padding,kernel_regularizer=self.kernel_regularizer)(x)
x=BatchNormalization()(x)
x=Activation(self.activation)(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
SENet

一种轻量级通道注意力机制
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
class SEBlock(object):
def __init__(self,se_rate=16,l2_rate=0.001):
self.se_rate=se_rate
self.l2_rate=l2_rate
def __call__(self,inputs):
shape=inputs.shape
squeeze=GlobalAveragePooling2D()(inputs)
squeeze=Dense(shape[-1]//self.se_rate,activation="relu")(squeeze)
extract=Dense(shape[-1],activation=tf.nn.sigmoid)(squeeze)
extract=tf.expand_dims(extract,axis=1)
extract=tf.expand_dims(extract,axis=1)
output=tf.keras.layers.multiply([extract,inputs])
return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
ResNet

非常经典的结构,就不做过多说明了
class Residual(object): def __init__(self,filters,kernel_size,strides=1,padding='valid',activation=None): self.filters=filters self.kernel_size=kernel_size self.strides=strides self.padding=padding self.activation=activation def __call__(self,inputs): x=Convolution2D(filters=self.filters[0], ksize=(1,1), strides=self.strides, padding=self.padding, activation=self.activation)(inputs) x=Convolution2D(filters=self.filters[1], ksize=self.kernel_size, strides=self.strides, padding=self.padding, activation=self.activation)(x) x=Convolution2D(filters=self.filters[2], ksize=(1,1), strides=self.strides, padding=self.padding, activation=None)(x) if x.shape.as_list()[-1]!=inputs.shape.as_list()[-1]: inputs=Convolution2D(filters=self.filters[2], ksize=(1,1), strides=self.strides, padding=self.padding, activation=None)(inputs) x=tf.keras.layers.add([inputs,x]) x=tf.keras.layers.Activation(self.activation)(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
SE+Res
残差之前加上SENet通道注意力机制
class Residual(object): def __init__(self,filters,kernel_size,strides=1,padding='valid',activation=None): self.filters=filters self.kernel_size=kernel_size self.strides=strides self.padding=padding self.activation=activation def __call__(self,inputs): x=Convolution2D(filters=self.filters[0], ksize=(1,1), strides=self.strides, padding=self.padding, activation=self.activation)(inputs) x=Convolution2D(filters=self.filters[1], ksize=self.kernel_size, strides=self.strides, padding=self.padding, activation=self.activation)(x) x=Convolution2D(filters=self.filters[2], ksize=(1,1), strides=self.strides, padding=self.padding, activation=None)(x) x=SEBlock(se_rate=16)(x) #在残差add之前加上SENet即可,非常方便hhh if x.shape.as_list()[-1]!=inputs.shape.as_list()[-1]: inputs=Convolution2D(filters=self.filters[2], ksize=(1,1), strides=self.strides, padding=self.padding, activation=None)(inputs) x=tf.keras.layers.add([inputs,x]) x=tf.keras.layers.Activation(self.activation)(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
结构可视化
待补充
完整网络结构的代码
import tensorflow as tf from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Input from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import GlobalAveragePooling2D from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import AveragePooling2D from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Activation from tensorflow.keras.models import Model from tensorflow.keras.layers import Softmax from tensorflow.keras.layers import Dense from tensorflow.keras.regularizers import l2 class SEBlock(object): def __init__(self,se_rate=16,l2_rate=0.001): self.se_rate=se_rate self.l2_rate=l2_rate def __call__(self,inputs): shape=inputs.shape squeeze=GlobalAveragePooling2D()(inputs) squeeze=Dense(shape[-1]//self.se_rate,activation="relu")(squeeze) extract=Dense(shape[-1],activation=tf.nn.sigmoid)(squeeze) extract=tf.expand_dims(extract,axis=1) extract=tf.expand_dims(extract,axis=1) output=tf.keras.layers.multiply([extract,inputs]) return output class Convolution2D(object): def __init__(self,filters,ksize,strides=1,padding="valid",activation=None,kernel_regularizer=None): self.filters=filters self.kernel_regularizer=kernel_regularizer self.ksize=ksize self.strides=strides self.padding=padding self.activation=activation def __call__(self,x): x=Conv2D(self.filters,self.ksize,self.strides,padding=self.padding,kernel_regularizer=self.kernel_regularizer)(x) x=BatchNormalization()(x) x=Activation(self.activation)(x) return x class Residual(object): def __init__(self,filters,kernel_size,strides=1,padding='valid',activation=None): self.filters=filters self.kernel_size=kernel_size self.strides=strides self.padding=padding self.activation=activation def __call__(self,inputs): x=Convolution2D(filters=self.filters[0], ksize=(1,1), strides=self.strides, padding=self.padding, activation=self.activation)(inputs) x=Convolution2D(filters=self.filters[1], ksize=self.kernel_size, strides=self.strides, padding=self.padding, activation=self.activation)(x) x=Convolution2D(filters=self.filters[2], ksize=(1,1), strides=self.strides, padding=self.padding, activation=None)(x) x=SEBlock(se_rate=16)(x) if x.shape.as_list()[-1]!=inputs.shape.as_list()[-1]: inputs=Convolution2D(filters=self.filters[2], ksize=(1,1), strides=self.strides, padding=self.padding, activation=None)(inputs) x=tf.keras.layers.add([inputs,x]) x=tf.keras.layers.Activation(self.activation)(x) return x class SEResNet50(object): def __init__(self,se_rate=16,l2_rate=0,drop_rate=0.25): self.se_rate=se_rate self.l2_rate=l2_rate self.drop_rate=drop_rate def __call__(self,inputs): x=Convolution2D(32,[3,3],[1,1],activation="relu",padding="same")(inputs) x=Residual([32,32,128],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([32,32,128],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([32,32,128],[3,3],[1,1],activation="relu",padding="same")(x) x=MaxPooling2D([3,3],[2,2],padding="same")(x) x=Residual([64,64,256],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([64,64,256],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([64,64,256],[3,3],[1,1],activation="relu",padding="same")(x) x=Dropout(self.drop_rate)(x) x=Residual([64,64,256],[3,3],[1,1],activation="relu",padding="same")(x) x=MaxPooling2D([3,3],[2,2],padding="same")(x) x=Residual([128,128,512],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([128,128,512],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([128,128,512],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([128,128,512],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([128,128,512],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([128,128,512],[3,3],[1,1],activation="relu",padding="same")(x) x=Dropout(self.drop_rate)(x) x=MaxPooling2D([3,3],[2,2],padding="same")(x) x=Residual([256,256,1024],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([256,256,1024],[3,3],[1,1],activation="relu",padding="same")(x) x=Residual([256,256,1024],[3,3],[1,1],activation="relu",padding="same")(x) x=GlobalAveragePooling2D()(x) x=Dropout(self.drop_rate)(x) x=Dense(10,activation="softmax")(x) print(self) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
加载CIFAR10数据集
batch_size=128
data_path="dataseats/cifar10/Image"
mode_path="dataseats/cifar10/Image/TFMode"
dataset=DatasetReader(data_path,image_size=[32,32])
train_dataset=dataset.train_batch(batch_size=batch_size)
test_dataset=dataset.test_batch(batch_size=batch_size)
- 1
- 2
- 3
- 4
- 5
- 6
定义模型结构
plateau=ReduceLROnPlateau(monitor="val_acc", #12epoch准确率没有上升,学习率减半 verbose=1, mode='max', factor=0.6, patience=12) early_stopping=EarlyStopping(monitor='val_acc',#70epoch准确率没有上升,停止训练 verbose=1, mode='max', patience=70) checkpoint=ModelCheckpoint(f'SERESNET101_CLASSIFIER_CIFAR10_DA.h5',#保存acc最高的模型 monitor='val_acc', verbose=1, mode='max', save_weights_only=False, save_best_only=True) inputs=Input(shape=[32,32,3]) #定义输入shape outputs=SEResNet50()(inputs) model=Model(inputs,outputs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
编译和训练
model.compile(loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(lr=0.001),
metrics=['acc'])
trained_model=model.fit(
train_dataset,
steps_per_epoch=50000//batch_size,
shuffle=True,
epochs=300,
validation_data=test_dataset,
validation_steps=10000//batch_size,
callbacks=[plateau,early_stopping,checkpoint]
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
loss和acc变化曲线
待补充
评估和预测
在训练集上训练模型,然后使用测试集来测试网络的准确率:
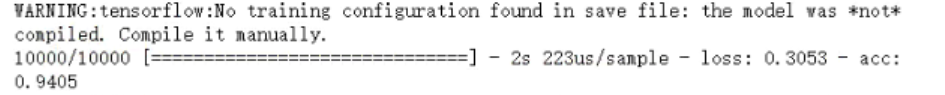
在测试集上,准确率可以达到94.05%
其他的一些补充
AdamW+L2
L2有利于防止模型的过拟合,但是Adam+L2并不是一个好选择
但是可以考虑AdamW+weight_decay
这里待测试
使用SGD训练
Adam通常来说比SGD收敛速度更快,但是最终模型的准确率和泛化能力在CV任务上比不上SGD的解,因此使用SGD或SGDM可能会得到更好的准确率
这里有空会进行实验对比下结果

