- 1HTML5设计网站结构简单设计_html的网站架构设计
- 2在 Windows 上从源代码安装 OpenCV – C++ / Python-附带安装脚本_opencv c++ 安装 win
- 3【Windows】使用PowerShell安装vim_powershell vim
- 4树莓派远程连接的四种方式(最全)
- 5动态扩容Linux根目录 (解决/dev/mapper/centos-root 占用过高)_linux 在不影响现有系统的情况下扩容/dev/mapper/centos-root
- 6Scapy学习笔记之数据包的结构_scapy中每一层layer可能的值
- 7关于生成式人工智能模型应用的调研
- 8unity农场模拟经营游戏源码
- 9Qt Quick Lession1 (体验快速构建动态效果界面)_qt动态界面设计
- 10Pytest参数化-上篇_pytest yield后面加参数
GPT-3论文翻译总结
赞
踩
1 简介
本文根据2020年OpenAI《Language Models are Few-Shot Learners》翻译总结的,GPT-3的论文。不过原文较长,75页,主要内容思想集中在前十几页,我基于前13页翻译总结的。
GPT,一种半监督方法,首先是非监督的预训练,然后进行监督训练微调。
详见https://blog.csdn.net/zephyr_wang/article/details/113430006
GPT-2,只需要非监督训练。
详见https://blog.csdn.net/zephyr_wang/article/details/113748490
从文章标题可以看出来,GPT-3关注Few-Shot(只需少量标注样本,10到100)。当然GPT-3更希望自己是Zero-Shot(无需标注样本,无监督学习),文中还提了one-shot。认为人类的学习更像是Zero-Shot,从资料中自己提取知识。
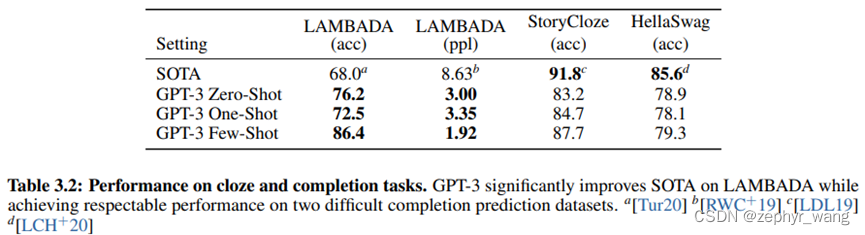
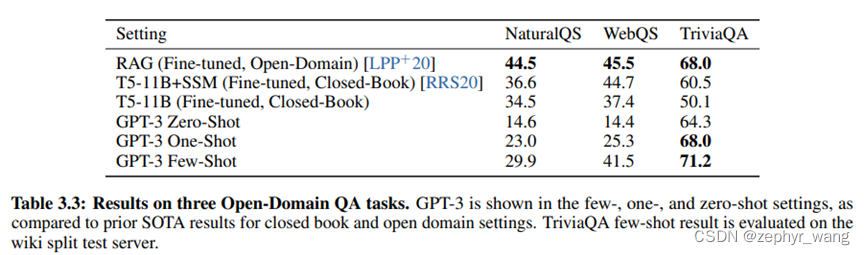
GPT-3的 Few-Shot (FS)、One-Shot (1S)、Zero-Shot (0S)效果接近有时超越fine-tune模型的效果。
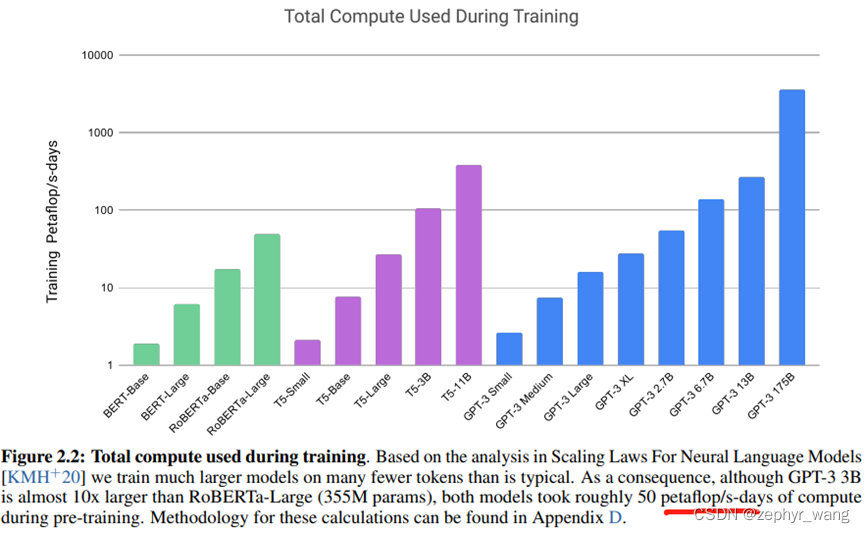
GPT-3是自回归(autoregressive)模型,1750亿参数。训练计算成本如下,采用petaflop/s-days进行衡量的,从下图可以看出来GPT-3的计算量够大,1000多petaflop/s-days:
2 方法
目前模型训练主要有如下四种方法,Fine-Tuning (FT)、Few-Shot (FS)、One-Shot (1S)、Zero-Shot (0S)。如下图所示,其中GPT-3采用的Few-Shot (FS)、One-Shot (1S)、Zero-Shot (0S)没有采用梯度更新(no gradient update)。以One-Shot为例,没有梯度更新是指将一个标注样本直接插入到要预测文本的前面,如下图one-shot中的example,然后将任务描述(task description)、one-shot的exmaple、要预测(翻译)的句子整合在一起(下面蓝色部分)整体输入到GPT-3,来输出最终的结果。

2.1 模型结构
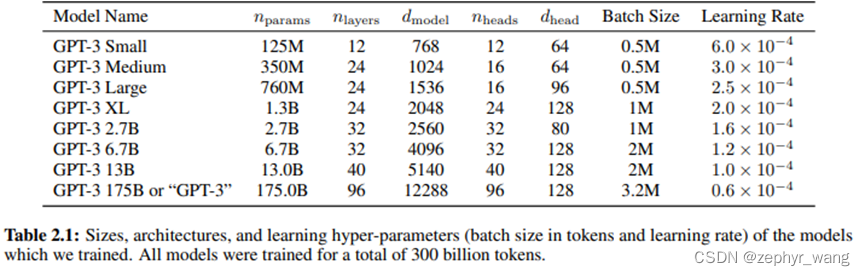
文中比较了下面8个模型,GPT-3一般指下面最大那个。大模型可以采用更大的batch size和更小的学习率进行训练。
GPT-3采用和GPT-2一样的模型结构,包括modified initialization, pre-normalization, and reversible(可逆) tokenization。不一样的是采用了类似Sparse Transformer模型在Transformer层的alternating dense and locally banded sparse attention patterns。
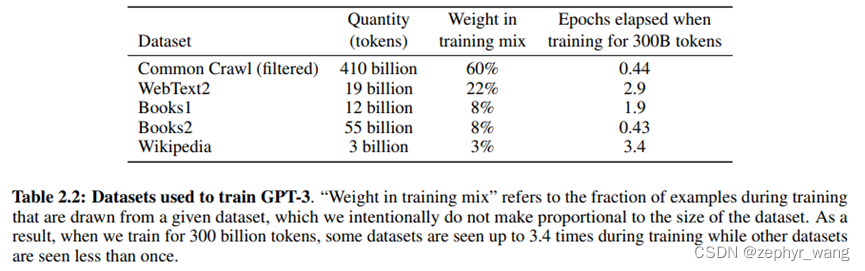
2.2 训练数据
common crawl数据过滤前45TB,我们进行了过滤,过滤后570GB.
3 实验结果
从下面两个表中,可以看到GPT-3的 Few-Shot (FS)、One-Shot (1S)、Zero-Shot (0S)效果接近有时超越fine-tune模型的效果。