
- 1VS2015使用QAxObject注意事项_qaxobject 对应的lib库
- 2超全前端面试回答-设计模式_design_对于开发中对设计模式的应用面试怎么回答
- 3Relu 与 leakyRelu_relu和leaky relu
- 4word doc/docx 格式文件转换为 markdown_doc 转.md文件
- 5Python办公自动化|可能是全网最完整的 Python 操作 Excel库总结!_python办公自动化常用的库
- 6创建自己的docker镜像然后pull下载验证_docker 怎么验证拉取的镜像是完整的
- 7hswish_hswish hsigmoid
- 8数据结构与算法(python实现)_数据结构与算法:python语言实现 pdf
- 9如何创建自己的 Spring Boot Starter 并为其编写单元测试
- 10python数组定义_数组真的只能从0开始吗?python表示不同意
稀疏表示分类(Sparse Representation for Classification,SRC)
赞
踩
稀疏表示分类(Sparse Representation for Classification,简称SRC)是一项在模式识别和信号处理中应用广泛的技术。它基于这样一个概念:一个信号(比如图像、语音等)可以用一个较大的字典中的一些基向量稀疏地表示。
想象一下,有一个巨大的图书馆(字典),其中每一本书(字典中的基向量)代表了一个特定的模式或特征。如果我们想描述或表达某种特定的信息(信号),在理想的情况下,我们只需要从这个图书馆中借几本相关的书就能够准确地表达出所需的信息。这表示我们使用了一种稀疏的方法,因为我们并没有需要整个图书馆的所有书,而只选择了一小部分。
在SRC中,这个“图书馆”包含了各种各样的features,这些features是从属于不同类别的训练样本中提取出来的。当我们遇到一个新的信号(比如一个待分类的图像)时,我们尝试使用图书馆中的所有书(整个字典)来表达这个新的信号。在最理想的状态下,新信号只会用它真正属于的类别中的一小部分书(即该类别下的训练样本)来表达自己,而其他的书(其他类别的特征)并不会被用到或者只会用到很少一部分。这种表达方式是稀疏的,因为它只涵盖了字典的一小部分。
流程
SRC的工作流程大致如下:
-
创建字典:首先需要一个字典,它由不同类别的训练样本组成。每个类别的样本都会贡献一些“书”,也就是这个大字典的一部分。
-
信号的稀疏表示:当我们有了一个新的信号,比如一个未知分类的图像时,我们尝试找出最少的字典元素,使得它们结合在一起可以近似这个新信号。
-
分类:根据这个新信号被表示的方式,我们检查使用的是哪一部分训练样本。我们假定如果大部分使用的训练样本来自某个特定的类别,那么未知信号最有可能属于这个类别。
SRC有许多实际应用,尤其是在面部识别领域效果显著。利用人脸图像构建字典,新的测试人脸图像通常可以很好地用同一个人的稀疏组合来表示,从而实现准确分类。
范例
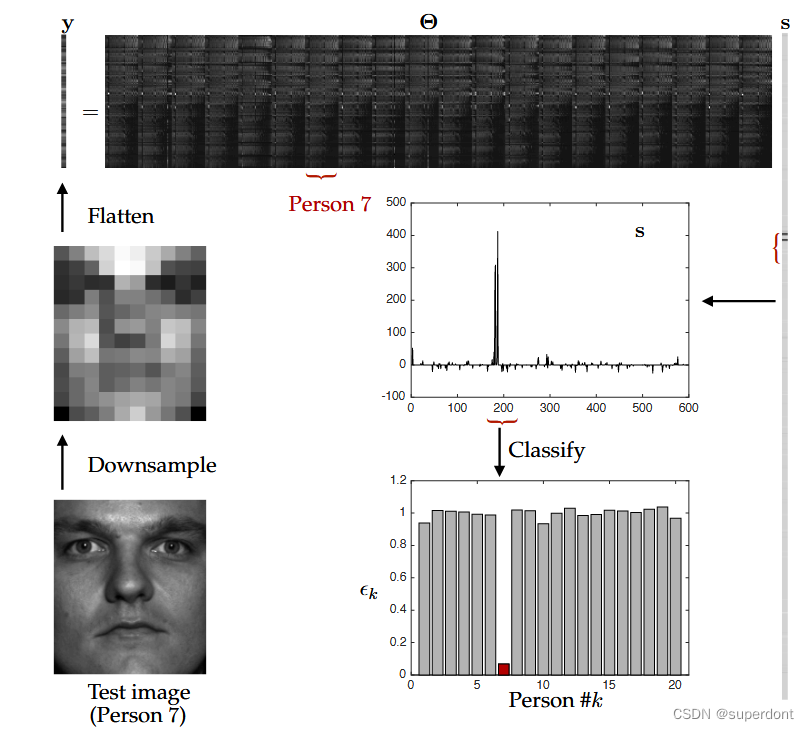
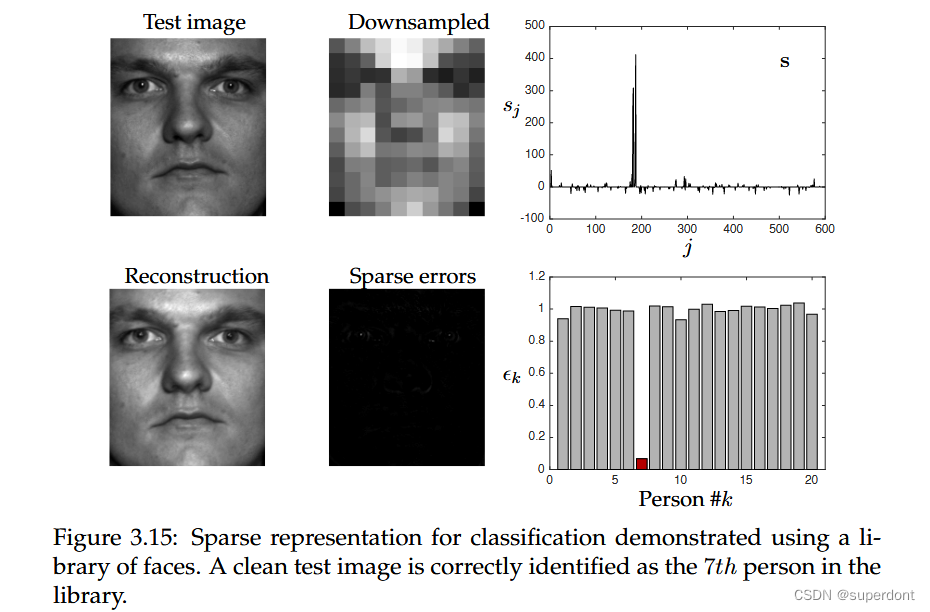
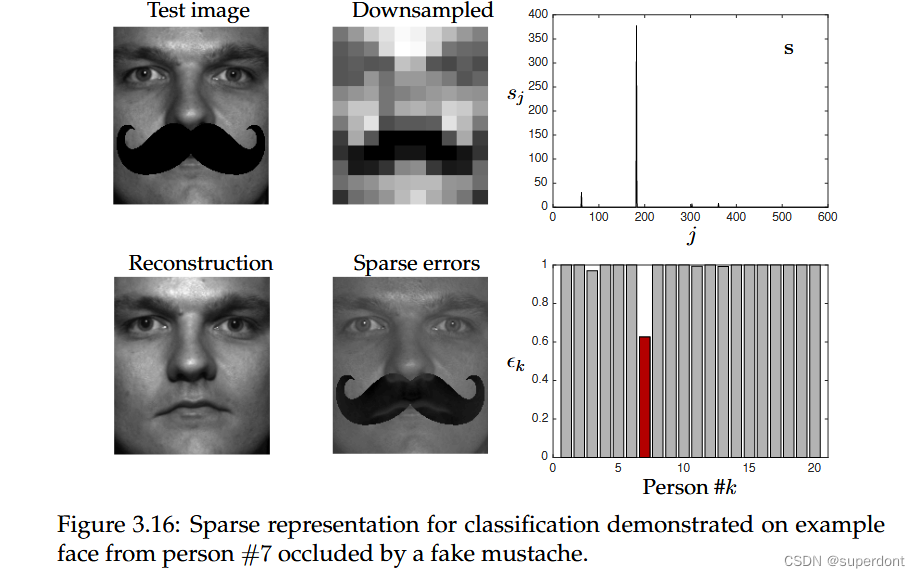
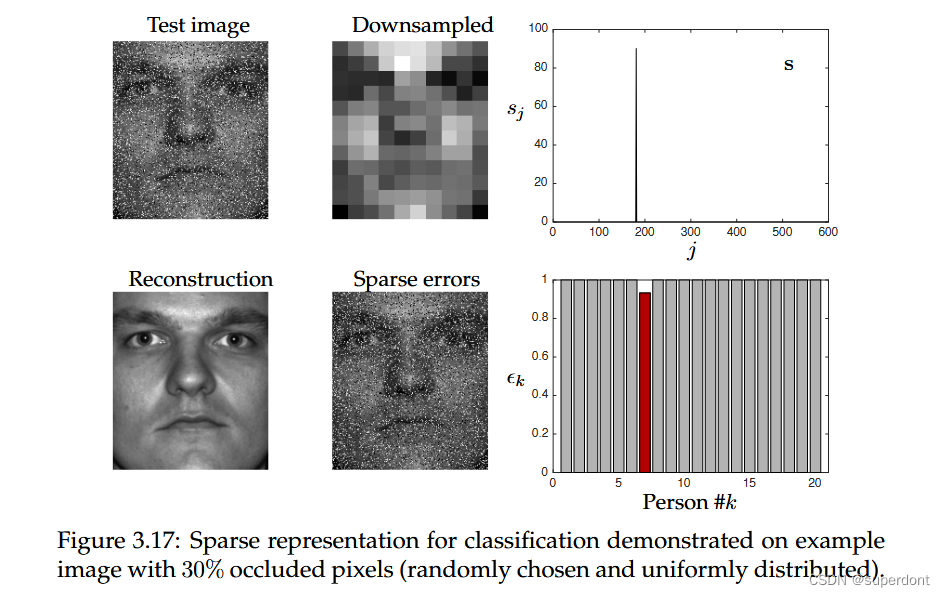
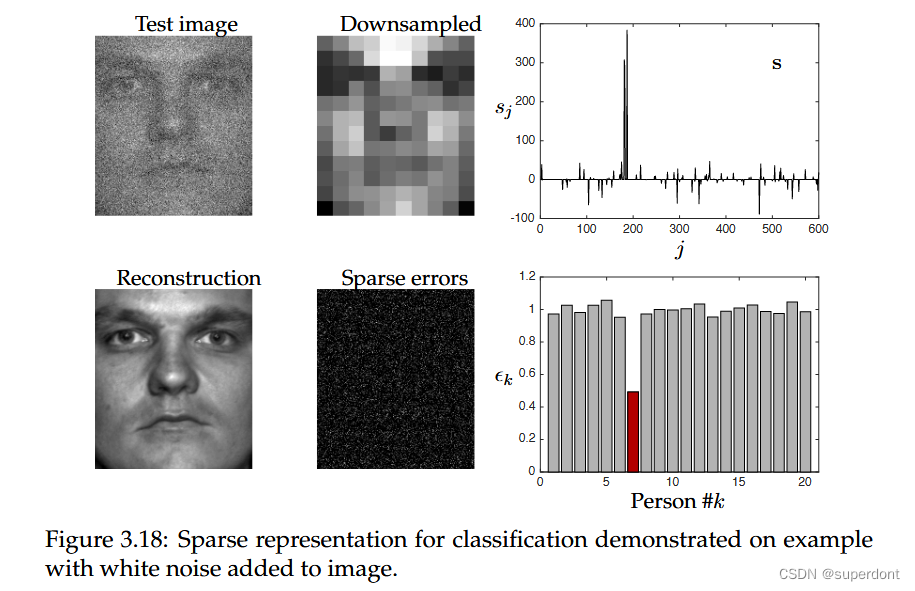
SRC的基本示意图如下图所示,其中使用人脸图像库构建过度完备的库Θ。在这个例子中,Yale B数据库中的每个20个不同人员中使用了30张图像,导致Θ中有600列。为了使用压缩感知,即1最小化,我们需要Θ欠定,因此我们将每个图像从192×168下采样到12×10,使得压缩后的图像变成了120维向量。下采样图像的算法对分类准确性产生影响。然后,与类别c对应的新测试图像y经过适当降采样以匹配Θ的列,然后使用压缩感知算法将其稀疏表示为Θ的列的和。得到的系数向量s应该是稀疏的,并且理想情况下主要在库中与类别c中正确人员对应的区域具有大系数。算法中的最终分类阶段是通过计算s向量中与每个类别分别对应的系数来实现的2重建误差。选择使2重建误差最小的类别作为测试图像的分类结果。
代码
Code 3.4: Load Yale faces data and build training and test sets.

Code 3.5: Downsample training images to build Θ library.

Code 3.6: Build test images and downsample to obtain y.

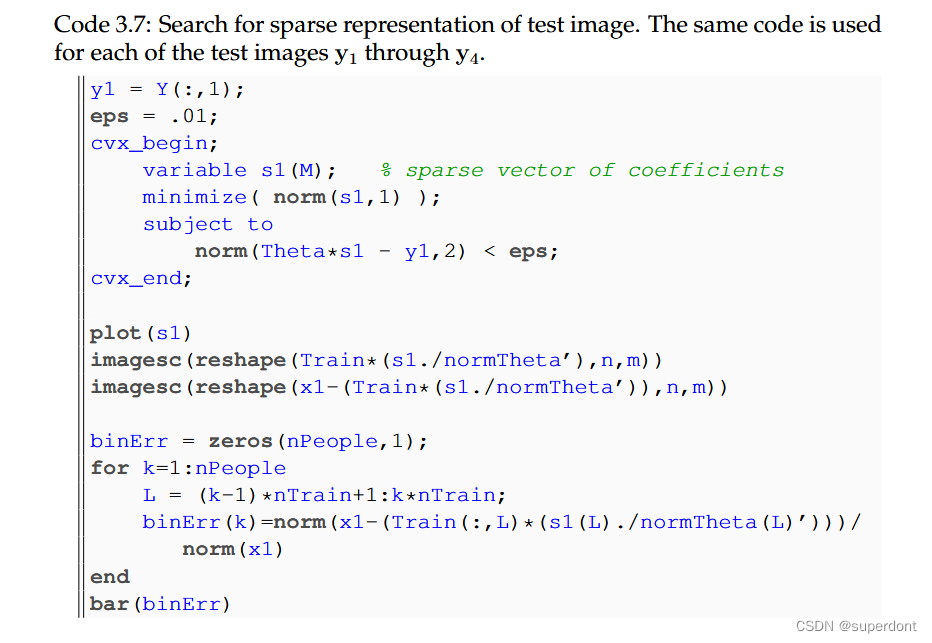
Code 3.7: Search for sparse representation of test image. The same code is used for each of the test images y1 through y4.
测试
参考文献

相关博文
我的图书
下面两本书欢迎大家参考学习。
OpenCV轻松入门
李立宗,OpenCV轻松入门,电子工业出版社,2023
本书基于面向 Python 的 OpenCV(OpenCV for Python),介绍了图像处理的方方面面。本书以 OpenCV 官方文档的知识脉络为主线,并对细节进行补充和说明。书中不仅介绍了 OpenCV 函数的使用方法,还介绍了函数实现的算法原理。
在介绍 OpenCV 函数的使用方法时,提供了大量的程序示例,并以循序渐进的方式展开。首先,直观地展示函数在易于观察的小数组上的使用方法、处理过程、运行结果,方便读者更深入地理解函数的原理、使用方法、运行机制、处理结果。在此基础上,进一步介绍如何更好地使用函数处理图像。在介绍具体的算法原理时,本书尽量使用通俗易懂的语言和贴近生活的实例来说明问题,避免使用过多复杂抽象的公式。
本书适合计算机视觉领域的初学者阅读,包括在校学生、教师、专业技术人员、图像处理爱好者。
本书第1版出版后,深受广大读者朋友的喜爱,被很多高校选为教材,目前已经累计重印9次。为了更好地方便大家学习,对本书进行了修订。

计算机视觉40例
李立宗,计算机视觉40例,电子工业出版社,2022
近年来,我深耕计算机视觉领域的课程研发工作,在该领域尤其是OpenCV-Python方面积累了一点儿经验。因此,我经常会收到该领域相关知识点的咨询,内容涵盖图像处理的基础知识、OpenCV工具的使用、深度学习的具体应用等多个方面。为了更好地把所积累的知识以图文的形式分享给大家,我将该领域内的知识点进行了系统的整理,编写了本书。希望本书的内容能够对大家在计算机视觉方向的学习有所帮助。
本书以OpenCV-Python(the Python API for OpenCV)为工具,以案例为载体,系统介绍了计算机视觉从入门到深度学习的相关知识点。
本书从计算机视觉基础、经典案例、机器学习、深度学习、人脸识别应用等五个方面对计算机视觉的相关知识点做了全面、系统、深入的介绍。书中共介绍了40余个经典的计算机视觉案例,其中既有字符识别、信息加密、指纹识别、车牌识别、次品检测等计算机视觉的经典案例,也包含图像分类、目标检测、语义分割、实例分割、风格迁移、姿势识别等基于深度学习的计算机视觉案例,还包括表情识别、驾驶员疲劳监测、易容术、识别年龄和性别等针对人脸的应用案例。
在介绍具体的算法原理时,本书尽量使用通俗易懂的语言和贴近生活的示例来说明问题,避免使用复杂抽象的公式来介绍。
本书适合计算机视觉领域的初学者阅读,适于在校学生、教师、专业技术人员、图像处理爱好者使用。


