
- 1java获取系统CPU和内存使用率的三种方法_oshi获取cpu使用率
- 2LLC谐振电路(二) 同步整流技术_llc同步整流的工作原理
- 3海洋信息处理-非合作水声通信信号检测及识别_水声通信传输速率测试
- 4得到输入内容的首字母
- 5说说 Spring 定时任务如何大规模企业级运用_spring-scheme.xml 定时任务太多
- 6深入理解Java虚拟机(第三版)-- 虚拟机中的对象_吴声子夜歌 java
- 7数据结构---堆
- 8java to_date(),to_char() 转换函数
- 9VSAN存储磁盘空间回收_vmfs5和vmfs6区别
- 10单片机(STM32,GD32,NXP等)中BootLoader的严谨实现详解_单片bootloader实现
OpenTelemetry 和 Elastic:共同努力为社区建立持续的性能分析
赞
踩
作者:来自 Elastic Israel Ogbole, Alexander Wert, Tim Rühsen

性能分析(profiling)正在成为可观察性的核心支柱,被恰当地称为第四支柱,OpenTelemetry (OTel) 项目引领了这一重要的发展。 这篇博文深入探讨了 OTel 中性能分析方面的最新进展以及 Elastic® 如何积极为此做出贡献。
在 Elastic,我们是 OpenTelemetry 项目的坚定支持者和贡献者。 该项目的灵活性、性能和供应商不可知论的优势已经显现出来; 我们看到客户兴趣高涨。
为此,在捐赠我们的 Elastic Common Schema 和基于 invokedynamic 的 java 代理方法之后,我们最近宣布打算捐赠我们的连续性能分析代理 - 一个全系统、始终在线的连续分析解决方案,无需运行时 /字节码检测、重新编译、主机上调试符号或服务重新启动。
性能分析可以通过最大限度地减少计算浪费来帮助组织运行高效的服务,从而降低运营成本。 利用 eBPF,Elastic 分析代理为所有应用程序的运行时行为提供了前所未有的可见性:它构建从内核到用户空间本机代码,一直到在更高级别运行时运行的代码的堆栈跟踪,使你能够识别性能回归, 减少浪费的计算,并更快地调试复杂问题。
在 OpenTelemetry 中启用分析:迈向统一可观察性的一步
Elastic 积极参与 OTel 社区,特别是在 Profiling Special Interest Group (SIG) 内。 该小组在定义 OTel 性能分析数据模型方面发挥了重要作用,这是标准化分析数据的关键一步。
最近合并的 OpenTelemetry 增强提案 (OTEP) 引入了对 OpenTelemetry 协议 (OTLP) 的分析支持,这标志着一个重要的里程碑。 通过将配置文件标准化与指标、跟踪和日志一起作为核心可观察性支柱,OTel 提供了一整套可观察性工具,使用户能够全面了解其应用程序的运行状况和性能。
为了配合这一进展,我们将基于 eBPF 的全系统连续性能分析代理捐赠给 OTel。 与此同时,我们正在性能分析代理中实施实验性 OTel 分析信号,以确保和演示代理中的 OTel 协议兼容性,并为完全基于 OTel 的分析信号集合做好准备,并将其与日志、指标和跟踪相关联。
为什么 Elastic 将基于 eBPF 的分析代理捐赠给 OpenTelemetry?
计算效率一直是软件专业人员最关心的问题。 然而,在每一行代码都影响底线和环境的时代,还有一个值得关注的理由。 Elastic 致力于帮助 OpenTelemetry 社区提高计算效率,因为高效的软件不仅可以降低销售成本 (COGS),还可以减少碳足迹。
我们从内部和客户的评价中亲眼目睹了分析见解如何帮助提高软件效率。 这可以改善客户体验、降低资源消耗并降低云成本。

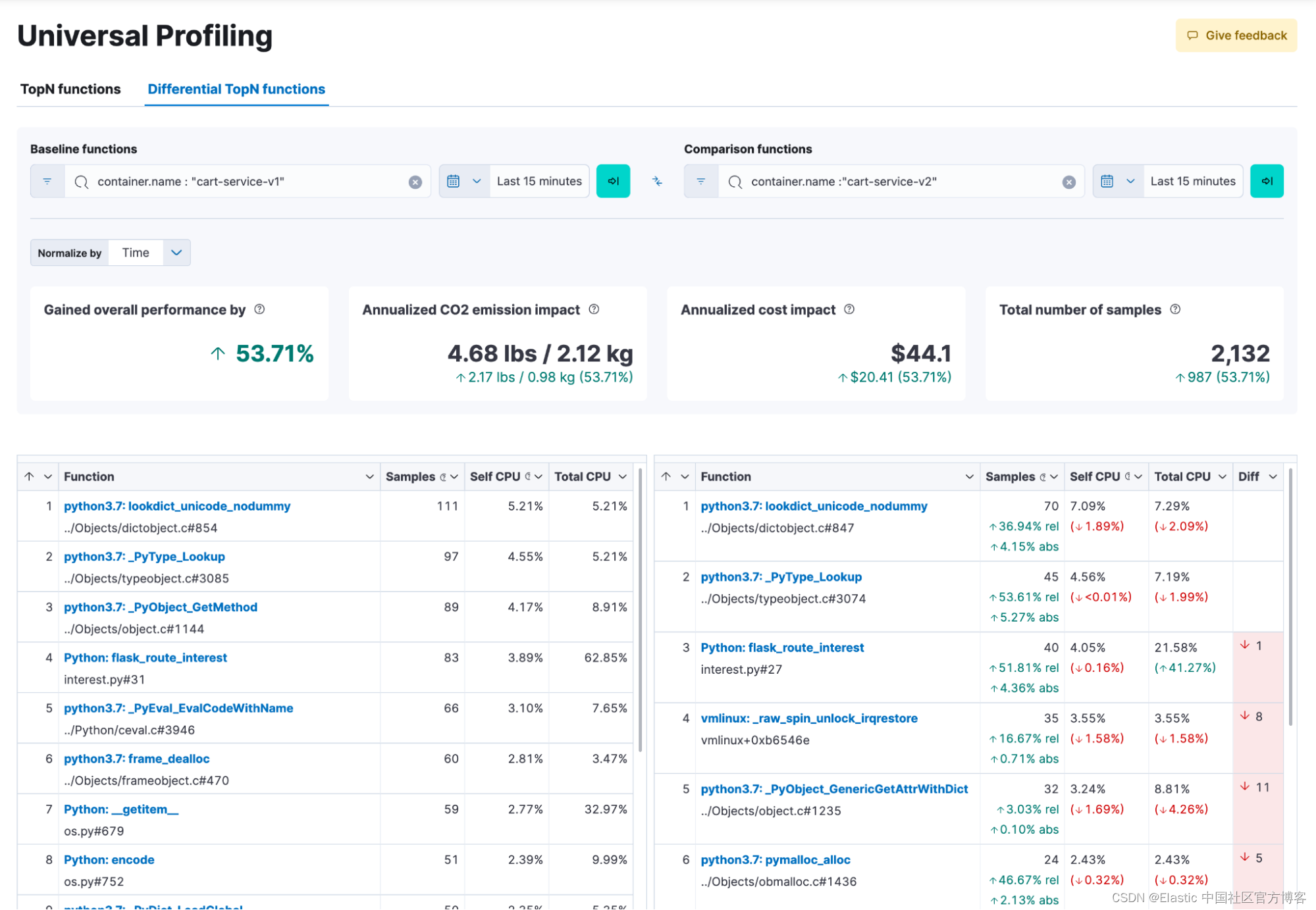
此外,采用全系统性能分析策略(例如 Elastic Universal Profiling)与仅关注运行时的传统仪器分析器有很大不同。 Elastic Universal Profiling 提供整个系统的可见性,不仅可以分析你自己的代码,还可以分析第三方库、内核操作和你不拥有的其他代码。 这种综合方法通过识别非最佳公共库并发现消耗 CPU 周期的 “未知的未知因素(unknown unknowns)” 来促进快速优化。 通常,当库或某些守护进程的资源消耗超过应用程序本身的资源消耗时,就会达到临界点。 如果没有系统范围的分析,以及按服务切片数据和聚合总使用量的功能,精确定位这些资源密集型组件将成为一项艰巨的挑战。
在 Elastic,我们有一个拥有广泛云基础设施的客户,他计划与其云提供商协商,为云提供商的虚拟机内代理消耗的大量计算资源收回资金。 这些示例强调了整个系统性能分析的重要性以及如果捐赠提案被接受,OpenTelemetry 社区将获得的好处。
具体来说,OTel 用户将获得一个轻量级、经过实战测试的生产级连续性能分析代理,具有以下功能:
- 非常低的 CPU 和内存开销(1% CPU 和 250MB 内存是我们测试的上限,代理通常设法保持低于该上限)
- 通过利用 .eh_frame 数据支持本机 C/C++ 可执行文件,无需 DWARF 调试信息,如 “通用分析如何在没有帧指针和符号的情况下展开堆栈” 中所述
- 支持在主机上没有帧指针和调试符号的情况下对系统库进行性能分析
- 支持运行时之间的混合堆栈跟踪 - 堆栈跟踪从内核空间通过未修改的系统库一直到高级语言
- 支持本机代码(C/C++、Rust、Zig、Go 等,主机上没有调试符号)
- 支持广泛的高级语言(Hotspot JVM、Python、Ruby、PHP、Node.JS、V8、Perl),.NET 正在准备中
- 100% 非侵入式:无需将代理或库加载到正在分析的进程中
- 无需重新配置、检测或重新启动 HLL 解释器和 VM:代理支持在默认配置中展开每种受支持的语言
- 支持 x86 和 Arm64 CPU 架构
- 支持本机内联框架,可深入了解编译器优化并提供更高精度的函数调用链
- 支持概率分析以降低数据存储成本
- 。 。 。 和更多
Elastic 对提高计算效率的承诺以及我们对 OpenTelemetry 愿景的信念强调了我们致力于通过捐赠分析代理来推进可观察性生态系统。 Elastic 不仅贡献技术,还专门组建了一支由专业分析领域专家组成的团队来共同维护和推进 OpenTelemetry 中的性能分析功能。
这个捐赠对 OTel 社区有何裨益?
指标、日志和跟踪为系统健康状况提供了宝贵的见解。 但如果你可以解锁更深层次的可见性呢? 这就是为什么分析是对 OTel 工具包的完美补充:
1. 深入的系统可见性:超越表面
把全系统性能分析想象成对你的系统群的 MRI 扫描。它深入到系统内部,揭示了潜藏在表面下的隐藏性能问题。你可以识别出 “未知的未知” —— 否则你可能不会注意到的低效问题 —— 并全面了解你的系统在其核心如何运作。
2. 跨信号相关性:自信地回答 “为什么”
Elastic Universal Profiling 代理支持与 OTel Java agent/SDK 的跟踪关联(Go 支持即将推出!)。 这种相关性使 OTel 用户能够按服务或服务端点查看分析数据,从而进行更加上下文感知和有针对性的根本原因分析。 这种强大的组合使你能够在跟踪级别查明资源消耗的确切原因。 不再需要猜测为什么特定功能会占用 CPU 或为什么会发生某些事件。 你最终可以准确回答关键的 “为什么” 问题,从而实现有针对性的优化工作。
3. 成本和可持续性优化:超越性能
我们的分析方法不仅仅是性能提升。 通过将整个系统分析数据与跟踪相关联,我们可以帮助你衡量与应用程序中特定服务和功能相关的环境影响和云成本。 这使你能够做出数据驱动的决策,优化性能和资源利用率,从而实现更可持续和更具成本效益的运营。
Elastic 对 OpenTelemetry 的承诺
Elastic 目前支持越来越多的云原生计算基金会 (CNCF) 项目,例如 Kubernetes (K8S)、Prometheus、Fluentd、Fluent Bit 和 Istio。 Elastic 的应用程序性能监控 (APM)本身也支持 OTel,确保所有 APM 功能均可通过 Elastic 或 OTel 代理或两者的组合使用。 除了 ECS 贡献以及与 OTel SemConv 的持续合作之外,Elastic 还继续为其他 OTel 项目做出贡献,包括语言 SDK(例如 OTel Swift、OTel Go、OTel Ruby 等),并参与多个特殊兴趣小组 (special interest groups - SIG) 将 OTel 建立为可观察性和安全性的标准。
我们很高兴能够加强与 OTel 的关系,并有机会以有利于 Elastic 社区和更广泛的 OTel 社区的方式捐赠我们的分析代理。了解有关 Elastic 的 OpenTelemetry 支持的更多信息,或者为捐赠提案做出贡献,或者只是加入对话。
随着 OTel 分析部分的不断发展,请继续关注进一步的更新。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付

