
- 1大型语言模型(LLM)技术精要_首创将大语言模型(llm)技术引入静态白盒检测场景,进一步降低了白盒测试的误报率,
- 2Harmony OS 父子组件传参_鸿蒙 组件传参
- 3AKShare 快速入门
- 4Spring Boot 与 Spring Security_springboot springsecurity
- 5python--素数求和_python判断素数相加
- 6IP如何异地共享文件?
- 7Java System#exit 无法退出程序的问题探索_system.exit(-1)进程未退出
- 8鸿蒙入门开发教程:一文带你详解工具箱元服务的开发流程_鸿蒙元服务预加载
- 9Java面试八股文整理
- 10详细教程 - 进阶版 鸿蒙harmonyOS应用 第十七节——鸿蒙OS多线程编程指南_鸿蒙 多线程
爬取Leetcode的每日一题(Java/Python)_leetcode抓取报文
赞
踩
抓取Leetcode的每日一题信息
思路一(发送GraphQL Query获取数据)
参考文章:https://www.cnblogs.com/ZhaoxiCheung/p/9333476.html
接口分析
主要的数据存在于graphql/接口中:
https://leetcode-cn.com/graphql/
首页热门题目接口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h9MMB12p-1635930652410)(https://raw.githubusercontent.com/Onion224/Images/main/image-20211102110733963.png)]](https://img-blog.csdnimg.cn/b601405a9dbd42a18e15b5d826a5b0f7.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
是否AC状态查看接口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q9DjbTN8-1635930510523)(https://raw.githubusercontent.com/Onion224/Images/main/image-20211102111011935.png)]](https://img-blog.csdnimg.cn/eb12516376584a2c9fb4cb74f69b9843.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
每日一题接口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yDbqPi7f-1635930510526)(https://raw.githubusercontent.com/Onion224/Images/main/image-20211102111325460.png)]](https://img-blog.csdnimg.cn/35796e9733004e879a317674b18d330f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
构造 GraphQL Query来获取信息
在Headers下的Request Payload中我们可以看到一个query字段,这是我们要构造的 GraphQL Query 的一个重要信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iWWzhSM2-1635930510538)(https://raw.githubusercontent.com/Onion224/Images/main/image-20211102112407407.png)]](https://img-blog.csdnimg.cn/fbb85f42017e4273993403bc86056ceb.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
利用Postman来分析接口
我们并不一开始就用代码来获取题目信息,而是先利用 Postman 来看看如何获取题目信息。右键 Network 下的 graphql 文件—>Copy—>Copy as cURL(bash)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o70pdG2R-1635930510541)(https://raw.githubusercontent.com/Onion224/Images/main/885804-20180719232607953-589650086.png)]](https://img-blog.csdnimg.cn/7b2840a2064d4a64b75be135a5383288.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
接着我们打开Postman,点击左上角File里的import,然后找到Raw text栏
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YaRVKe0n-1635930510544)(https://raw.githubusercontent.com/Onion224/Images/main/image-20211102113235146.png)]](https://img-blog.csdnimg.cn/f13b81d45d9e402889a10bff09cfae18.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
将copy下来的cURL粘贴到Raw text中,点击continue,就可以在Postman中查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QyAWzGxH-1635930510546)(C:\Users\12526\AppData\Roaming\Typora\typora-user-images\image-20211102114157857.png)]](https://img-blog.csdnimg.cn/976c708f9ee0486f87cc4c71944f39ca.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
在这之前遇到了一个小问题,把copy all as cURL看成了copy as cURL,导致在Postman中解析错误。
curl解析的结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U6cWusjg-1635930510548)(C:\Users\12526\AppData\Roaming\Typora\typora-user-images\image-20211102114326263.png)]](https://img-blog.csdnimg.cn/8bd00627d8da413bbfc8161d6cba718d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pWy5Luj56CB55qE5rSL6JGx5aS0,size_20,color_FFFFFF,t_70,g_se,x_16)
从解析的结果看,和我们在Headers中看到的query字段类似,不过有一些细节需要更改。
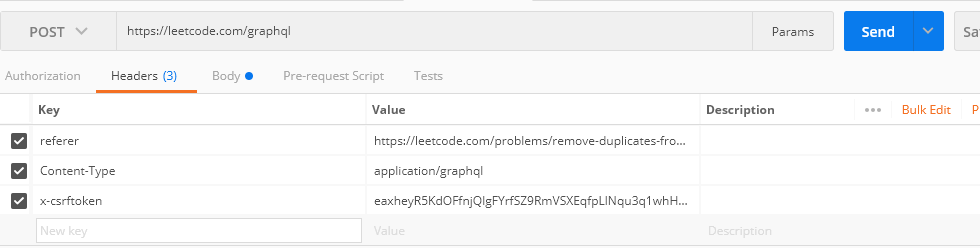
当然,如果不想直接粘贴复制的 cURL,那么我们可以自己在 Postman 中写 Header 和 Body,需要注意的是这边的 Content-Type是application/graphql,Body 中的 GraphQL 构造,参照 Request Payload 中的query的字段来构造
利用Java的Jsoup和okhttp库来发送http请求和解析Json数据
package com.example.leetcode_card.utils; import com.alibaba.fastjson.JSONObject; import okhttp3.*; import org.jsoup.Connection; import org.jsoup.Jsoup; import java.io.IOException; import java.util.Map; import java.util.Objects; public class GraphqlUtil { private static String BASE_URL = "https://leetcode-cn.com"; private static String questionUrl = "https://leetcode-cn.com/problems/two-sum/description/"; private static String GRAPHQL_URL = "https://leetcode-cn.com/graphql"; public GraphqlUtil() { } public static String getContent(String title) throws IOException { Connection.Response response = Jsoup.connect(questionUrl) .method(Connection.Method.GET) .execute(); String csrftoken = response.cookie("aliyungf_tc"); String __cfduid = response.cookie("__cfduid"); OkHttpClient client = new OkHttpClient.Builder() .followRedirects(false) .followSslRedirects(false) .build(); String query = "query{ question(titleSlug:\"%s\") { questionId translatedTitle translatedContent difficulty } }"; String postBody = String.format(query,title); assert csrftoken != null; Request request = new Request.Builder() .addHeader("Content-Type","application/graphql") .addHeader("Referer",questionUrl) .addHeader("Cookie","__cfduid=" + __cfduid + ";" + "csrftoken=" + csrftoken) .addHeader("x-csrftoken",csrftoken) .url(GRAPHQL_URL) .post(RequestBody.create(MediaType.parse("application/graphql; charset=utf-8"),postBody)) .build(); Response response1 = client.newCall(request).execute(); //由于json的原因,返回的数据中文变成了Unicode码,需要另外解码 return unicodetoString(response1.body().string()); } //获取每日一题的题目内容(英文),用来构建完整的请求API public static String getTitle() throws IOException { Connection.Response response = Jsoup.connect(questionUrl) .method(Connection.Method.GET) .execute(); String csrftoken = response.cookie("aliyungf_tc"); String __cfduid = response.cookie("__cfduid"); OkHttpClient client = new OkHttpClient.Builder() .followRedirects(false) .followSslRedirects(false) .build(); // 获取LeetCode题目标题时的查询字符串 String postBody = "query questionOfToday { todayRecord { question { questionFrontendId questionTitleSlug __typename } lastSubmission { id __typename } date userStatus __typename }}"; assert csrftoken != null; Request request = new Request.Builder() .addHeader("Content-Type","application/graphql") .addHeader("Referer",questionUrl) .addHeader("Cookie","__cfduid=" + __cfduid + ";" + "csrftoken=" + csrftoken) .addHeader("x-csrftoken",csrftoken) .url(GRAPHQL_URL) .post(RequestBody.create(MediaType.parse("application/graphql; charset=utf-8"),postBody)) .build(); Response response1 = client.newCall(request).execute(); String titleInfo = unicodetoString(response1.body().string()); //将title解析出来 JSONObject jsonObject = JSONObject.parseObject(titleInfo); return jsonObject.getJSONObject("data") .getJSONArray("todayRecord") .getJSONObject(0) .getJSONObject("question") .getString("questionTitleSlug"); } //解码 public static String unicodetoString(String unicode) { if (unicode == null || "".equals(unicode)) { return null; } StringBuilder sb = new StringBuilder(); int i = -1; int pos = 0; while ((i = unicode.indexOf("\\u", pos)) != -1) { sb.append(unicode.substring(pos, i)); if (i + 5 < unicode.length()) { pos = i + 6; sb.append((char) Integer.parseInt(unicode.substring(i + 2, i + 6), 16)); } } sb.append(unicode.substring(pos)); return sb.toString(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
引入的maven库:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>LeetcodeSpider</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.14.3</version> </dependency> <!-- https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp --> <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.9.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.12</version> </dependency> <!-- https://mvnrepository.com/artifact/top.jfunc.common/converter --> <dependency> <groupId>top.jfunc.common</groupId> <artifactId>converter</artifactId> <version>1.8.0</version> </dependency> </dependencies> </project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
思路二(利用python爬虫爬取GraphQL接口)
参考文章:https://blog.csdn.net/malloc_can/article/details/113004579
# coding=<encoding name> : # coding=utf-8 from datetime import datetime import requests import json import smtplib from email.mime.text import MIMEText base_url = 'https://leetcode-cn.com' # 获取今日每日一题的题名(英文) response = requests.post(base_url + "/graphql", json={ "operationName": "questionOfToday", "variables": {}, "query": "query questionOfToday { todayRecord { question { questionFrontendId questionTitleSlug __typename } lastSubmission { id __typename } date userStatus __typename }}" }) leetcodeTitle = json.loads(response.text).get('data').get('todayRecord')[0].get("question").get('questionTitleSlug') # 获取今日每日一题的所有信息 url = base_url + "/problems/" + leetcodeTitle response = requests.post(base_url + "/graphql", json={"operationName": "questionData", "variables": {"titleSlug": leetcodeTitle}, "query": "query questionData($titleSlug: String!) { question(titleSlug: $titleSlug) { questionId questionFrontendId boundTopicId title titleSlug content translatedTitle translatedContent isPaidOnly difficulty likes dislikes isLiked similarQuestions contributors { username profileUrl avatarUrl __typename } langToValidPlayground topicTags { name slug translatedName __typename } companyTagStats codeSnippets { lang langSlug code __typename } stats hints solution { id canSeeDetail __typename } status sampleTestCase metaData judgerAvailable judgeType mysqlSchemas enableRunCode envInfo book { id bookName pressName source shortDescription fullDescription bookImgUrl pressImgUrl productUrl __typename } isSubscribed isDailyQuestion dailyRecordStatus editorType ugcQuestionId style __typename }}"}) # 转化成json格式 jsonText = json.loads(response.text).get('data').get("question") # 题目题号 no = jsonText.get('questionFrontendId') # 题名(中文) leetcodeTitle = jsonText.get('translatedTitle') # 题目难度级别 level = jsonText.get('difficulty') # 题目内容 context = jsonText.get('translatedContent') # print(leetcodeTitle) # print(context) # print(level) # print(no) # 早安语录接口(天行数据API,自行申请免费)) response = requests.get("") json = json.loads(response.text) # 得到语录数据 ana = json.get('newslist')[0].get('content') # 表情链接 face_url = 'http://wx3.sinaimg.cn/large/007hyfXLly1g0uj7x5jpaj301o02a0sw.jpg' # 开始运行时间(可通过配置文件解耦) begin_time = datetime(2020, 12, 23) # 脚本运行时间计算 info = "<span style='color:cornflowerblue'>本脚本已运行{0}天<span>".format( (datetime.today() - begin_time).days.__str__()) # 数据全部HTML化 htmlText = """ <head> <meta charset=UTF-8> <link rel="stylesheet"> <style> code { color: blue; font-size: larger; } </style> </link> </head> <body> <div> </B><BR></B><FONT style="FONT-SIZE: 12pt; FILTER: shadow(color=#af2dco); WIDTH: 100%; COLOR: #730404; LINE-HEIGHT: 100%; FONT-FAMILY: 华文行楷" size=6><span style="COLOR: cornflowerblue">早安语录:</span>""" + ana + """</FONT><img width="40px" src=""" + face_url + """"> <div> <h3>Leetcode-每日一题</h3> <h4>""" + no + '.' + leetcodeTitle + '.' + level + """</h4>""" + context + '本题连接:<a href=' + url + ">" + url + "</a></div>" + info
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
文章内容仅限用于学习,文章未经允许,禁止转载。


