
- 1中文命名实体识别:基于PyTorch的多模型中文命名实体识别
- 2工作一到五年的Java程序员该如何提升自己?_java程序员自我提升 site:csdn.net
- 3英特尔开发套件“哪吒”快速部署YoloV8 on Java_英特尔哪吒
- 4Sysbench 性能测试(小白快速上手)_sysbench测试fileio
- 5【int与char的配对】D. Blue-Red Permutation_int 和char组合
- 6小波变换(DWT),短时傅里叶分析(STFT),与快速傅里叶(FFT)之间的关系_短时傅里叶变换和快速傅里叶变换
- 7Android-JNI开发系列《四》Native-Crash定位_[erecovery]readevent: ereceventmanager readevent 0
- 8用python调用VideoReTalking实现电影后期制作
- 9《springboot中实现excel表格导出》_springboot导出excel
- 10教育的未来已来!AIGC如何全方位助力教师开启全新教学体验?_aigc for 教育
RNN在自然语言处理中的应用及其PyTorch实现_rnn自然语言预测
赞
踩
作者:廖星宇
本文节选自《深度学习入门之PyTorch》,本书从人工智能的介绍入手,了解机器学习和深度学习的基础理论,并学习如何用PyTorch框架对模型进行搭建。
对于人类而言,以前见过的事物会在脑海里面留下记忆,虽然随后记忆会慢慢消失,但是每当经过提醒,人们往往能够重拾记忆。在神经网络的研究中,让模型充满记忆力的研究很早便开始了,Saratha Sathasivam 于1982 年提出了霍普菲尔德网络,但是由于它实现困难,在提出的时候也没有很好的应用场景,所以逐渐被遗忘。深度学习的兴起又让人们重新开始研究循环神经网络(Recurrent Neural Network),并在序列问题和自然语言处理等领域取得很大的成功。
本文将从循环神经网络的基本结构出发,介绍RNN在自然语言处理中的应用及其PyTorch 实现。
循环神经网络
前一章介绍了卷积神经网络,卷积神经网络相当于人类的视觉,但是它并没有记忆能力,所以它只能处理一种特定的视觉任务,没办法根据以前的记忆来处理新的任务。那么记忆力对于网络而言到底是不是必要的呢?很显然在某些问题上是必要的,比如,在一场电影中推断下一个时间点的场景,这个时候仅依赖于现在的情景并不够,需要依赖于前面发生的情节。对于这样一些不仅依赖于当前情况,还依赖于过去情况的问题,传统的神经网络结构无法很好地处理,所以基于记忆的网络模型是必不可少的。
循环神经网络的提出便是基于记忆模型的想法,期望网络能够记住前面出现的特征,并依据特征推断后面的结果,而且整体的网络结构不断循环,因为得名循环神经
网络。
循环神经网络的基本结构
循环神经网络的基本结构特别简单,就是将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。使用一个简单的两层网络作为示范,在它的基础上扩充为循环神经网络的结构,我们用图1简单地表示。
可以看到网络在输入的时候会联合记忆单元一起作为输入,网络不仅输出结果,还会将结果保存到记忆单元中,图1就是一个最简单的循环神经网络在一次输入时的结构示意图。
输入序列的顺序改变, 会改变网络的输出结果,这是因为记忆单元的存在,使得两个序列在顺序改变之后记忆单元中的元素也改变了,所以会影响最终的输出结果。
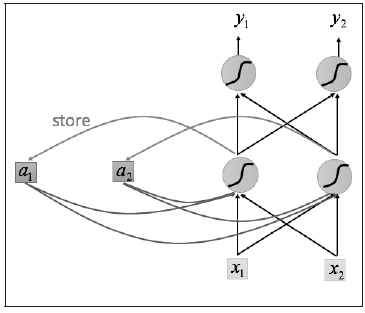
图1是序列中一个数据点传入网络的示意图,那么整个序列如何传入网络呢?将序列中的每个数据点依次传入网络即可,如图2所示。
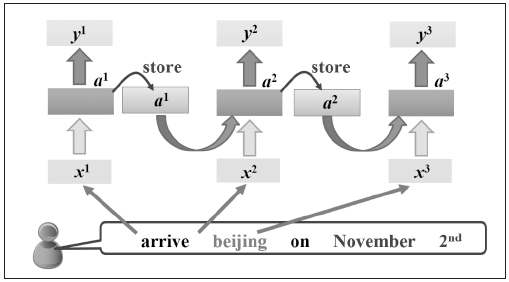
无论序列有多长,都能不断输入网络,最终得到结果。可能看到这里,读者会有一些疑问,图2中每一个网络是不是都是独立的权重?对于这个问题,先考虑一下如果是不同的序列,那么图2 中格子的数目就是不同的,对于一个网络结构,不太可能出现这种参数数目变化的情况。
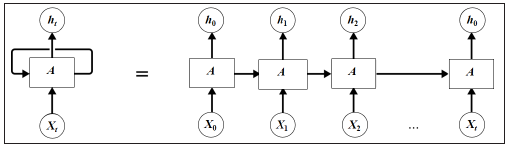
事实上,这里再次使用了参数共享的概念,也就是说虽然上面有三个格子,其实它们都是同一个格子,而网络的输出依赖于输入和记忆单元,可以用图5.5表示。
如图5.5所示,左边就是循环神经网络实际的网络流,右边是将其展开的结果,可以看到网络中具有循环结构,这也是循环神经网络名字的由来。同时根据循环神经网络的结构也可以看出它在处理序列类型的数据上具有天然的优势,因为网络本身就是一个序列结构,这也是所有循环神经网络最本质的结构。
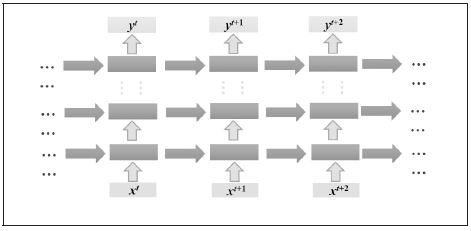
循环神经网络也可以有很深的网络层结构,如图4所示。
可以看到网络是单方向的,这代表网络只能知道单侧的信息,有的时候序列的信息不只是单边有用,双边的信息对预测结果也很重要,比如语音信号,这时候就需要看到两侧信息的循环神经网络结构。这并不需要用两个循环神经网络分别从左右两边开始读取序列输入,使用一个双向的循环神经网络就能完成这个任务,如图5所示。
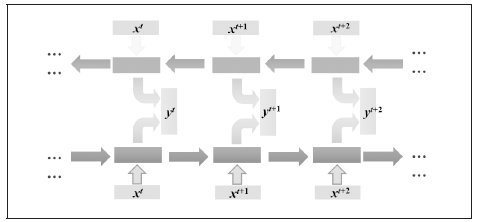
使用双向循环神经网络,网络会先从序列的正方向读取数据,再从反方向读取数据,最后将网络输出的两种结果合在一起形成网络的最终输出结果。
自然语言处理的应用
循环神经网络目前在自然语言处理中应用最为火热,所以这一小节将介绍自然语言处理中如何使用循环神经网络。
词嵌入
首先介绍自然语言处理中的第一个概念——词嵌入(word embedding),也可以称为词向量。
图像分类问题会使用one-hot 编码,比如一共有五类,那么属于第二类的话,它的编码就是(0, 1, 0, 0, 0),对于分类问题,这样当然特别简明。但是在自然语言处理中,因为单词的数目过多,这样做就行不通了,比如有10000 个不同的词,那么使用one-hot这样的方式来定义,效率就特别低,每个单词都是10000 维的向量,其中只有一位是1,其余都是0,特别占用内存。除此之外,也不能体现单词的词性,因为每一个单词都是one-hot,虽然有些单词在语义上会更加接近,但是one-hot 没办法体现这个特点,所以必须使用另外一种方式定义每一个单词,这就引出了词嵌入。
词嵌入到底是什么意思呢?其实很简单,对于每个词,可以使用一个高维向量去表示它,这里的高维向量和one-hot 的区别在于,这个向量不再是0 和1 的形式,向量的每一位都是一些实数,而这些实数隐含着这个单词的某种属性。这样解释可能不太直观,先举四个例子,下面有4 段话:
(1)The cat likes playing ball.
(2)The kitty likes playing wool.
(3)The dog likes playing ball.
(4)The boy likes playing ball.
重点分析里面的4 个词,cat、kitty、dog 和boy。如果使用one-hot,那么cat 就可以表示成(1, 0, 0, 0),kitty 就可以表示成(0, 1, 0, 0),但是cat 和kitty 其实都表示小猫,所以这两个词语义是接近的,但是one-hot 并不能体现这个特点。
下面使用词嵌入的方式来表示这4 个词,假如使用一个二维向量(a, b) 来表示一个词,其中a,b 分别代表这个词的一种属性,比如a 代表是否喜欢玩球,b 代表是否喜欢玩毛线,并且这个数值越大表示越喜欢,这样就能够定义每一个词的词嵌入,并且通过这个来区分语义,下面来解释一下原因。
对于cat,可以定义它的词嵌入是(-1, 4),因为它不喜欢玩球,喜欢玩毛线;而对于kitty,它的词嵌入可以定义为(-2, 5);那么对于dog,它的词嵌入就是(3, -2),因为它喜欢玩球,不喜欢玩毛线;最后对于boy,它的词向量就是(-2, -3),因为这两样东西他都不喜欢。定义好了这样的词嵌入,怎么去定义它们之间的语义相似度呢?可以通过词向量之间的夹角来定义它们的相似度。下面先将每个词向量都在坐标系中表示出来,如图6所示。
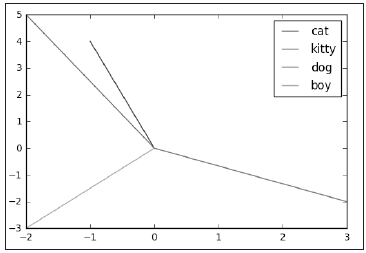
图6 就显示出了不同词向量之间的夹角,可以发现kitty 和cat 的夹角更小,所以它们更加相似的,而dog 和boy 之间夹角很大,所以它们不相似。
通过这样一个简单的例子能够看出词嵌入对于单词的表示具有很好的优势,但是问题来了,对于一个词,怎么知道如何去定义它的词嵌入?如果向量的维数只有5 维,可能还能定义出来,如果向量的维数是100 维,那么怎么知道每一维体是多少呢?
这个问题可以交给神经网络去解决,只需要定义我们想要的维度,比如100 维,神经网络就会自己去更新每个词嵌入中的元素。而之前介绍过词嵌入的每个元素表示一种属性,当然对于维数比较低的时候,可能我们能够推断出每一维具体的属性含义,然而维度比较高之后,我们并不需要关心每一维到底代表着什么含义,因为每一维都是网络自己学习出来的属性,只需要知道词向量的夹角越小,表示它们之间的语义更加接近就可以了。这就好比卷积网络会对一张图片提取出很厚的特征图,并不需要关心网络提取出来的特征到底是什么,只需要知道抽象的特征能够帮助我们分类图像就可以了。
词嵌入的PyTorch 实现
词嵌入在PyTorch 中是如何实现的呢?下面来具体实现一下。
PyTorch 中的词嵌入是通过函数nn.Embedding(m, n) 来实现的,其中m 表示所有的单词数目,n 表示词嵌入的维度,下面举一个例子:
1 word_to_ix = {'hello': 0, 'world': 1}
2 embeds = nn.Embedding(2, 5)
3 hello_idx = torch.LongTensor([word_to_ix['hello']])
4 hello_idx = Variable(hello_idx)
5 hello_embed = embeds(hello_idx)
6 print(hello_embed)- 1
- 2
- 3
- 4
- 5
- 6
上面就是输出的hello 的词嵌入,下面来解释一下代码。首先需要给每个单词建立一个对应下标,这样每个单词都可以用一个数字去表示,比如需要hello 的时候,就可以用0来表示,用这种方式,访问每个词会特别方便。接着是词嵌入的定义nn.Embedding(2,5),如上面介绍过的,表示有两个词,每个词向量是5 维,也就是一个2 * 5 的矩阵,只不过矩阵中的元素是可以被学习更新的,所以如果有1000 个词,每个词向量希望是100 维,就可以这样定义词嵌入nn.Embedding(1000, 100)。访问每一个词的词向量需要将tensor 转换成Variable,因为词向量也是网络中更新的参数,所以在计算图中,需要通过Variable 去访问。另外这里的词向量只是初始的词向量,并没有经过学习更新,需要建立神经网络优化更新,修改词向量里面的参数使得词向量能够表示不同的词,且语义相近的词能够有更小的夹角。
以上介绍了词嵌入在PyTorch 中是如何实现的,下一节将介绍词嵌入是如何更新的,以及它如何结合N Gram 语言模型进行预测。
N Gram 模型
首先介绍N Gram 模型的原理和它要解决的问题。在一篇文章中,每一句话都是由很多单词组成的,而且这些单词的排列顺序也是非常重要的。在一句话中,是否可以由前面几个词来预测这些词后面的一个单词?比如在“I lived in France for 10 years, I can speak _ .”这句话中,我们希望能够预测最后这个词是French。
知道想要解决的问题后,就可以引出N Gram 语言模型了。对于一句话T,它由w1;w2;…wn 这n 个词构成,可以得到下面的公式:
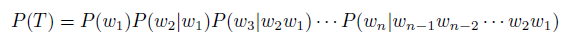
但是这样的一个模型存在着一些缺陷,比如参数空间过大,预测一个词需要前面所有的词作为条件来计算条件概率,所以在实际中没办法使用。为了解决这个问题,引入了马尔科夫假设,也就是说这个单词只与前面的几个词有关系,并不是和前面所有的词都有关系,有了这个假设,就能够在实际中使用N Gram 模型了。
对于这个条件概率,传统的方法是统计语料中每个单词出现的频率,据此来估计这个条件概率,这里使用词嵌入的办法,直接在语料中计算这个条件概率,然后最大化条件概率从而优化词向量,据此进行预测。
单词预测的PyTorch 实现
首先给出一段文章作为训练集:
1 CONTEXT_SIZE = 2
2 EMBEDDING_DIM = 10
3 # We will use Shakespeare Sonnet 2
4 test_sentence = """When forty winters shall besiege thy brow,
5 And dig deep trenches in thy beauty's field,
6 Thy youth's proud livery so gazed on now,
7 Will be a totter'd weed of small worth held:
8 Then being asked, where all thy beauty lies,
9 Where all the treasure of thy lusty days;
10 To say, within thine own deep sunken eyes,
11 Were an all-eating shame, and thriftless praise.
12 How much more praise deserv'd thy beauty's use,
13 If thou couldst answer 'This fair child of mine
14 Shall sum my count, and make my old excuse,'
15 Proving his beauty by succession thine!
16 This were to be new made when thou art old,
17 And see thy blood warm when thou feel'st it cold.""".split()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
CONTEXT_SIZE 表示想由前面的几个单词来预测这个单词,这里设置为2,就是说我们希望通过这个单词的前两个单词来预测这一个单词,EMBEDDING_DIM 表示词嵌入的维数。
接着建立训练集,遍历所有语料来创建,将数据整理好,需要将单词分三个组,每个组前两个作为传入的数据,而最后一个作为预测的结果。
1 trigram = [((test_sentence[i], test_sentence[i+1]), test_sentence[i+2])
2 for i in range(len(test_sentence)-2)]- 1
- 2
将每个单词编码,即用数字来表示每个单词,只有这样才能够传入nn.Embedding得到词向量。
1 vocb = set(test_sentence) # 通过set将重复的单词去掉
2 word_to_idx = {word: i for i, word in enumerate(vocb)}
3 idx_to_word = {word_to_idx[word]: word for word in word_to_idx}- 1
- 2
- 3
然后可以定义N Gram 模型如下:
1 class NgramModel(nn.Module):
2 def __init__(self, vocb_size, context_size, n_dim):
3 super(NgramModel, self).__init__()
4 self.n_word = vocb_size
5 self.embedding = nn.Embedding(self.n_word, n_dim)
6 self.linear1 = nn.Linear(context_size*n_dim, 128)
7 self.linear2 = nn.Linear(128, self.n_word)
8
9 def forward(self, x):
10 emb = self.embedding(x)
11 emb = emb.view(1, -1)
12 out = self.linear1(emb)
13 out = F.relu(out)
14 out = self.linear2(out)
15 log_prob = F.log_softmax(out)
16 return log_prob- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
模型需要传入的参数有三个,分别是所有的单词数、预测单词所依赖的单词数、即CONTEXT_SIZE 和词向量的维度。网络在向前传播中,首先传入单词得到词向量,模型是根据前面两个词预测第三个词的,所以需要传入两个词,得到的词向量是(2, 100),然后将词向量展开成(1, 200),接着经过线性变换,经过relu 激活函数,再经过一个线性变换,输出的维数是单词总数,最后经过一个log softmax 激活函数得到概率分布,最大化条件概率,可以用下面的公式表示:
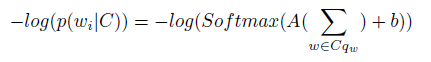
在网络的训练中,不仅会更新线性层的参数,还会更新词嵌入中的参数,训练100次模型,可以发现loss 已经降到了0.37,也可以通过预测来检测模型是否有效:
1 word, label = trigram[3]
2 word = Variable(torch.LongTensor([word_to_idx[i] for i in word]))
3 out = ngrammodel(word)
4 _, predict_label = torch.max(out, 1)
5 predict_word = idx_to_word[predict_label.data[0][0]]
6 print('real word is {}, predict word is {}'.format(label, predict_word))- 1
- 2
- 3
- 4
- 5
- 6
运行上面的代码,可以发现真实的单词跟预测的单词都是一样的,虽然这是在训练集上,但是在一定程度上也说明这个小模型能够处理N Gram 模型的问题。
上面介绍了如何通过最简单的单边N Gram 模型预测单词,还有一种复杂一点的N Gram 模型通过双边的单词来预测中间的单词,这种模型有个专门的名字,叫Continuous Bag-of-Words model(CBOW),具体内容差别不大,就不再赘述。
词性判断
上面只使用了词嵌入和N Gram 模型进行自然语言处理,还没有真正使用循环神经网络,下面介绍RNN 在自然语言处理中的应用。在这个例子中,我们将使用LSTM 做词性判断,因为同一个单词有着不同的词性,比如book 可以表示名词,也可以表示动词,所以需要结合前后文给出具体的判断。先介绍使用LSTM 做词性判断的原理。
- 基本原理
定义好一个LSTM 网络,然后给出一个由很多个词构成的句子,根据前面的内容,每个词可以用一个词向量表示,这样一句话就可以看做是一个序列,序列中的每个元素都是一个高维向量,将这个序列传入LSTM,可以得到与序列等长的输出,每个输出都表示为对词性的判断,比如名词、动词等。从本质上看,这是一个分类问题,虽然使用了LSTM,但实际上是根据这个词前面的一些词来对它进行分类,看它是属于几种词性中的哪一种。
思考一下为什么LSTM 在这个问题里面起着重要的作用。如果完全孤立地对一个词做词性的判断,往往无法得到比较准确的结果,但是通过LSTM,根据它记忆的特性,就能够通过这个单词前面记忆的一些词语来对它做一个判断,比如前面的单词如果是my,那么它紧跟的词很有可能就是一个名词,这样就能够充分地利用上文来处理这个问题。
- 字符增强
还可以通过引入字符来增强表达,这是什么意思呢?就是说一些单词存在着前缀或者后缀,比如-ly 这种后缀很可能是一个副词,这样我们就能够在字符水平上对词性进行进一步判断,把两种方法集成起来,能够得到一个更好的结果。
在实现上还是用LSTM,只是这次不再将句子作为一个序列,而是将每个单词作为一个序列。每个单词由不同的字母组成,比如apple 由a p p l e 构成,给这些字符建立词向量,形成了一个长度为5 的序列,将它传入LSTM 网络,只取最后输出的状态层作为它的一种字符表达,不需要关心提取出来的字符表达到底是什么样,它作为一种抽象的特征,能够更好地预测结果。
词性判断的PyTorch 实现
作为演示,使用一个简单的训练数据,下面有两句话,每句话中的每个词都给出了词性:
1 training_data = [
2 ("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),
3 ("Everybody read that book".split(), ["NN", "V", "DET", "NN"])
4 ]- 1
- 2
- 3
- 4
接着对单词和词性由a 到z 的字符进行编码:
1 word_to_idx = {}
2 tag_to_idx = {}
3 for context, tag in training_data:
4 for word in context:
5 if word not in word_to_idx:
6 word_to_idx[word] = len(word_to_idx)
7 for label in tag:
8 if label not in tag_to_idx:
9 tag_to_idx[label] = len(tag_to_idx)
10
11 alphabet = 'abcdefghijklmnopqrstuvwxyz'
12 character_to_idx = {}
13 for i in range(len(alphabet)):
14 character_to_idx[alphabet[i]] = i- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
接着先定义字符水准上的LSTM,定义方式和之前类似:
1 class CharLSTM(nn.Module):
2 def __init__(self, n_char, char_dim, char_hidden):
3 super(CharLSTM, self).__init__()
4 self.char_embedding = nn.Embedding(n_char, char_dim)
5 self.char_lstm = nn.LSTM(char_dim, char_hidden, batch_first=True)
6
7 def forward(self, x):
8 x = self.char_embedding(x)
9 _, h = self.char_lstm(x)
10 return h[0]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
定义两层结构:第一层是词嵌入,第二层是LSTM。在网络的前向传播中,先将单词的n 个字符传入网络,再通过nn.Embedding 得到词向量,接着传入LSTM 网络,得到隐藏状态输出h,然后通过h[0] 得到想要的输出状态。对于每个单词,都可以通过CharLSTM 用相应的字符表示。
接着完成目标,分析每个单词的词性,首先定义好词性的LSTM 网络:
1 class LSTMTagger(nn.Module):
2 def __init__(self, n_word, n_char, char_dim, n_dim, char_hidden,
3 n_hidden, n_tag):
4 super(LSTMTagger, self).__init__()
5 self.word_embedding = nn.Embedding(n_word, n_dim)
6 self.char_lstm = CharLSTM(n_char, char_dim, char_hidden)
7 self.lstm = nn.LSTM(n_dim+char_hidden, n_hidden, batch_first=True)
8 self.linear1 = nn.Linear(n_hidden, n_tag)
9
10 def forward(self, x, word_data):
11 word = [i for i in word_data]
12 char = torch.FloatTensor()
13 for each in word:
14 word_list = []
15 for letter in each:
16 word_list.append(character_to_idx[letter.lower()])
17 word_list = torch.LongTensor(word_list)
18 word_list = word_list.unsqueeze(0)
19 tempchar = self.char_lstm(Variable(word_list).cuda())
20 tempchar = tempchar.squeeze(0)
21 char = torch.cat((char, tempchar.cpu().data), 0)
22 char = char.squeeze(1)
23 char = Variable(char).cuda()
24 x = self.word_embedding(x)
25 x = torch.cat((x, char), 1)
26 x = x.unsqueeze(0)
27 x, _ = self.lstm(x)
28 x = x.squeeze(0)
29 x = self.linear1(x)
30 y = F.log_softmax(x)
31 return y- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
看着有点复杂,慢慢来介绍。首先使用n_word 和n_dim 定义单词的词向量矩阵的维度,n_char 和char_dim 定义字符的词向量维度,char_hidden 表示字符水准上的LSTM 输出的维度,n_hidden 表示每个单词作为序列输入LSTM 的输出维度,最后n_tag 表示输出的词性分类。介绍完里面参数的含义,下面具体介绍其中网络的向前传播。
学习过PyTorch 的动态图结构,网络的向前传播就非常简单了。因为要使用字符增强,所以在传入一个句子作为序列的同时,还需要传入句子中的单词,用word_data表示。动态图结构使得前向传播中可以使用for 循环将每个单词都传入CharLSTM,得到的结果和单词的词向量拼在一起作为新的序列输入,将它传入LSTM 中,最后接一个全连接层,将输出维数定义为词性的数目。
这是基本的思路,就不具体解释每句话的含义了,只是要注意代码里面有unsqueeze和squeeze 的操作,原因前面介绍过,LSTM 的输入要带上batch_size,所以需要将维度扩大。
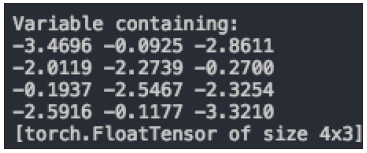
网络训练经过了300 次,loss 降到了0.16 左右。为了验证模型的准确性,可以预测“Everybody ate the apple”这句话中每个词的词性,一共有三种词:DET、NN、V。最后得到的结果如图7所示。
结果是一个4 行3 列的向量,每一行表示一个单词,每一列表示一种词性,从左到右的词性分别是DET、NN、V。从每行里面取最大值,那么第一个词的词性就是NN,第二个词是V,第三个词是DET,第四个词是NN,与想要的结果相符。
以上,通过几个简单的例子介绍了循环神经网络在自然语言处理中的应用,当然真正的应用会更多,同时也更加复杂,这里就不再深入介绍了,对自然语言处理感兴趣的读者可以进行更深入地探究。


