
热门标签
热门文章
- 1Ubuntu20.04重装系统过程(多图,含保存文件+卸载旧系统+安装新系统)_ubuntu重装系统
- 2我们究竟还要学习哪些Android知识?学习路线+知识点梳理_知识点学习路径
- 3168份Java计算机毕业设计选题推荐(源码+论文+PPT)_计算机专业毕业设计选题方向java
- 4华为云云耀云服务器L实例评测|教你如何使用云服务器L实例
- 5大数据机器学习是什么,主要能应用到哪些领域?_大数据 机器学习
- 6【机器学习300问】75、如何理解深度学习中Dropout正则化技术?
- 7本地启用并操作Redis
- 8数据科学与大数据专业毕业设计(论文)选题推荐_数据科学与大数据技术专业毕业设计选题有哪几类?
- 9Verilog-实现时钟分频(1KHZ、奇、偶分频,占空比为50%)_50mhz分频1hz是几分频
- 10干货|Webhook配置钉钉/飞书机器人告警
当前位置: article > 正文
大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架_大模型是给了transformer基本的b
作者:AllinToyou | 2024-04-17 20:24:11
赞
踩
大模型是给了transformer基本的b
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用3-大模型的基础架构Transformer模型,掌握Transformer就掌握了大模型的灵魂骨架。Transformer是一种基于自注意力机制的深度学习模型,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它最初被设计用来处理序列到序列(seq2seq)任务,如机器翻译,但现在已经广泛应用于各种NLP任务。下面我们将详细介绍其网络结构。
一、Transformer的结构介绍
我们需要理解Transformer模型的整体架构。这个模型由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器读取输入序列,并生成一个连续的表示;解码器则利用这个表示生成输出序列。
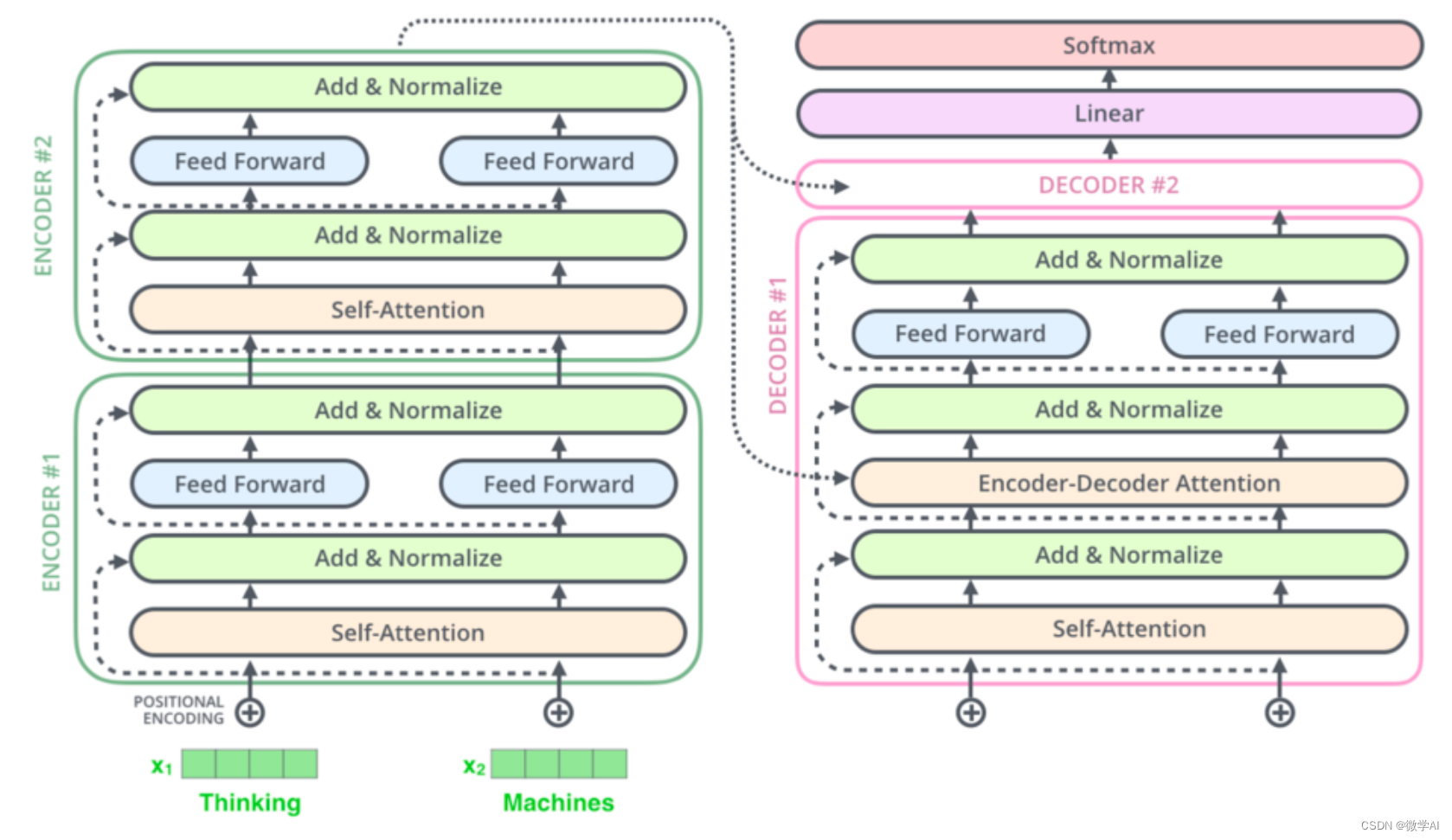
1.数据输入层:
输入数据通常是一段文本或者句子,比如“我喜欢看书”。为了让计算机能理解这段文本,我们需要把每个单词转换成计算机能理解的形式。这就涉及到了下一个环节——词嵌入。
2.词嵌入:
在词嵌入阶段,每个单词会被映射到一个高维空间中的向量。例如,“我”可能被映射为[0.1, 0.3, …, 0.5],“喜欢”可能被映射为[0.2, 0.4, …, 0.6]。这样做的目标是使得语义相近的单词在高维空间中位置接近。词嵌入是将离散的词语映射到连续的向量空间。假设我们有一个大小为
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/442085
推荐阅读
相关标签

