
- 1【Linux】文件打包解压_tar_zip
- 2一个 3 年 Java 程序员 5 家大厂的面试总结(已拿 Offer)_3年后端大厂真实面经
- 3java8-Stream流_stream流复杂caoz
- 4【KTips】在Kotlin中实现一个十分简单的自循环状态机
- 5git Bash 生成SSH密钥步骤_gitbash密钥
- 6基于SpringBoot的美食分享平台_美食分享系统数据设计
- 7豆瓣读书top250数据爬取与可视化_书籍出版时间爬虫可视化怎么写
- 8微信公众号图片防盗链机制的应对办法^-^_mmbiz.qpic.cn
- 9Java配置方式使用Spring MVC_java spring mvc
- 10kkFileView部署
Pytorch 的数据处理 学习笔记_pytorch处理图片数据集
赞
踩
一. 数据集Dataset
Dataset是一个抽象类,用于表示数据集。可以创建自定义的Dataset类来加载和准备好的数据,无论数据是存储在何处(例如磁盘、内存或其他位置)。PyTorch提供了一些内置的Dataset类,例如TensorDataset、ImageFolder等,也可以根据自己的需求创建自定义的Dataset类。
1.引入Dataset
from torch.utils.data import Dataset2.(选做)查看Dataset详情
通常情况,我们想看一个大容器中包含哪几个小部分,使用dir(***),想查看一个具体的工具,使用help(***),所以这里使用help函数
help(Dataset)实现效果如下(使用jupyter实现,没有安装jupyter可参照上一篇博客)
令一种展现方法
Dataset??实现效果如下

2.先获取一张图片试试
先使用最基本的python处理图片的库 PIL
首先自己找一张图片,并复制图片的路径,我这里方便起见,使用的是绝对路径
(第一行引入的Dataset,这里可删)
- from torch.utils.data import Dataset
- from PIL import Image
-
- img_Path = "E:\\Python\\study\\sunflower.png" # 获取图片路径
- img = Image.open(img_Path) # 使用PIL的open方法
- img.show() # 使用show函数查看
运行效果如下

3.获取一整个图片文件夹的图片
首先要有一个文件夹,文件夹中图片
获取一整个文件夹的图片,得找一个方便的工具,就得引入os库了
os库中提供了获取文件夹中所有文件的函数
为便于理解,简单查阅了一下os:
os 库是 Python 标准库之一,提供了与操作系统交互的功能。通过 os 库,你可以执行许多与文件系统、进程管理以及环境变量相关的操作。以下是 os 库的一些主要功能:
-
文件和目录操作:
os库允许你执行许多文件和目录的操作,如创建、删除、重命名、检查文件或目录是否存在等。 -
路径操作:
os.path模块提供了一组函数,用于处理文件路径,包括连接路径、获取文件名、获取目录名、判断路径是否为文件或目录等。 -
环境变量:
os.environ变量提供了一个字典,包含当前进程的环境变量。你可以使用它来获取、设置或操作环境变量。 -
进程管理:
os库允许你执行一些基本的进程管理操作,如获取当前进程 ID、执行系统命令、获取系统信息等。 -
权限和权限修改:
os库中的一些函数允许你检查和修改文件和目录的权限,如更改文件的所有者、更改文件权限等。
包含引入os库,总共引入的代码如下:
- from torch.utils.data import Dataset
- from PIL import Image
- import os
以Dataset为对象,创建类
(1)创建init函数
class MyData(Dataset):创建构造函数
def __init__(self, root_dir, label_dir):我的数据集文件结构为

赋初始值,root_dir为数据集中train文件的位置,label_dir为train文件下ants文件的名称,即为ants
- self.root_dir = root_dir
- self.label_dir = label_dir
通过os的join函数将这两个字符串拼接
self.path = os.path.join(self.root_dir, self.label_dir)os的listdir可以获取文件夹下的文件列表,获取一下文件列表
self.img_path = os.listdir(self.path)init全部代码
- def __init__(self, root_dir, label_dir):
- self.root_dir = root_dir
- self.label_dir = label_dir
- self.path = os.path.join(self.root_dir, self.label_dir)
- self.img_path = os.listdir(self.path)
(2)创建getitem函数
def __getitem__(self, index):init函数中获取了文件的列表,可以通过索引获取列表中的某一个文件,因此getitem函数中提供了参数index
img_name = self.img_path[index]获取了文件名字,然后将这个文件名字与之前的root,label字符串拼接,即为具体图片的路径
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)使用PIL库提供的open,获取img对象
img = Image.open(img_item_path)获取了img对象,每个对象还有相对应的label名称
label = self.label_dir将img对象和label这两个变量返回
return img, labelgetitem全部代码
- def __getitem__(self, index):
- img_name = self.img_path[index]
- img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
- img = Image.open(img_item_path)
- label = self.label_dir
- return img, label
(3)创建len函数
def __len__(self):len函数用于获取文件数目,此处即为文件夹中图片的数目
我们刚才通过os的listdir已经获取了文件列表,只需要返回列表长度即可
return len(self.img_path)len函数全部代码
- def __len__(self):
- return len(self.img_path)
(4)变量代入测试
- root_dir = "E:\\Python\\study\\ch1\\dataset\\train"
- ants_label_dir = "ants_img"
- bees_label_dir = "bees_img"
- ants_dataset = MyData(root_dir, ants_label_dir)
- bees_dataset = MyData(root_dir, bees_label_dir)
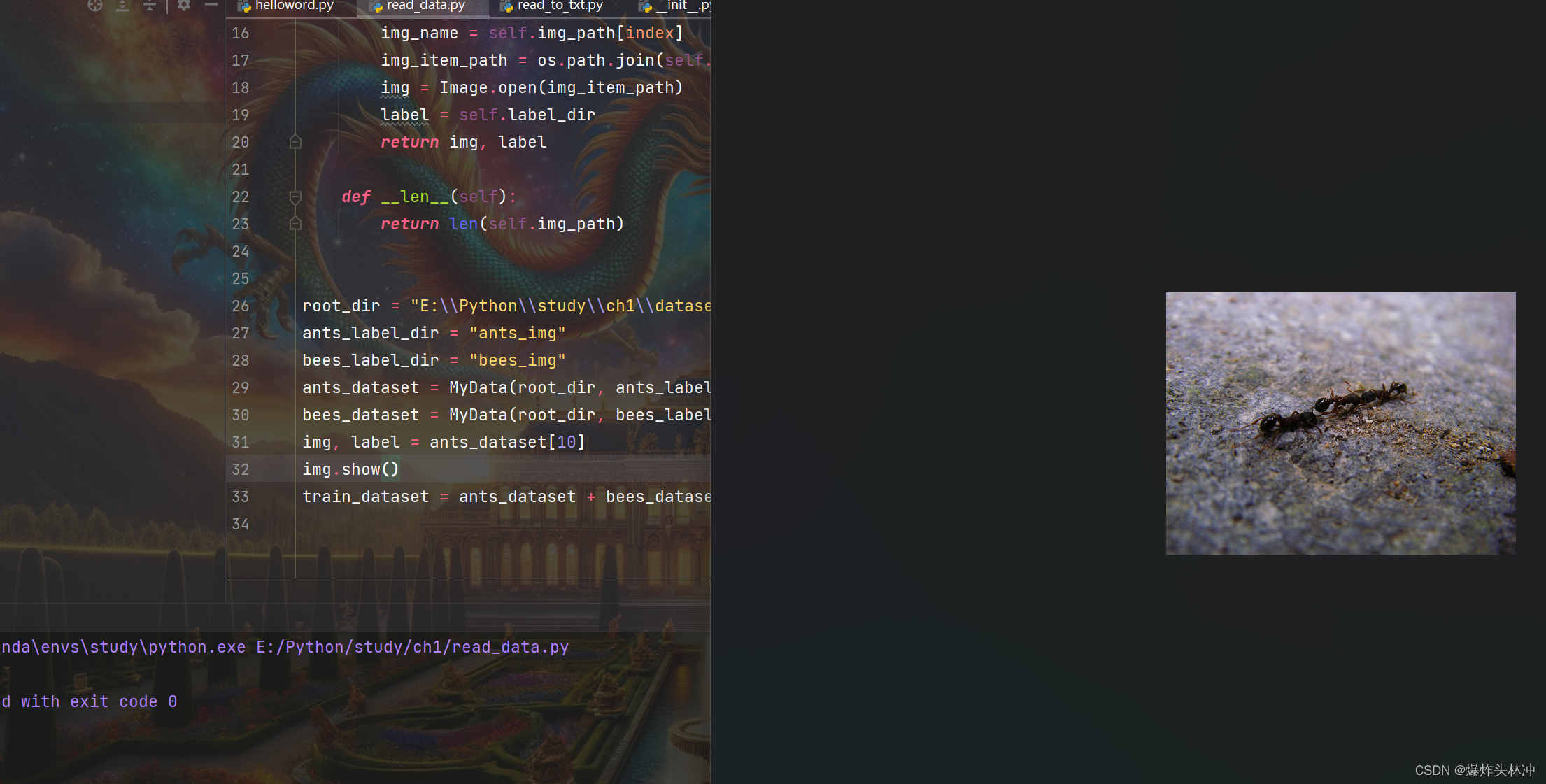
展示获取的图片,这里我获取ants下的第11张图片(索引从0开始)
我们上面的getitem方法返回的是img和label,然后我们要获取img使用show方法打开图片
获取返回返回值
img, label = ants_dataset[10]使用img的show验证
img.show()运行效果如下
(5)文件集拼接
在上面我获取了ants下的图片集,也获取了bees下的图片集,可以相加这两个集中获取所有的图片
train_dataset = ants_dataset + bees_dataset获取第240张图片(前提是你有这么多),打开验证
- img, label = train_dataset[240]
- img.show()
测试全部代码
- root_dir = "E:\\Python\\study\\ch1\\dataset\\train"
- ants_label_dir = "ants_img"
- bees_label_dir = "bees_img"
- ants_dataset = MyData(root_dir, ants_label_dir)
- bees_dataset = MyData(root_dir, bees_label_dir)
- train_dataset = ants_dataset + bees_dataset
- img, label = train_dataset[240]
- img.show()
4.处理数据存入txt文件
引入os文件,因为要获取ants中的全部文件列表
定义train所在的路径和下一级存储文件(这里指图片)的文件夹
使用join拼接
随便存了一个值,将target_dir的字符串依据'_'
- import os
-
- root_dir = 'E:\\Python\\study\\ch1\\dataset\\train'
- target_dir = 'ants_img'
- img_path = os.listdir(os.path.join(root_dir, target_dir))
- label = target_dir.split('_')[0]
- out_dir = 'ants_label'
- for i in img_path:
- file_name = i.split('.jpg')[0]
- with open(os.path.join(root_dir, out_dir, "{}.txt".format(file_name)), 'w') as f:
- f.write(label)
二. TensorBoard
安装
conda activate tensorboard引入库
from torch.utils.tensorboard import SummaryWriter创建summarywriter实例
write = SummaryWriter("logs")add_scalar用于记录标量数据,而add_image用于记录图像数据
1.add_scalar 打印 y=x 曲线
- from torch.utils.tensorboard import SummaryWriter
-
- writer = SummaryWriter("../logs")
-
- # writer.add_image()\
- for i in range(100):
- writer.add_scalar("y=x", i, i)
-
- writer.close()
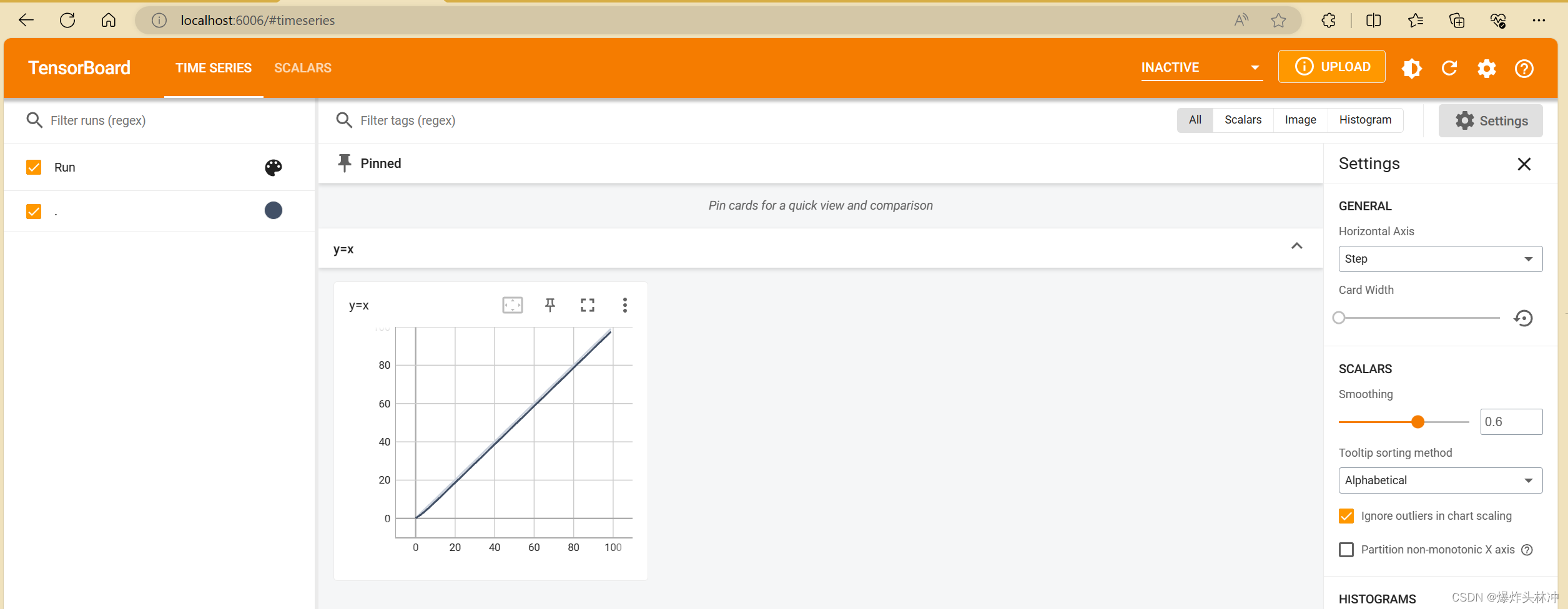
引入依赖,创建writer实例,其中../logs是文件名,我要在上一级目录创建logs文件(在项目目录下创建logs文件),使用循环,标记画图,标签名为y=x,i , i表示x,y的值相同。
打开terminal到项目目录下,输入
tensorboard --logdir=logs --port=6007
logs为项目目录下生成的记录文件夹名称,port为打开所需的端口,不写port则默认打开6006
效果如下

打开网址(我没指定port端口,默认打开6006端口)
整体代码
- from torch.utils.tensorboard import SummaryWriter
-
- writer = SummaryWriter("../logs")
-
- # writer.add_image()\
- for i in range(100):
- writer.add_scalar("y=x", i, 2 * i) # 标签,x,y
-
- writer.close()
2.add_image 展示图片步骤
引入依赖,这个的实现,需要将PIL类型的image转换成Numpy类型,因此还要引入numpy
- from torch.utils.tensorboard import SummaryWriter
- from PIL import Image
- import numpy as np
创建writer实例,在项目目录下创建了logs文件夹
writer = SummaryWriter("../logs")定义图片路径
img_path = "dataset/train/ants_img/0013035.jpg"有了路径,要获取图片对象
img = Image.open(img_path)获取的对象为PIL类型,后面的操作需要Numpy类型,因此要转型
img_arr = np.array(img)使用add_image方法
test为标签名,img_arr为Numpy类型的图片,1为step步数,dataformats是一种相对固定的格式。
writer.add_image("test", img_arr, 1, dataformats="HWC")最后必须跟上close!否则全部白费
writer.close()效果如下(我后面有换了张图片,写了个step2,所以会有移动条)

整体代码
- from torch.utils.tensorboard import SummaryWriter
- from PIL import Image
- import numpy as np
-
- writer = SummaryWriter("../logs")
- img_path = "dataset/train/ants_img/6743948_2b8c096dda.jpg"
- img = Image.open(img_path)
- img_arr = np.array(img)
- writer.add_image("test", img_arr, 2, dataformats="HWC")
- writer.close()
三. Transforms
1. 介绍
torchvision.transforms是PyTorch中的一个模块,用于进行图像数据的预处理和增强操作。它提供了一系列的转换函数,可以方便地对图像进行各种处理,如缩放、裁剪、旋转、翻转、归一化等。这些转换可以应用于单张图像或图像数据集,在训练神经网络时特别有用。
主要的功能包括:
-
图像变换(Image Transformations):如大小调整、裁剪、旋转、翻转等。这些变换通常用于数据增强,以提高模型的鲁棒性和泛化能力。
-
数据归一化(Data Normalization):对图像进行均值和标准差的归一化处理,以便于模型的训练和收敛。
-
数据类型转换(Data Type Conversion):将图像数据从PIL Image或NumPy数组转换为Tensor,以便于在PyTorch中使用。
-
图像增强(Image Augmentation):如随机裁剪、随机旋转、颜色扰动等,用于增加训练数据的多样性,从而提高模型的泛化能力。
这些transforms可以通过torchvision.transforms.Compose函数将多个转换组合起来,构建一个转换序列,然后应用到图像数据上。这样,可以很方便地对图像数据进行预处理,使其适用于不同的深度学习任务。
2. ToTensor
将PIL格式的图片转化成Tensor格式的图片
引入库
- from torchvision import transforms
- from PIL import Image
引入图片地址,获取PIL格式的图片
- image_path = "dataset/train/ants_img/0013035.jpg"
- img_PIL = Image.open(image_path)
创建用于格式转换的转换器工具
trans_tensor = transforms.ToTensor()格式转换
img_tensor = trans_tensor(img_PIL)打印验证
print(img_tensor)效果如下
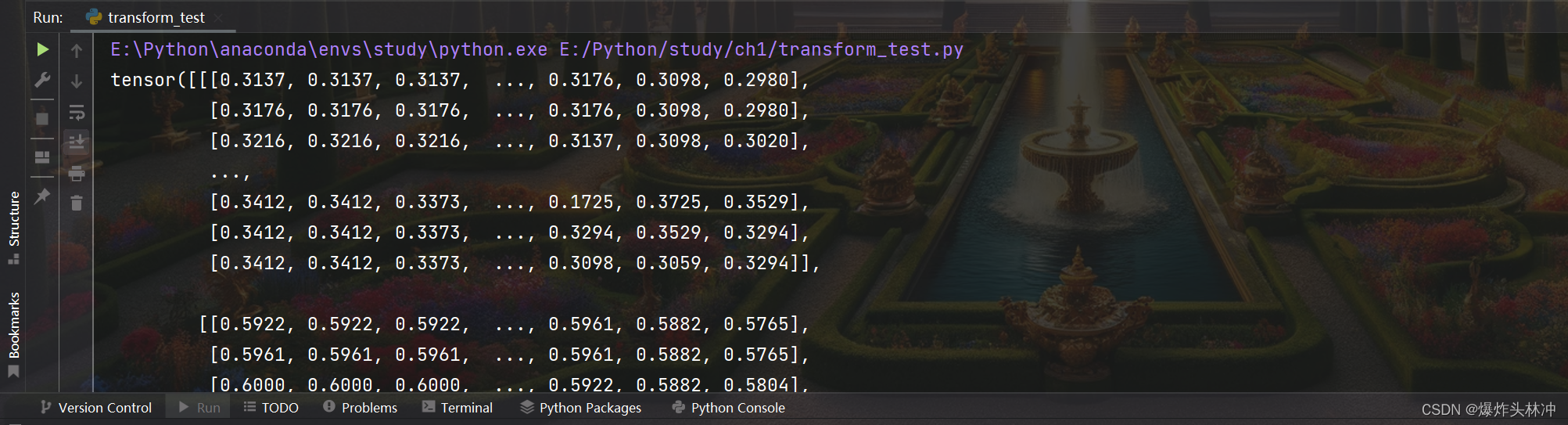
基本的使用流程(参照土堆)
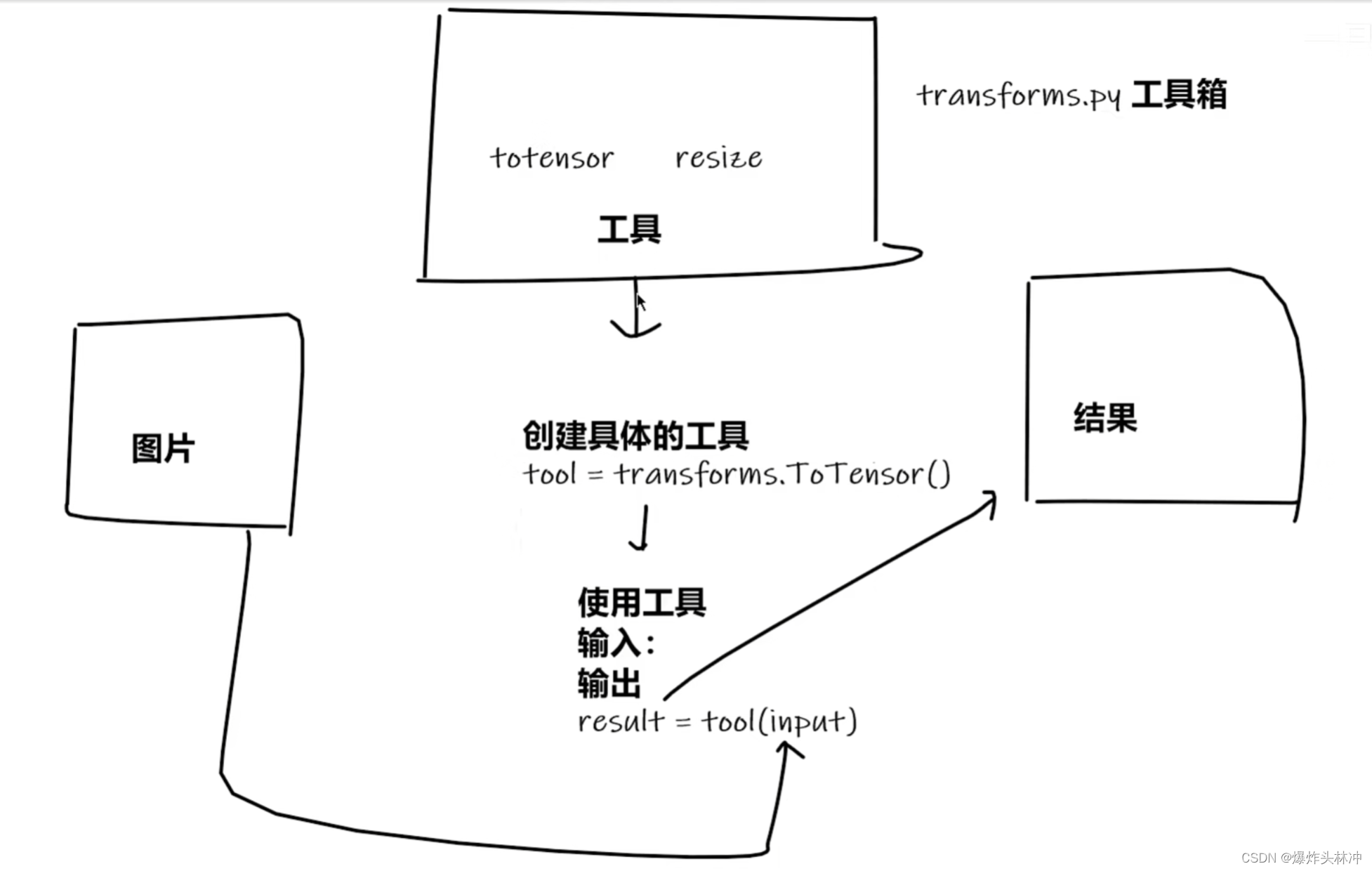
3. add_image 传入Tensor类型图片
只是把之前的pil转为numpy格式,换成了pil转为Tensor格式
- from torch.utils.tensorboard import SummaryWriter
- from PIL import Image
- from torchvision import transforms
-
- writer = SummaryWriter("../logs")
- img_path = "dataset/train/bees_img/21399619_3e61e5bb6f.jpg"
- img = Image.open(img_path)
- tensor_trans = transforms.ToTensor()
- tensor_img = tensor_trans(img)
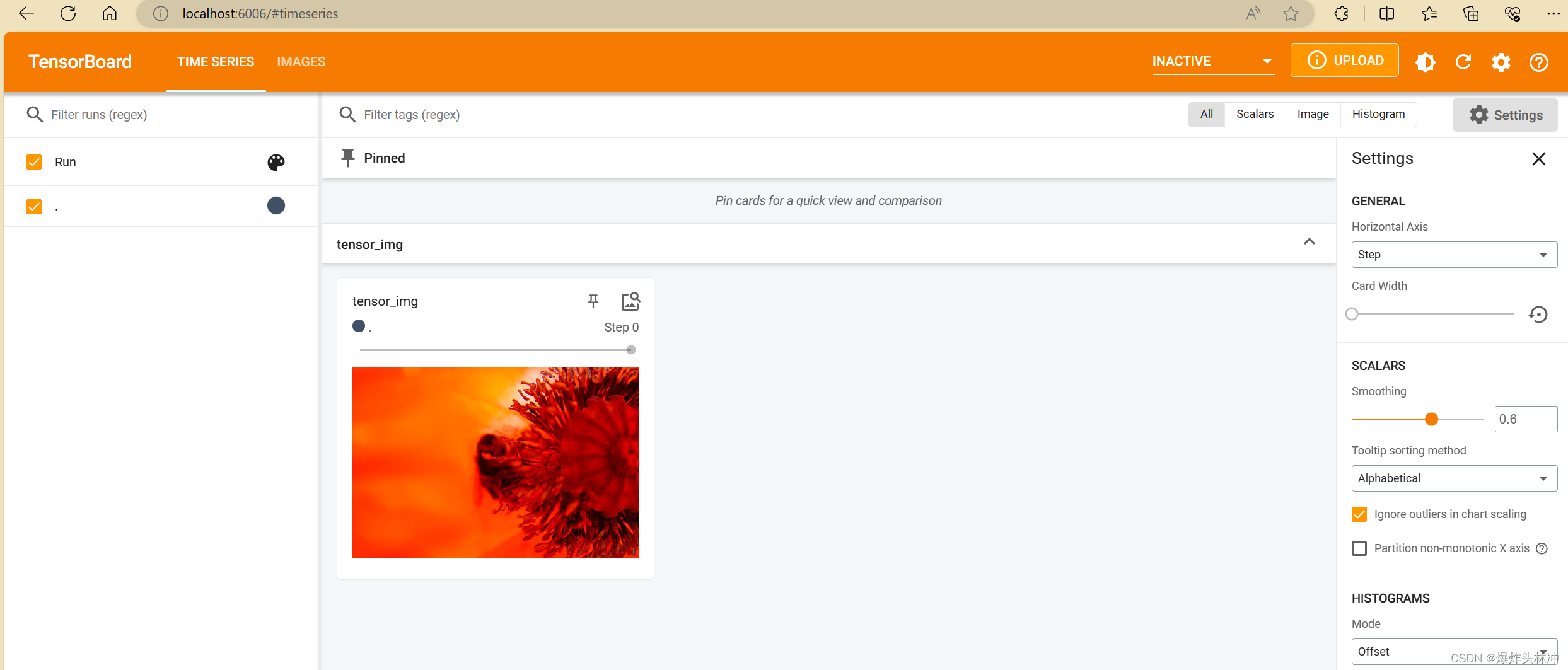
- writer.add_image("tensor_img", tensor_img)
- writer.close()
运行,使用Tensorboard打开

效果如下
4. normalize
在数据处理中,"normalize" 通常用于将数据重新缩放到一个统一的范围内,以便更好地适应模型的训练或者其他数据处理操作。在 `transform` 中的 `normalize` 函数则是用来实现这个目的的。具体来说,它会将每个特征的数值按照一定的规则进行缩放,通常是将其调整为均值为0,标准差为1的分布,或者将其缩放到某个指定的范围内,比如 [0, 1] 或者 [-1, 1]。这有助于加快模型的收敛速度,并且有时可以提高模型的准确性和稳定性,实现归一化。
重新将代码温故一下
引入依赖,需要pil获取图片,需要使用Tensorboard的summarywriter打印log文件,查看图片,需要使用transform的normalize对图片归一化操作
- from PIL import Image
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
先创建writer实例(logs文件创建在项目文件下)
writer = SummaryWriter("../logs")先获取图片路径,然后通过PIL的Image的open方法获取图片
- img_path = "dataset/train/bees_img/354167719_22dca13752.jpg"
- img_PIL = Image.open(img_path)
transform的normalize中要传入Tensor类型的图片,所以要把pil格式的图片转换成Tensor格式
创建转换器然后转换
- # ToTensor
- trans_util = transforms.ToTensor()
- tensor_img = trans_util(img_PIL)
然后将创建normalize工具,对Tensor类型的图片做归一化处理,其中的参数为自定义可改
- normalize_util = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- nol_img = normalize_util(tensor_img)
计算公式如下

(截自土堆)
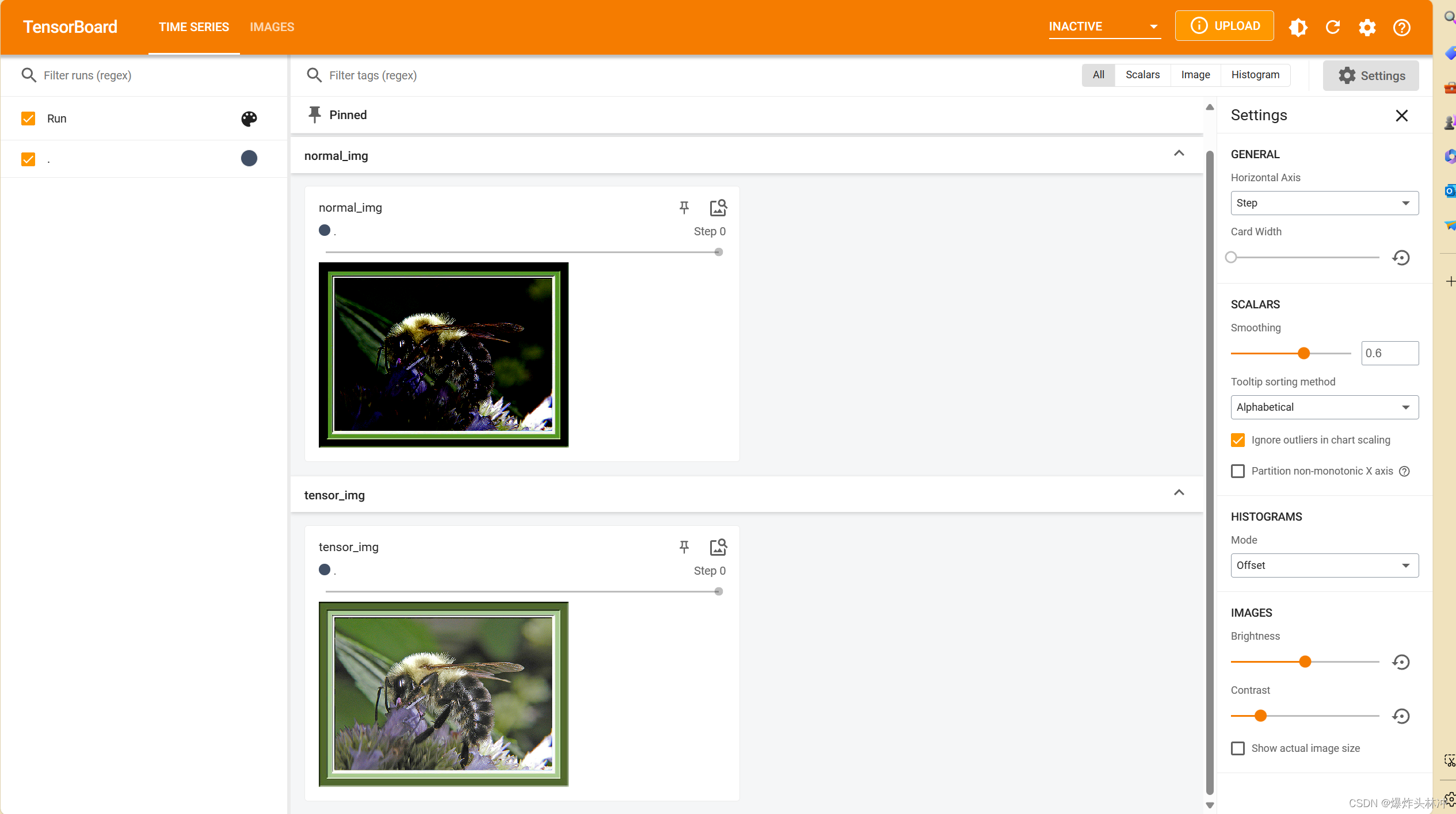
执行Tensorboard的add_img操作
writer.add_image('normal_img',nol_img)最后千万别忘了close!
writer.close()为了能展示图片变化,我将原本的图片也进行了add_image操作,为了验证上面的运算式,我获取了图片的[0][0][0]位置的值分别处理前后打印
全部代码如下(注意logs文件路径,根据实际情况)
- from PIL import Image
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
-
- writer = SummaryWriter("../logs")
- img_path = "dataset/train/bees_img/354167719_22dca13752.jpg"
- img_PIL = Image.open(img_path)
- # ToTensor
- trans_util = transforms.ToTensor()
- tensor_img = trans_util(img_PIL)
- writer.add_image('tensor_img', tensor_img)
- # Normalize
- print(tensor_img[0][0][0])
- normalize_util = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- nol_img = normalize_util(tensor_img)
- print(nol_img[0][0][0])
- writer.add_image('normal_img',nol_img)
- writer.close()
运行,print打印如下

运行Tensorboard

打开页面显示如下
5. resize
在数据处理中,“resize” 通常用于调整图像或数据的尺寸,以适应模型的输入要求或者统一数据的大小。在 transform 中的 resize 函数就是用来实现这个目的的。具体来说,它可以将图像或数据调整为指定的大小,通常是通过插值等方法来改变图像的像素或数据的分辨率,以确保其在训练或处理过程中具有一致的大小。这对于确保模型的输入数据大小一致性是非常重要的,可以使模型更容易地学习到特征并提高模型的准确性。
在上述的代码基础上编写
创建transforms的指定大小图片转化工具,指定宽和高的大小
resize_util = transforms.Resize((512, 512))使用resize转化器,里面需要传入pil格式的图片!!!不是传Tensor格式!!!
resize_img = resize_util(img_PIL)经过转化器,返回的还是pil图片
我们想要使用add_image在Tensorboard中展示,首先,add_image中传入的是Tensor类型的图片,所以,要把pil格式的图片转换成Tensor格式的图片
tensor_resize_img = trans_util(resize_img) # trans_util为toTensor的转换器执行add_image
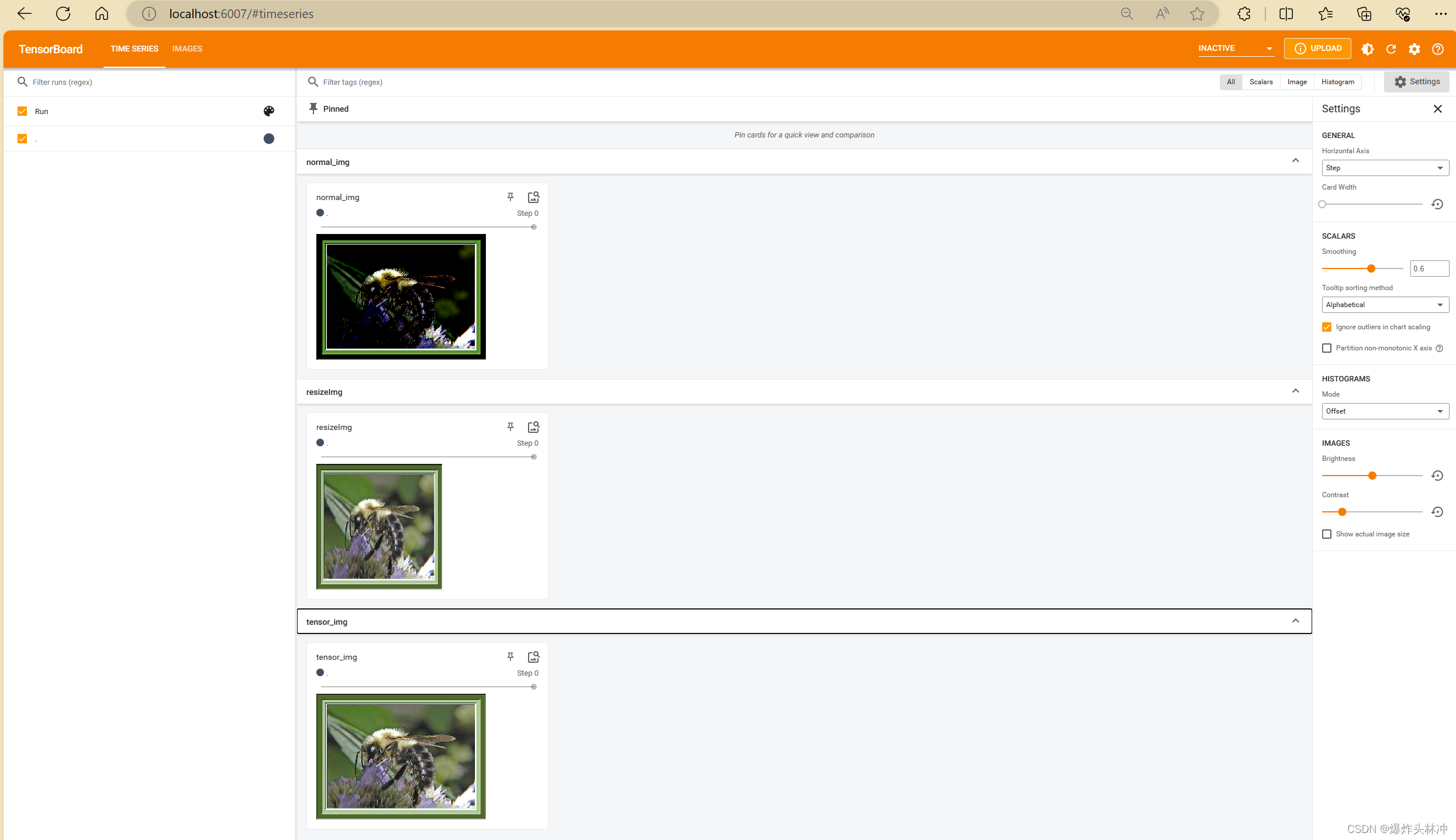
writer.add_image('resizeImg', tensor_resize_img)最后关闭writer
writer.close()全部代码如下(包括之前)
- from PIL import Image
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
-
- writer = SummaryWriter("../logs")
- img_path = "dataset/train/bees_img/354167719_22dca13752.jpg"
- img_PIL = Image.open(img_path)
- # ToTensor
- trans_util = transforms.ToTensor()
- tensor_img = trans_util(img_PIL)
- writer.add_image('tensor_img', tensor_img)
- # Normalize
- print(tensor_img[0][0][0])
- normalize_util = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- nol_img = normalize_util(tensor_img)
- print(nol_img[0][0][0])
- writer.add_image('normal_img', nol_img)
- # Resize
- resize_util = transforms.Resize((512, 512))
- resize_img = resize_util(img_PIL)
- tensor_resize_img = trans_util(resize_img) # trans_util为toTensor的转换器
- writer.add_image('resizeImg', tensor_resize_img)
- writer.close()
删除之前的log文件,重新运行
6. RandomCrop
随机裁剪(RandomCrop)是图像处理和计算机视觉任务中常用的技术,特别是在为图像分类或目标检测等任务训练卷积神经网络(CNN)的情境下。
在随机裁剪中,会提取输入图像的随机子区域或裁剪,并将其用作训练样本。这有助于引入训练数据的变化,从而提高模型的鲁棒性和泛化能力。通过在训练过程中随机裁剪图像的不同部分,模型学会关注数据中不同的特征和模式。
随机裁剪通常与其他数据增强技术结合使用,如随机旋转、翻转、缩放和颜色抖动,以进一步增加训练数据的多样性,并增强模型对未见示例的泛化能力。
randomcrop也是transforms中的一个工具,需要创建裁剪实例,然后传入pil的图片,然后会输出pil格式的img
首先引入依赖
- from PIL import Image
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
创建writer实例
writer = SummaryWriter("../logs")获取图片路径,获取pil图片
- img_path = "dataset/train/ants_img/t04f1f9f09c47b6150d.jpg"
- img = Image.open(img_path)
然后要剪裁,创建剪裁工具,我设置的是剪裁长宽为200的子图片
crop_util = transforms.RandomCrop(200)将pil图片剪裁
img_crop = crop_util(img)我想在Tensorboard中展示图片,需要用到add_image,而add_image里面要传入Tensor格式的图片
因此,首先要将pil转为Tensor图片
- tensor_util = transforms.ToTensor()
- tensor_img = tensor_util(img_crop)
执行add_image
writer.add_image("tensor_yiLeina", tensor_img)关闭writer
writer.close()打开Tensorboard看剪裁图片

效果如下

全部代码
- from PIL import Image
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
-
- writer = SummaryWriter("../logs")
- img_path = "dataset/train/ants_img/t04f1f9f09c47b6150d.jpg"
- img = Image.open(img_path)
- # RandomCrop
- crop_util = transforms.RandomCrop(200)
- img_crop = crop_util(img)
- tensor_util = transforms.ToTensor()
- tensor_img = tensor_util(img_crop)
- writer.add_image("tensor_yiLeina", tensor_img)
- writer.close()
7. compose
在PyTorch中,transforms.Compose是一个类,它接受一个变换操作的列表,并将它们组合成一个单一的可调用对象。当你对数据集应用这个组合的变换时,数据会按照列表中的顺序依次通过每个变换。这使得数据预处理变得既简单又可重复。
使用transforms.Compose的好处是它提供了一种清晰、模块化的方式来定义数据预处理流程,这有助于代码的维护和复用。此外,它还确保了所有数据都会经过相同的预处理步骤,这对于训练稳定的机器学习模型至关重要。
我们可以自己规划一个操作流程,比如,我规划的是,先将pil的图片resize,然后normalize归一化,然后随机剪裁,最后add_image循环执行十次
代码如下:
- from PIL import Image
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
-
- writer = SummaryWriter("../logs")
- img_path = "dataset/train/ants_img/t04f1f9f09c47b6150d.jpg"
- img = Image.open(img_path)
- # 先resize
- resize_util = transforms.Resize(600)
- # 转换为Tensor
- tensor_util = transforms.ToTensor()
- # normalize
- normalize_util = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
- # 然后RandomCrop,循环十次
- pil_util = transforms.ToPILImage()
- crop_util = transforms.RandomCrop(200)
- # 将所有操作整理为compose
- compose = transforms.Compose([resize_util, tensor_util, normalize_util, pil_util, crop_util, tensor_util])
- for i in range(10):
- compose_image = compose(img)
- writer.add_image("compose_img", compose_image, i)
- writer.close()
Tensorboard展示

四. dataset 与 transform
1.数据集下载
此处下载的数据集是cifar10
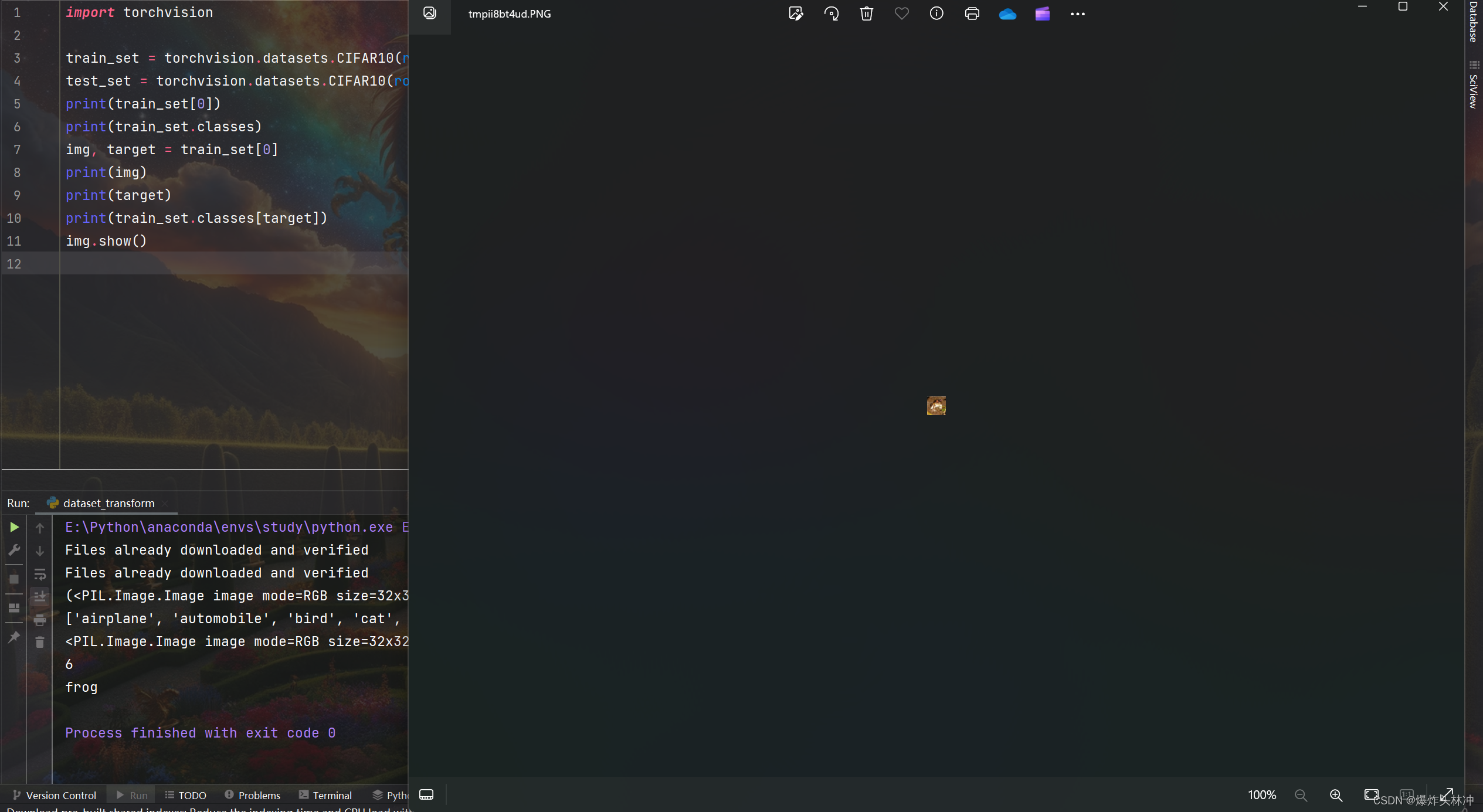
- import torchvision
-
- train_set = torchvision.datasets.CIFAR10(root="./data", train=True, download=True)
- test_set = torchvision.datasets.CIFAR10(root="./data", train=True, download=True)
运行效果如下

2.打印查看
打印查看数据集第0个元素
print(train_set[0])结果

使用img,target分别接收,并打印
img, target = train_set[0]结果

打印查看数据集中的类别
print(train_set.classes)结果
![]()
查看指定target图片类别
print(train_set.classes[target])结果
![]()
全部代码
- import torchvision
-
- train_set = torchvision.datasets.CIFAR10(root="./data", train=True, download=True)
- test_set = torchvision.datasets.CIFAR10(root="./data", train=True, download=True)
- print(train_set[0])
- print(train_set.classes)
- img, target = train_set[0]
- print(img)
- print(target)
- print(train_set.classes[target])
- img.show()
运行结果
3. 多图片处理
我的目的是获取包含多个数据的数据集,我们知道里面的图片是pil格式,我想要在Tensorboard中多个图片展示,因此要将数据集全部转换为Tensor格式,这步操作看似要遍历,挨个转化,实则可以一步到位
首先引入依赖
- import torchvision
- from torch.utils.tensorboard import SummaryWriter
创建writer实例
writer = SummaryWriter("../logs")创建格式转化器,使用的是compose,里面写了一步Tensor转化
- trans_tensor = torchvision.transforms.Compose([
- torchvision.transforms.ToTensor()
- ])
转化如何使用呢?在下载图片时直接用,添加transform属性,赋值为转化器,此时获取的是转化后的Tensor图片
- train_set = torchvision.datasets.CIFAR10(root="./data", train=True, transform=trans_tensor, download=True)
- test_set = torchvision.datasets.CIFAR10(root="./data", train=True, transform=trans_tensor, download=True)
我展示前十张图片
- for i in range(10):
- img, target = train_set[i]
- writer.add_image("datalist", img, i)
关闭
writer.close()运行后,Tensorboard展示
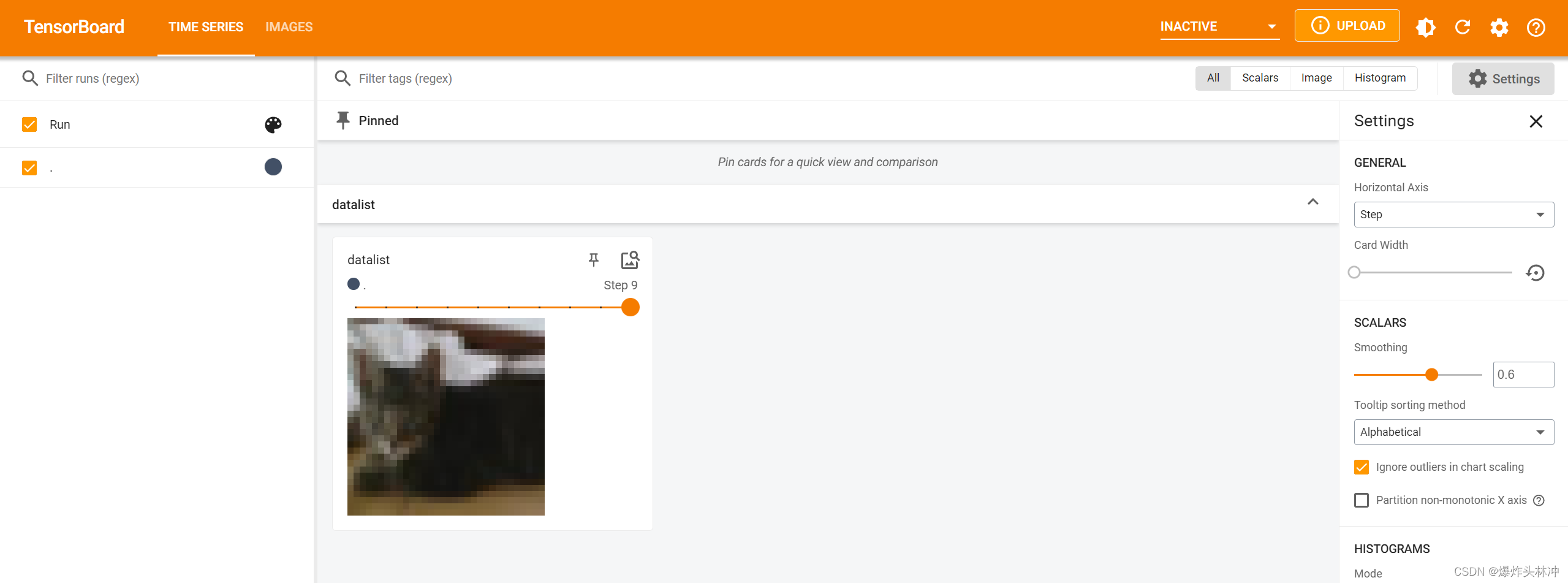
全部代码
- import torchvision
- from torch.utils.tensorboard import SummaryWriter
-
- writer = SummaryWriter("../logs")
- trans_tensor = torchvision.transforms.Compose([
- torchvision.transforms.ToTensor()
- ])
- train_set = torchvision.datasets.CIFAR10(root="./data", train=True, transform=trans_tensor, download=True)
- test_set = torchvision.datasets.CIFAR10(root="./data", train=True, transform=trans_tensor, download=True)
- for i in range(10):
- img, target = train_set[i]
- writer.add_image("datalist", img, i)
- writer.close()
五. dataloader
DataLoader在PyTorch中扮演着非常关键的角色,它用于封装和管理数据集的加载过程,使数据可以以批量(batch)方式供模型训练使用。这样做有几个主要的好处和功能:
-
批量加载:
DataLoader可以自动将数据分批加载,每一批数据包含多个元素,这对于利用现代计算库(如GPU)进行并行计算非常重要。 -
多线程/多进程加载:
DataLoader支持使用多线程或多进程来并行加载数据,这有助于提高数据加载的效率,尤其是在处理大型数据集时。 -
数据打乱与采样:在训练过程中,为了保证模型泛化能力,通常需要打乱输入数据的顺序。
DataLoader可以自动进行数据的随机打乱。此外,它还支持更复杂的数据采样策略,比如权重采样,这对于处理不平衡数据集特别有用。 -
与
Dataset的集成:DataLoader与PyTorch的Dataset对象紧密集成,可以从任何继承自Dataset的对象中加载数据。这为用户自定义数据加载和预处理提供了极大的灵活性。 -
自动化的异常处理:在数据加载过程中,
DataLoader能够优雅地处理可能发生的各种异常或错误,确保数据加载流程的稳定性。
dataloader主要的参数如下:
-
dataset:这是我们将要载入的数据集。这个数据集应该是继承自
torch.utils.data.Dataset的实例,包含了数据及其对应的标签。在你的例子中,test_set就是待加载的数据集。 -
batch_size:这是每个批次包含的数据样本数。这个参数主要是为了利用计算资源进行并行计算。在你的例子中,每个批次将包含64个样本。
-
shuffle:这是一个布尔型参数,用于控制是否在每个训练周期开始时打乱数据的顺序。在训练阶段设置
shuffle=True可以帮助模型泛化能力,防止模型记住数据的顺序。然而,在验证和测试阶段,我们通常设为shuffle=False,这样可以使结果的回现性更强。 -
num_workers:这是用于数据加载的子进程数。如果设置为0(如你的例子所示),则数据将在主进程中同步加载。对于大型数据集,设置更多的工作者可以加速数据加载,但也会增加内存用量。
-
drop_last:如果设置为
True,那么最后一个不完整的批次(即其样本数少于batch_size的批次)将被丢弃。这个参数在某些情况下会有用,例如,当批次的大小对应用网络的结构有要求时,或者当我们希望所有批次的大小完全相同时。在你的例子中,如果测试集的样本数不是64的倍数,那么最后不完整的那一批次将被丢弃。
引入依赖
- import torchvision
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
获取数据集,因为是测试集,所以train设置为了false
test_set = torchvision.datasets.CIFAR10(root="./data", train=False, transform=torchvision.transforms.ToTensor())创建dataloader数据加载器
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=True)创建writer实例
writer = SummaryWriter("../logs")循环使用add_images添加图片,注意是add_images,后面有s,因为一次获取的是多个图片
- step = 0
- for data in test_loader:
- imgs, targets = data
- writer.add_images("loaderImg", imgs, step)
- step = step + 1
关闭writer
writer.close()Tensorboard查看


