
- 1eNSP——vpn技术-gre与mgre_ensp路由器gre
- 2uniapp制作简单的tab切换_uniapp tab
- 3Python爬取网页数据并导入表格_python shtml 抓取
- 4RAL 2023开源 | 第一个基于NeRF的实时LiDAR SLAM!_nerf 2023
- 5解决办法:E: 仓库 “......” 没有 Release 文件_仓库没有release文件,无法使用该源进行更新
- 6NzN的数据结构--复杂度分析
- 7hbase 的Rowkey设计方案_hbase rowkey生成
- 8毕设选题 单片机51单片机智能药盒控制系统设计_基于51的智能药箱系统设计与实现
- 9Maven快速构建flink项目骨架(一、cmd方式)_archetyp flink
- 10Android单元测试全解_android 单元测试
英伟达推出免训练,可生成连贯图片的文生图模型ConsiStory,生成角色一致性解决新方案_consistory nvidia
赞
踩
目前,多数文生图模型皆使用的是随机采样模式,使得每次生成的图像效果皆不同,在生成连贯的图像方面非常差。
例如,想通过AI生成一套图像连环画,即便使用同类的提示词也很难实现。虽然DALL·E 3和Midjourney可以对图像实现连贯的生成控制,但这两个产品都是闭源的。
因此,英伟达和特拉维夫大学的研究人员开发了免训练一致性连贯文生图模型——ConsiStory。(即将开源)

相关链接
论文地址:https://arxiv.org/abs/2402.03286
论文简介
论文的核心内容是介绍了一个名为ConsiStory的文本到图像生成模型,该模型能够在无需额外训练的情况下生成连贯的图像序列。
ConsiStory模型主要解决了两个问题:一是识别和定位图像中的共同主体,二是在不同图像中保持主体的视觉一致性。为了实现这些目标,ConsiStory采用了主体驱动自注意力(SDSA)和特征注入等核心模块。
ConsiStory模型可以作为一种插件,帮助其他扩散模型提升文本到图像生成的一致性和连贯性。对在文本到图像生成领域实现更连贯和一致性输出的研究者和开发者来说,提供了一种新的解决方案。
论文解读

引言
文本到图像模型通过允许用户通过自然语言指导图像生成过程,提供了一种新的创造性灵活性。然而,使用这些模型在不同的提示下一致地描绘相同的主题仍然具有挑战性。现有的方法微调模型,教它描述特定用户提供的主题的新单词,或者向模型添加图像调节。这些方法需要冗长的每个主题的优化或大规模的预训练。此外,它们很难将生成的图像与文本提示对齐,并在描绘多个主题时面临困难。
本文提出了ConsiStory,一种无需训练的方法,通过共享预训练模型的内部激活,实现了一致的主题生成。我们引入了主题驱动的共享注意力块和基于对应的特征注入,以促进图像之间的主题一致性。此外,我们开发了鼓励布局多样性同时保持主题一致性的策略。我们将ConsiStory与一系列基线进行比较,并展示了在主题一致性和文本对齐方面的最先进的性能,而无需进行单一的优化步骤。最后,ConsiStory可以自然地扩展到多主题场景,甚至可以实现对常见对象的免训练个性化。
方法
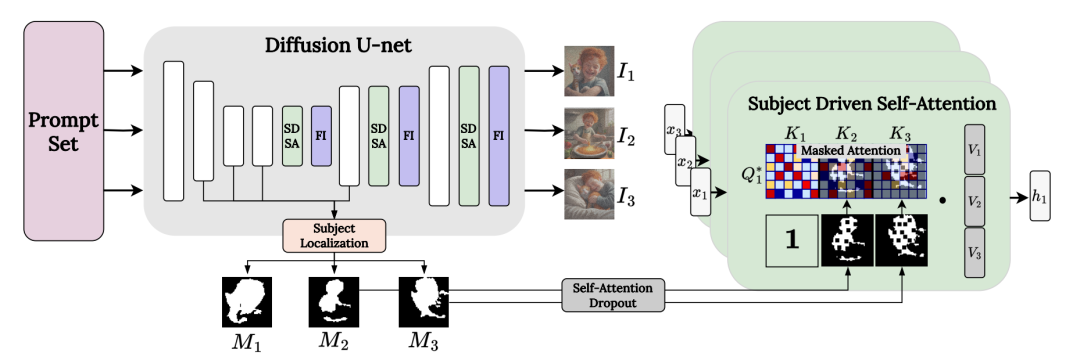
主体驱动自注意力(SDSA)
主体驱动自注意力(SDSA)是ConsiStory的核心模块之一。它通过扩展生成模型中的自注意力机制,使得在生成的图像批次中能够共享与主体相关的视觉信息,从而确保不同图像中主体的外观保持一致。
SDSA的关键在于扩大了自注意力层,使得一个图像中的“提示词”不仅可以关注自身图像的输出结果,还可以关注批次中其他图像的主体区域的输出结果。这样主体的视觉特征就可以在整个批次中共享,不同图像中的主体能够相互“对齐”,从而实现主体的一致性。
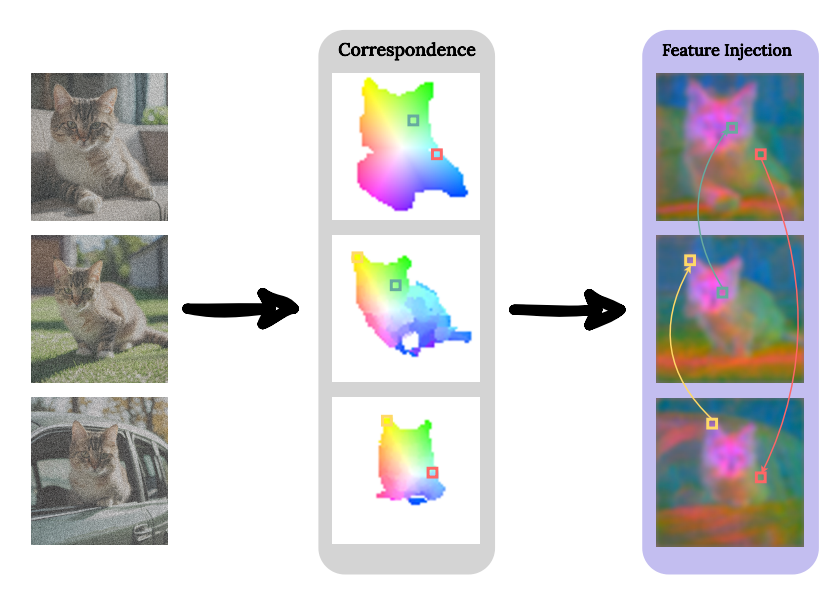
特征注入
为了,ConsiStory采用了“特征注入”机制。这一机制通过在图像生成过程中共享自注意力输出特征,加强了图像间相似区域(如纹理、颜色等)的一致性。
特征共享同样采用主体蒙版进行限定,同时设置了相似度阈值,以确保只在足够相似的区域之间执行特征共享。这样一来,只有在主体之间具有足够相似性的区域才会执行特征共享,从而确保了主体细节在不同图像之间的一致性,并避免了背景等不相关部分的影响。
实验
支持多个一致的主题
比如下图,不仅保留了男孩的特征,也保留了狗的特征。而其他方法通常至少忽略一个主题。

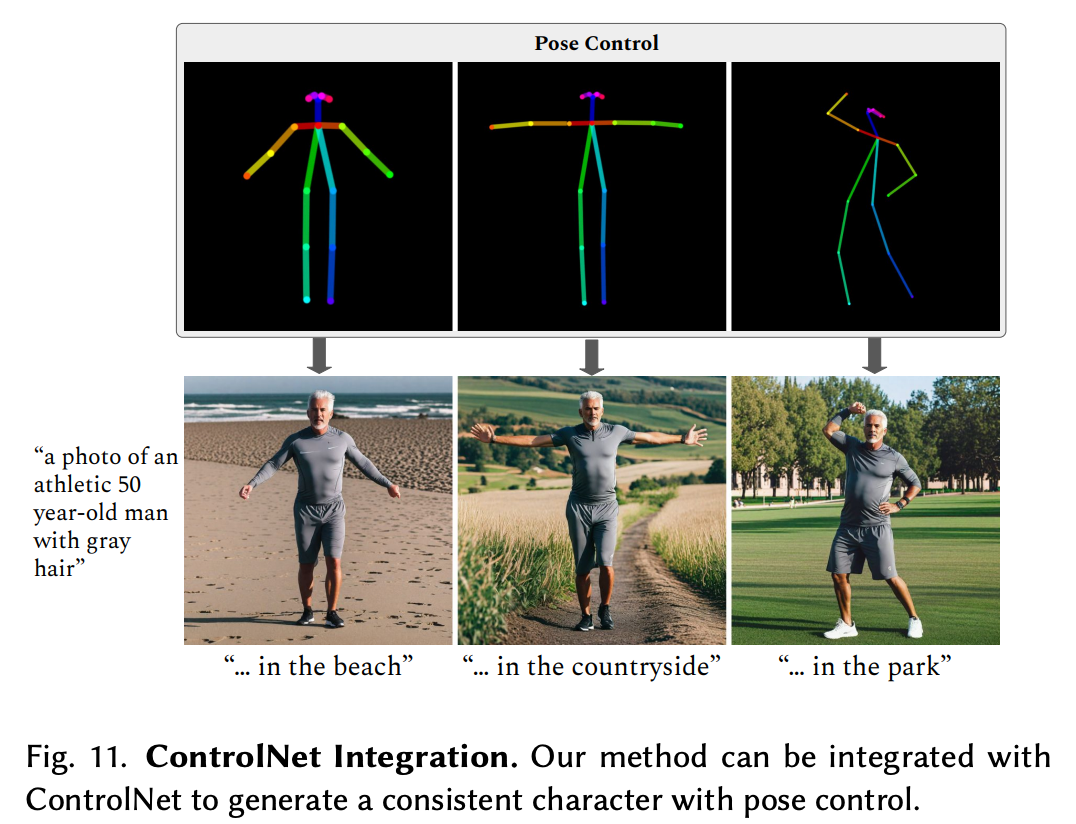
跟ControlNet集成
ConsiStory可以跟ControlNet集成,生成不同姿态的一致性的角色。
无需训练的个性化生成
简单理解就是图片转图片,将一张图片中的元素植入到另一张图片中,并保持该元素在新场景中自然融入,比如给左边的红色背包换背景。

变换种子值
每张AI生成的图片都有一个seed值,ConsiStory可以实现通过改变seed值(起始噪音)来变换场景,但主题不改变(如下图每行的猫头鹰)。

支持种族多样性
针对人像,ConsiStory可以保持该人物的种族特征不改变。

比较其他方法
如下图,最上面是ConsiStory方法,底下分别是IP-Adapter、TI、DB-LoRA方法,可以看下角色的一致性和对提示词的遵循程度,至少从官方提供的示例上看,ConsiStory都更胜一筹。

感谢你看到这里,也欢迎点击关注下方公众号或者关注本公众号的官方读者交流群,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

