
- 1单目深度估计综述(updating...)_单目深度估计 csdn
- 2Unity 2021版本,Unity打包Apk卡在calling IPostGenerateGradleAndroidProject callbacks_caling ipostgenerategradleandroidproject callbacks
- 3python数据分析:对抖音博主视频观看数据分析_基于python的视频信息的数据分析
- 4毕业设计课题:学生成绩管理系统,基于java+SSM+mysql
- 5托普利兹矩阵(T矩阵)及其应用(Matlab demo测试)_matlab生成托普利兹矩阵
- 66月GitHub上最牛逼的10个Java开源项目,号称“Star收割机“
- 7java学习笔记1_log4j详细配置狂神
- 8基于web青岛城市文化展示网站设计与实现
- 911.2 Go 常用包介绍
- 10机器学习之One-Hot Encoding_用onehotencoder函数对训数据集为
Shuffle的过程作用详解_shuffle 作用
赞
踩
shuffle
shuffle过程中的几个名词:shuffle:洗牌;spill:溢出;combiner:合成;merge:融入混合;copy:复制
shuffle的使用地点:发生在map task输出结果传送到reduce task 输入的阶段
使用shuffle的好处:在从map task端拉取数据到reduce task端时,减少宽带的消耗,
将数据完整的从map task端拉取数据到reduce task端
减少磁盘IO对task的影响
shuffle过程理解:
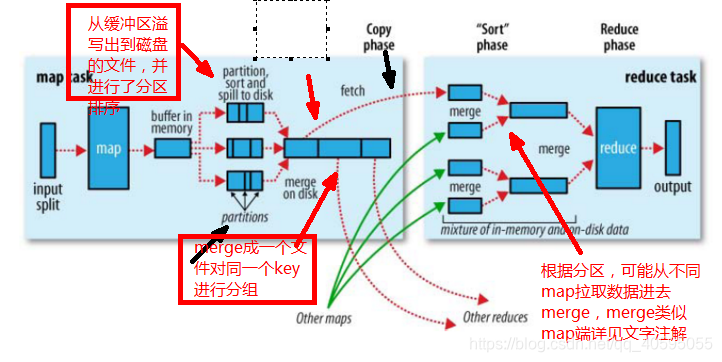
1.在map task端,输入的数据来源于hdfs,切分成片来读取,默认一个block对于一个split。
在map端执行详细过程:
2.在执行完mapper后,mapper的输出时k/v对。需要给reduce task处理,不同的k/v给哪个reduce处理呢(假设不只有一个reduce)
在这里执行partioner(默认是对key hash,在以ruduce 任务的数量取模。可以看源码)也可以自定义分区。
假如对一个key经过partitioner计算后得到0,那么就确定了分区是part-r-00000;
确定分区之后将该对值写入map的缓存区
1.就这样在map task端将输出的数据写入缓冲区直到到达阈值(默认缓冲区大小100M,阈值是80%).
达到阈值启动溢写线程(spill)将前面80M的数据写入到磁盘一个文件,这个单独的溢写线程不会影响map task,因为还有20M空间供map task输出结果
启动溢写线程后,对即将写到磁盘上的80M数据的key做排序(sort)。
2.前面处理了一个k/v进入到哪个reduce task,在讲很多k/v写入磁盘时,每一个都知道自己应该被哪个reduce执行,则在磁盘文件时去同一个reduce端的在一起拼团这个过程叫combiner。
combiner是个优化过程,这样可以减少map和reduce任务之间传输的中间数据,减少partition的索引记录。(例如我之前的单词计数例子中map输出的是<hello,1><hello,1>到reduce输入端时<hello,2>)
combiner的使用可以提高效率但是使用不当反而会影响效率。
在这里思考下:Combiner本身已经执行了reduce操作,为什么在Reducer阶段还要执行reduce操作?
combiner操作发生在map端,处理一个任务所接收的文件中的数据,不能跨map任务执行;只有reduce可以接收多个map任务处理的数据(reduce会拉取不同map 端输出的数据放入一个缓冲区)。
3.如果数据很大,会发生多次溢写既会有多个溢写文件。当map task完成,所有的输出数据都在一些磁盘溢写文件中,然后将多个溢写文件合并到一个文件中这个过程就是merge。
在merge时进行group,把不同map中的相同key合为一个做例如<hello,{1,1}>。如果设置了combiner也会合并切求和或者求平均值(自己定义)
注意,如果没有发生spill也没指定combiner产生的文件里存放的是map的输出例如<hello,1><hello,1>可以通过设置reduce task数量为0 查看part-m-00000文件看
3.到此map端工作结束,生成的这个文件存放在taskTracker能拿到的某个本地目录内,每个reduce task不断地通过RCP从JobTacker那后去map task是否完成。如果reduce task 得到通知获知
某台TaskTrack上的map task执行完成,shuffle开始执行将map的输出拉入reduce过程。
4.rudecer真正执行之前就是不断的拉取当前job里的每个map输出结果然后不断的merge,最终形成一个文件作为reduce task的输入文件。
在reduce 端执行详细过程:
1.copy过程:拉取数据,reduce进程启动一些数据copy线程(Fetcher),通过http方式请求map task所在的TaskTrack 获取map task输出文件(文件被TaskTracker管理在本地磁盘)。
2.merge阶段:merge 动作copy过来的数据先放入内存缓冲区,merge有三种方式:1内存到内存;2内存到磁盘,3磁盘到磁盘默认不启用第一种。类似map中的过程,当到达阈值时也会spill,如果设置combiner也会启用,
在磁盘溢写了很多文件,直到map端没有数据,第二种merge方式结束。然后启用第三种方式merge生成最终的哪个文件
3.reduce的输入文件:最后生成的那个文件默认存在磁盘中shuffle结束,然后执行reducer,把结果放到HDFS上

