
热门标签
热门文章
- 1读人工智能时代与人类未来笔记19_读后总结与感想兼导读
- 22024年Python最新Python二级考试试题汇总(史上最全)_计算机二级python真题_2024安徽python省二级模拟
- 3如何面试Web前端开发工程师_如何面试有4年经验的web前端工程师
- 4git合并指定分支上的文件到当前分支_如何合并其他分支的指定文件或代码块到当前分支
- 5git 合并指定文件到当前分支_apply this hunk to index and worktree
- 6【UE5:CesiumForUnreal】——从地球全景聚焦到某区域的动画制作_cesium实现全景图
- 7[Vue-常见错误]浏览器显示Uncaught runtime errors_uncaught runtimeerror: indirect call to null
- 8GPT实战系列-智谱GLM-4的模型调用_智谱glmchat4实战
- 9LabVIEW开发指针式压力仪表图像识别
- 10Ambari——大数据平台的搭建利器
当前位置: article > 正文
几个nlp的小项目(文本分类)_mamba文本分类
作者:AllinToyou | 2024-06-15 15:45:23
赞
踩
mamba文本分类
导入加载数据类、评测类
load_dataset: 加载数据集
load_metric:加载评测类

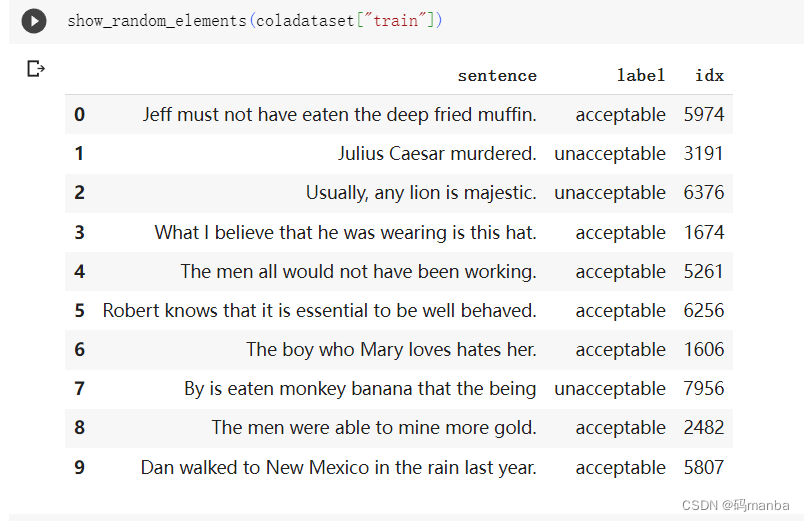
查看数据集

精确展示数据
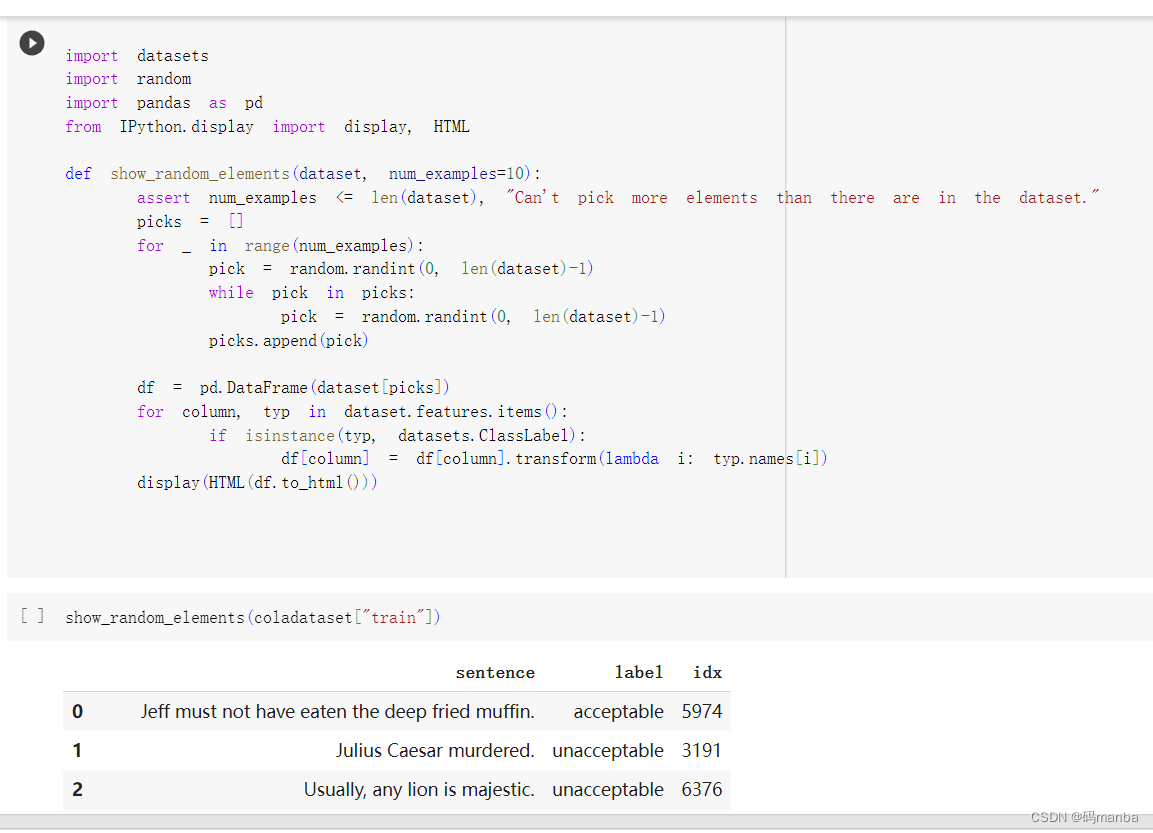
测评方法
传入 预测值和具体值

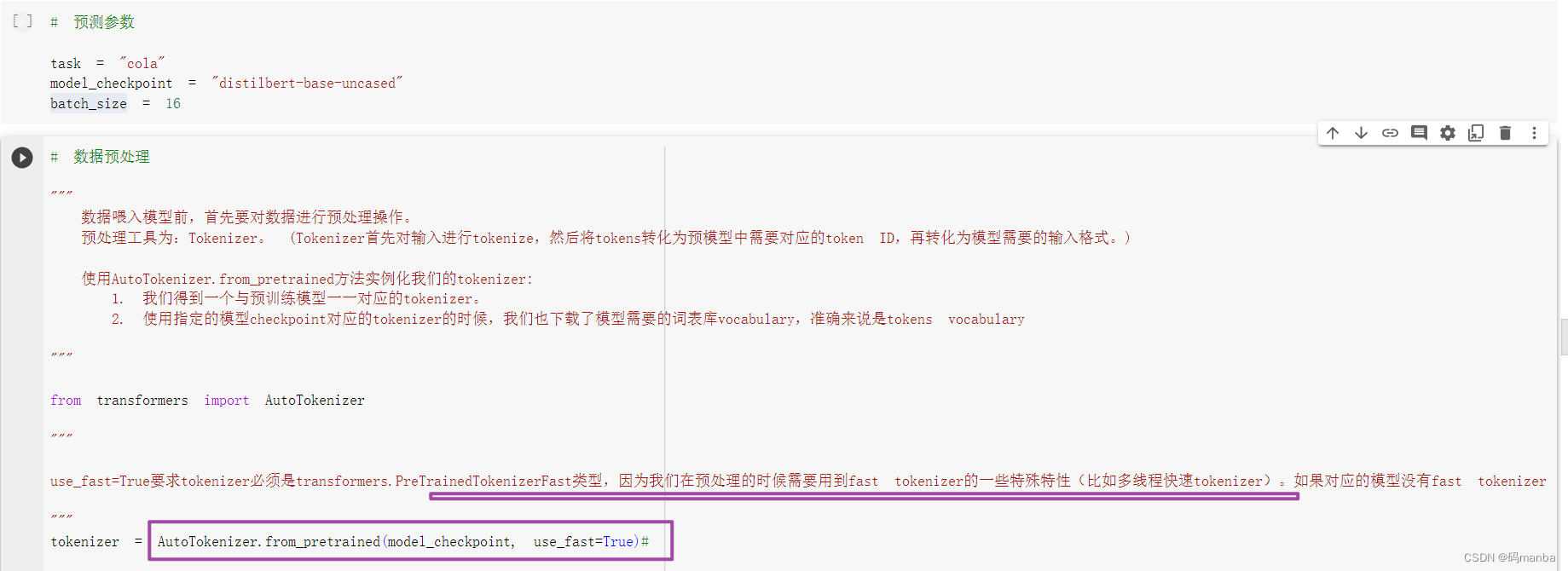
设置参数
task: 选择的任务,可加载数据集
model_checkpoint: 设置加载模型的名称
batch_size: 批量大小
distilbert-base-uncased模型介绍

tokenizer,token化的解释
数据喂入模型前,首先要对数据进行预处理操作。
预处理工具为:Tokenizer。 (Tokenizer首先对输入进行tokenize,然后将tokens转化为预模型中需要对应的token ID,再转化为模型需要的输入格式。)

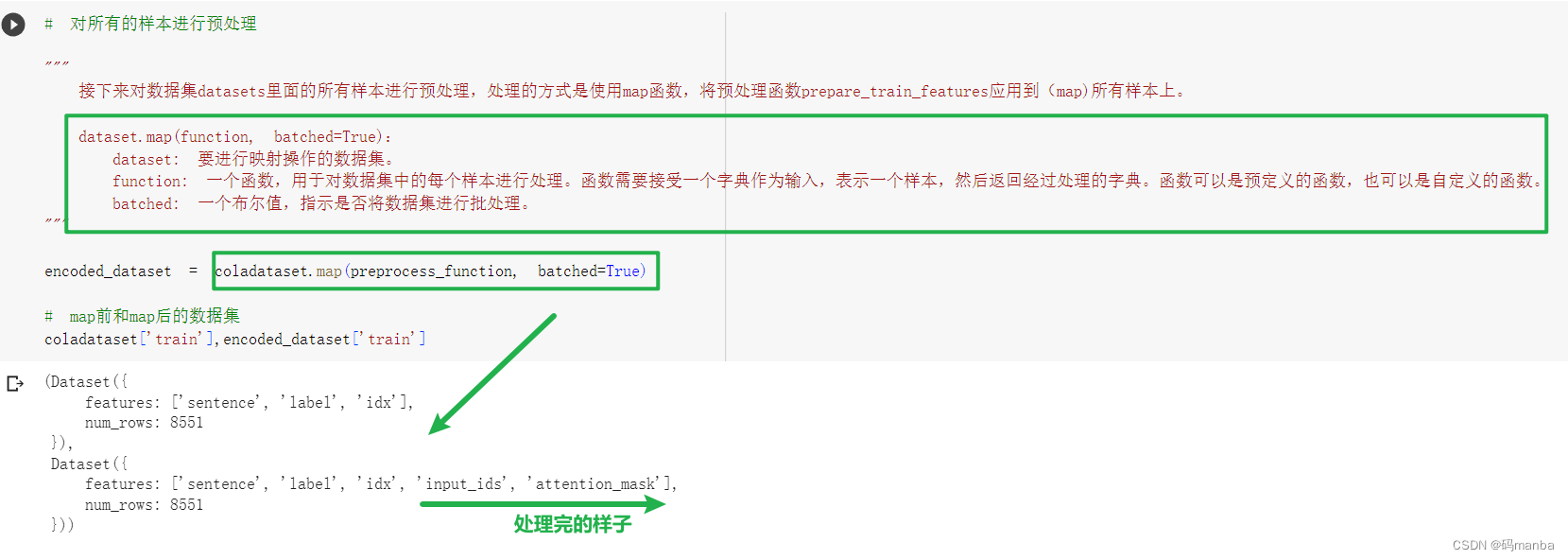
对数据集进行预处理
加载预训练模型进行训练

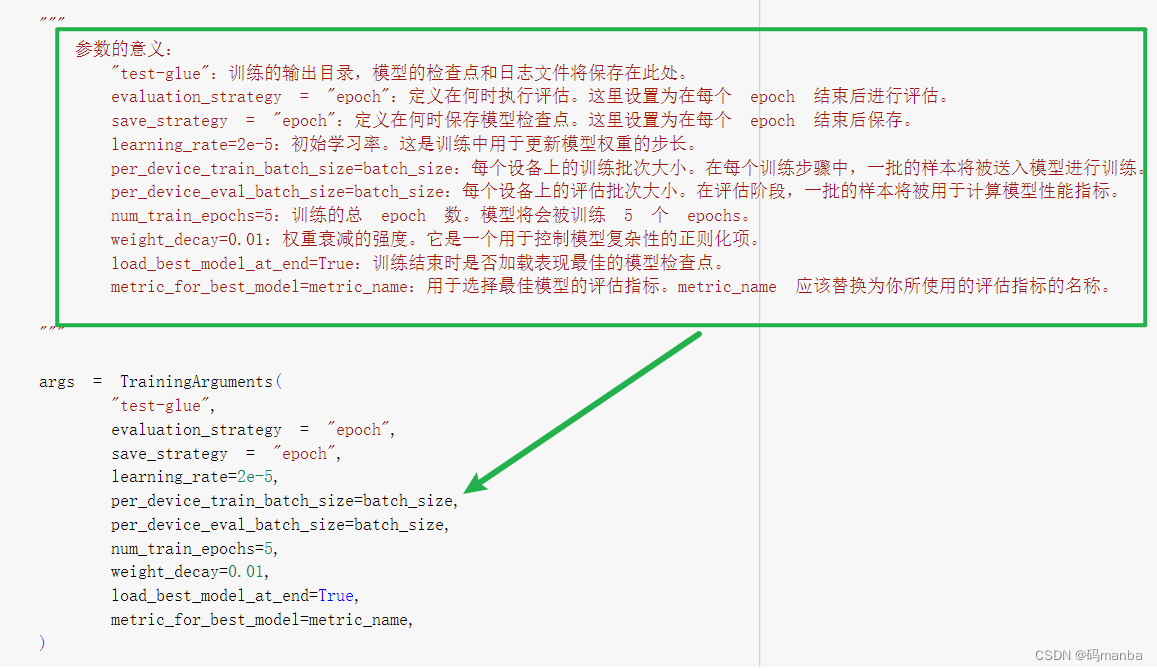
设置训练模型的参数
一个根据任务名获取,测评方法的函数


创建预训练模型
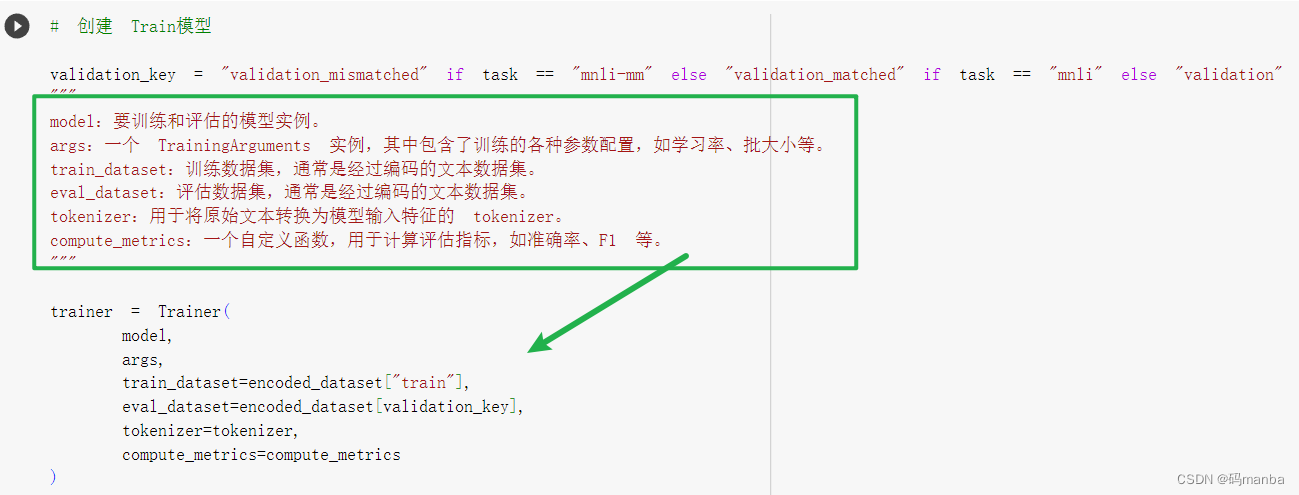
开始训练
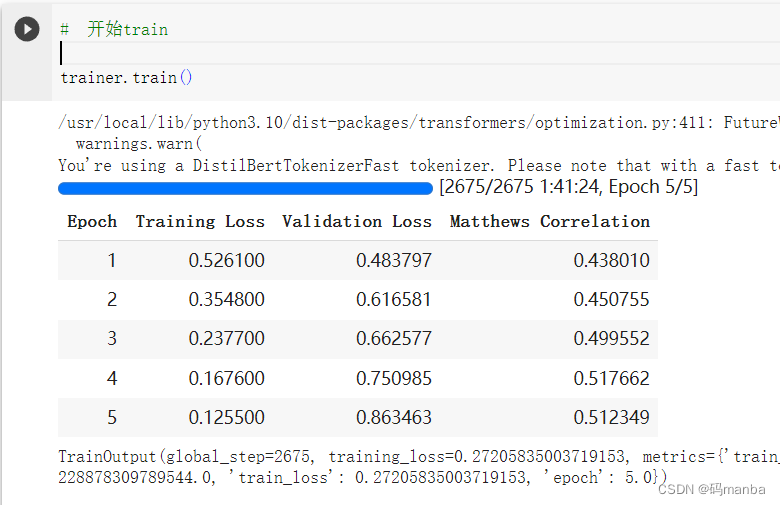
本项目的工作完成了什么任务?
判断了 某个句子的语法是否正确,根据label进行反向传播训练!
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/722854
推荐阅读
相关标签

