
- 1【Vue框架系列】Vue框架快速入门(基于Vue2)_vue2框架
- 2指向结构体的指针p++与p = p->next的区别_p->next和p++
- 3python s append_详细介绍pandas的DataFrame的append方法使用
- 4MFC 如何实现edit框内只能输入数字包括负号_mfc编辑框 正负数
- 5【详解】Spring Security 之 SecurityContext
- 6bootstrap modal填充数据_Bootstrap使用模态框modal实现表单提交弹出框
- 7html折叠导航菜单,JS实现移动端可折叠导航菜单(现代都市风)
- 8一次高并发下生成js随机数的实践_js new date().gettime()高并发
- 9阿里云ecs环境搭建—— 六、七 tomcat和nginx
- 10借用GitHub将typora图片文件快速上传CSDN
人手一个编程助手!北大最强代码大模型CodeShell-7B开源,性能霸榜,IDE插件全开源_掘力计划第27期 codeshell:本地化轻量化的智能代码助手
赞
踩
今天,北京大学软件工程国家工程研究中心知识计算实验室联合四川天府银行AI实验室,正式开源70亿参数的代码大模型CodeShell,成为同等规模最强代码基座。
与此同时,团队将软件开发代码助手的完整解决方案全部开源,人手一个本地化轻量化的智能代码助手的时代已经来临!

CodeShell代码:https://github.com/WisdomShell/codeshell
CodeShell基座模型:https://huggingface.co/WisdomShell/CodeShell-7B
代码助手VSCode插件:https://github.com/WisdomShell/codeshell-vscode
具体来说,CodeShell-7B基于5000亿Tokens进行了冷启动训练,上下文窗口长度为8192。
在权威的代码评估基准(HumanEval和MBPP)上,CodeShell取得同等规模最好的性能,超过了CodeLlama-7B和StarCodeBase-7B。
与此同时,同CodeShell-7B配套的量化与本地部署方案,以及支持VSCode与JetBrains IDE的插件也全部开源,为新一代智能代码助手提供了轻量高效的全栈开源解决方案。
CodeShell模型和插件的相关代码已经在Github发布,并严格遵循Apache 2.0开源协议,模型在HuggingFace平台发布,支持商用。
CodeShell:性能最强的7B代码基座大模型
CodeShell构建了高效的数据治理体系,通过冷启动预训练5000亿Token,代码生成性能超过了CodeLlama-7B与StarCoder-7B。
相比而言,CodeLlama在强大的Llama2上继续预训练依然学习了超过5000亿Token,而StarCoder冷启动训练了10000亿Token,是CodeShell的两倍。
CodeShell的原始训练数据基于自己爬取的Github数据、Stack和StarCoder数据集,以及少量高质量的中英文数据。
通过在数据判重、数据过滤规则、数据质量模型上设计了一套体系化的数据治理流水线,CodeShell构建了高质量的预训练数据。
CodeShell构建了包含7万个词的词表,中文、英文、代码的压缩比分别为2.83、3.29、3.21,支持中英文和代码的平衡且高效的编解码。
在更小规模的各种基座架构上进行大量预训练实验后,CodeShell架构设计最终融合了StarCoder和Llama两者的核心特性。
以GPT-2为基础,采用fill-in-middle(FIM)模式支持代码特有的补齐生成方法,引入Grouped-Query Attention和ROPE位置编码,最终形成了CodeShell高性能且易于扩展上下文窗口的独特架构。
为了获得最大的分布式训练效率,Codeshell基于Megatron-LM,在Attention算子优化、数据预处理、数据加载、日志输出、状态监控、分布式训练管理等方面进行了深度定制,支持Flash Attention2加速,训练吞吐量达到了每GPU每秒3400 Token的业界先进水平。
CodeShell预训练的上下文窗口为8192。经过5000亿Token训练,CodeShell在humaneval和mbpp两个主流评测数据集都体现了明显的优势。在humaneval的其它编程语言评测中,如JavaScript、Java、C++,CodeShell依然性能领先。
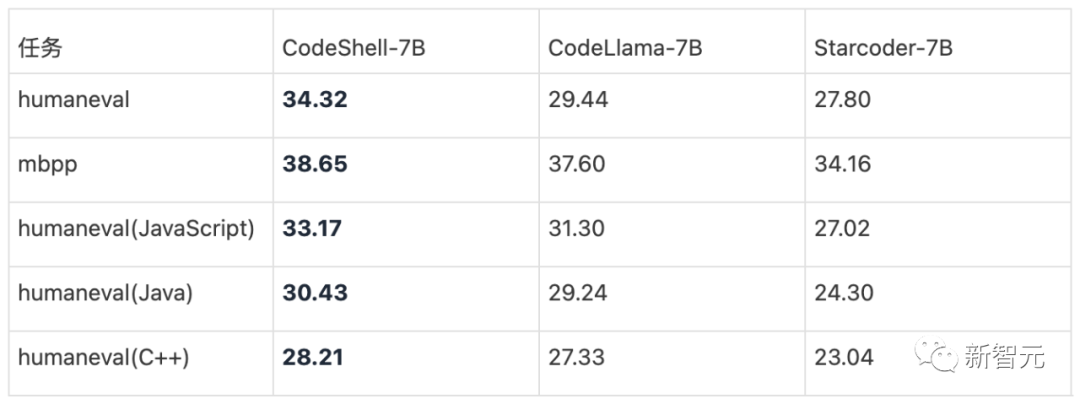
在CodeShell的训练中团队发现,通过刻意「刷榜」训练,可以让代码基座评分「虚高」,但是在实际应用和微调中无法体现与分数匹配的潜力。
为了验证CodeShell预训练的「纯粹性」,团队采用WizardCoder的Evol-instruction数据构建方法生成微调数据,使用这份数据分别对CodeShell、CodeLlama、StarCoder进行微调,并用WizardCoder提供的Prompt进行统一的HumanEval评估。这一场景下CodeShell依然保持优异性能,充分验证了CodeShell的真实底座能力。
CodeShell在Hggingface权威的代码大模型榜单中的表现也极其亮眼!在这份榜单中,各种经过特定优化的代码基座和微调模型,在HumanEval评分上可以超越CodeLLama,但是体现综合能力的综合胜率(Win Rate)与CodeLlama却依然有很大差距。
令人惊喜的是,CodeShell不仅在HumanEval上霸榜7B模型,综合胜率与CodeLlama-7B持平。考虑到CodeLlama-7B训练的Token数量超过两万五千亿,而CodeShell的数量仅为五分之一,这份榜单充分体现了CodeShell团队的技术实力。
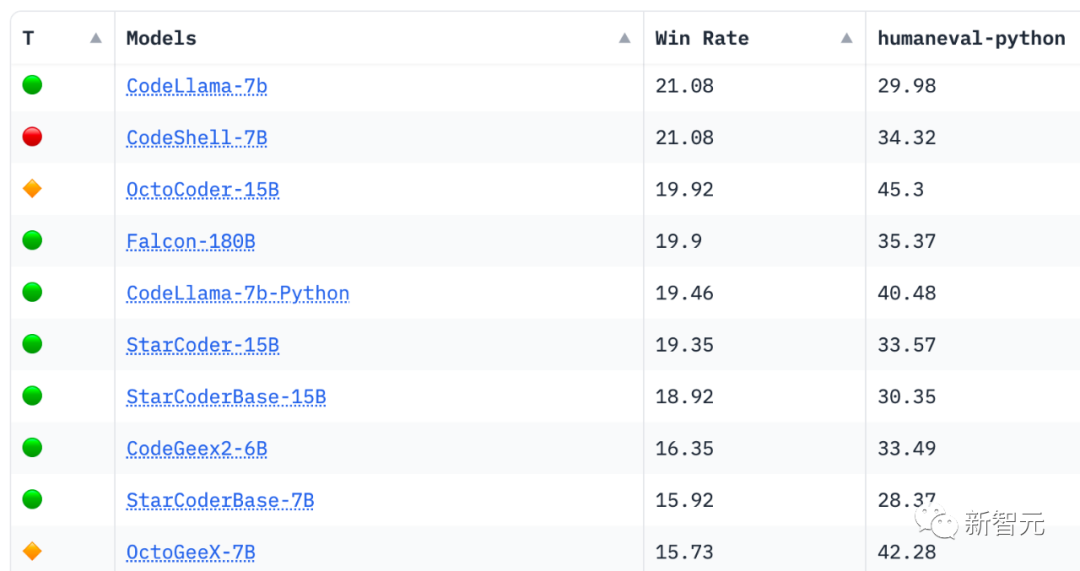
正在研发中的CodeShell新版本将在强大的代码能力基础进一步提升中英文处理能力,综合能力值得更大的期待。
CodeShell-Chat:功能齐全的代码助手模型
在CodeShell底座基础上,团队面向真实的软件开发场景,通过高效微调,训练了支持对话、代码生成、代码补齐、代码注释、代码检查与测试用例生成的全能代码助手模型CodeShell-Chat。
为此,CodeShell团队分别构造了数万条高质量代码对话数据和代码补齐数据,设计了基于规则与基于嵌入表示相结合的微调数据筛选方法,构造了多任务一致的微调数据格式,并在基座模型上采用任务分类优化策略进行小规模微调,最终得到了高效实用的代码助手模型。
为了进一步降低使用门槛,支持轻量级本地部署,团队针对CodeShell独有的架构扩展了llama.cpp —— 一个纯 C/C++ 实现的LLaMA模型高效推理接口,以支持CodeShell的模型在各种计算架构中的格式转化、推理运行以及量化部署。
在16G内存的苹果笔记本上进行推理,响应速率可达每秒18 Token,真实的使用体验非常流畅。
想象一下,一个在飞行途中的程序员,打开普通的Mac电脑,即可使用性能几乎无损、仅占4G内存的4-bits量化版本。本地部署不仅保障了数据安全,更是可以随时随地使用!

方便易用的CodeShell代码助手插件
对众多开发者而言,即便拥有功能强大的代码助手模型,其应用门槛仍然过高。
为此,CodeShell团队诚意满满地把IDE插件也开源了!
IDE插件目前支持VSCode和IntelliJ IDEA,适用于各种主流编程语言。
在开发过程中,CodeShell代码助手插件提供了两种模式,即专注模式和交互模式,两种模式相互协同,共同提升开发效率。
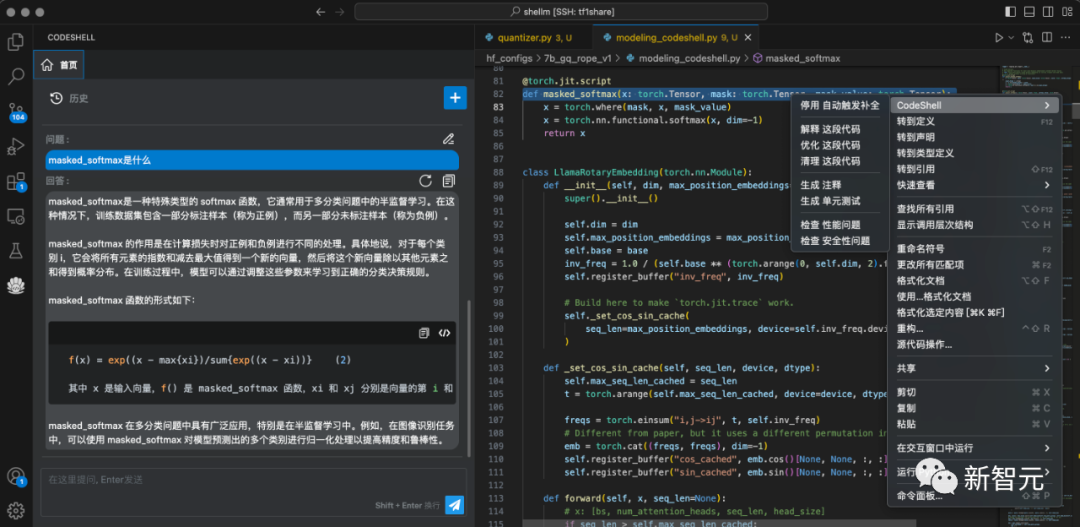
在专注模式下,通过对当前项目代码的分析,提供代码提示与补全功能,从而提高编程效率。
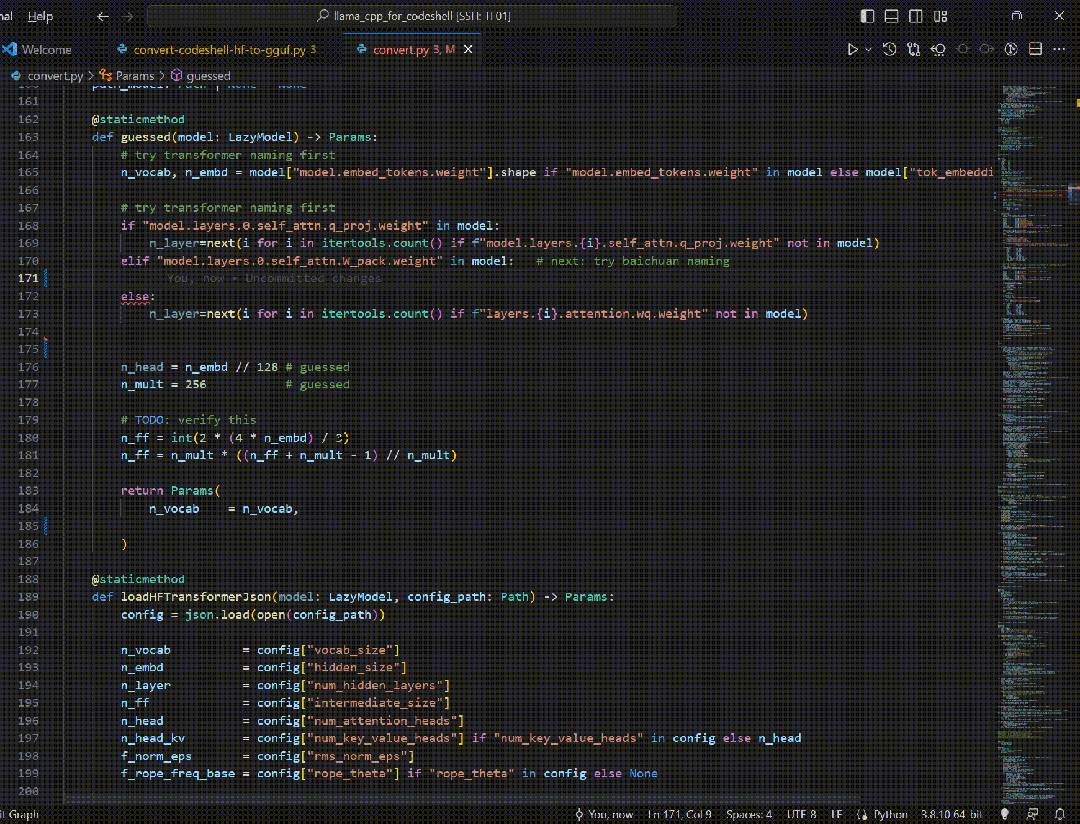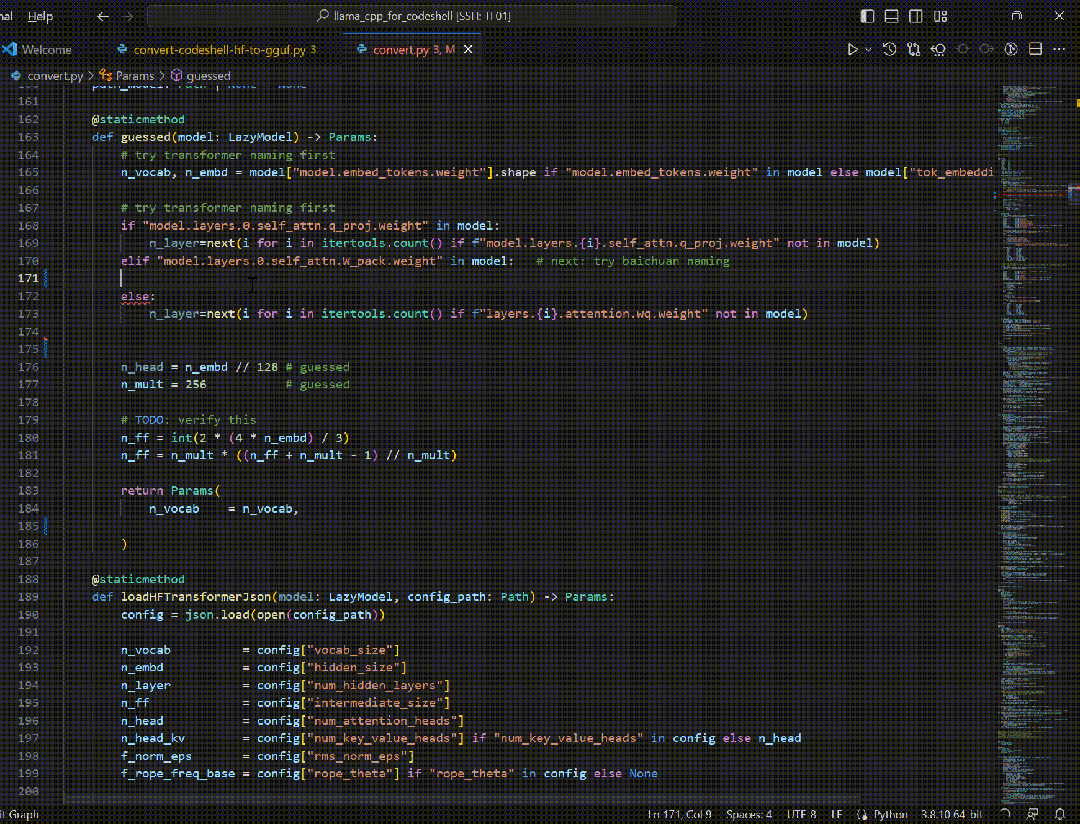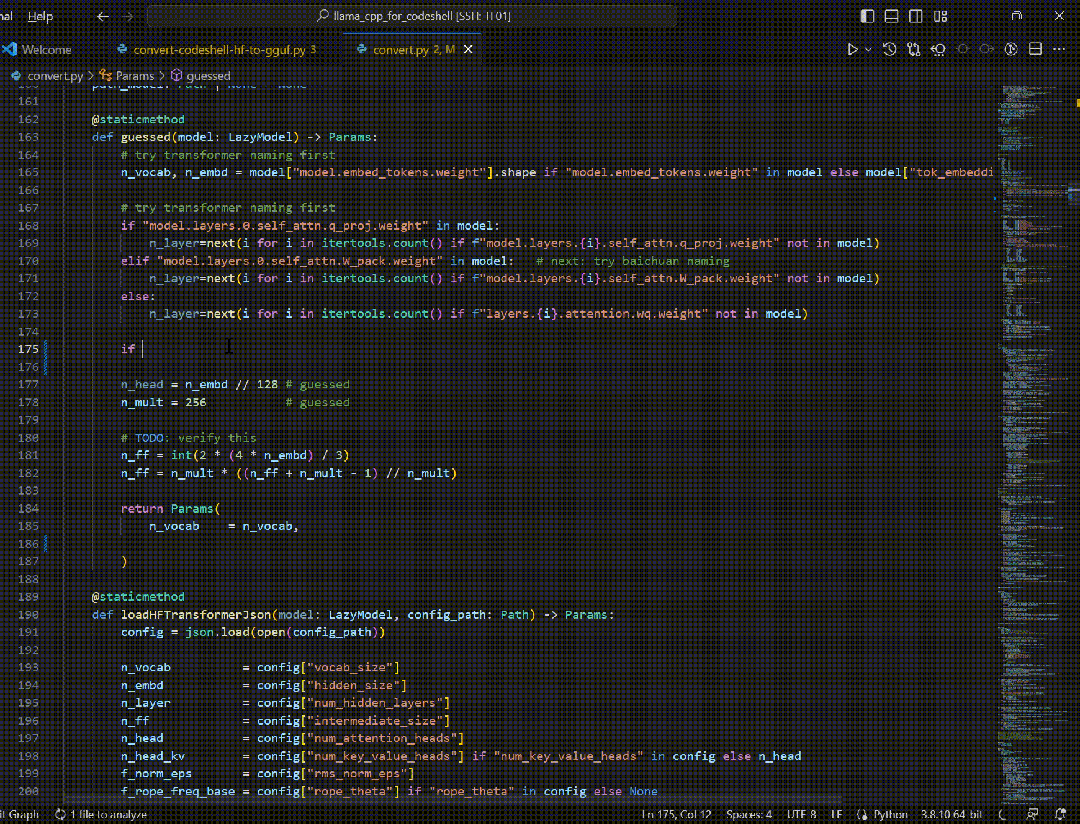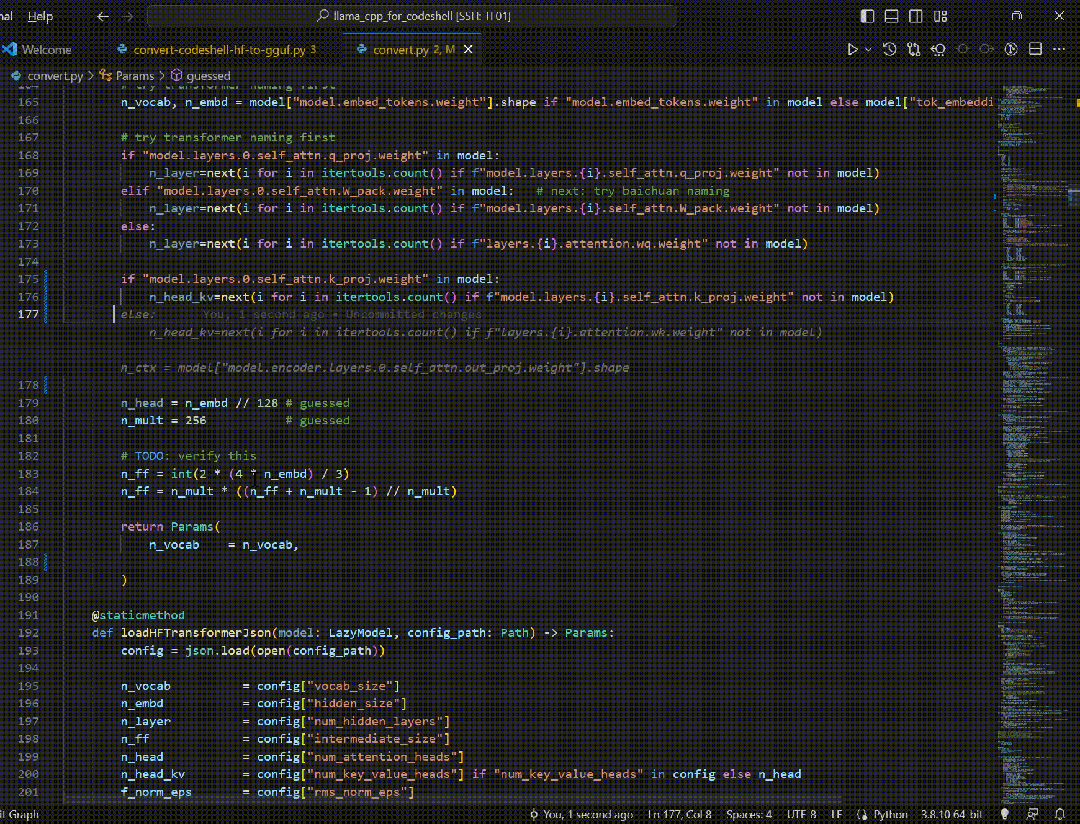
在交互模式下,IDE插件通过向代码助手大模型发送特定的交互Prompt和用户输入,可提供丰富的功能,来看几个实例。
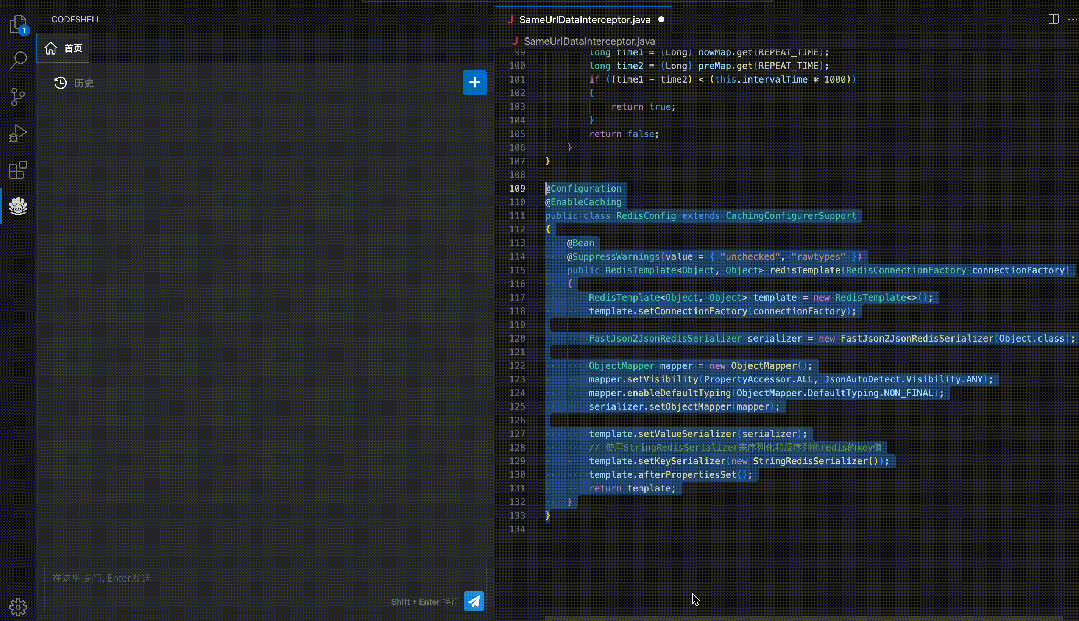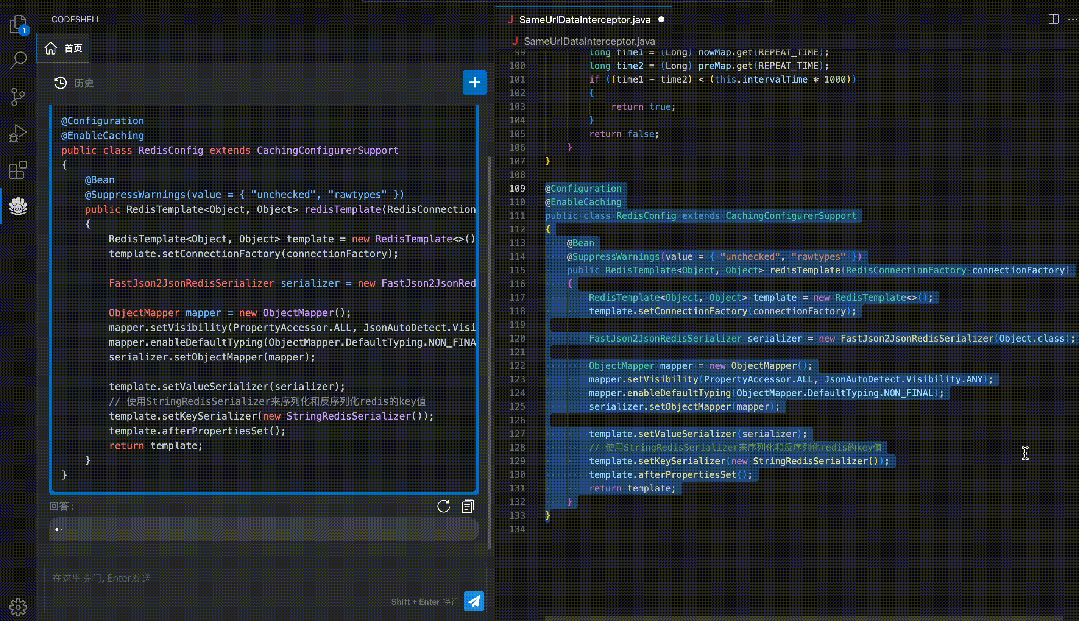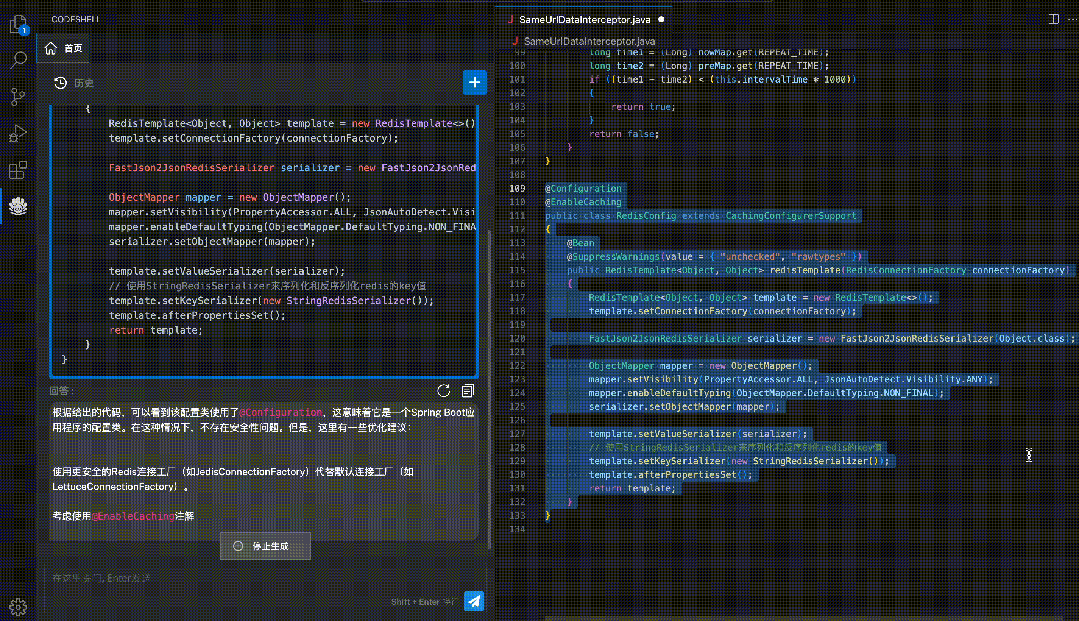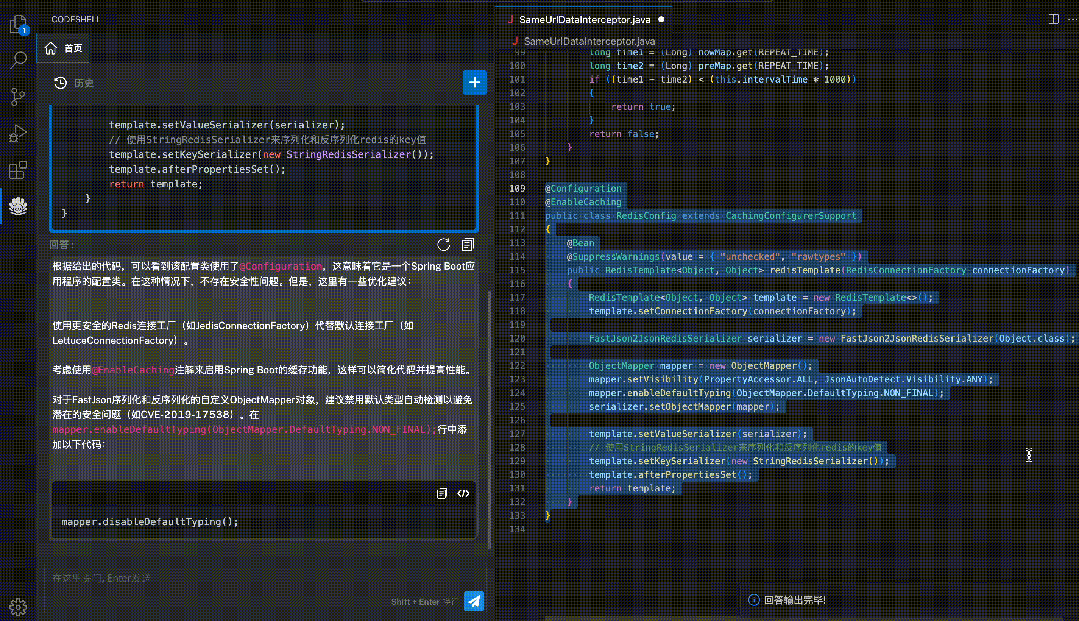
智能问答:在编程过程中直接向代码助手模型提出问题,无需切换至其他界面,支持对话与编程两种场景无缝融合。
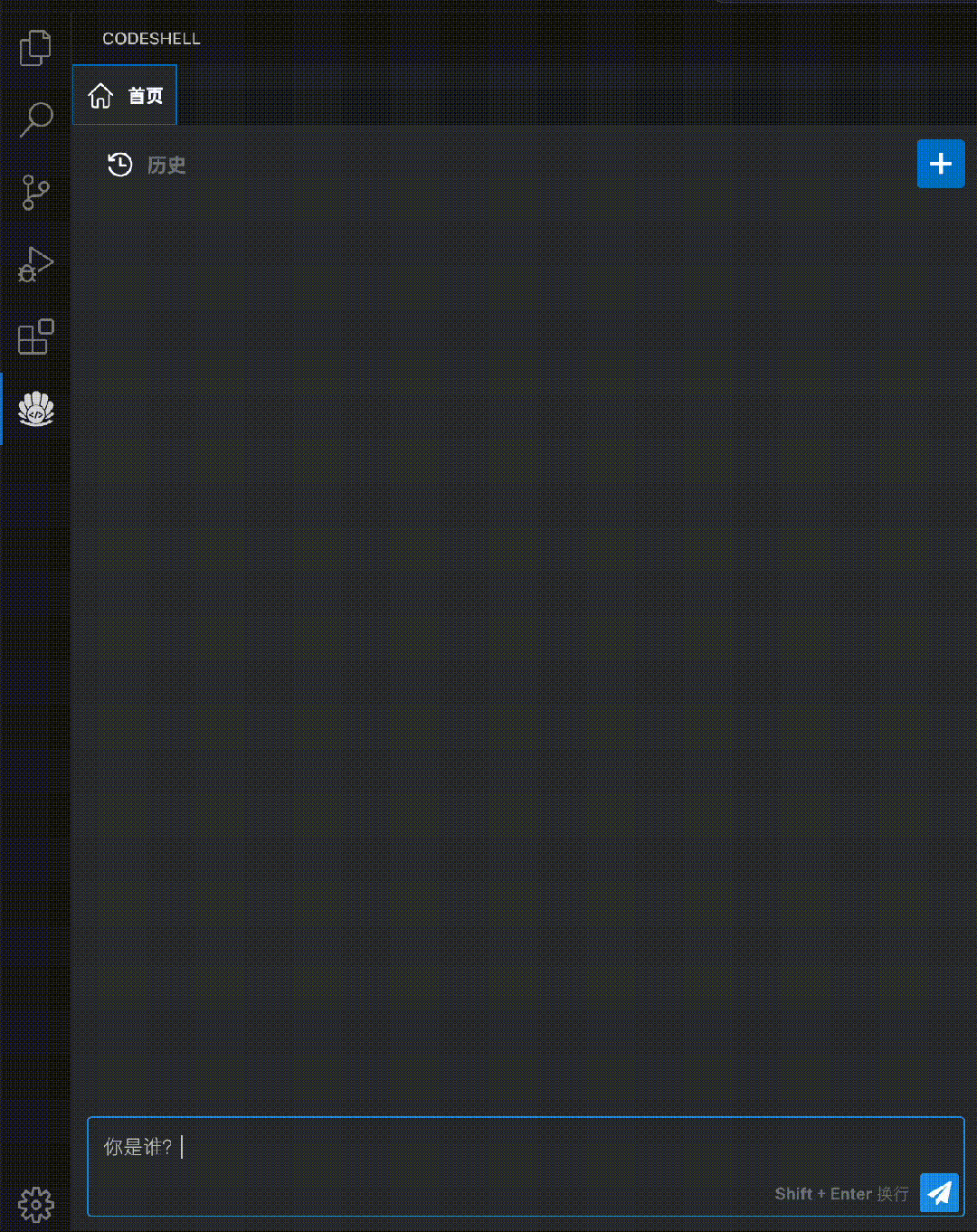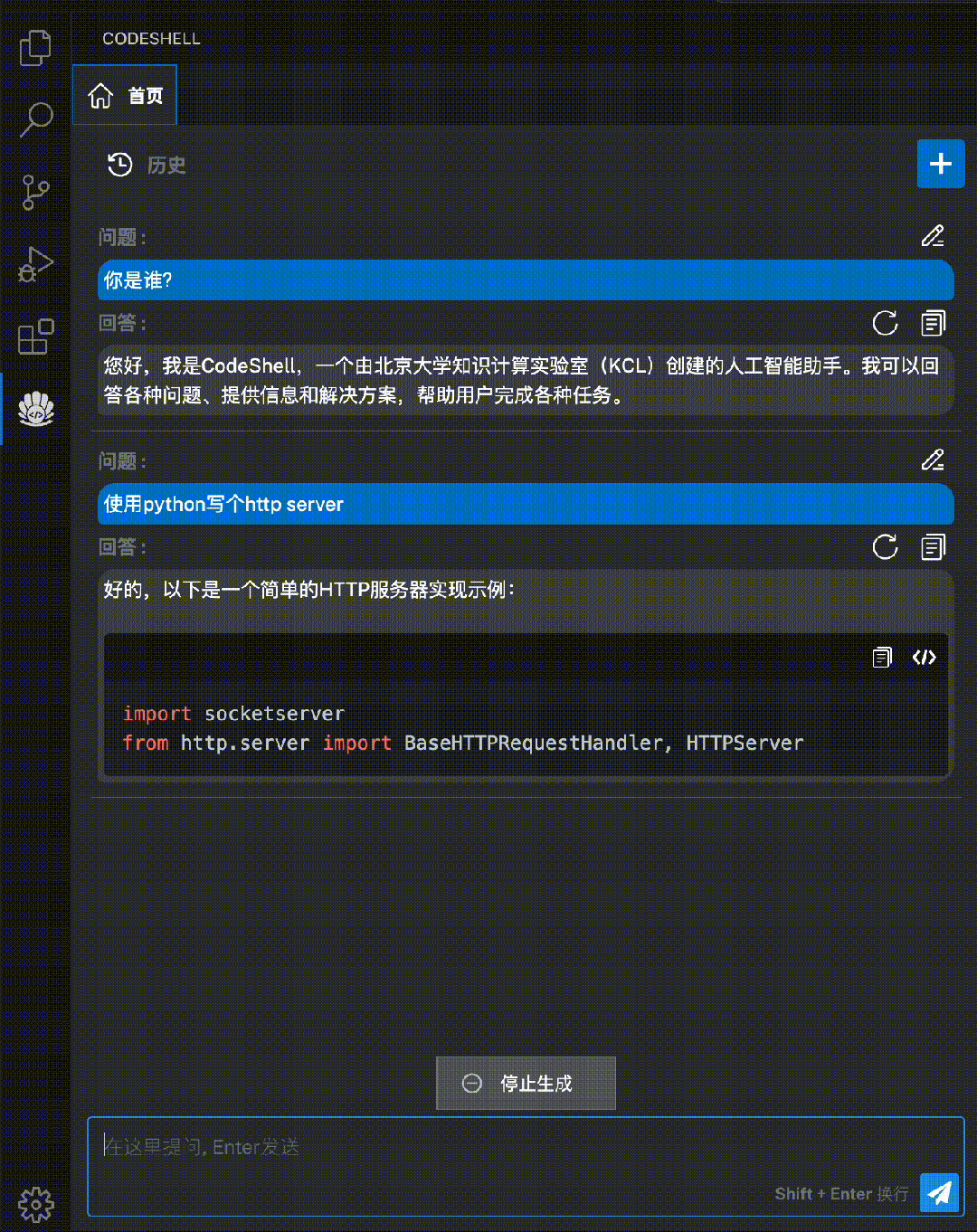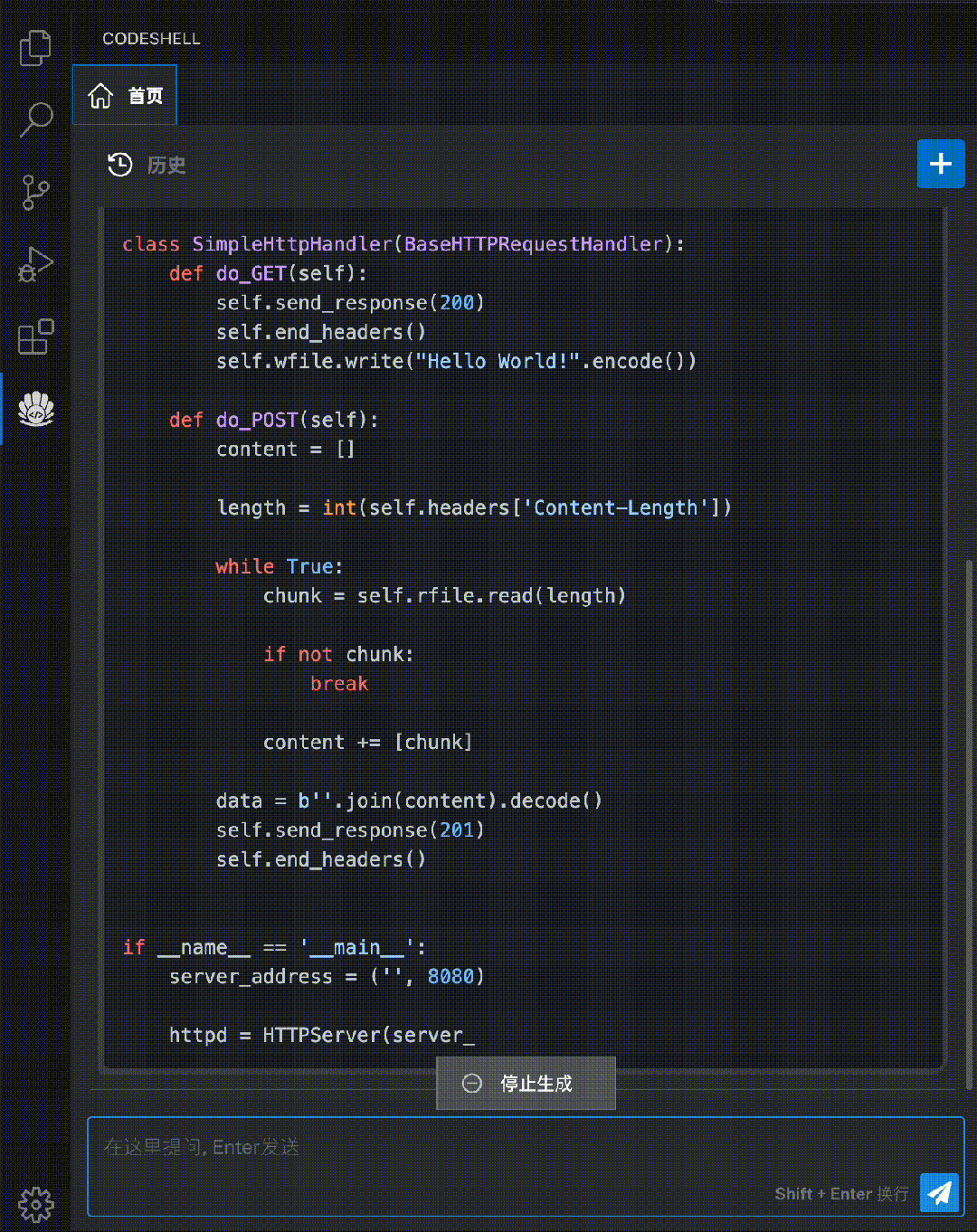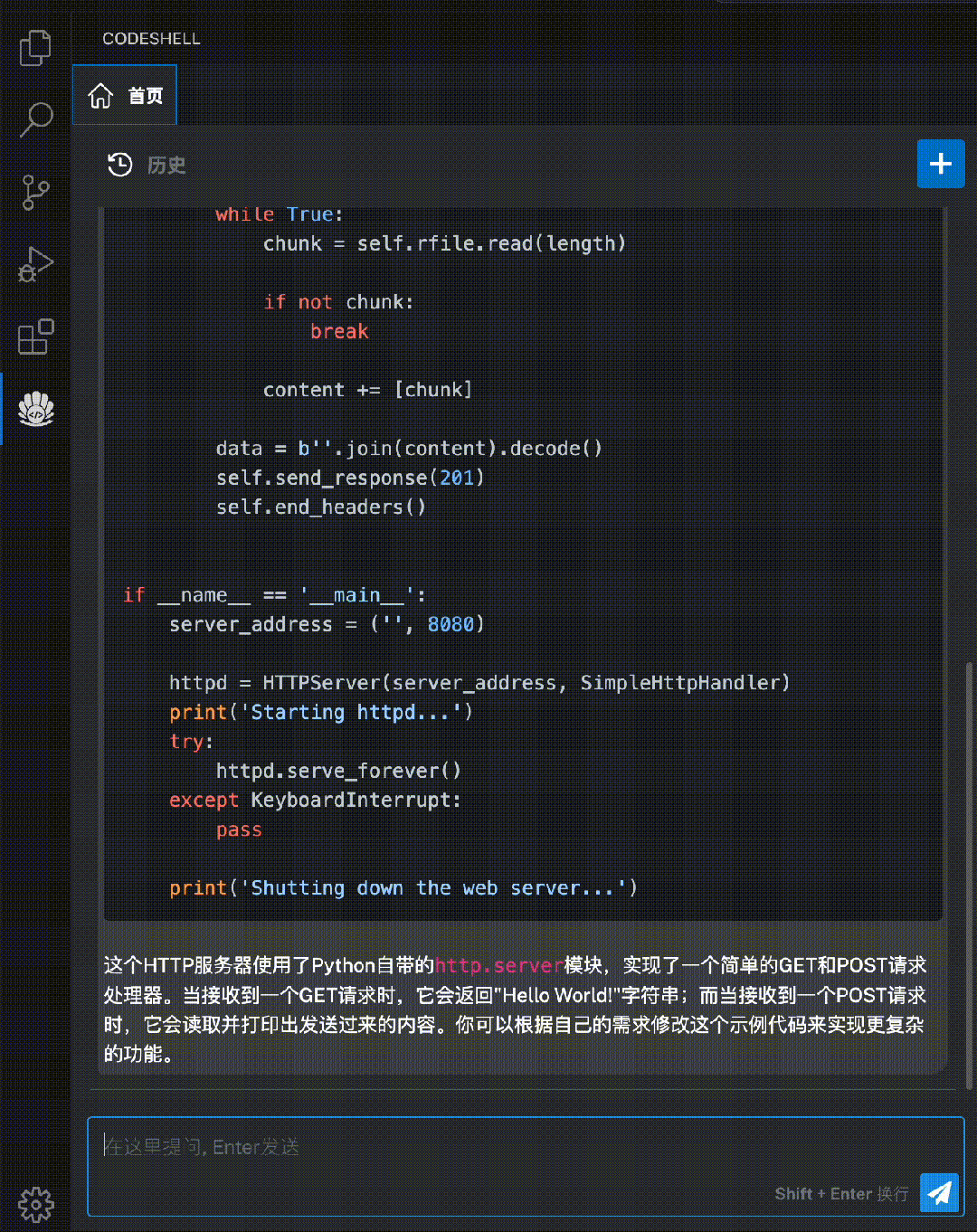
代码解释:使用自然语言解释代码的运行过程,让开发者更好地理解代码的结构和逻辑。
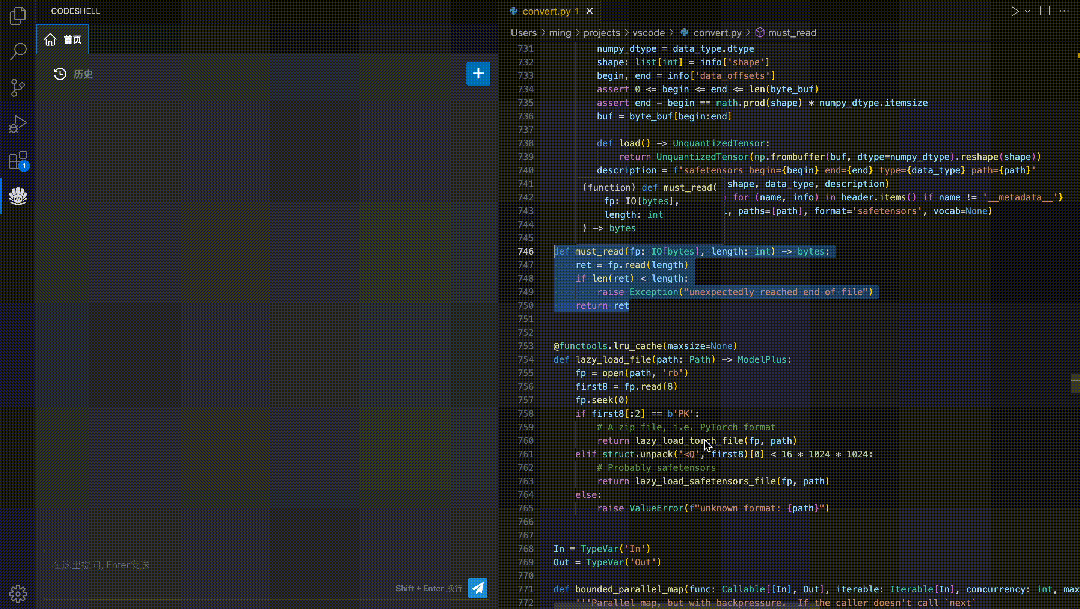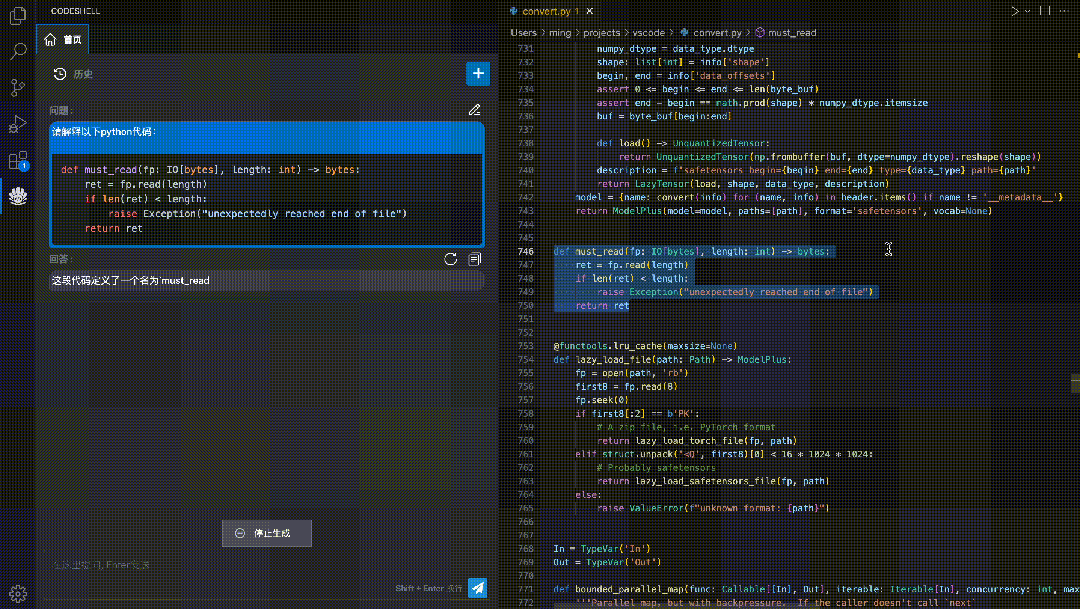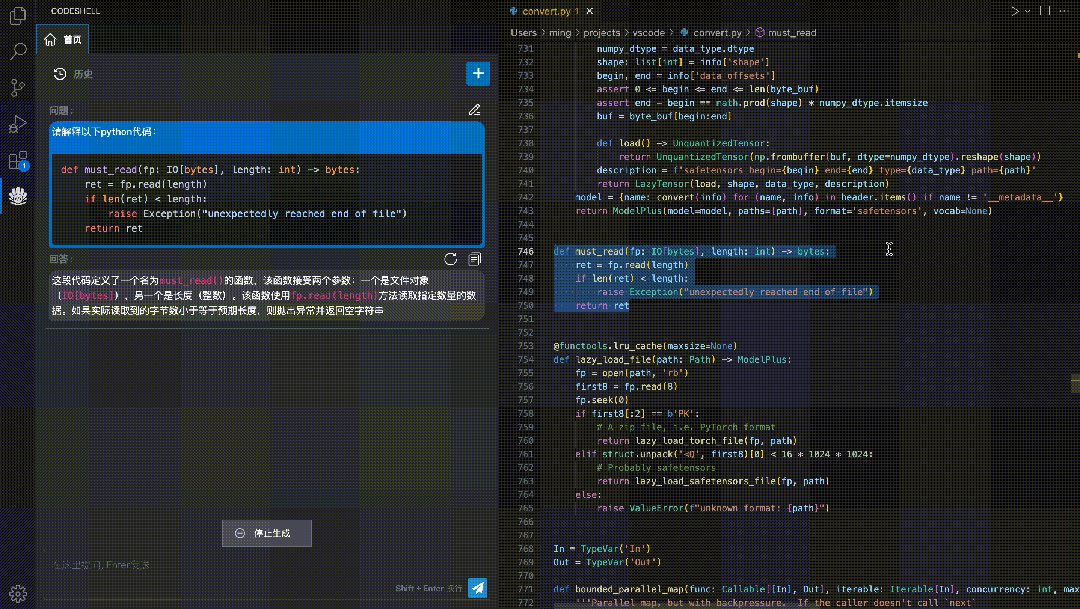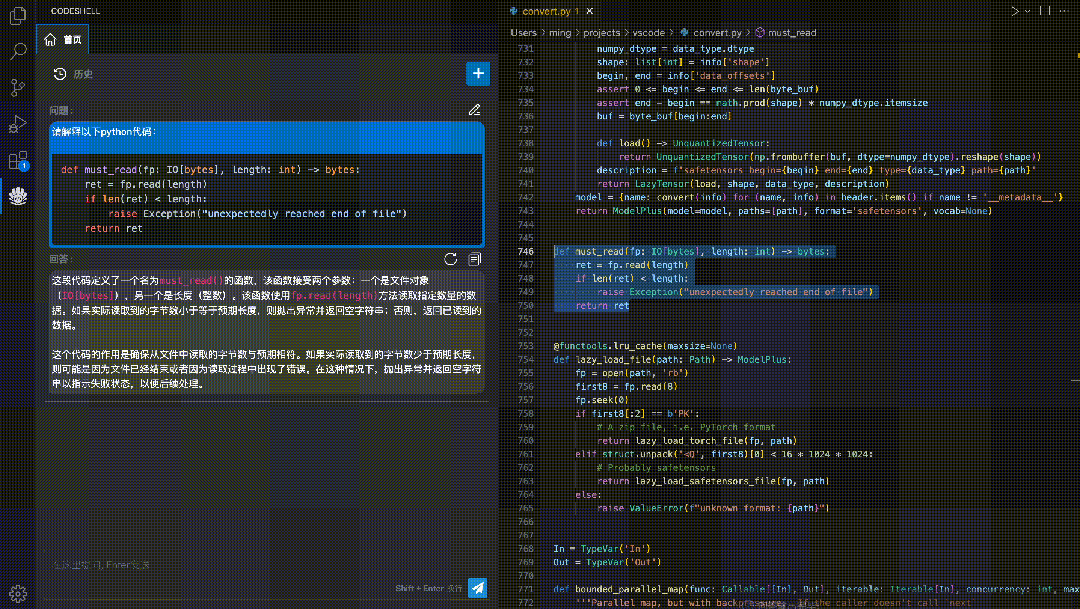
安全检测:检测代码中的潜在安全风险,如可能出现的SQL注入、跨站脚本攻击等,帮助排查安全性风险。
其它功能还包括:
自动添加注释——为代码自动生成描述其功能、参数及返回值等相关信息的注释;
代码优化与审计——对代码进行深入分析,检测潜在的错误、冗余代码和性能瓶颈,并为开发者提供相应的修复建议;
代码格式检查——自动检测代码的排版和格式问题,发现潜在的不规范现象;
性能评估——对代码的性能风险进行评估,发现潜在的性能瓶颈,为优化代码性能提供支持;
测试用例生成——基于代码逻辑,自动创建测试用例,以辅助进行代码测试和验证,确保代码的正确性和稳定性。
开发者下载模型,在本地做简单操作和配置,即可马上体验。
全面的代码能力自动评估工具
CodeShell团队同时发布了一个针对代码助手能力的统一评估基准,近期将开源并公开论文,加入到CodeShell的开源「全家桶」中。
在大模型评测上,CodeShell团队底蕴深厚,团队此前曾经发布过通用大模型对话能力的自动评估工具PandaLM。
开源地址:https://github.com/WeOpenML/PandaLM
CodeShell团队在模型训练中发现,现有的评估基准无法准确反映其真实能力,其面临的问题包括试题难度较低、评估场景与实际开发环境脱节等,同时评估基准提供的任务上下文信息也非常有限,导致代码大模型评估者难以进行深入分析。
为此,CodeShell团队提出了一个包含完整程序上下文的多任务编程模型评估基准CodeShell-UCB(Unified Code Bench)。
CodeShell-UCB的评估任务提供了完整的程序上下文信息,包括完整的真实项目代码、运行环境和执行脚本。
CodeShell-UCB通过执行程序分析、规则筛选、人工筛选,提炼出了代码助手任务试题,并提供了一套统一的编译、运行、测试环境。
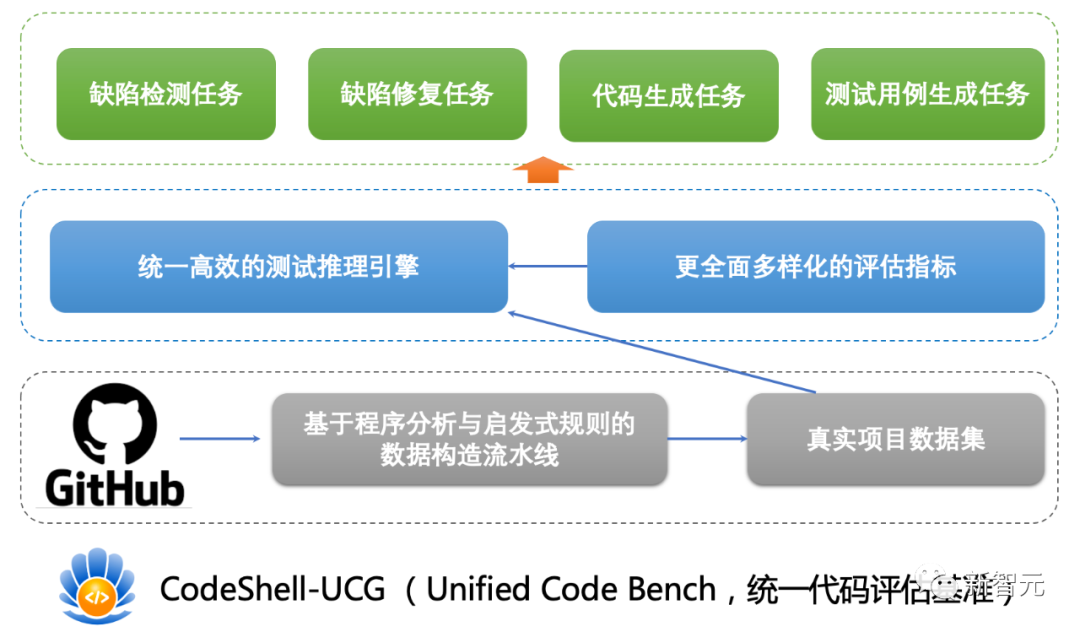
CodeShell-UCB的五个评测任务位覆盖了软件开发的重要场景:
1. 代码生成:关注如何自动生成优质、符合要求的代码片段。CodeShell-UCB包含了235个单函数代码生成试题。
2. 基于被测代码的测试用例生成:关注如何基于特定的被测代码自动生成有效、全面的测试用例。CodeShell-UCB包含了139个基于被测代码的测试用例生成试题。
3. 基于问题报告的测试用例生成:当存在错误报告时,快速并精确地创建出相应的测试用例,不仅可以帮助快速定位、修复问题,同时也可以提高回归测试的效率。CodeShell-UCB包含了58个基于问题报告的测试用例生成试题。
4. 缺陷检测:自动化的缺陷检测能够大幅度提高开发效率并且减少人为疏漏造成的错误。CodeShell-UCB包含了956个检测样本的标签平衡缺陷检测试题。
5. 缺陷修复:一旦缺陷被检测出,如何对其进行有效的修复也是一个复杂且重要的任务。CodeShell-UCB包含了478个单函数缺陷代码的缺陷修复试题。
这五个任务提供了一个全面深入的评估方案,支持不同软件开发场景下检验和评估代码大模型的能力。
同时,CodeShell-UCB推理框架具有较高的通用性,涵盖了本地Huggingface模型的推理、本地Text-Generation-Inference的加速推理,以及使用闭源API(如OpenAI API、Claude API)的推理。
生成的代码随后会在CodeShell-UCB执行器中运行和评估,提供了包括编译成功率、Pass@K、Pass@T以及测试覆盖率在内的多样化、多维度的评估指标。
下表展示了代码助手CodeShell-Chat和在WizardCoder的对比。
尽管WizardCoder通过在CodeLlama上精心微调获得了很高的HumanEval分数,但是在更加综合全面的测试基准下,CodeShell-Chat各种编码任务下具有明显的优势,更适合软件开发的实际场景。
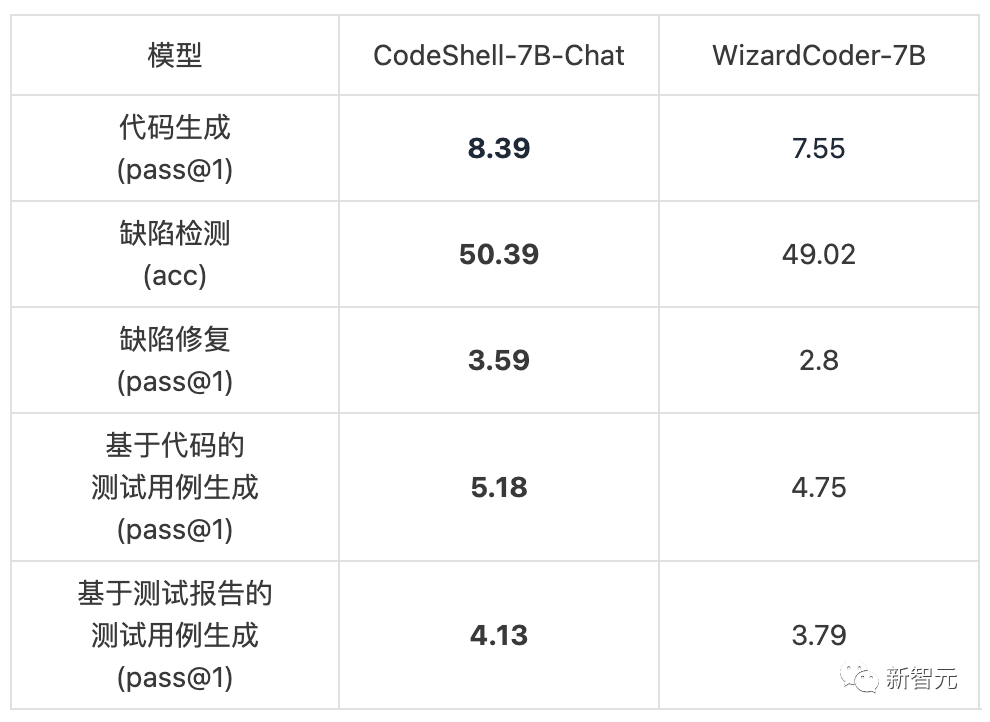
CodeShell-UCG评估基准既可以用于评估模型的编程能力,也可以用于评估各种不同的Prompt设计策略,研究者可以在CodeShell-UCB的基础上进行数据与任务的扩展并展开更细致的模型分析。
北京大学软件工程国家工程研究中心知识计算实验室(张世琨、叶蔚课题组)长期关注软件工程与人工智能交叉领域,聚焦程序语言与自然语言的语义理解与交互问题,在打造CodeShell的过程中建立了一支大模型精英团队,覆盖基座预训练、基础设施优化、数据治理、模型微调与对齐、模型评估、模型量化与部署等核心环节与任务,近期将推出更加重磅的模型与产品,敬请期待!
参考资料:
https://github.com/WisdomShell/codeshell

