
热门标签
热门文章
- 1mac安装Android SDK_mac安卓sdk下载
- 2前端使用tesseract ocr 图文识别,训练自己字库,vue中使用tesseract_tesseract vue 中文
- 3www.97top10.com--做最好的技术交流网站
- 4Axure发布至服务器_axure9部署本地服务器
- 5Ubuntu systemd.service服务单元配置详解(中文)_ubuntu service
- 6Java注解详解和自定义注解实战,用代码讲解
- 7鸿蒙4.0开发视频教程:开启智能未来,从这里启航!_华为鸿蒙官网4.0开发学习视频
- 8史上最强的「自动化测试」学习路线在这里_自动化测试路线
- 9android 获取堆栈地址,Android查看activity的任务堆栈
- 10详解git如何回滚提交记录_git回滚某次提交
当前位置: article > 正文
latex写论文(TeXstudio工具)_怎么用texstudio写论文
作者:Cpp五条 | 2024-03-15 01:27:35
赞
踩
怎么用texstudio写论文
前言
学校老师要求我们以IEEE顶级会议格式与标准写报告,于是过程虽然麻烦点,但是效果还是不错了,下面先展示一下自己写完的效果。


IEEE模板
我是在 Overleaf 上注册了个账号下载了模板,里面有各种会议论文的写作模板,这个注册还挺麻烦,要外网注册,国内邮箱都不行。进行后点菜单,菜单里有下载源码。

模板免费分享
已经将在官网下载的模板打包压缩上转,链接如下:
https://download.csdn.net/download/weixin_39615182/13799871
大家下载后用TeXstudio打开下面.tex文件,我建议你把他复制一份然后重命名成自己的。如复制一个重命名为Sample_my.tex。若TexStudio工具没有下载的自己去搜索下载安装一下。打开后点击绿色运行图标即可。

如果你要写中文,并且要插入图片,那么你必须引入两个包,如图,不然会报错

参考文献写作方法
这里参考文献需要重点说一下,滑倒最后两个thebibliography中间的就是参考文献,不建议大家这么写

添加文献,我是这么做的:
1、将上图
\begin{thebibliography}和\end{thebibliography}
以及它中间的都删除,换成下面两行代码
\bibliographystyle{plain} %参考文献,默认写plain
\bibliography{smoke}
- 1
- 2
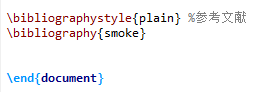
2、创建一个smoke.bib文件,这个文件在你.tex文件同目录创建,名字自己去,因为我报告是做抽烟识别,所以我取smoke,你取什么记得顺便把图中\bibliography{}中改一下即可
3、创建好后,在TeXstudio打开smoke.bib,如下

4、我们怎么作出这种有角标引用文献效果呢?

- 首先,假设你要找yolov4的文献,你先要知道yolov4文献全名,搜索并下载论文的pdf得知全名是YOLOv4: Optimal Speed and Accuracy of Object Detection,复制这个名字。到下面链接粘贴http://scholar.hedasudi.com
搜索后,点引号,即引用
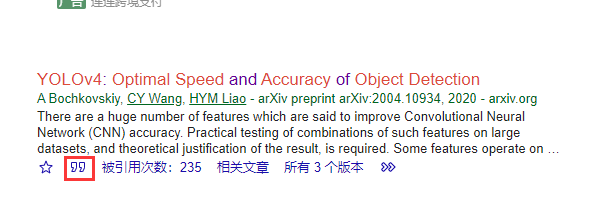
再点击BibTex

点击就会跳出.bib格式的参考文献,将其复制,放到创建的smoke.bib中

5、最后一步就是引用了你只需要在你.tex文件中,如我这里yolov4要写个引用,就写\cite{bochkovskiy2020yolov4},注意:cite中要和找到的bib第一行名字一致,这样就会自动在最后参考文献引用,文献也会在最后显示出来

我的.tex文件代码
\documentclass[conference]{IEEEtran} % correct bad hyphenation here \usepackage{ctex}%引入中文包,使得中文可以正常显示 \usepackage{graphicx} %导入图片的宏包 \hyphenation{op-tical net-works semi-conduc-tor IEEEtran} \begin{document} % paper title %\title{Submission Format for IMS2014 (Title in 24-point Times font)} % If the \LARGE is deleted, the title font defaults to 24-point. % Actually, % the \LARGE sets the title at 17 pt, which is close enough to 18-point. %+++++++++++++++++++++++++++++++++++++++++++ \title{\kaishu 基于yolov4算法的抽烟检测} \author{\kaishu 喻\,曾\,郑\,陈\,黄 } % use only for invited papers %\specialpapernotice{(Invited Paper)} % make the title area \maketitle \begin{abstract} 抽烟检测在实际应用场景中具有重大意义,如油田,加油站,公共场所等都不能有明火,未熄灭的火苗可能会带来巨大的安全隐患,所以需要通过监控的方式进行实时监督,本系统主要是基于yolov4算法对抽烟行为进行识别,首先在网络上收集了许多抽烟图片,并进行了数据预处理操作,然后对图片指定区域进行了标注。本文用yolov4算法以及SSD算法分别对数据集进行了训练,最后对比发现yolov4算法效果更好。于是最终确定yolov4算法训练出的模型为检测模型,我们打开摄像头检测时发现抽烟行为都能检测出,但对于十分相似的白色物体会识别错误,如粉笔,这是需要改进的,最终对比两个算法,发现yolov4检测效果更好,故使用yolov4进行检测。 \end{abstract} \IEEEoverridecommandlockouts \begin{keywords} 抽烟检测,yolov4,数据预处理,SSD \end{keywords} % no keywords % For peer review papers, you can put extra information on the cover % page as needed: % \begin{center} \bfseries EDICS Category: 3-BBND \end{center} % % for peerreview papers, inserts a page break and creates the second title. % Will be ignored for other modes. \IEEEpeerreviewmaketitle \section{引言} % no \PARstart 目标检测是计算机视觉领域的基本且重要的问题之一,几十年来也一直都是一个活跃的研究领域。目标检测的目标是确定某张给定图像中是否存在给定类别(比如人、车、自行车、狗和猫)的目标实例;如果存在,就返回每个目标实例的空间位置和覆盖范围。目标检测主要可以分为两大主要类别:1. 两级式(two-stage)检测框架,包含一个用于区域的预处理步骤,使得整体流程是两级式的。2. 单级式(one-stage)检测框架,即无区域的框架,这是一种单独提出的方法,不会将检测提议分开,使得整个流程是单级式的。如下(1),(2),(3),(4)为基于区域(two-stage)的网路,(5),(6)是基于回归(one-stage)的网络,基于区域的网络,精度高,但运算较慢,无法达到本系统的实时要求,而基于回归的网络检测速度快,能达到实时效果,故作为备选网络,最终比较备选网络哪个更优。 \begin{enumerate} \setlength{\itemsep}{-2ex} \setlength{\parskip}{0ex} \setlength{\parsep}{0ex} \item R-CNN\\R-CNN\cite{girshick2014rich}使用深度学习的方法代替了传统的目标检测方法,是基于深度学习的目标检测算法的鼻祖,但该网络检测图片耗时,速度慢,繁琐,占用空间大。\hfil\break \item Fast R-CNN\\Fast R-CNN\cite{girshick2015fast}弥补了上面的不足,框架更为精简,但候选区域使用了选择性搜索算法(SS),该算法占用目标检测2/3的时间,因此还无法满足实时性要求。\hfil\break \item Faster R-CNN\\Faster R-CNN\cite{ren2016faster}检测过程有4个步骤1、提取候选区域 2、特征提取 3、特征分类 4、边框回归 ,上述 4步统一到一个深度网络框架中用候选区域网络(RPN)取代选择性搜索(SS),这也是Faster R-CNN的巨大优势,极大提升检测候选框的生成速度,但还是达不到实时的效果。 \hfil\break \item YoLo\\YoLo将目标检测任务转换成了一个回归问题,使得yolo检测最快速度达到200fps(Frames Per Second---每秒钟帧数越多,所显示的动作就会越流畅),达到实时效果,但在精度上会有所下降,这是在精度与速度权衡后的结果。本文就用了yolov4-keras\cite{bochkovskiy2020yolov4}网络进行训练。\hfil\break \item SSD\\SSD\cite{liu2016ssd}在做到实时检测基础上,进一步提高了其检测准确率,SSD模型核心Prior box,SSD基于Faster R-CNN的候选区域机制,提出了Prior\,box概念,SSD优点明显,运行速度可以与yolo媲美,检测精度则可以与Faster RCNN媲美,缺点是需要人工设定Prior\,box的参数值。本文也用了SSD网络进行训练。\hfil\break \end{enumerate} \section{相关技术概述} \begin{enumerate} \setlength{\itemsep}{-2ex} \setlength{\parskip}{0ex} \setlength{\parsep}{0ex} \item YoLoV4\\yolov4相较于yolov3\cite{redmon2018yolov3}增加了许多新特性,并且识别的平均精确率也有所提高,新增特性有WRC,CSP,CmBN,SAT,Mish激活,Mosaic数据增强,CmBN,DropBlock正则化和CIoU丢失等等,增加了许多新的小tricks,且AP与FPS这两项指数相比YOLOv3分别提高了10\%与12\%。 \hfil\break \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.45]{yolo.jpg} %设置缩放比例 \caption{yolov4性能} %设置图片的一个编号以及为图片添加标题 \end{figure} yolov4网络结构由三部分组成,分别是CSPDarkNet53,SSP,PAN,CSPDarkNet53是主干网络,假设输入图像大小为416×416×3,首选会经过DarknetConv2D\_BN\_Mish卷积块,卷积块由DarknetConv2D、BatchNormalization、Mish三部分组成,即该卷积结构包括l2正则化、批标准化、Mish激活函数这一系列操作。然后后面有5个CSPResblockBody,分别为×1,×2,×8,×8,×4,表示重复多少次resblock\_body,可以看到该残差结构块中先有个ZeroPadding2D对二维矩阵的四周填充0,即零填充层,然后三个DarknetConv2D\_BN\_Mish卷积块,第二个DarknetConv2D\_BN\_Mish卷积块会生成一个大的残差边(后面会解释残差边),然后有个for循环对通道进行整合[compose]与特征提取,这个循环多少次就是图中×1,×2,×8等。,在后面进行一次1x1的DarknetConv2D\_BN\_Mish卷积,再concatenate堆叠拼接,最后再对通道数进行整合并返回。可以看到,resblockbody中有大量的DarknetConv2D\_BN\_Mish卷积块进行卷积提取特征。SSP与PAN是特征金字塔部分,首先SSP结构进行了三次DarknetConv2D\_BN\_Leaky卷积,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1,该结构能分离出最显著的上下文特征,是强有力的特征提取,池化后,再进行堆叠。PANet(PAN)是2018年发表的一种实例分割算法,它可以反复提取特征,即反复进行上采样,最后可以得到三个yolo\,head,这里和yolov3中最终得到的一样。 \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.25]{yolobone.jpg} %设置缩放比例 \caption{yolov4网络结构} %设置图片的一个编号以及为图片添加标题 \end{figure} \item SSD\\SSD 是基于一个前向传播 CNN 网络,产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个 非极大值抑制(Non-maximum suppression) 得到最终的 predictions。SSD网络结构从图中可以看出来分为两部分 基础网络 + 金字塔网络。基础网络是VGG-16\cite{simonyan2014very}的前4层网络。金字塔网络是特征图逐渐变小的简单卷积网络由5部分构成,结构图如下。 \hfil\break \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.25]{ssd.jpg} %设置缩放比例 \caption{ssd网络结构} %设置图片的一个编号以及为图片添加标题 \end{figure} \item OpenCV\\OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。我们主要利用OpenCv开启摄像头功能,以便进行检测。 \hfil\break \item Keras\\Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。 \hfil\break \end{enumerate} \section{实验内容与分析} 首选,我们利用爬虫收集到的4000+张图片,并且进行了一定的筛选与预处理,最终留下了2400+张图片作为训练集,并且一起对这些图片用labelImg工具进行了标注工作,我们总共训练了两个模型,一个用yolov4训练,一个用SSD训练,根据长时间训练后的结果对十张相同的图片进行预测,对二者效果做了一个对比。并且发现yolov4与SSD开摄像头进行检测时,yolov4稍微有点一卡一卡的感觉,但是SSD整体显得较为流畅,这是二者帧速率不同导致的,yolov4的帧速率实际只有30FPS左右,但是SSD大概有60FPS左右,故显得比较流畅,最后我们开摄像头进行了识别。\\检测步骤如下: \begin{enumerate} \setlength{\itemsep}{-2ex} \setlength{\parskip}{0ex} \setlength{\parsep}{0ex} \item OpenCv调用VideoCapture(0)方法打开摄像头\hfil\break \item 对视频流进入循环,逐帧读取图片及标注位置\hfil\break \item 转变图片格式\hfil\break \item 将图片的特征信息转成数组的形式\hfil\break \item 开始检测图片,其中以yolov4为例,yolo在检测图片函数中,会对图片进行预处理,如Mosaic数据增强,还会做归一化。\hfil\break \item 进行预测,并将将预测结果进行解码\hfil\break \item 筛选出其中得分高于confidence的框\hfil\break \item 去掉灰条\hfil\break \item 进行画图操作,画矩形框并显示\hfil\break \end{enumerate} \section{实验结果} 实验过程中我们用两个模型分别检测相同的十张图片,效果如下,我们可以看到用ssd模型对10张图片进行预测,只有6张检测成功。而用yolov4训练的模型对10张图片进行预测,能检测出8张,故yolov4训练的模型效果更好,图6为效果对比图,红色的折线为yolov4,蓝色的折线为ssd,另外还做了一个简易GUI界面方便用户操作。 \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.4]{ssd_detection.jpg} %设置缩放比例 \caption{ssd检测图片} %设置图片的一个编号以及为图片添加标题 \end{figure} \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.35]{yolov4_detection.jpg} %设置缩放比例 \caption{yolov4检测图片} %设置图片的一个编号以及为图片添加标题 \end{figure} \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.2]{compare.jpg} %设置缩放比例 \caption{效果对比} %设置图片的一个编号以及为图片添加标题 \end{figure} \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.6]{video.jpg} %设置缩放比例 \caption{开摄像头识别} %设置图片的一个编号以及为图片添加标题 \end{figure} \begin{figure}[!htb] %插入图片 \centering \includegraphics[scale=0.3]{window.jpg} %设置缩放比例 \caption{简易GUI界面} %设置图片的一个编号以及为图片添加标题 \end{figure} \section{实验结论} 本文提出了一种基于yolov4算法的抽烟检测解决方法,本文对yolov4算法与SSD算法作了比较,检测效果还是yolov4更好,并且该模型大部分图片都能检测出,但是这里存在一些问题,一个就是yolov4在实验结果中的FPS相对不高,所以会有卡顿的情况,这一点SSD就显得较为流畅了,以后可以试着用yolov4-tiny\cite{jiang2020real},因为该网络训练出的模型很小,加载快,并且官方说该网络FPS更快。另一个问题是模型能检测抽烟行为,但对于极其相似的物体,如粉笔,形状和颜色与烟都十分相似,这里考虑可能的解决办法是增加一个烟雾检测。 \bibliographystyle{plain} %参考文献 \bibliography{smoke} \end{document}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/238266?site
推荐阅读
相关标签

