
热门标签
热门文章
- 17-60 对a[10]数组中的素数排序_输入10个正整数到a数组中,对a[10]数组中的素数升序排序。 输入格式: 在一行中输入
- 2Java提升不到2个月,月薪从9k到15K,都来祝贺吧!_java升薪
- 3玩转 Python 集合,这一篇就够了_python集合初始化
- 4深入理解JVM原理-G1收集器_jvm原理有一定了解
- 5SpringBoot-实现搜索功能_springboot实现搜索功能
- 6大模型替00后整顿职场!文心一言「重构」办公软件:从聊天到写代码通通效率飞升...
- 7Python自然语言处理:NLTK库详解
- 8Siammask代码阅读笔记(二)_vot2018 lost number
- 9鸿蒙一次开发,多端部署(一)简介
- 10详解深度学习三维重建网络:MVSNet、PatchMatchNet、JDACS-MS
当前位置: article > 正文
mmdetection算法之DETR(0)_mmdetection 跑detr模型训练结果为0
作者:Cpp五条 | 2024-03-29 23:05:42
赞
踩
mmdetection 跑detr模型训练结果为0
前言
简单介绍下mmdetection里的DETR算法,后续有时间会详细补充和修改。
DETR
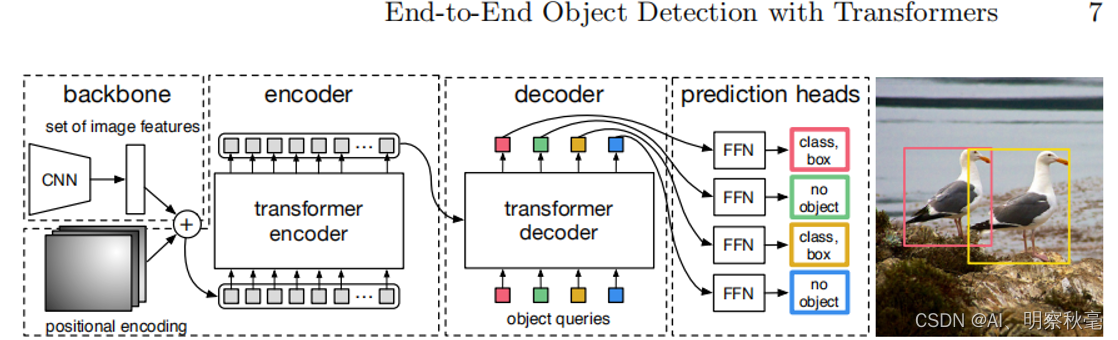
基本网络结构
backbone:resnet50输出的最后一层
neck:无
head:transformer,编解码+FFN+最后的预测分类和回归
一、模型输出
我们直接看经过resnet50特征提取后的transformer部分
def forward_single(self, x, img_metas): """"Forward function for a single feature level. Args: x (Tensor): Input feature from backbone's single stage, shape [bs, c, h, w]. img_metas (list[dict]): List of image information. Returns: all_cls_scores (Tensor): Outputs from the classification head, shape [nb_dec, bs, num_query, cls_out_channels]. Note cls_out_channels should includes background. all_bbox_preds (Tensor): Sigmoid outputs from the regression head with normalized coordinate format (cx, cy, w, h). Shape [nb_dec, bs, num_query, 4]. """ # construct binary masks which used for the transformer. # NOTE following the official DETR repo, non-zero values representing # ignored positions, while zero values means valid positions. batch_size = x.size(0) input_img_h, input_img_w = img_metas[0]['batch_input_shape'] masks = x.new_ones((batch_size, input_img_h, input_img_w)) # 建立个MASK,是因为同一batch输入resnet的大小需要保持一致,就需要对图像进行padding(全0)操作以保证同一batch的尺寸相同。 #但是后面进行自注意力时,这些无效信息要进行mask掉 for img_id in range(batch_size): # [B,H,W] img_h, img_w, _ = img_metas[img_id]['img_shape'] masks[img_id, :img_h, :img_w] = 0 x = self.input_proj(x) # 2048-256 [B,C,H,W] # interpolate masks to have the same spatial shape with x masks = F.interpolate( masks.unsqueeze(1), size=x.shape[-2:]).to(torch.bool).squeeze(1) # [B,C,H,W] # position encoding,下面有其代码 pos_embed = self.positional_encoding(masks) # [bs, embed_dim, h, w] # outs_dec: [nb_dec, bs, num_query, embed_dim] # 下面有代码 outs_dec, _ = self.transformer(x, masks, self.query_embedding.weight, pos_embed) # 返回nb_dec个 all_cls_scores = self.fc_cls(outs_dec) all_bbox_preds = self.fc_reg(self.activate( self.reg_ffn(outs_dec))).sigmoid() return all_cls_scores, all_bbox_preds

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
位置编码
def forward(self, mask): """Forward function for `SinePositionalEncoding`. Args: mask (Tensor): ByteTensor mask. Non-zero values representing ignored positions, while zero values means valid positions for this image. Shape [bs, h, w]. Returns: pos (Tensor): Returned position embedding with shape [bs, num_feats*2, h, w]. """ # For convenience of exporting to ONNX, it's required to convert # `masks` from bool to int. mask = mask.to(torch.int) not_mask = 1 - mask # logical_not y_embed = not_mask.cumsum(1, dtype=torch.float32) # Y方向进行累加 x_embed = not_mask.cumsum(2, dtype=torch.float32) # X方向进行累加 if self.normalize: # 分别将两个方向上的累加结果归一化到[0,2N]区间 y_embed = (y_embed + self.offset) / \ (y_embed[:, -1:, :] + self.eps) * self.scale x_embed = (x_embed + self.offset) / \ (x_embed[:, :, -1:] + self.eps) * self.scale dim_t = torch.arange( self.num_feats, dtype=torch.float32, device=mask.device) dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats) pos_x = x_embed[:, :, :, None] / dim_t pos_y = y_embed[:, :, :, None] / dim_t # use `view` instead of `flatten` for dynamically exporting to ONNX B, H, W = mask.size() pos_x = torch.stack( (pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).view(B, H, W, -1) pos_y = torch.stack( (pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).view(B, H, W, -1) pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2) return pos
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
总结
这种检测模型的代码介绍,我现在就一部分一部分介绍,还没找到合适的编写方法,先这样吧,后面有更好的编写习惯和模式后,在整体进行修改补充下吧!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/337851
推荐阅读
相关标签

