
- 1postcss安装和使用(详细)
- 25 种常见的 Linux 打包类型:tar、gzip、bzip2、zip 、 7z_linux文件打包
- 3华为鸿蒙javascript,第一个华为鸿蒙app跑起来了
- 4Java -枚举的使用_java枚举的使用
- 5仓库管理系统/课程设计/ASP.NET/_.net 后端 仓库管理模版页面布局
- 6python汽车大数据分析可视化系统【计算机毕业设计】大数据 (含源码)建议收藏_ps d:\毕业设计\车辆大屏可视化> python manage.py startapp myap
- 7计算机开启蓝牙网络,怎么打开电脑蓝牙功能(笔记本电脑蓝牙怎么开)
- 8MLP(多层神经网络)介绍_mlp算法分布式
- 9微信小程序对接微信支付详细教程_微信小程序接入微信支付
- 10华为ensp配置vrrp
keras CAM和Grad-cam原理简介与实现_三维特征转变为yi维特征
赞
踩
keras CAM和Grad-cam原理简介与实现
两种分类模型
-
feature extraction+Flatten+softmax
-
feature extraction+GAP+softmax。
以VGG16为例(其他模型原理一样),在做完卷积激活池化操作后,每张图像特征提取可得到7x7x512大小的特征图,为了在全连接层作分类,需要将提取的特征图(三维)转化成一维的特征。这两种类型分类模型的唯一差异就在将三维特征转化成一维特征的方式
1、特征提取(feature extraction)+flatten+softmax
这种方式使用keras的flatten层将三维特征直接从左向右排列成一维向量(类似于np.flatten())。例如将7x7x512的特征图flatten后拉成了25088长的一维向量。然后接全连接层(FCN,可看到多层感知机分类器),最后经过softmax层输出每类的概率。

2、 feature extraction+GAP+softmax
Global average pooling(GAP)是论文Network In Network[1]提出的,主要为了解决全连接层参数过多,不易训练且容易过拟合等问题,例如VGG16网络模型的参数90%左右的参数是全连接层的参数。用GAP替换flatten操作将三维特征转化成一维向量。GAP层实现非常简单,就是一个与特征图大小相同的平均池化层。例如7x7x512的特征图,使用7x7大小的平均池化层,池化后可得到512长的一维向量。这里可以对比一下这两种方式的参数量,假设全连接层节点个数1024个,flatten的参数量是25088x1024。而GAP的参数量是512x1024。这个差异还是很大的。

二、CAM和Grad-CAM
CAM和Grad-cam都是求如下图右侧的结果。可视化模型根据图像的那个区域判别该图是猫。可以帮组我们理解模型学习的特征。
只需要得到heatmap(上图左侧),将heatmap叠加到原图即可。代码如下。cam和Grad-cam也就是要求heatmap。
import cv2
superimposed_img = cv2.addWeighted(img,0.6,heatmap,0.4,0)
- 1
- 2
Python-OpenCV 图像叠加or图像混合加权实现
cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]]) → dst
- 1
参数说明
src1 – first input array.
alpha – weight of the first array elements.
src2 – second input array of the same size and channel number as src1.
beta – weight of the second array elements.
dst – output array that has the same size and number of channels as the input arrays.
gamma – scalar added to each sum.
dtype – optional depth of the output array; when both input arrays have the same depth, dtype can be set to -1, which will be equivalent to src1.depth().
矩阵表达式来代替:
dst = src1 * alpha + src2 * beta + gamma;
- 1
- 2
由参数说明可以看出,被叠加的两幅图像必须是尺寸相同、类型相同的
并且,当输出图像array的深度为CV_32S时,这个函数就不适用了,这时候就会内存溢出或者算出的结果压根不对。
CV_32S is a signed 32bit integer value for each pixel
- 1
CAM和Grad-cam求heatmap的具体流程如下:
1)求图像经过特征提取后最后一次卷积后得到的特征图(也就是VGG16 conv5_3的特征图(7x7x512))
2)512张feature map在全连接层分类的权重肯定不同,利用反向传播求出每张特征图的权重。注意cam和Grad-cam的不同就在于求每张特征图权重的方式。其他流程都一样
3)用每张特征图乘以权重得到带权重的特征图(7x7x512),在第三维求均值得到7x7的map(np.mean(axis=-1)),relu激活,归一化处理(避免有些值不在0-255范围内)。
- 1
- 2
- 3
- 4
- 5
该步最重要的是relu激活(relu只保留大于0的值),relu后只保留该类别有用的特征。正数认为是该类别有用的特征,负数是其他类别的特征(或无用特征)。如下图,假设某类别最后加权后为0.8965,类别值越大则是该类别的概率就越高,那么属于该类别的特征即为wx值大于0的特征。小于0的特征可能是其他类的特征。通俗理解,假如图像中出现一个猫头,那么该特征在猫类别中为正特征,在狗类别中为负特征,要增加猫的置信度,降低狗的置信度。
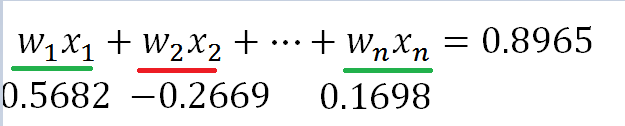
假如不加relu激活的话,heatmap代表着多类别的特征,论文中是这样概述的:如果没有relu,定位图谱显示的不仅仅是某一类的特征。而是所有类别的特征。
4) 将处理后的heatmap放缩到图像尺寸大小,便于与图像加权
- 1
从流程中可看到,cam和Grad-cam不同之处在于求每个特征图的权重的方式,这也是这两个方法的亮点之处,(其他部分,如求特征图我们在可视化卷积特征也常做,CAM和Grad-cam只是给这些特征加上权重,突出显示我们关注的重点),下面分别介绍cam和Grad-cam求特征图权重的方式,并给出各自的实现的keras版本源码。
1、CAM源码
CAM方法要求模型必须使用GAP层。 因为GAP层使模型具有更强的可解释性,GAP后每张特征图对应一个节点(下图中红色的节点),CAM的思想是把该节点的权重w作为该特征图的权重。具体做法是选择softmax层值最大的节点反向传播,求GAP层的梯度作为(7x7x512)特征图的权重。

CAM实现源码
# -*- coding=utf-8 -*- """ Created on 2019-6-19 21:39:53 @author: fangsh.suk """ import keras import cv2 import numpy as np import keras.backend as K from keras.applications.resnet50 import preprocess_input from keras.preprocessing.image import load_img,img_to_array K.set_learning_phase(1) #set learning phase weight_file_dir = '/data/sfang/logo_classify/keras_model/checkpoint/best_0617.hdf5' img_path = '/data/sfang/logo_classify/keras_model/error_analyez/0614/0/09219.png' model = keras.models.load_model(weight_file_dir) image = load_img(img_path,target_size=(224,224)) x = img_to_array(image) x = np.expand_dims(x,axis=0) x = preprocess_input(x) pred = model.predict(x) class_idx = np.argmax(pred[0]) # 获得某个类别输出 class_output = model.output[:,class_idx] # 取得最后一个卷积层,和 全局平均池化层 last_conv_layer = model.get_layer("block5_conv3") gap_weights = model.get_layer("global_average_pooling2d_1") # 求 预测类别的输出对gap层输出的导数 grads = K.gradients(class_output,gap_weights.output)[0] # 调试函数,给定input,返回梯度和最后一个卷积层的输出 iterate = K.function([model.input],[grads,last_conv_layer.output[0]]) #这里调用直接就返回了池化层的梯度,卷积层的输出 pooled_grads_value, conv_layer_output_value = iterate([x]) # 压缩一下维度,应该是四维变成三维的 pooled_grads_value = np.squeeze(pooled_grads_value,axis=0) # 现在已经有了梯度,也有了最后一个卷积层(7x7x512)特征图的权重 #将GAP层的梯度作为(7x7x512)特征图的权重。即512个图分别乘以全局平均池化的梯度 for i in range(512): conv_layer_output_value[:,:,i] *= pooled_grads_value[i] #将通道从512变成1,直接在通道channel维度求均值 heatmap = np.mean(conv_layer_output_value, axis=-1) #现在heatmap是7*7的了,再进行relu激活。maximum将heatmap和0逐个比较,选择较大的值 heatmap = np.maximum(heatmap,0) # max 默认求列向的最大,即每个值除以列的最大值,这里应该就是缩放到0-1的意思 #因为后面heatmap会乘以255 heatmap /= np.max(heatmap) # img = cv2.imread(img_path) #resize输出为 img = cv2.resize(img,dsize=(224,224),interpolation=cv2.INTER_NEAREST) # img = img_to_array(image) heatmap = cv2.resize(heatmap,(img.shape[1],img.shape[0])) # 将0-1的7*7heatmap放大到0-255 heatmap = np.uint8(255 * heatmap) # 伪彩色,COLORMAP_JET色度图表示值的大小 heatmap = cv2.applyColorMap(heatmap,cv2.COLORMAP_JET) # 权重叠加 superimposed_img = cv2.addWeighted(img,0.6,heatmap,0.4,0) cv2.imshow('Grad-cam',superimposed_img) cv2.waitKey(0)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
代码流程 及 解释
K.set_learning_phase(1) #set learning phase
- 1
设置学习模式是训练还是预测
the value “1” (training mode) or “0” (test mode)
keras.backend.set_learning_phase(0) # train mode
keras.backend.set_learning_phase(1) # predict mode
之所以这么区分,是因为某些层在预测和训练时不同
from keras import backend as K
print(K.learning_phase())
- 1
- 2
- 加载模型load_model(h5文件)
- load_img 加载图片(tensor类型)
- img_to_array 转换为array, expand_dim扩展维度,因为preprocess_input接收的是4维,还包括了batch这一维度
- 送入resnet50的预处理函数preprocess_input
- model.predict预测
- pred[0]第一个样本的类别概率分布,np.argmax获得概率最大的值的index,即第几类
- model.output[:,class_idx]获得某个类别输出
- K.gradients(y,x)用于求y关于x 的导数(梯度),
K.gradients()实现y对x求导
求导返回值是一个list,list的长度等于len(x)
假设返回值是[grad1, grad2, grad3],y=[y1, y2],x=[x1, x2, x3]。则,真实的计算过程为:
其中y1/x1表示求y1关于x1的偏导数。
PS :K.gradients()应该是通过tensorflow的tf.gradients()实现的
K.function函数可以接收传入数据,并返回一个numpy数组。使用这个函数我们可以方便地看到中间结果,尤其对于变长输入的Input。下面是官方关于function的文档。
就是放进去输入输出,然后调用的时候,给一个input就返回定义的output
cv读取的图片,shape[0]是高,shape[1]是宽
cv.resize函数
# 读入原图片
img = cv.imread('test.jpg')
# 打印出图片尺寸
print(img.shape)
# 将图片高和宽分别赋值给x,y
x, y = img.shape[0:2]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
cv2.applyColorMap(heatmap,cv2.COLORMAP_JET)
colormap(色度图),人无法感知灰度的微小变化,但是对颜色变化能更好的感知.不同颜色代表不同意思,
色度图的一种模式colormap_jet
2、Grad-cam
CAM要求模型必须使用GAP,也就是要想使用CAM必须要重构模型,重新训练;并且对于某些任务GAP并不适用。Grad-cam实现了不改变模型结构的求定位图谱的方法。具体流程还是上述的流程,只是巧妙的求出来每张特征图的权重。
Grad-cam的思想是选择softmax值最大的节点(对应置信度最高的类别)反向传播,对最后一层卷基层求梯度,每张特征图的梯度的均值作为该张特征图的权重。同时,论文中给出证明,当特征映射与输出有链接权重时,Grad-cam求得的权重与CAM的一样,这里不给出具体的公司推导,感兴趣的自行去看论文。

实现源码。与CAM仅仅在求特征图权重部分不一样。
需要根据自己情况修改的部分在注释中备注
# -*- coding=utf-8 -*- """ Created on 2019-6-19 21:39:53 @author: fangsh.suk """ import keras import cv2 import numpy as np import keras.backend as K from keras.applications.resnet50 import preprocess_input from keras.preprocessing.image import load_img,img_to_array K.set_learning_phase(1) #set learning phase #需根据自己情况修改1.训练好的模型路径和图像路径 weight_file_dir = '/data/sfang/logo_classify/keras_model/checkpoint/best_0617.hdf5' img_path = '/data/sfang/logo_classify/keras_model/error_analyez/0614/0/09219.png' model = keras.models.load_model(weight_file_dir) image = load_img(img_path,target_size=(224,224)) x = img_to_array(image) x = np.expand_dims(x,axis=0) x = preprocess_input(x) pred = model.predict(x) class_idx = np.argmax(pred[0]) class_output = model.output[:,class_idx] #需根据自己情况修改2. 把block5_conv3改成自己模型最后一层卷积层的名字 last_conv_layer = model.get_layer("block5_conv3") grads = K.gradients(class_output,last_conv_layer.output)[0] pooled_grads = K.mean(grads,axis=(0,1,2)) iterate = K.function([model.input],[pooled_grads,last_conv_layer.output[0]]) pooled_grads_value, conv_layer_output_value = iterate([x]) ##需根据自己情况修改3. 512是我最后一层卷基层的通道数,根据自己情况修改 for i in range(512): conv_layer_output_value[:,:,i] *= pooled_grads_value[i] heatmap = np.mean(conv_layer_output_value, axis=-1) heatmap = np.maximum(heatmap,0) heatmap /= np.max(heatmap) img = cv2.imread(img_path) img = cv2.resize(img,dsize=(224,224),interpolation=cv2.INTER_NEAREST) # img = img_to_array(image) heatmap = cv2.resize(heatmap,(img.shape[1],img.shape[0])) heatmap = np.uint8(255 * heatmap) heatmap = cv2.applyColorMap(heatmap,cv2.COLORMAP_JET) superimposed_img = cv2.addWeighted(img,0.6,heatmap,0.4,0) cv2.imshow('Grad-cam',superimposed_img) cv2.waitKey(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
代码解读
关键代码:求卷积的权重,即求
类别输出class_output 对最后一个卷积层last_conv_layer的输出的导数
之前cam是
class_output对 gap_weights.output 直接得到grads
gradCAM多了一步,对三维的grads求均值得到一维的pooled_grads
关键在此,对卷积的三个维度求导以后再求平均,得到的是三维 得到的结果不久和 gap层的一维一样吗
pooled_grads = K.mean(grads,axis=(0,1,2))

