
- 1C语言:输入两个升序排列的序列,将两个序列合并为一个有序序列并输出。_c语言给定两组已按升序排列好的整型数据,合并为一组
- 2Java基础知识回顾-SecureRandom和Random
- 3华为eNSP配置MSTP实验_ensp的mstp配置
- 4np.zeros
- 5基于FPGA的HDMI设计导航页面
- 6当Suno遇上GPTs:一场音乐与AI的创新之旅
- 7Java-MyBatis解决模糊查询的三种方案_java中mysql模糊查询
- 8区块链+会计(3)_区块链 会计
- 9Python实现网页循环持续点赞_电脑上如何自动在网页上点赞
- 10IBM SPSS Statistics for Mac中文激活版:强大的数据分析工具
OceanBase数据库实践入门——性能测试建议_oceanbase数据库可靠性测试
赞
踩
概述
本文主要分享针对想压测OceanBase时需要了解的一些技术原理。这些建议可以帮助用户对OceanBase做一些调优,再结合测试程序快速找到适合业务的最佳性能。由于OceanBase自身参数很多、部署形态也比较灵活,这里并没有给出具体步骤。
数据库读写特点
压测的本质就是对一个会话的逻辑设计很高的并发。首先需要了解单个会话在数据库内部的读写逻辑。比如说,业务会话1对数据库发起一个DML SQL,第一次修改某笔记录,数据库会怎么做呢?
为了便于理解OB的行为,我们先看看ORACLE是怎么做的。后面有对比才可以加深理解。
ORACLE 读写特点
ORACLE会话第一次修改一行记录,如果该记录所在块(8K大小)不在内存(Buffer Cache)里时会先从磁盘文件里读入到内存里。这个称为一次物理读,为了性能考虑,ORACLE一次会连续读取相邻的多个块。然后就直接在该块上修改,修改之前会先记录REDO和UNDO(包括UNDO的REDO)。然后这个数据块就是脏块(Dirty Block)。假设事务没有提交,其他会话又来读取这个记录,由于隔离级别是读已提交(READ COMMITTED),ORACLE会在内存里克隆当前数据块到新的位置,新块包含了最新的未提交数据。然后ORACLE在新块上逆向应用UNDO链表中的记录,将数据块回滚到读需要的那个版本(SCN),然后才能读。这个也称为一次一致性读(Consistency Read),这个新块也称为CR块。
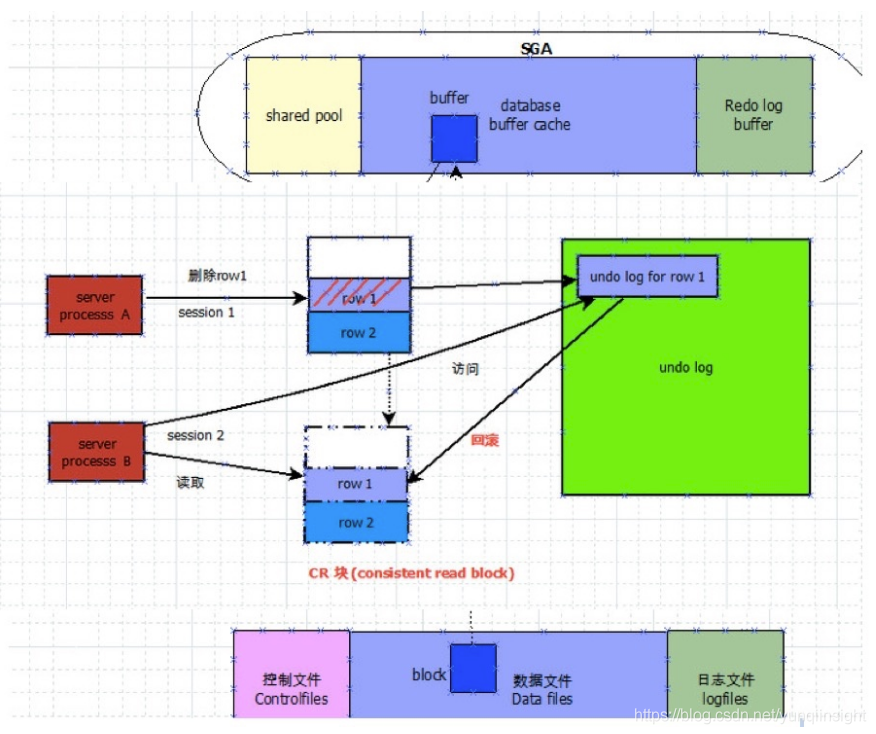
即使是修改一条记录一个字段的几个字节,整个块(8K大小)都会是脏块。随着业务持续写入,大量脏块会消耗数据库内存。所以ORACLE会有多重机制刷脏块到磁盘数据文件上。在事务日志切换的时候也会触发刷脏块操作。如果业务压力测试ORACLE,大量的写导致事务日志切换很频繁,对应的刷脏操作可能相对慢了,就会阻塞日志切换,也就阻塞了业务写入。这就是ORACLE的特点。解决办法就是加大事务日志文件,增加事务日志成员或者用更快的磁盘存放事务日志和数据文件。
ORACLE里一个表就是一个Segment(如果有大对象列还会有独立的Segment,这个先忽略),Segment由多个不一定连续的extent组成,extent由连续的Block(每个大小默认8K)组成,extent缺点是可能会在后期由于频繁删除和插入产生空间碎片。
OceanBase 读写特点
OceanBase会话第一次修改一行记录,如果该记录所在块(64K大小)不在内存(Block Cache)里时也会先从磁盘文件里读入到内存里。这个称为一次物理读。然后要修改时跟ORACLE做法不同的是,OceanBase会新申请一小块内存用于存放修改的内容,并且链接到前面Block Cache里该行记录所在块的那笔记录下。如果修改多次,每次修改都跟前面修改以链表形式关联。同样在修改之前也要先在内存里记录REDO。每次修改都会记录一个内部版本号,记录的每个版本就是一个增量。其他会话读取的时候会先从Block Cache中该记录最早读入的那个版本(称为基线版本)开始读,然后叠加应用后面的增量版本直到合适的版本(类似ORACLE中SCN概念)。(随着版本演进,这里细节逻辑可能会有变化。)
OB的这个读方式简单说就是从最早的版本读起,逐步应用增量(类似REDO,但跟REDO日志无关)。而ORACLE一致性读是从最新的版本读起,逐步回滚(应用UNDO)。在OB里,没有UNDO。当版本链路很长时,OB的读性能会略下降,所以OB也有个checkpoint线程定时将记录的多个版本合并为少数几个版本。这个合并称为小合并(minor compaction)。此外,OB在内存里针对行记录还有缓存,
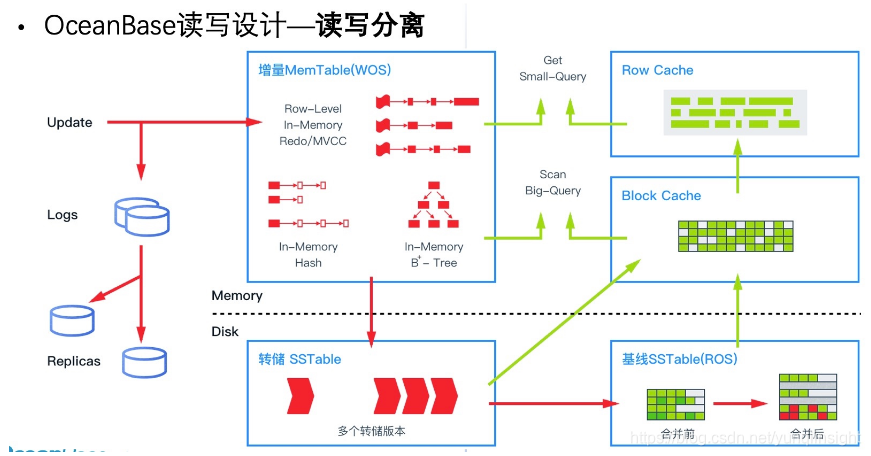
从上面过程还可以看出,每次修改几个字节,在内存里的变脏的块只有增量版本所在的块(默认写满才会重新申请内存),基线数据块是一直不变化。所以OB里脏块产生的速度非常小,脏块就可以在内存里保存更久的时间。实际上OB的设计就是脏块默认不刷盘。那如果机器挂了,会不会丢数据呢?
OB跟ORACLE一样,修改数据块之前会先记录REDO,在事务提交的时候,REDO要先写到磁盘上(REDO同时还会发送往其他两个副本节点,这个先忽略)。有REDO在,就不怕丢数据。此外,增量部分每天还是会落盘一次。在落盘之前,内存中的基线数据和相关的增量数据会在内存里进行一次合并(称Merge),最终以SSTable的格式写回到磁盘。如果说内存里块内部产生碎片,在合并的那一刻,这个碎片空间基本被消弭掉了。所以说OB的数据文件空间碎片很小,不需要做碎片整理。同时OB的这个设计也极大降低了LSM的写放大问题。
当业务压测写OB时,脏块的量也会增长,最终达到增量内存限制,这时候业务就无法写入,需要OB做合并释放内存。OB的合并比较耗IO、CPU(有参数可以控制合并力度),并且也不会等到内存用尽才合并,实际会设置一个阈值。同时为了规避合并,设计了一个转储机制。当增量内存使用率超过阈值后,就开启转储。转储就是直接把增量内存写到磁盘上(不合并)。转储对性能的影响很小,可以高峰期发生,并且可以转储多次(参数配置)。
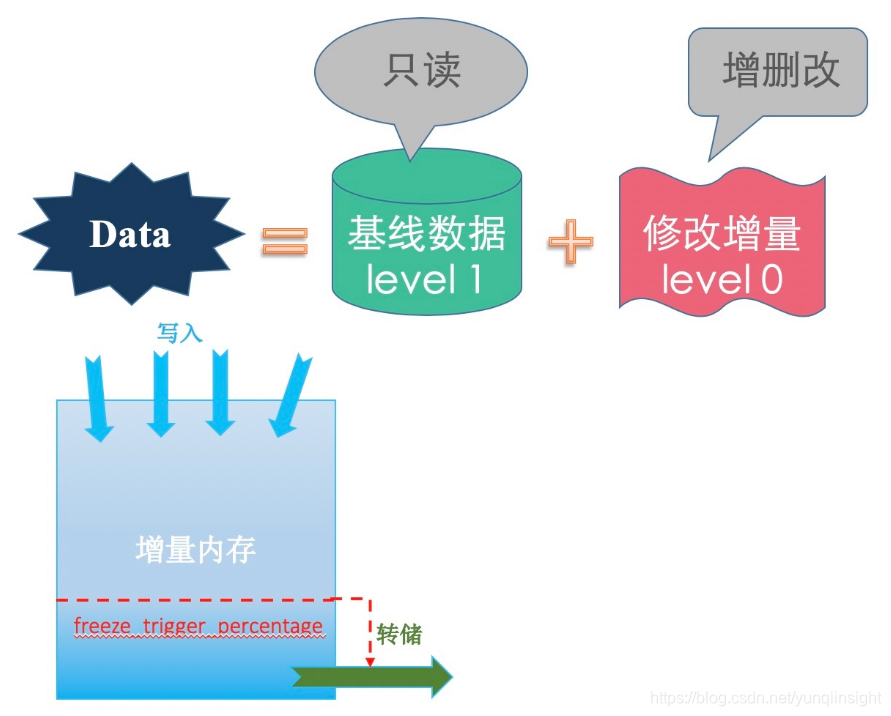
OB增量内存就类似一个水池,业务写是进水管在放水, 转储和大合并是出水管。水位就是当前增量内存使用率。当进水的速度快于出水,池子可能就会满。这时候业务写入就会报内存不足的错误。
这就是OB读写的特点,解决方法就是加大OB内存、或者允许OB自动对业务写入速度限流。
OceanBase部署建议
OB 在commit的时候redo落盘会写磁盘。读数据的时候内存未命中的时候会有物理读,转储和大合并的时候落盘会有密集型写IO。这些都依赖磁盘读写性能。所以建议磁盘都是SSD盘,并且建议日志盘和数据盘使用独立的文件系统。如果是NVME接口的闪存卡或者大容量SSD盘,那日志盘和数据盘放在一起也可以。不要使用LVM对NVME接口的大容量SSD做划分,那样瓶颈可能会在LVM自身。
OB的增量通常都在内存里,内存不足的时候会有转储,可以转储多次。尽管如此,建议测试机器的内存不要太小,防止频繁的增量转储。通常建议192G内存以上。
OB集群的节点数至少要有三个。如果是功能了解,在单机上起3个OB进程模拟三节点是可以的,但是如果是性能测试,那建议还是使用三台同等规格的物理机比较合适。机器规格不一致时,最小能力的机器可能会制约整个集群的性能。 OceanBase集群的手动部署请参考《OceanBase数据库实践入门——手动搭建OceanBase集群》。在部署好OceanBase之后,建议先简单了解一下OceanBase的使用方法,详情请参考文章《OceanBase数据库实践入门——常用操作SQL》。
如果要验证OB的弹性缩容、水平扩展能力,建议至少要6节点(部署形态2-2-2)。并且测试租户(实例)的每个Zone里的资源单元数量至少也要为2个,才可以发挥多机能力。这是因为OB是多租户设计,对资源的管理比较类似云数据库思想,所以里面设计有点精妙,详情请参见《揭秘OceanBase的弹性伸缩和负载均衡原理》。
下面是一个租户的测试租户资源初始化建议
- 登录sys租户
- create resource unit S1, max_cpu=2, max_memory='10G', min_memory='10G', max_iops=10000, min_iops=1000, max_session_num=1000000, max_disk_size=536870912;
- create resource unit S2, max_cpu=4, max_memory='20G', min_memory='20G', max_iops=20000, min_iops=5000, max_session_num=1000000, max_disk_size=1073741824;
- create resource unit S3, max_cpu=8, max_memory='40G', min_memory='40G', max_iops=50000, min_iops=10000, max_session_num=1000000, max_disk_size=2147483648;
- select * from __all_unit_config;
-
- create resource pool pool_demo unit = 'S2', unit_num = 2;
- select * from __all_resource_pool order by resource_pool_id desc ;
-
- create tenant t_obdemo resource_pool_list=('pool_demo');
- alter tenant t_obdemo set variables ob_tcp_invited_nodes='%';
请注意上面的unit_num=2这个很关键。如果unit_num=1,OB会认为这个租户是个小租户,后面负载均衡处理时会有个默认规则。
- 登录业务租户
- create database sbtest;
- grant all privileges on sbtest.* to sbuser@'%' identified by 'sbtest';
sysbench压测建议
因为测试场景跟业务有关,这里就以常见的sysbench场景举例分析
sysbench工具可以建几个结构相同的表,然后执行纯读、纯写、读写混合。其中读又分根据主键或者二级索引查询,等值查询、IN查询或范围查询几种。详细的可以查看官方介绍。
如果用sysbench压测OB,创建很多表是一种方法。另外一种方法就是创建分区表。OceanBase是分布式数据库,数据迁移和高可用的最小粒度是分区,分区是数据表的子集。分区表有多个分区,非分区表只有一个分区。分区表的拆分细节是业务可以定义的。OceanBase可以将多个分区分布到不同节点,也可能不会分布到多个节点。这个取决于OB集群和租户的规划设计。所以对sysbench创建的表(分区),在性能分析时要分析分区具体的位置。
建表准备
下面是sysbench里分区表示例,修改 oltp_common.lua:
- query = string.format([[
- CREATE TABLE sbtest%d(
- id %s,
- k INTEGER DEFAULT '0' NOT NULL,
- c CHAR(120) DEFAULT '' NOT NULL,
- pad CHAR(60) DEFAULT '' NOT NULL,
- %s (id,k)
- ) partition by hash(k) partitions %s %s %s]],
- table_num, id_def, id_index_def, part_num, engine_def, extra_table_options)
需要注意用分区表后,主键列和唯一索引列需要包含分区键。分区表的索引有本地(LOCAL)索引和全局索引两种。本地索引的存储跟数据是在一起的,全局索引的存储是独立的。全局索引是为了应对查询条件不是分区键的场景,没有全局索引时,会扫描所有分区的本地索引。这两种索引的性能优劣没有定论,以实际业务场景测试为准。此外,传统数据库索引对修改操作会有负面影响,分布式数据库的全局索引对修改操作的影响可能更大,因为一个简单的DML语句都会因为要同步修改全局索引而产生分布式事务。而本地索引就没有分布式事务问题。所以对全局索引的使用场景要谨慎评估。这个特性不是OB特有,只要是分布数据库都会面临这个问题。
数据分布均衡
本节是说明OB数据分布背后的原理和方法。
OceanBase是分布式数据库,它通过每个机器上的observer进程将多个机器的资源能力聚合成一个大的资源池,然后再为每个业务分配不同资源规格的租户(实例)。所以每个业务租户(实例)的资源能力都只是整个集群能力的子集。业务并不一定能使用到全部机器资源。
OceanBase里的数据都有三份,细到每个分区有三个副本,角色上有1个leader副本2个follower副本。默认只有leader副本提供读写服务,leader副本所在的节点才有可能提供服务,有负载。OceanBase调整各个节点负载的方法是通过调整内部leader副本的位置实现的。这个调整可以让OceanBase自动做,也可以手动控制。
OceanBase自动负载均衡是参数enable_rebalance控制,默认值为True。可以查看确认。修改用alter system语句。
- alter system set enable_rebalance=True;
- show parameters like 'enable_rebalance';

查看实际表的分区leader副本位置
- ##查看分区分布
- SELECT t5.tenant_id,t5.tenant_name,t3.database_name, t4.tablegroup_name, t2.table_name, t1.partition_id, concat(t1.svr_ip,':',t1.svr_port) observer, t1.role, t1.data_size,t1.row_count
- from `gv$partition` t1 join `__all_table` t2 on (t1.tenant_id=t2.tenant_id and t1.table_id=t2.table_id)
- join `__all_database` t3 on (t2.tenant_id=t3.tenant_id and t2.database_id=t3.database_id)
- left join `__all_tablegroup` t4 on (t1.tenant_id=t4.tenant_id and t1.tablegroup_id=t4.tablegroup_id)
- join `__all_tenant` t5 on (t1.tenant_id=t5.tenant_id)
- where t5.tenant_id = 1020 and role=1 and database_name in ('sysbenchtest')
- order by t5.tenant_id,t3.database_id,t1.tablegroup_id,t1.partition_id, t1.role;
sysbench命令参数
sysbench的机制是压测过程中如果有错误就会报错退出,所以需要针对一些常见的错误进行忽略处理,这样sysbench会话可以重试继续运行。比如说主键或者唯一键冲突、事务被杀等等。
下面的运行命令供参考
- 初始化
./sysbench --test=./oltp_read_only.lua --mysql-host=***.***.82.173 --mysql-port=4001 --mysql-db=test --mysql-user="sbuser" --mysql-password=sbtest --tables=16 --table_size=100000000 --threads=32 --time=300 --report-interval=5 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016 prepare- 纯读
./sysbench --test=./oltp_read_only.lua --mysql-host=***.***.82.173 --mysql-port=4001 --mysql-db=test --mysql-user="sbuser" --mysql-password=sbtest --tables=16 --table_size=100000000 --threads=96 --time=600 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016 --secondary=on run- 纯写
./sysbench --test=./oltp_write_only.lua --mysql-host=***.***.82.173 --mysql-port=4001 --mysql-db=test --mysql-user="sbuser" --mysql-password=sbtest --tables=16 --table_size=100000000 --threads=32 --time=600 --report-interval=5 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016,1062 run- 读写混合
./sysbench --test=./oltp_read_write.lua --mysql-host=***.***.82.173 --mysql-port=4001 --mysql-db=test --mysql-user="sbuser" --mysql-password=sbtest --tables=16 --table_size=100000000 --threads=32 --time=600 --report-interval=5 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016,1062 run测试观察
在纯写或者读写测试中,注意观察增量增量内存使用进度。如果写入速度比转储和合并速度还快,那会碰到内存不足写入失败错误。这就是OB租户资源相对不足了。观察这个内存使用进度可以通过 dooba脚本。dooba脚本默认在/home/admin/oceanbase/bin/目录下。
使用示例如下:
python dooba -h11..84.84 -uroot@sys#obdemo -P2883 -p**
OB有个内部视图gv$sql_audit可以查看执行过所有成功或失败的SQL,用来分析具体的SQL性能。用法详情参见官网(oceanbase.alipay.com) 或 文章《阿里数据库性能诊断的利器——SQL全量日志》。
- select /*+ read_consistency(weak) query_timeout(1000000000) */ usec_to_time(request_time) req_time, svr_Ip, trace_id, sid, client_ip, tenant_id,tenant_name,user_name,db_name, query_sql, affected_rows,ret_code, event, state, elapsed_time, execute_time, queue_time, decode_time, get_plan_time, block_cache_hit, bloom_filter_cache_Hit, block_index_cache_hit, disk_reads,retry_cnt,table_scan, memstore_read_row_count, ssstore_read_row_count, round(request_memory_used/1024/1024) req_mem_mb
- from gv$sql_audit
- where tenant_id=1012 and user_name in ('demouser')
- order by request_time desc
- limit 100;
经验总结
本节是一些测试场景的经验总结,需要提前了解一些OceanBase的原理特性介绍。
实际测试情形可能会出现由于是三节点部署,所以测试时压力都打到一台服务器上,这个建议用六节点测试。还有个办法就是禁用自动负载均衡手动调整分区位置。调整是OB给业务的手段,业务上有些表会有JOIN,为了性能(避免跨节点请求),业务需要这种干预能力。
还有一种情形是写入压力非常大,跑了一段时间后报内存不足的提示,这个就是租户内存资源相对写入速度和量不足了(OB的转储和合并对内存的回收赶不上写入对内存的消耗),此时需要扩容或者调整测试需求。OB 2.x版本还有自动对应用写入限速功能(自我保护),这个会影响测试报告里性能结果。如果数据库分析sql性能以及分布式调优都做了,那可以认为当前写入的TPS就是数据库的写入峰值了。需要注意的是不同的硬件,不同的租户规格,不同的测试场景,这个TPS能力都表现不同。
sysbench有个batch insert功能,当表是分区表的时候,默认这个batch insert 很可能会产生分布式事务,性能比单表写入要慢。需要靠提高客户端并发数来提升总的吞吐量。此外这个批量的大小不宜太大。由于OB支持SQL执行计划缓存,SQL文本过大且并发很高时,会在SQL解析环节面临内存不足问题。数据库内存的大部分还是主要用于存取数据。JAVA的addBatch方法也同理,建议批量大小设置为100以内。
在查询验证数据的时候,可能会碰到超时类错误。OB里超时的可能场景有多个:
- SQL语句超时,由租户变量 ob_query_timeout控制。单位是微秒,默认是10秒。
- 事务空闲超时,由租户变量 ob_trx_idle_timeout控制。单位是微秒,默认120秒。
- 事务超时,由租户变量 ob_trx_timeout控制。单位是微秒,默认100秒。
以上超时时间都可以在租户里根据实际情况修改。
其他
关于使用分布式数据库测试,不同的做法可以得到不同的结果。即使是同一个OB租户(实例),不同的人设计的表结构不同,或者SQL不同都有可能取得不同的性能数据。这些不同都是可以从原理上给出解释。熟知这些原理的更容易发挥OB的分布式数据库特点。使用越深入会发现这个原理越多且更加有趣。当然环境、场景的不同,还是会遇到一些问题。如果有碰到问题,欢迎公众号留言讨论。
原文链接
本文为云栖社区原创内容,未经允许不得转载。

