
- 1文心一言 VS 讯飞星火 VS chatgpt (71)-- 算法导论7.1 1题
- 2技术思维vs管理思维 程序员与项目经理5大思维差异_技术与管理的思维模式区别与联系
- 32024年2月份实时获取地图边界数据方法,省市区县街道多级联动【附实时geoJson数据下载】_南沙区乡镇行政边界 geojson数据
- 4Android从外部API获取json数据并以listview形式展现
- 5微信小程序image组件图片设置最大宽度 宽高自适应_小程序全屏图片大小
- 6python:消息推送 - 飞书机器人推送 - 富文本格式_python怎么给飞书发送通知
- 7Android编译系统之交叉编译器详解_android 交叉编译
- 8yolov4 flask部署web服务(视频检测)_yolo-flask视频识别
- 9【毕业设计/课程设计】基于微信小程序的在线求职/招聘系统设计与实现(源码+文章) 含Java Web管理端_招聘小程序源码
- 10DFI(Deep/DynamicFlow Inspection,深度/动态流检测)_dfi深度流量
实用篇-ES-DSL查询文档_es 查询所有的文档
赞
踩
数据的存储不是目的,我们希望从海量的酒店数据中检索出需要的信息,这就是ES的搜索功能
官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl。DSL是用来查询文档的
Elasticsearch提供了基于JSON的DSL来定义查询,简单说就是用json来描述查询条件,然后发送给es服务,最后es服务基于查询条件,把结果返回给我们
常见的查询类型包括如下:
1、查询所有: 查询出所有数据,一般在测试的时候使用
match_all2、全文检索查询: 利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配
match_querymulti_match_query3、精确查询: 根据精确的词条值去查找数据,一般是查找keyword、数值、日期、boolean等类型的字段。这些字段是不需要分词的,但是依旧会建立倒排索引,把字段的整体内容作为一个词条,并存入倒排索引。在查找的时候,也就不需要分词,直接把搜索的内容去跟倒排索引匹配即可
- ids,表示根据id,进行精确匹配
-
- range,表示根据数值范围,进行精确匹配
-
- term,表示根据数据的值,进行精确匹配
4、地理查询: 根据经纬度查询
geo_distancegeo_bounding_box5、复合查询: 复合查询可将上述各种查询条件组合一起,合并查询条件
bool,利用逻辑运算把其它查询条件组合起来function_score,用于控制相关度算分,算分会影响性能一、DSL查询语法

- GET /hotel/_search
- {
- "query": {
- "match_all": {}
- }
- }
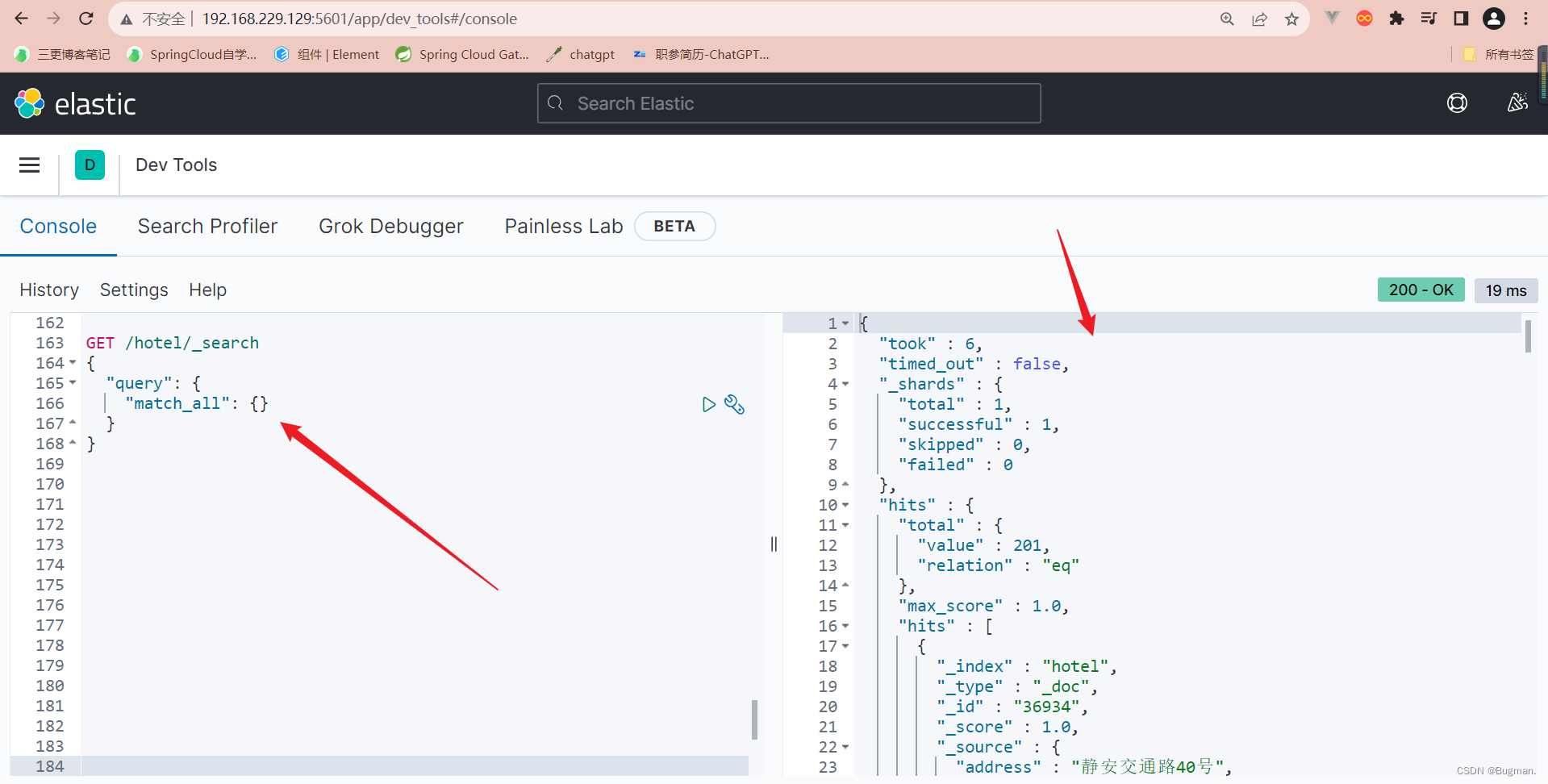
存在一个问题,我们明明查询的是所有文档,查询结果也显示查询出所有的文档了,为什么上图右侧,鼠标往下拉,最多才只有10条文档数据呢
原因: 受默认的分页条件限制,后面学习的时候,会进行解决
二、全文检索查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为hotel的索引库,导入了批量文档。然后开始下面的操作
全文检索查询,分为下面两种,会对用户输入内容进行分词之后,再进行匹配。也就是利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配
match_querymulti_match_query【第一种全文检索查询】
match查询(也就是match_query查询): 全文检索查询的一种,会对用户输入的内容进行分词,然后去倒排索引库检索
- GET /索引库名/_search
- {
- "query": {
- "match": {
- "字段名": "TEXT"
- }
- }
- }
具体操作如下,为了让大家知道hotel索引库有哪些字段,我把当初建立gghotel索引库的类先放出来
注意: 我要解释一下,上面有个字段叫all,那个字段是当时自定义的,不清楚的话可回去看 '实用篇-ES-RestClient操作' 的 'hotel数据结构分析'。
all的作用如下图,相当于一个大的字段,里面存放了几个小字段,优点是我们可以在这个大的字段里面搜索到多个小字段的信息
然后,我们就正式开始全文检索查询,输入如下。注意all换成其它字段也没事,例如换成name字段。正常来说,我们检索name字段,就只在name字段检索匹配的分词文档,但是在all字段里面检索时,也会检索到name、brand、business字段,原因如上面那个图的copy_to属性

【第二种全文检索查询】
multi_match(也就是multi_match_query查询): 与match查询类似,只不过允许同时查询多个字段
- GET /索引库名/_search
- {
- "query": {
- "multi_match": {
- "query": "TEXT",
- "字段名": ["FIELD1", " FIELD12"]
- }
- }
- }
- # 第二种全文检索查询 multi_match。查询business、brand、name字段中包含'如家'的文档,满足一个字段即可
- GET /hotel/_search
- {
- "query": {
- "multi_match": {
- "query": "如家",
- "fields":["business","brand","name"]
- }
- }
- }

三、精确查询

term: 根据词条的精确值查询,强调精确匹配
range: 根据值的范围查询,例如金额、时间
【第一种精确查询 term】
具体操作如下
查询city为杭州
- GET /hotel/_search
- {
- "query":{
- "term":{
- "city":{
- "value":"杭州"
- }
- }
- }
- }
【第二种精确查询 range】
- GET /hotel/_search
- {
- "query": {
- "range": {
- "price": {
- "gte": 10,
- "lte": 20
- }
- }
- }
- }
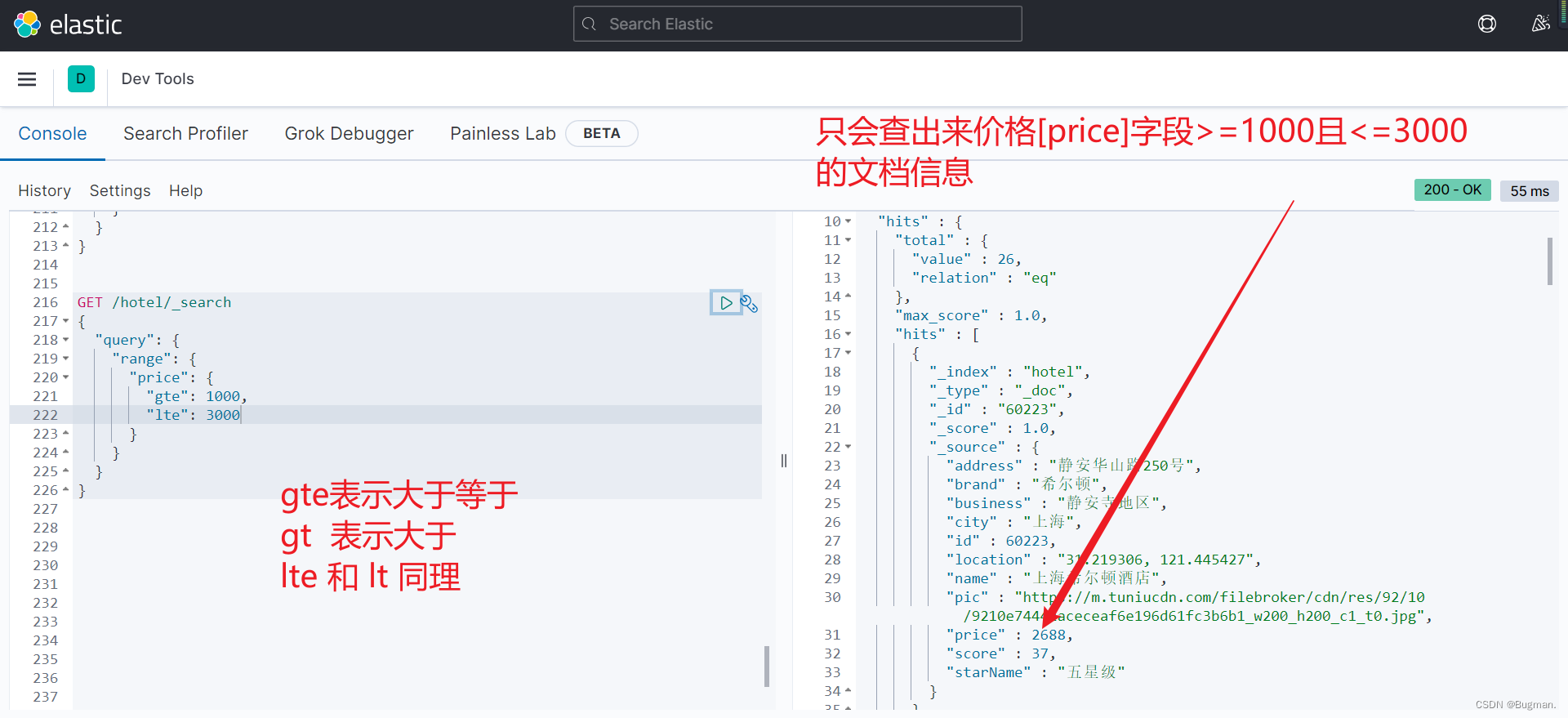
四、地理查询
根据经纬度查询。常见的使用场景包括: 查询附近酒店、附近出租车、搜索附近的人。使用方式有很多种,介绍如下,这种最常用
geo_distance: 查询到指定中心点,以该点为圆心,distance为半径的圆,符合要求的所有文档
- GET /索引库名/_search
- {
- "query": {
- "geo_distance": {
- "distance": "15km",
- "字段名": "31.21,121.5"
- }
- }
- }

具体操作如下
输入如下DSL语句
- GET /hotel/_search
- {
- "query": {
- "geo_distance": {
- "distance": "15km",
- "location": "31.21,121.5"
- }
- }
- }
五、相关性算分
上面学的全文检索查询、精确查询、地理查询,这三种查询在es当中都称为简单查询,下面我们将学习复合查询。复合查询可以其它简单查询组合起来,实现更复杂的搜索逻辑,其中就有 '算分函数查询' 如下
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为hotel的索引库,导入了批量文档。然后开始下面的操作
算分函数查询(function score): 可以控制文档相关性算分、控制文档排名。例如搜索'外滩' 和 '如家' 词条时,某个文档要是都能匹配这两个词条,那么在所有被搜索出来的文档当中,这个文档的位置就最靠前,简单说就是越匹配就排名越靠前


六、函数算分查询
上面只是简单演了相关性打分中的函数算分查询,文档与搜索关键字的相关度越高,打分就越高,排名就越靠前。不过,有的时候,我们希望人为地去控制控制文档的排名,例如某些文档我们就希望排名靠前一点,算分高一点,此时就需要使用函数算分查询,下面就来学习 '函数算分查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
使用 ’函数算分查询(function score query)’,可以在原始的相关性算分的基础上加以修改,得到一个想要的算分,从而去影响文档的排名,语法如下
- GET /索引库名/_search
- {
- "query": {
- "function_score": {
- "query": { "match": {"字段": "词条"} },
- "functions": [
- {
- "filter": {"term": {"指定字段": "值"}},
- "算分函数": 函数结果
- }
- ],
- "boost_mode": "加权模式"
- }
- }
- }

function score需要考虑的三要素
1. 哪些文档需要算分加权
2. 算分函数是什么
3. 加权模式是什么
下面我们实现一个案例:给如家这个品牌的酒店排名靠前一些
考虑三要素
1. 哪些文档需要算分加权 brand为如家的酒店
2. 算分函数是什么 weigh
3. 加权模式是什么 相加/相乘都可
输入如下DSL语句,表示在 '如家' 这个品牌中,字段为'北京'的酒店排名靠前一些
七、布尔查询
这是第二种复合查询
布尔查询不会去修改算分,而是把多个查询语句组合成一起,形成新查询,这些被组合的查询语句,被称为子查询。子查询的组合方式有如下四种
1、must:必须匹配每个子查询,类似"与"
2、should:选择性匹配子查询,类似"或"
3、must_not:必须不匹配,不参与算分,类似"非"
4、filter:必须匹配,不参与算分
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
输入如下DSL语句,表示搜索名字包含'如家',价格不高于400,在坐标31.21,121.5周围10km范围内的文档
八、搜索结果处理
lasticsearch(称为es)支持对搜索的结果,进行排序,默认是根据 '相关度' 算分,也就是score值,根据score值进行排序。
可以排序的字段类型有: keyword类型、数值类型、地理坐标类型、日期类型
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
1. 排序
输入如下DSL语句,表示对所有的文档,根据评分(score)进行降序排序,如果评分相同就根据价格(price)升序排序

2. 分页
elasticsearch(称为es)默认情况下只返回前10 条数据。而如果要查询更多数据就需要修改分页参数,分页参数包括from和size,语法如下
- GET /索引库名/_search
- {
- "query": {
- "要查询的字段": {}
- },
- "from": 要查第几页, // 分页开始的位置,默认为0
- "size": 每页显示多少条文档, // 期望获取的文档总数
- "sort": [ //表示排序
- {"price": "排序方式"}
- ]
- }
输入如下DSL语句,表示对所有的文档,根据价格(price)进行升序排序,每次分页显示20条数据,看的是第六页
size默认是10,表示一页显示多少条文档。from默认是0,表示你要看的是第一页
- GET /hotel/_search
- {
- "query": {
- "match_all": {}
- },
- "sort": [
- {
- "price": {
- "order": "asc"
- }
- }
- ],
- "from": 5,
- "size": 20
- }


3. 搜索结果处理-高亮
高亮: 就是在搜索结果中把搜索关键字突出显示。高亮显示的原理如下
1、将搜索结果中的关键字用标签标记出来
2、在页面中给标签添加css样式
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
语法
- GET /索引库名/_search
- {
- "query": {
- "match": { //match表示带关键字的查询
- "字段": "TEXT"
- }
- },
- "highlight": {
- "fields": {
- "字段名": {
- "require_field_match": "false",//默认是true,表示 '字段' 要和 '字段名' 要一致。如果我们写的是不一致的话,就需要修改为false
- "pre_tags": "<em>", // 用来标记高亮字段的前置标签,es会帮我们把标签加在关键字上。默认是<em>
- "post_tags": "</em>" // 用来标记高亮字段的后置标签,es会帮我们把标签加在关键字上。默认是</em>
- }
- }
- }
- }


总结
- GET /索引库名/_search
- {
- "query": {
- "match": {
- "字段名": "如家"
- }
- },
- "from": 0, // 分页开始的位置
- "size": 20, // 期望获取的文档总数
- "sort": [
- { "price": "asc" }, // 普通排序
- {
- "_geo_distance" : { // 距离排序
- "location" : "31.040699,121.618075",
- "order" : "asc",
- "unit" : "km"
- }
- }
- ],
- "highlight": {
- "fields": { // 高亮字段
- "字段名": {
- "pre_tags": "<em>", // 用来标记高亮字段的前置标签
- "post_tags": "</em>" // 用来标记高亮字段的后置标签
- }
- }
- }
- }


