
热门标签
热门文章
- 1【shell】读取表格文件的数据_shell读取excel
- 29个免费的AI辅助编程工具,智能自动编写和生成代码_辅助开发ai工具
- 340-找数组中只出现奇数次的n个数字(n=1,2)_数组中只有两个奇数
- 4外接显示器设置_简单又实用,Macbook外接显示器有哪些好操作
- 5自己动手做百度首页_百度网页html制作
- 62.1 Verilog HDL基本结构_always块的敏感列表中是否可以写wire
- 7HFish|一款安全、简单、有效的蜜罐平台|搭建与使用详细教学_蜜罐搭建
- 8基于人脸识别的考勤系统:Python3 + Qt5 + OpenCV3 + FaceNet + MySQL_人脸识别考勤app 开源
- 9前端开发:JS中向对象中添加对象的方法_一个对象如何添加另一个对象
- 10数据结构学习笔记——多维数组、矩阵_多维矩阵是什么意思
当前位置: article > 正文
大数据库课程(项目2 结构化数据仓库——Hive)_结构化数据库
作者:Cpp五条 | 2024-05-23 23:17:24
赞
踩
结构化数据库
项目2 结构化数据仓库——Hive
- 项目描述
- 项目背景
- 信息时代的来临使得企业营销焦点从以产品中心转变为以客户为中心,客户关系管理成为企业的核心问题。客户关系管理的关键问题是客户分类,通过客户分类,可以得到不同价值的客户,从而采取个性化服务方案,将有限营销资源集中于高价值客户,实现企业利润最大化目标。
- 国内某航空公司面临着常旅客流失,竞争力下降和航空资源未充分利用等经营危机。目前该航空公司已积累了大量的会员档案信息和其乘坐航班记录,数据字段及其说明如右表所示。实现航空公司客户价值分析首先需要对航空客户数据进行探索分析和处理,考虑到数据量、数据类型的问题,将使用Hive数据仓库工具对航空客户数据进行数据存储、探索分析和处理。
- 项目背景

-
-
- 项目目标
- 本项目将对Hive的架构原理、安装流程进行介绍,结合航空公司客户价值分析实例,详细介绍Hive的基本操作,并使用Hive实现航空公司客户价值分析建模的特征数据的构建。
- 项目分析
- 学习Hive的架构原理及集群搭建过程,根据航空公司客户价值分析的业务需求安装配置Hive集群。
- 学习Hive表创建、管理与表数据的导入导出操作,在Hive中创建航空客户信息表,并导入航空客户数据至Hive表中。
- 学习Hive的SELECT基础查询语句,对航空客户数据字段进行描述性统计,查询数据字段的空值、最大值和最小值,对航空客户数据的质量有一定了解。
- 学习HiveQL子查询语句与自定义UDF函数,并对航空客户数据进行基础探索,统计客户的会员级别和入会时长。
- 对航空客户数据进行业务探索,并构建适合用于航空客户价值分析建模的特征数据。
- 1.了解Hive的架构原理
- 任务描述
- Hive数据仓库基于Hadoop开发,是Hadoop生态圈组件之一,具备海量数据存储和处理能力,是大数据领域离线批量处理数据的常用工具。
- 本小节的任务是了解Hive的起源、特点及其架构,这是学习与掌握Hive海量数据存储计算的第一步。
- 大数据体系的共同点
- 模块化
- 平台化
- 实时化
- 不完善
- 1. Hive的简介
- Hive起源于Facebook(脸书)的杰夫·汉姆贝彻的团队,Facebook是美国的一个社交网站,主要创始人是马克·扎克伯格。2008年3月,Facebook每天产生200GB的评价数据。2008年10月,每天产生的数据经压缩后已经超过了2TB。
- 面对越来越大的数据规模,传统的数据库已经无法满足数据的管理和分析的需求,为了解决这一问题,Facebook自主研发出一款数据管理规模远超传统数据库的新产品——Hive。
- Hive就是一个数据仓库, 仓库中的数据都是在HDFS中管理的数据文件
- Hive 支持类似SQL语句的功能
- Hive 所处理的是已经存储起来的数据,这种计算也就是我们所说的离线计算
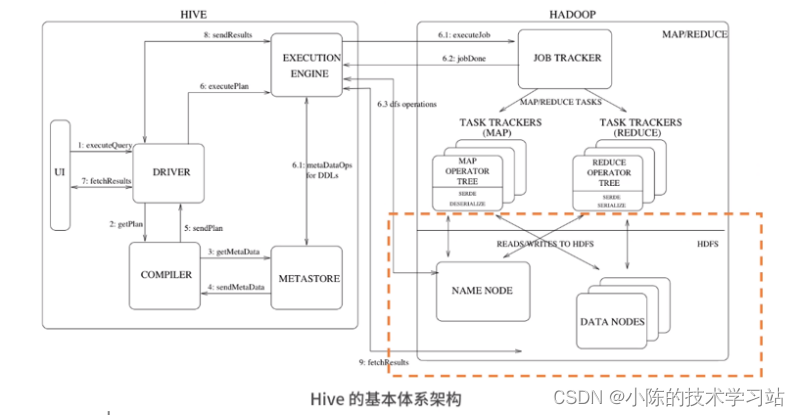
- Hive的基本体系架构
- 任务描述
-
-
-
-
- (1) UI
- 用户界面,主要负责与使用者的交互
- 通过UI向系统提交查询和其他操作
- (2)驱动器(Driver)
- 驱动器在接收HiveQL语句之后
- 创建会话来启动语句的执行,并监控执行的生命周期和进度
- 驱动器既负责与编译器的交互,又负责与执行引擎的交互
- (3) 编译器(Compiler)
- 编译器接收驱动器传来的HiveQL
- 并从元数据仓中获取所需要的元数据
- 然后对HiveQL语句进行编译,将其转化为可执行的计划
- (4)执行引擎(Execution Engine)
- 它对Hadoop的作业进行跟踪和交互,调度需要运行的任务
- (5)元数据仓(Metastore)
- 在编译和优化之后,执行器将执行任务
- 构建的Hive表的表名、表字段、表结构、分区、类型存储路径等等
- 元数据通常存储在传统的关系型数据库中,比如MySQL
- Hive的优点

- (1) UI
-
-
-
-
-
- Hive的缺点

- Hive的缺点
-
-
-
-
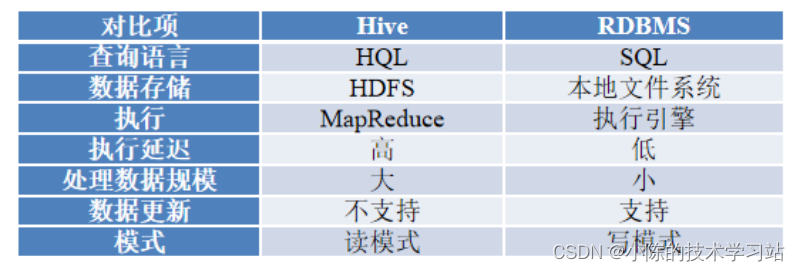
- Hive是基于HDFS和MapReduce的分布式数据仓库。
- 传统的数据库主要应用于基本的、日常的事务处理,如银行转账。数据仓库侧重决策支持,提供直观的查询结果,主要用于数据分析。
- Hive与传统数据库(RDBMS)之间的对比如下表所示。
-
-
-
- 2. Hive的特点
- Hive具有可伸缩、可扩展、高容错的特点。
- 可伸缩:Hive为超大数据集设计了计算和扩展能力(MapReduce作为计算引擎,HDFS作为存储系统)。一般情况下,不需要重启服务Hive就可以自由的扩展集群的规模。
- 可扩展:除了HQL自身提供的能力,用户还可以自定义数据类型、也可以用任何语言自定义Mapper和Reducer脚本,还可以自定义函数(普通函数、聚集函数)等,这赋予了Hive极大的可扩展性。
- 高容错:Hive本身并没有执行机制,用户查询的执行是通过MapReduce框架实现的,由于MapReduce框架本身具有高容错的特点,所以Hive也相应具有高容错的特点。
- Hive相较于传统的数据库,Hive结构更为简单,处理数据的规模更为庞大,但Hive不支持数据更新,有较高的延迟,并且Hive在作业提交和调度的时候需要大量的开销。Hive并不能够在大规模数据集上实现低延迟快速的查询。
- Hive主要适用于日志分析、多维度数据分析,海量结构化数据离线分析等场景。
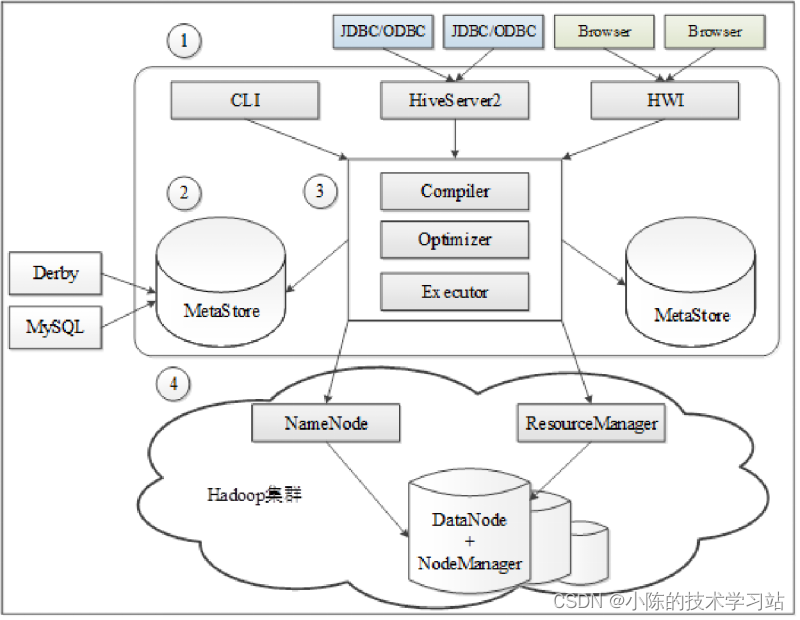
- Hive架构由用户接口、元数据库、解析器、Hadoop集群组成。
- 2. Hive的特点
-
-
-
-
- 用户接口:用于连接访问Hive,包括命令行接口(CLI)、JDBC/ODBC和HWI(Hive Web Interface)3种方式。
- Hive元数据库(MetaStore):Hive数据包括数据文件和元数据,数据文件存储在HDFS,元数据信息存储在数据库中,如Derby(Hive默认数据库)、MySQL,Hive中的元数据信息包括表的名字、表的列和分区、表的属性、表的数据所在的目录等。
- Hadoop集群:Hive用HDFS进行存储,用MapReduce进行计算,Hive数据仓库的数据存储在HDFS中,业务实际分析计算是利用MapReduce执行的。
- 从Hive架构图可以看出,Hive本质上可以理解为一个客户端工具,或是一个将SQL语句解析成MapReduce作业的引擎。Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce。
-
- 2.安装配置Hive
- 对Hive有了初步了解后,还需要安装Hive组件,这是学习Hive的前提条件。
- Hive使用Hadoop的MapReduce作为执行引擎,使用HDFS作为底层存储,因此安装Hive之前需要先搭建Hadoop集群环境。本小节的任务是搭建Hadoop集群和Hive工具。
- 由于Hive完全依赖于Hadoop的HDFS和MapReduce,所以在安装配置Hive前需要先搭建好Hadoop集群。(了解过程)
- 在本文中采用的分布式Hadoop集群版本为2.6.4,共有4个节点,包括1个主节点和3个子节点
- 主节点主机名为master
- 子节点分别为slave1、slave2和slave3
- 每个节点都采用一个单核处理器,内存最大值均为1024MB,操作系统为Centos版本的Linux操作系统。
- 搭建Hadoop集群
- 在Linux系统主节点master下启动集群,在master、slave1、slave2和slave3上分别执行命令“jps”,若出现右图所示的信息,则说明集群启动成功。
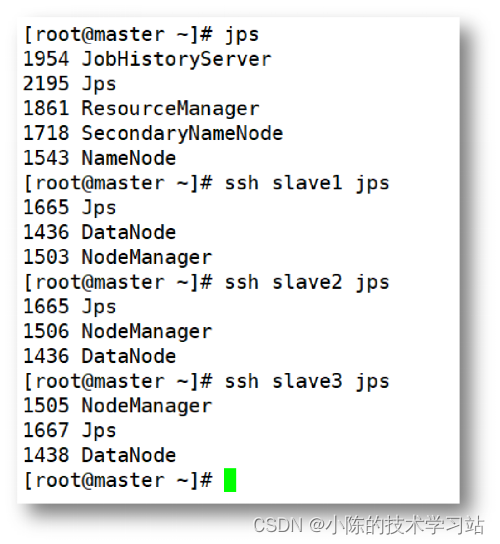
- 在Linux系统主节点master下启动集群,在master、slave1、slave2和slave3上分别执行命令“jps”,若出现右图所示的信息,则说明集群启动成功。
-
-
-
-
- 集群节点均配置了主机名与IP地址的映射,因此在Hive的配置过程中,会直接使用主机名代替IP地址。
- 配置MySQL数据库
- 将Hadoop集群所有节点中的jline-0.9.94.jar替换为jline-2.12.jar。先将每个节点的/usr/local/hadoop-2.6.4/share/hadoop/yarn/lib目录下的jline-0.9.94.jar重命名为jline-0.9.94.jar.bak。
- Hive会将表中的元数据信息存储在数据库中,但Hive的默认数据库Derby存在并发性能差的问题,在实际生产环境中适用性较差,因此在实际生产中常常会使用其他数据库作为元数据库以满足实际需求。
- MySQL是一个开源的关系型数据库管理系统,由瑞典MySQL AB公司开发,属于Oracle旗下产品。MySQL是最流行的关系型数据库管理系统之一,它具有体积小、速度快、成本低等特点,适合作为存储Hive元数据的数据库。
- 安装MySQL后,在命令行输入“mysql -u root -p123456”(根据安装时所示的设置,用户名为root,密码为123456)命令登录MySQL,MySQL设置远程访问权限命令。
- 配置Hive数据仓库
- 完成Hadoop集群准备以及MySQL的配置后,可以开始安装并配置Hive,安装配置Hive需要以下3个文件。
- MySQL驱动包:mysql-connector-java-5.1.42-bin.jar。
- Hive安装包:apache-hive-1.2.1-bin.tar.gz。
- 配置文件:hive-site.xml。
- 在Linux系统中,Hive的安装配置步骤如下。
- 将准备的文件上传至Linux系统的/usr/local/src目录下。
- 在命令行输入“cd /usr/local/src”命令切换至/usr/local/src目录,再输入“tar -xzvf apache-hive-1.2.1-bin.tar.gz -C /usr/local/”命令,解压apache-hive-1.2.1-bin.tar.gz文件至/usr/local/目录下。
- 在命令行输入“mv /usr/local/apache-hive-1.2.1-bin hive”命令,修改apache-hive-1.2.1-bin名称为hive。
- Hive安装完成后,输入“ls -l ../”命令,查看/usr/local/src目录的上一级目录(即/usr/local)包含的详细信息,可在/usr/local/目录下看见Hive的安装目录“hive”,如下图所示。
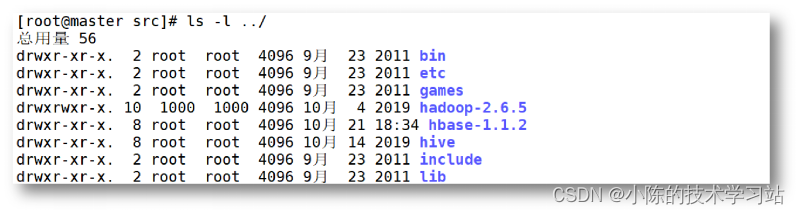
- 完成Hadoop集群准备以及MySQL的配置后,可以开始安装并配置Hive,安装配置Hive需要以下3个文件。
-
-
-
-
-
- 接着Hive的安装配置。
- 进入到/usr/local/hive/conf目录下,执行“cp hive-env.sh.template hive-env.sh”命令复制hive-env.sh.template文件并重命名为hive-env.sh,然后执行“vi hive-env.sh”命令编辑hive-env.sh配置文件,在文件末尾添加Hadoop安装目录的路径。
- 执行“vi /etc/profile”命令编辑/etc/profile文件,配置Hive的环境变量。执行“source /etc/profile”命令使配置生效。
- 在/usr/local/hive/conf目录下,新建一个名为“hive-site.xml”的文件,并添加Hive配置。
- 复制MySQL驱动包至$HIVE_HOME/lib目录下。
- 在master节点将/usr/local/hive/lib/目录下的jline-2.12.jar分发到所有节点的/usr/local/hadoop-2.6.4/share/hadoop/yarn/lib目录下。
- Hive配置完成后,需要先启动Hive的元数据服务,再进入Hive。若出现下图所示的界面,说明Hive安装配置成功。
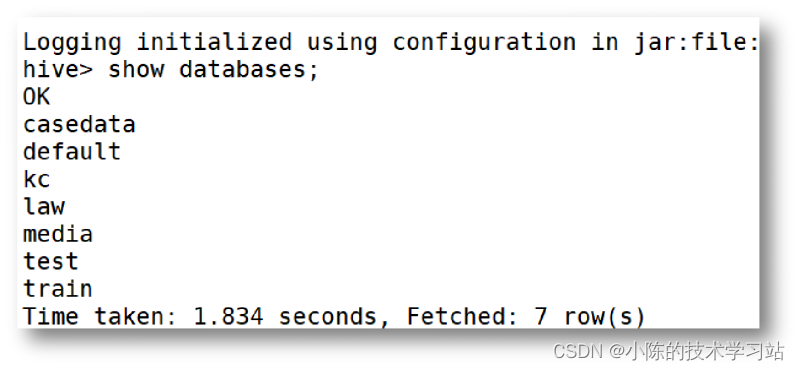
- 接着Hive的安装配置。
-
-
-
- 3.创建航空客户信息表
- 成功安装配置Hive后,即可使用Hive存储数据。
- 存储数据前,需要在Hive中先创建表。
- 本小节的任务是结合航空公司客户数据的结构,在Hive中创建航空客户信息表。
- 掌握Hive基础数据类型
- 在创建Hive表时需要指定字段的数据类型,Hive数据类型可以分为基础数据类型和复杂数据类型。Hive数据类型说明如下表所示。
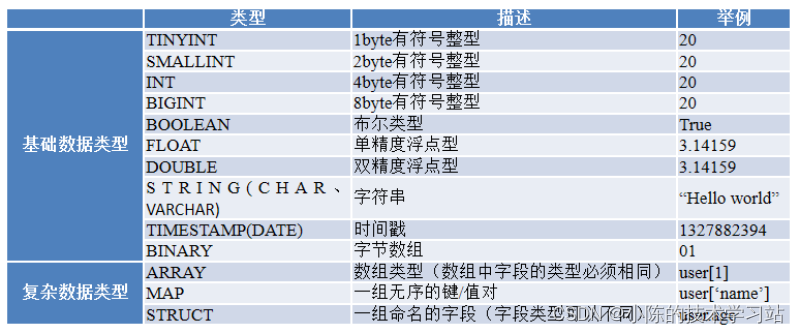
- 在创建Hive表时需要指定字段的数据类型,Hive数据类型可以分为基础数据类型和复杂数据类型。Hive数据类型说明如下表所示。
- 3.创建航空客户信息表
-
-
-
- 创建表
-
-
Hive建表语法如下。 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] // 指定字段的名称和字段数据类型。 [COMMENT table_comment] // 表的描述信息。 [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] // 表的分区信息。 [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] // 表的桶信息。 [ROW FORMAT row_format] // 表的数据分割信息,格式化信息。 [STORED AS file_format] // 表数据的存储序列化信息。 [LOCATION hdfs_path] // 数据存储的文件夹地址信息。
-
-
-
-
- 内部表和外部表区别在于,外部表的数据可以由Hive之外的进程管理(如HDFS)。
- Hive中常见的表类型有3种:内部表,外部表,分区表。
- 创建数据表部分关键字解释说明如下。
- EXTERNAL:若不使用EXTERNAL关键字则创建的表为内部表,若使用EXTERNAL关键字则可以创建一个外部表,用户可以访问存储在远程位置(如HDFS)中的数据,因此,当数据位于远程位置时,应使用外部表。
- CREATE TABLE:创建一个指定名字的表,若相同名字的表已经存在,则抛出异常,用户可以用IF NOT EXISTS选项忽略这个异常,新表将不会被创建。
- PARTITIONED BY:使用该关键字可以创建分区表,一个表可以具有一个或多个分区字段,并根据分区字段中的每个值创建一个单独的数据目录。
- 1. 创建内表
- 内部表是Hive中比较常见、基础的表,表的创建方式与SQL语句大致相同,字段间的分隔符默认为制表符“\t”,需要根据实际情况修改分隔符。
- 2. 创建外表
- 外部表描述了外部文件上的元数据。外部表数据可以由Hive外部的进程访问和管理,这种方式可以满足一份数据多人在线使用,因此外部表适用于部门间的共享数据的场景。
- 当外部表源数据位于HDFS时,删除外部表仅仅是删除元数据信息,源数据不会从远程位置中删除;而内部表是由Hive进行管理的,在删除内部表时,源数据也会被删除。
- 一般情况下,在创建外部表时会将表数据存储在Hive的数据仓库路径之外。
- 3. 创建分区表
- 当数据量很大时,查询速度会很慢,耗费大量时间,如果只需查询其中部分数据,那么可以使用分区表,提高查询的速度。
-
-
- 4.导入航空客户数据到航空客户信息表
- 5.查询航空客户信息表数据空值记录数
- 小结
- Hive解析器(驱动Driver):Hive解析器的核心功能是根据用户编写的SQL语法匹配出相应的MapReduce模板,并形成对应的MapReduce job进行执行,Hive中的解析器在运行时会读取元数据库MetaStore中的相关信息。
- 本章首先介绍了Hive数据仓库的起源、特点及框架原理。
- 其次,介绍了Hive的安装配置流程。
- 接着通过航空公司客户分析案例,详细介绍了Hive的基础数据类型、内置函数和Hive自定义函数UDF等基础操作,最后使用Hive构建出航空客户价值分析的特征数据,使读者对Hive的编程知识有更加深刻的理解。
-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/614812
推荐阅读
相关标签

