
热门标签
热门文章
- 12022朝花夕拾-持续快速成长
- 2Oracle 数据库唯一约束中的NULL的处理_oracle 唯一索引空值怎样处理
- 3区块链与金融监管:如何实现金融稳定和监管效果
- 4vue-element-admin-template 登陆报500超时错误 解决方案_vue-admin-template request failed with status code
- 5C语言与嵌入式AI边缘计算:TinyML、TensorFlow Lite在嵌入式设备上的应用(一)_c语言ai编程
- 6[MYSQL]数据同步提示:Specified key was too long;max key length is 767 bytes_数据库同步时specified key was too long; max key length i
- 7python智能联系人管理_基于python的智能联系人管理应用设计
- 8什么是分布式集群?
- 9CCF-GESP计算机学会等级考试2023年9月二级C++T2数字黑洞_2780: gsep2级9月 2.数字黑洞
- 10双非二本如何入职腾讯?只需要做好这些准备就能进大厂?_怎么入职腾讯
当前位置: article > 正文
(06)Hive——正则表达式_hive 正则
作者:Monodyee | 2024-05-21 23:11:00
赞
踩
hive 正则
Hive版本:hive-3.1.2
一、Hive的正则表达式概述
正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。
Hive的正则表达式灵活使用解决HQL开发过程中的很多问题,本篇文章主要对hive正则表达式的总结归纳。关系型数据库的正则表达式如下:
- like
- rlike
- regexp
- regexp_extract
- regexp_replace
1.1 字符集合
| 字符 | 描述 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [A-Z] | '[A-Z]' 可以匹配 'A' 到 'Z' 范围内的任意大写字母字符。 |
| [^a-z] | 匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \d | 匹配一个数字字符,等价于[0-9],匹配所有的数字 |
| \D | 匹配一个非数字字符,等价于[^0-9] |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]' |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]' |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM |
1.2 边界集合
| 字符 | 描述 |
| ^ | 每一行的开头,单行模式下等价于字符串的开头 |
| $ | 每一行的结尾,单行模式下等价于字符串的结尾 |
1.3 量词(重复次数)集合
| 字符 | 描述 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,} |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,} |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1} |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}'能匹配 "food" 中的两个 o |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 能匹配 "foooood" 中的所有 o |
| {n,m} | m 和n均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o |
1.4 转义操作符
| 字符 | 描述 |
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符等。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符 |
1.5 运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序。相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 | 示例 |
| 转义符\ | \ 是用于转义其他特殊字符的转义符号。它具有最高的优先级。 | \d 匹配数字,\. 匹配点号 |
| 圆括号() | 圆括号()用于创建子表达式,具有高于其他运算符的优先级。 | (abc)+ 匹配 "abc" 一次或多次 |
| 量词 *, +, ?, {n}, {n,}, {n,m} | 量词指定前面的元素可以重复的次数。 | a* 匹配零个或多个 "a" |
| 定位点^, $ | ^ 表示行的开头,$ 表示行的结尾 | |
| 管道符号| | | 表示"或"关系,用于在多个模式之间选择一个 | cat|dog 能够匹配到 "cat" 或 "dog" |
举例:\d{2,3}|[a-z]+(abc)* 的运算顺序
\d{2,3}匹配两到三个数字|表示或[a-z]+匹配一个或多个小写字母(abc)*匹配零个或多个 "abc"
二、Hive 正则表达式案例
2.1 like
- 语法1: A like B
- 语法2: like(A, B)
- 操作类型: strings
- 返回类型:boolean或null
- 描述:如果字符串A或者字符串B为null,则返回null;如果字符串A符合表达式B 的正则语法,则为true;否则为false。B中字符”_”表示任意单个字符,而字符”%”表示任意数量的字符。
- -- 举例:
- select 'ahngnfg' like '%nfg' --> true (%nfg也可以理解为以'nfg'结尾的字符)
- select 'ahngnfg' like 'nfg%' --> false(nfg%也可以理解为以'nfg'开头的字符)
- select 'ahngnfg' like '%nfg%' --> true (%nfg% 也可以理解为包含'nfg'的字符)
2.2 rlike
- 语法1: A rlike B
- 语法2: rlike (A, B)
- 操作类型: strings
- 返回类型: boolean或null
- 描述: 如果字符串A或者字符串B为null,则返回null;如果字符串A符合JAVA正则表达式B的正则语法,则为true;否则为false。B中字符”_”表示任意单个字符,而字符”%”表示任意数量的字符。
- java正则:
-
- "." 任意单个字符
- "*" 匹配前面的字符0次或多次
- "+" 匹配前面的字符1次或多次
- "?" 匹配前面的字符0次或1次
- "\d" 匹配一个数字字符,等于[0-9],使用的时候写成'\\d'
- "\D" 匹配一个非数字字符,等于[^0-9],使用的时候写成'\\D'
- -- 举例:
- select '2314' rlike '\\d+'; --> true
- select 'numrqe' rlike '^num'; --> true
2.3 regexp
- 语法1: A regexp B
- 语法2: regexp (A, B)
- 操作类型: strings
- 返回类型: boolean或null
- 描述: 功能与rlike相同
测试案例:
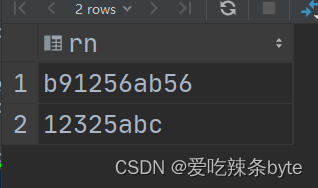
- -- 匹配有5个连续数字的字符串
- with tmp1 as
- (
- select '12325abc' as rn
- union all
- select 'b91256ab56' as rn
- union all
- select 'bfs89abc21' as rn
- )
- select rn
- from tmp1
- where rn regexp '\\d{5}';
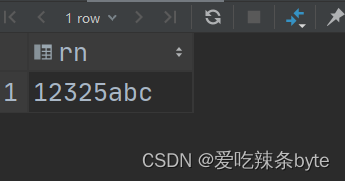
- -- 匹配开头有3个及以上连续数字的字符
- with tmp1 as
- (
- select '12325abc' as rn
- union all
- select '91fe56' as rn
- union all
- select 'bfs89abc21' as rn
- )
- select rn
- from tmp1
- where rn regexp '^\\d{3}';
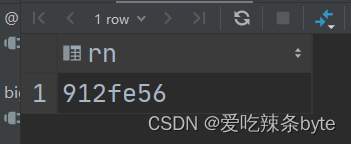
- -- 匹配开头只有3个连续数字的字符
- with tmp1 as
- (
- select '12325abc' as rn
- union all
- select '912fe56' as rn
- union all
- select 'bfs89abc21' as rn
- )
- select rn
- from tmp1
- where rn regexp '^\\d{3}\\D';
2.4 regexp_replace正则替换
- 语法: regexp_replace(string A, string B, string C)
- 操作类型: strings
- 返回值: string
- 说明: 将字符串A中的符合java正则表达式B的部分替换为C。
- -- 举例:
- select regexp_replace('h234ney', '\\d+', 'fd'); --> hfdney
2.5 regexp_extract正则提取
- 语法: regexp_extract(string A, string pattern, int index)
- 返回值: string
- 说明: 将字符串A按照pattern正则表达式的规则拆分,返回index指定的字符,index从1开始计
- --举例:
- select regexp_extract('honeymoon', 'hon(.*?)(oon)', 0); --> honeymoon
- select regexp_extract('honeymoon', 'hon(.*?)(oon)', 1); --> eym
- select regexp_extract('honeymoon', 'hon(.*?)(oon)', 2); --> oon
参考文章:
HIVE正则(like、rlike、regexp、regexp_replace、regexp_extract)_hive 正则化-CSDN博客
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/605145
推荐阅读
相关标签

