
- 1Stable Diffusion vs Midjunery的区别和选择
- 2Python pandas库操作 excel_python excel pandas
- 3pyspark 读取本地csv_数据分析工具篇——pyspark应用详解
- 4多示例学习 (multi-instance learning, MIL) 学习路线 (分类)_多示例分类
- 5基于LSTM的空气污染情况预测与可视化平台设计与实现_基于深度学习的空气质量预测系统
- 6Linux “如何添加用户/组和修改用户/组”
- 7深度生成模型阅读笔记(二)——自回归模型
- 8全卷积神经网络图像分割(U-net)-keras实现_zhixuhao
- 9Xilinx IDELAYE2应用笔记及仿真实操_idelaye2使用
- 10SpringBoot+Vue在线视频教育平台(源码+论文+答辩PPT+开题报告)_springboot vue在线教育
【AI】S2500 64C*2 arm64 aarch64 kylin server 编译llama.cpp 使用chinese-alpaca-2-7b模型 CPU版本 更多的核心没有带来更好的性能_arm linux编译llama
赞
踩
编译llama.cpp
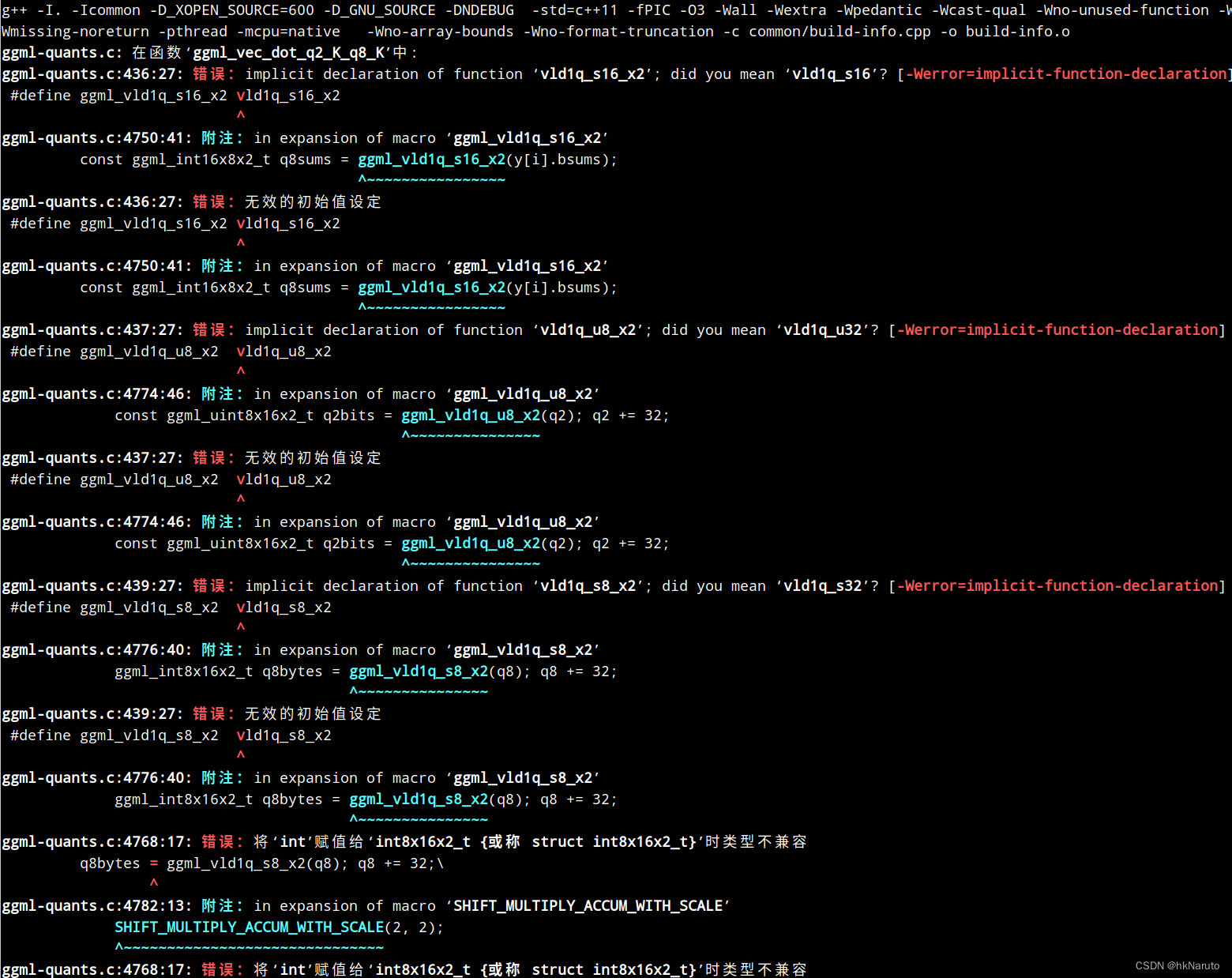
报错ggml-quants.c:436:27: 错误:implicit declaration of function ‘vld1q_s16_x2’; did you mean ‘vld1q_s16’
采用基于llvm的毕昇编译器
make -j32 CC=/root/bisheng-compiler-1.3.3-aarch64-linux/bin/clang CXX=/root/bisheng-compiler-1.3.3-aarch64-linux/bin/clang++
chat.sh
- #!/bin/bash
-
- # temporary script to chat with Chinese Alpaca-2 model
- # usage: ./chat.sh alpaca2-ggml-model-path your-first-instruction
-
- SYSTEM_PROMPT='You are a helpful assistant. 你是一个乐于助人的助手。'
- # SYSTEM_PROMPT='You are a helpful assistant. 你是一个乐于助人的助手。请你提供专业、有逻辑、内容真实、有价值的详细回复。' # Try this one, if you prefer longer response.
- MODEL_PATH=$1
- FIRST_INSTRUCTION=$2
-
- ./main -m "$MODEL_PATH" \
- --color -i -c 4096 -t 8 --temp 0.5 --top_k 40 --top_p 0.9 --repeat_penalty 1.1 \
- --in-prefix-bos --in-prefix ' [INST] ' --in-suffix ' [/INST]' -p \
- "[INST] <<SYS>>
- $SYSTEM_PROMPT
- <</SYS>>
- $FIRST_INSTRUCTION [/INST]"

测试 7b q8_0
# ll -h ~/ggml-model-f16-q8_0.bin
-rw-r--r-- 1 root root 6.9G 1月 23 14:59 /root/ggml-model-f16-q8_0.bin
# bash chat.sh ~/ggml-model-f16-q8_0.bin
成功启动
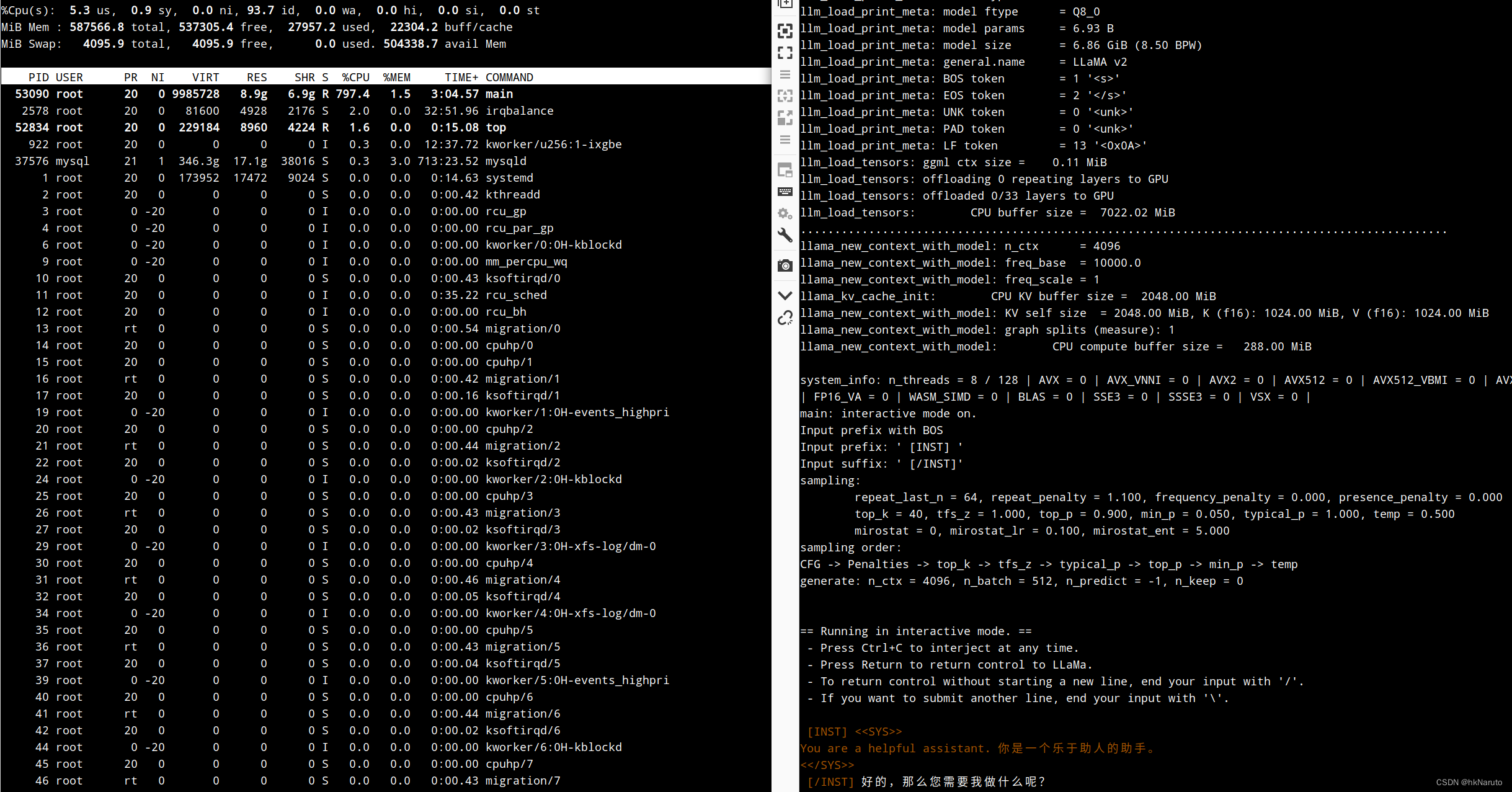
问题:明显看到CPU只使用了8个核心
继续观察

发现,并没有限制到某个node上。
即便如此,起响应速度也明细快于D2000 8核环境,内存大?
查看./main -h,发现线程参数
-t N, --threads N number of threads to use during generation (default: 64)
128线程测试
调整chat.sh脚本
#!/bin/bash
# temporary script to chat with Chinese Alpaca-2 model
# usage: ./chat.sh alpaca2-ggml-model-path your-first-instruction
SYSTEM_PROMPT='You are a helpful assistant. 你是一个乐于助人的助手。'
# SYSTEM_PROMPT='You are a helpful assistant. 你是一个乐于助人的助手。请你提供专业、有逻辑、内容真实、有价值的详细回复。' # Try this one, if you prefer longer response.
MODEL_PATH=$1
FIRST_INSTRUCTION=$2
./main -m "$MODEL_PATH" \
--color -i -c 4096 -t 128 --temp 0.5 --top_k 40 --top_p 0.9 --repeat_penalty 1.1 \
--in-prefix-bos --in-prefix ' [INST] ' --in-suffix ' [/INST]' -p \
"[INST] <<SYS>>
$SYSTEM_PROMPT
<</SYS>>
$FIRST_INSTRUCTION [/INST]"
CPU上去来,但是响应速度感觉变慢了!
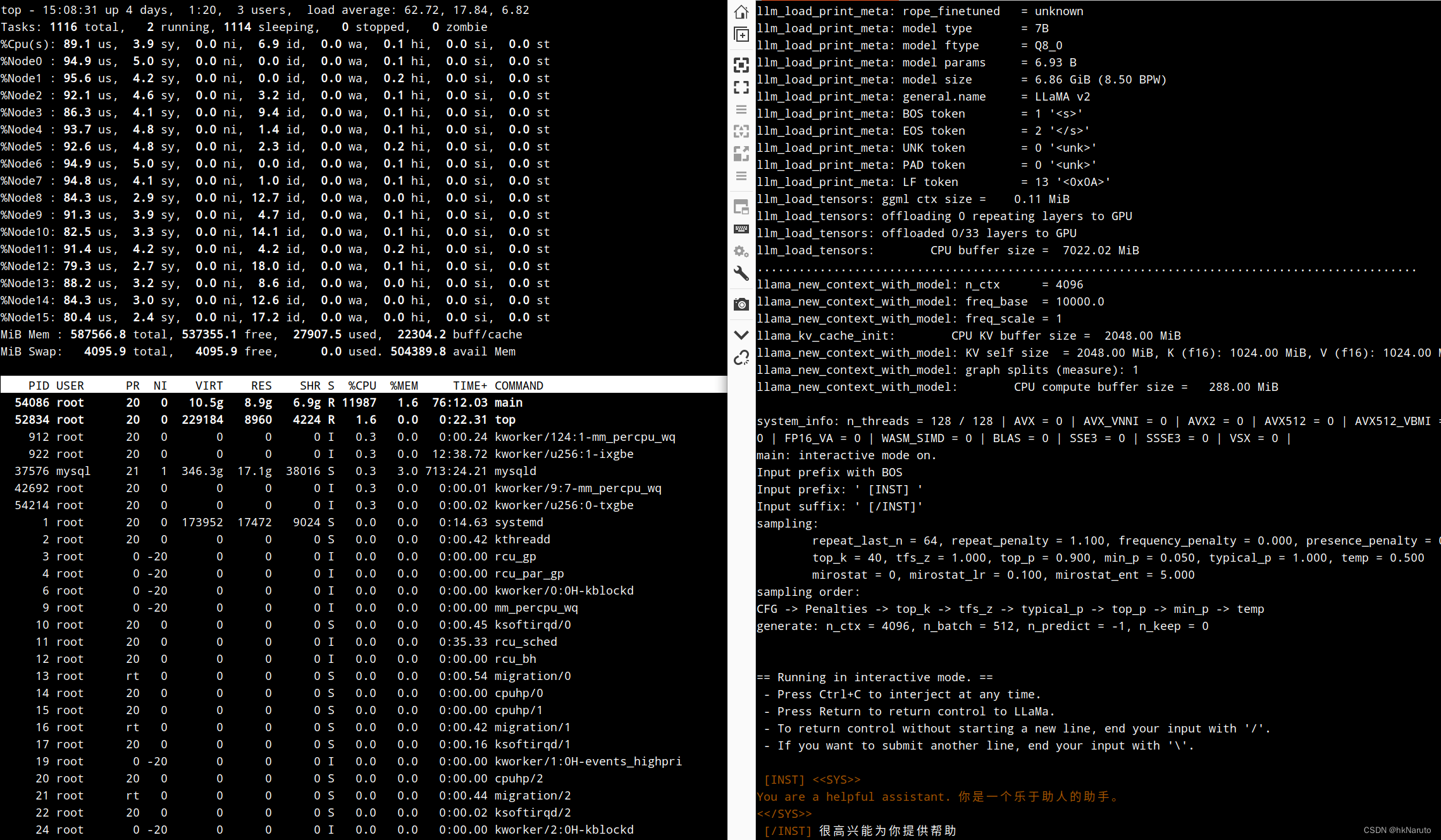
五秒钟都出不了一个字, 比-t 8还慢。。。

0-7 node 64线程(同样慢)
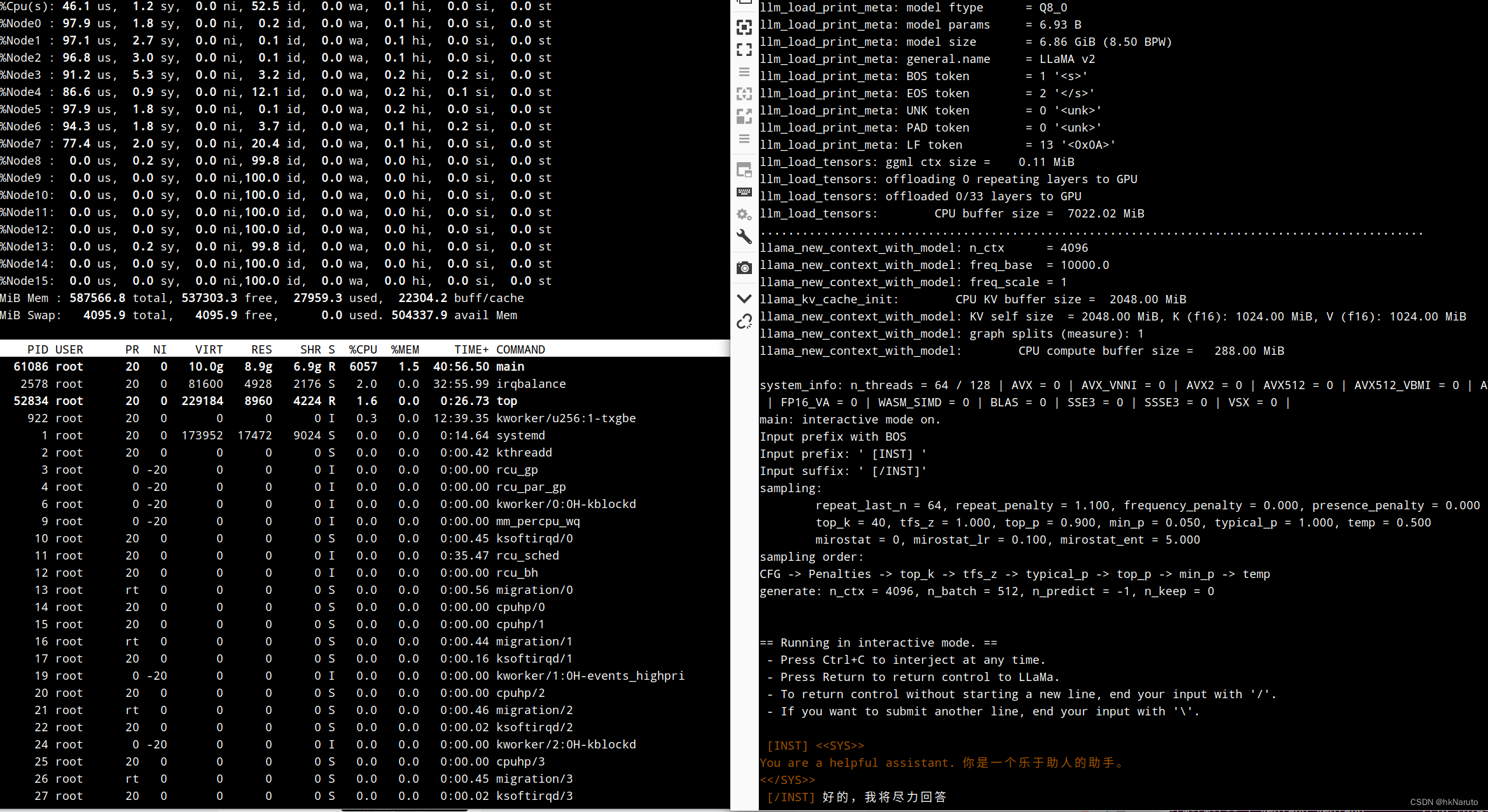
更多的CPU没有带来更好的性能提升。
参考:
https://hknaruto.blog.csdn.net/article/details/135764853?spm=1001.2014.3001.5502

