
热门标签
热门文章
- 1Linux命令(88)之echo_echo到文件不换行
- 2Python 中 NumPy 的数据类型_numpy显示数据类型
- 3linux终端执行需要交互的命令,例如执行命令后需要输入 Y/N 类似的_终端执行交互默认输入
- 4MyBatis3.x整理:(四)对象关系映射_mybatis--对象关系映射细节详解
- 5什么叫做云计算
- 6java 回溯算法 n皇后问题_回溯法n皇后问题java代码
- 7Android进程保活全攻略(中)_android service 监听锁屏解锁
- 8Hyper-V 启动黑屏的解决办法_hyper-v 黑屏
- 9语言模型(一)—— 统计语言模型n-gram语言模型
- 102024年五一数学建模竞赛赛题浅析-助攻快速选题_数学建模椭圆钢板切割
当前位置: article > 正文
Kafka消费者流程源码解析_kafka 消费者源码
作者:Cpp五条 | 2024-05-28 19:20:51
赞
踩
kafka 消费者源码
1.说明
本文章简单流程追踪一下Kafka从服务端拉取数据到客户端的流程。
看完本文,你将会大致了解消费者数据消费的过程。
2.消费者示例
Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "xxx:9092"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test"); properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.StickyAssignor"); KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties); // 订阅主题 kafkaConsumer.subscribe(Lists.newArrayList("test")); while (true) { // 拉取数据 ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> records : consumerRecords) { System.out.println(records); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
以上是一个简单的消费者demo,在开始源码之前务必 需要了解一下消费者消费初始化流程。
3.消费者消费初始化流程
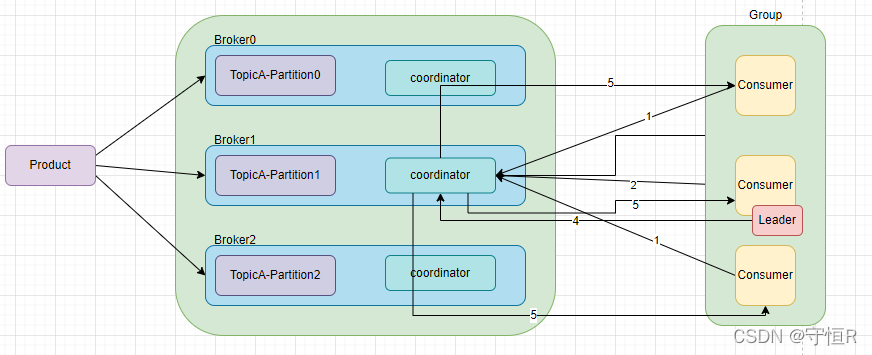 大致流程:
大致流程:
1.每个consumer都发送JoinGroup请求。
2.coordinator选出一个consumer作为leader。
3.把要消费的topic信息发送给leader消费者。
4.leader会制定一个消费方案,并把消费方案发给coordinator。
5.coordinator把消费方案下发给每个consumer。
6.每个consumer都会和coordinator保持心跳,默认3秒,一旦超时45秒,该消费者就会被移除,触发在平衡。
下面开始我们将重点分析数据拉取流程。
4.KafkaConsumer
KafkaConsumer的实例化:
private KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) { try { // 创建客户端对象 // reconnect.backoff.ms 连接重试时间 50ms // reconnect.backoff.max.ms 最大连接重试时间 1s // send.buffer.bytes 发送缓存 128kb // receive.buffer.bytes 64kb NetworkClient netClient = new NetworkClient( new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext), this.metadata, config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG), config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG), config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG), heartbeatIntervalMs); // 消费者分区分配策略 this.assignors = config.getConfiguredInstances( ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, PartitionAssignor.class); // 协助消费者初始化 // auto.commit.interval.ms 自动提交offset 5s this.coordinator = groupId == null ? null : new ConsumerCoordinator(logContext, this.client, groupId, maxPollIntervalMs, sessionTimeoutMs, config.getBoolean(ConsumerConfig.LEAVE_GROUP_ON_CLOSE_CONFIG)); // 消费者抓取器 // fetch.min.bytes 最小一次抓取的字节数 // fetch.max.bytes 最大抓取的字节数 // fetch.max.wait.ms 抓取的等待时间 // max.poll.records 一次性返回的最大条数 this.fetcher = new Fetcher<>( logContext, this.client, config.getInt(ConsumerConfig.FETCH_MIN_BYTES_CONFIG), config.getInt(ConsumerConfig.FETCH_MAX_BYTES_CONFIG), config.getInt(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG), config.getInt(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG), apiVersions); log.debug("Kafka consumer initialized"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
实例化过程中初始化了几个比较重要的组件。
5.consumer.subscribe
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
try {
log.info("Subscribed to topic(s): {}", Utils.join(topics, ", "));
// 订阅主题 (判断你是否需要更新订阅的主题) 注册了一个监听器,,有其他消费者挂了,需要重新分配
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
// 在平衡了,更新订阅信息
metadata.requestUpdateForNewTopics();
} finally {
release();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
subscribe()方法:
public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) {
// 注册负载均衡监听器
registerRebalanceListener(listener);
// 自动订阅模式
setSubscriptionType(SubscriptionType.AUTO_TOPICS);
// 是否需要更改订阅的主题
return changeSubscription(topics);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.consumer.poll()
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) { try { do { if (includeMetadataInTimeout) { // 1.消费者 或者 消费者组的初始化 // try to update assignment metadata BUT do not need to block on the timer for join group updateAssignmentMetadataIfNeeded(timer, false); } // 2.抓取数据 final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer); if (!records.isEmpty()) { // 3.拦截器处理数据 return this.interceptors.onConsume(new ConsumerRecords<>(records)); } } while (timer.notExpired()); return ConsumerRecords.empty(); } finally { } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
拉取数据,然后在经过拦截器处理数据,最后返回。
pollForFetches(timer):
// 开始拉取数据 fetcher.sendFetches(); public synchronized int sendFetches() { Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests(); for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) { final Node fetchTarget = entry.getKey(); final FetchSessionHandler.FetchRequestData data = entry.getValue(); // maxWaitMs 最大等待时间,默认500ms // minBytes 最少抓取一个字节 // maxBytes 最大抓取多少数据 默认50m final FetchRequest.Builder request = FetchRequest.Builder .forConsumer(this.maxWaitMs, this.minBytes, data.toSend()) .isolationLevel(isolationLevel) .setMaxBytes(this.maxBytes) .metadata(data.metadata()) .toForget(data.toForget()) .rackId(clientRackId); // 发送拉取数据的请求 RequestFuture<ClientResponse> future = client.send(fetchTarget, request); future.addListener(new RequestFutureListener<ClientResponse>() { // 拉取成功的回调 @Override public void onSuccess(ClientResponse resp) { // 把数据添加到队列里面 completedFetches.add(new CompletedFetch(partition, partitionData, metricAggregator, batches, fetchOffset, responseVersion)); } }); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
发送拉取数据的请求,拉取到的数据放到队列里面。
5.原理图
 完结。
完结。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/638940
推荐阅读
相关标签

