
- 1数据结构——哈希表、哈希桶
- 2在linux下安装mysql5.7_mysql5.7 aarch64 下载
- 3文心智能体:基于零代码平台的智能体开发与应用_文心智能体平台插件库
- 4git pull报错_git pull 报 git did not exist cleanly
- 5Android Service_c# android 后台运行
- 6安装Casaos系统后Nas脚本基础设置_casaos 安装完成后还需要安装那些文件
- 7springboot listener_Springboot 监听redis key的过期事件
- 8旅行商问题_旅行商问题,问题重述
- 9使用局部索引优化 PostgreSQL 和 MySQL 的性能
- 10redis队列list时效性过期解决方案_redis list 过期
强化学习算法_强化学习中加速度和角速度的离散化都具体怎么做的?比如角速度在[0,359]范围内
赞
踩
强化学习算法
游戏模型如下:
策略网络输入状态s,输出动作a的概率分布如下: π ( a ∣ s ) \pi(a|s) π(a∣s)
多次训练轨迹如下
- r表示回报
- 横轴为T, 1个回合的步骤数
- 纵轴为N, 回合数,1行代表1条轨迹,符合概率分布P
[
s
11
a
11
r
11
…
…
s
1
t
a
1
t
r
1
t
…
…
s
1
T
a
1
T
r
1
T
…
…
…
…
…
…
s
n
1
a
n
1
r
n
1
…
…
s
n
t
a
n
t
r
n
t
…
…
s
n
T
a
n
T
r
n
T
…
…
…
…
…
…
s
N
1
a
N
1
r
N
1
…
…
s
N
t
a
N
t
r
N
t
…
…
s
N
T
a
N
T
r
N
T
]
策略轨迹 τ = s 1 a 1 , s 2 a 2 , … … , s T a T \tau = s_{1} a_{1} , s_{2} a_{2},……,s_{T} a_{T} τ=s1a1,s2a2,……,sTaT
发生的概率
P
(
τ
)
=
P
(
s
1
a
1
,
s
2
a
2
,
…
…
,
s
T
a
T
)
P(\tau) = P(s_{1} a_{1} , s_{2} a_{2},……,s_{T} a_{T})
P(τ)=P(s1a1,s2a2,……,sTaT)
=
P
(
s
1
)
π
(
a
1
∣
s
1
)
P
(
s
2
∣
s
1
,
a
1
)
π
(
a
2
∣
s
2
)
P
(
s
3
∣
s
1
,
a
1
,
s
2
,
a
2
)
…
…
= P(s_{1})\pi(a_{1}|s_{1})P(s_{2}|s_{1},a_{1})\pi(a_{2}|s_{2})P(s_{3}|s_{1},a_{1},s_{2},a_{2})……
=P(s1)π(a1∣s1)P(s2∣s1,a1)π(a2∣s2)P(s3∣s1,a1,s2,a2)……
=
P
(
s
1
)
∏
t
=
1
T
−
1
π
(
a
t
∣
s
t
)
P
(
s
t
+
1
∣
s
1
,
a
1
,
.
.
.
.
.
.
,
s
t
,
a
t
)
= P(s_{1})\prod_{t=1}^{T-1}\pi(a_{t}|s_{t})P(s_{t+1}|s_{1},a_{1},......,s_{t},a_{t})
=P(s1)t=1∏T−1π(at∣st)P(st+1∣s1,a1,......,st,at)
根据 马尔科夫性(Markov Property),简化为:
P
(
τ
)
=
P
(
s
1
)
∏
t
=
1
T
−
1
π
(
a
t
∣
s
t
)
P
(
s
t
+
1
∣
s
t
,
a
t
)
P(\tau) = P(s_{1})\prod_{t=1}^{T-1}\pi(a_{t}|s_{t})P(s_{t+1}|s_{t},a_{t})
P(τ)=P(s1)t=1∏T−1π(at∣st)P(st+1∣st,at)
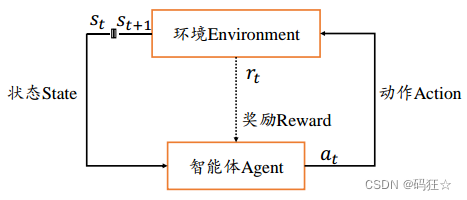
奖励
在每次智能体与环境的交互过程中,均会得到一个滞后的奖励
r
t
=
r
(
s
t
,
a
t
)
r_{t} = r(s_{t},a_{t})
rt=r(st,at)
一次交互轨迹
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

