
- 1Stable Diffusion基础:ControlNet之人体姿势控制_为什么我的controlnet不能控制骨架
- 2在VSCode中配置Verilog语言环境并使用学习WaveTrace插件
- 3GitHub配置SSH Key(详细版本)_github ssh key配置
- 4OpenCV项目开发实战--条形码和 QR 码扫描器(C++ 和 Python)的代码实现_opencv二维码检测c++
- 5六、Redis 分布式系统 —— 超详细操作演示!_redis怎么实现分布式
- 6解决 springboot项目打包部署到linux系统下,下载resources/static/静态资源找不到的问题_spirngboot 静态资源,打包到linux 丢失
- 7Linux文件权限_linux 文件权限
- 8vscode连接 gitee_vscode 使用ssh连接gitee
- 9图论(二):图的四种最短路径算法
- 10anaconda实现python环境搭建_anaconda配置python环境
服务器最全安装、配置、启动Spark集群_启动spark集群的命令_配置spark快速启动
赞
踩
(1)切换到 /opt 目录下
cd /opt/
- 1
- 2
(2)在官网下载spark的安装包,并上传至服务器上
(3)解压 spark 文件到当前目录(/opt)下面,使用相对路径或者绝对路径均可,下面的命令使用绝对路径
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /opt
- 1
- 2

(4)给Spark文件重命名为spark-2.2.0
mv spark-2.2.0-bin-hadoop2.7 spark-2.2.0
- 1
- 2
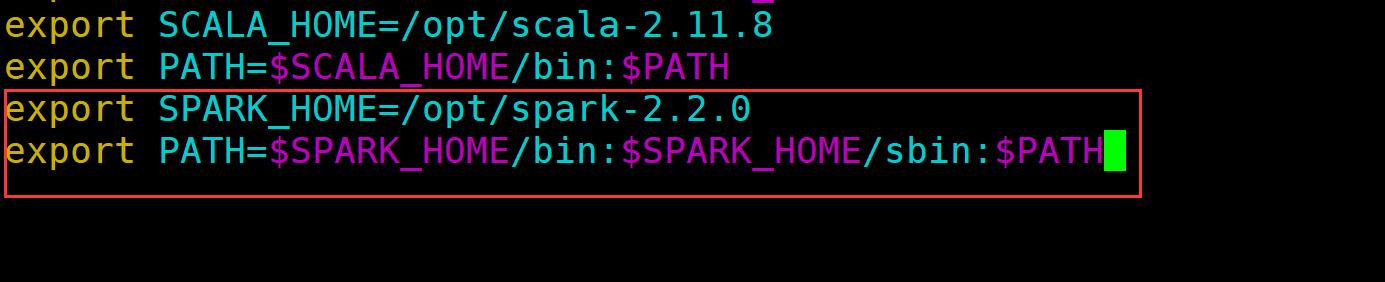
(5)配置环境变量,编辑 /etc/profile 文件,在文件最后添加 spark 路径
vim /etc/profile
- 1
- 2

export SPARK_HOME=/opt/spark-2.2.0
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
- 1
- 2
- 3
(6)使环境变量生效
source /etc/profile
- 1
- 2

(7)切换到 /opt/spark-2.2.0/conf 目录下
cd /opt/spark-2.2.0/conf
- 1
- 2

(8)修改 spark 的配置文件 spark-env.sh
先将文件 spark-env.sh.template 重命名为 spark-env.sh
mv spark-env.sh.template spark-env.sh
- 1
- 2

再修改文件spark-env.sh
vim spark-env.sh
- 1
- 2

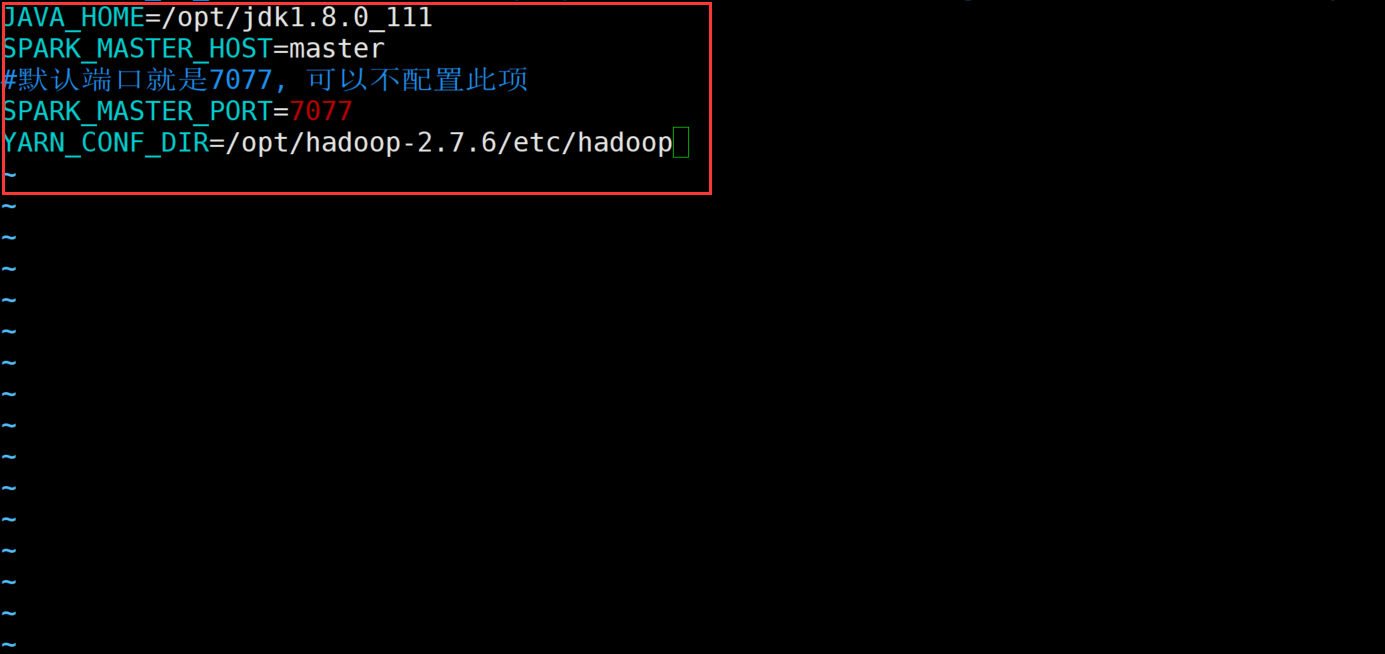
修改内容如下:
JAVA_HOME=/opt/jdk1.8.0_111
SPARK_MASTER_HOST=master
#默认端口就是7077, 可以不配置此项
SPARK_MASTER_PORT=7077
YARN_CONF_DIR=/opt/hadoop-2.7.6/etc/hadoop
- 1
- 2
- 3
- 4
- 5
- 6
(9)修改spark的配置文件
①、先将文件slaves.template重命名为slaves
mv slaves.template slaves
- 1
- 2
②、再修改文件slaves
vim slaves
- 1
- 2
修改内容如下:
master
slave1
slave2
- 1
- 2
- 3
- 4
(10)由于slave1节点也需要安装 spark,因此可以先将master节点的 /opt/spark-2.2.0 文件和 /etc/profile 文件拷贝到slave1的相同路径下
scp -r /opt/spark-2.2.0 root@slave1:/opt
- 1
- 2

scp /etc/profile root@slave1:/etc
- 1
- 2

(11)由于slave2节点也需要安装 spark,因此可以先将master节点的 /opt/spark-2.2.0 文件和 /etc/profile 文件拷贝到slave2的相同路径下
scp -r /opt/spark-2.2.0 root@slave2:/opt
- 1
- 2

自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
会持续更新**
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-ZAolN5tQ-1713035618597)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

