
- 1算法设计与分析_练习三_动态规划算法_有两个数字序列,序列x和序列y,求这两个序列的最长公共子序列。
- 2 前端状态管理请三思
- 3如何在Python中安装TensorFlow_tensorflow怎么安装到python
- 4【文献阅读笔记】M2SNet: Multi-scale in Multi-scale Subtraction Network for Medical Image Segmentation
- 5【强化学习】常用算法之一 “DQN”_dqn公式
- 6nlohmann/json学习使用及示例
- 7什么是0day漏洞,1day漏洞和nday漏洞?
- 8【Java每日面试题】大厂是如何设计秒杀系统的?,2024年最新java开发工程师面试问题汇总
- 9pyside2 环境配置 mac M1_macbook安装pyside2
- 10Mybatis-Plus 3.2.0 版本 MetaObjectHandler 无法进行公共字段全局填充_metaobjecthandler 和 自定义xml 冲突
我做的百度飞桨PaddleOCR .NET调用库
赞
踩
.NET Conf 2021中国我做了一次《.NET玩转计算机视觉OpenCV》的分享,其中提到了一个效果特别好的OCR识别引擎——百度飞桨PaddleOCR,后来我逐步把它封装了一下,代码全部开源(可点击查看原文跳转到Github):https://github.com/sdcb/paddlesharp,可以直接安装NuGet包使用,支持.NET Framework/.NET Core、支持Linux、支持GPU调用,支持14种语言模型的自动下载:

这里有使用方法和示例代码:
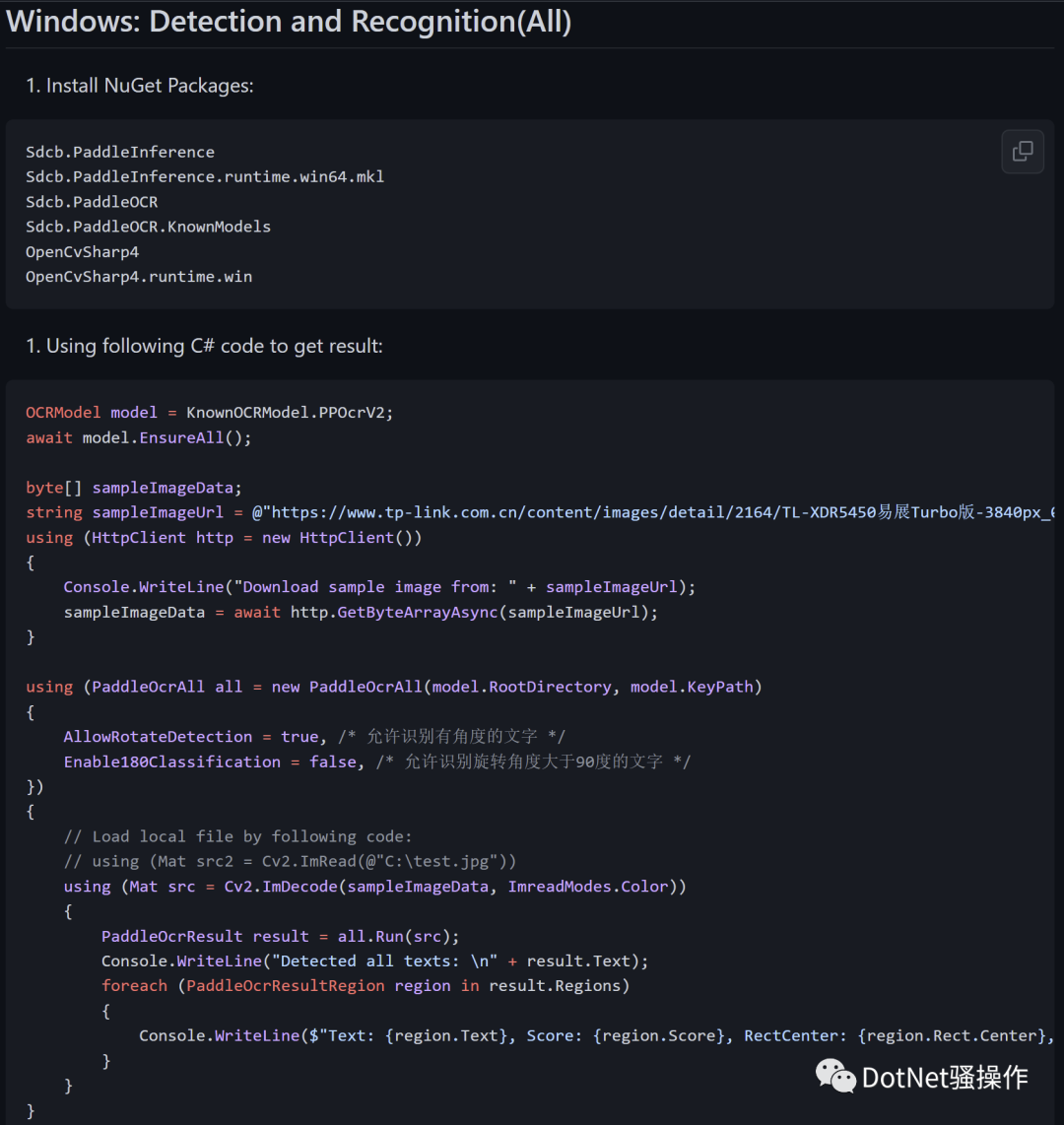
运行效果:
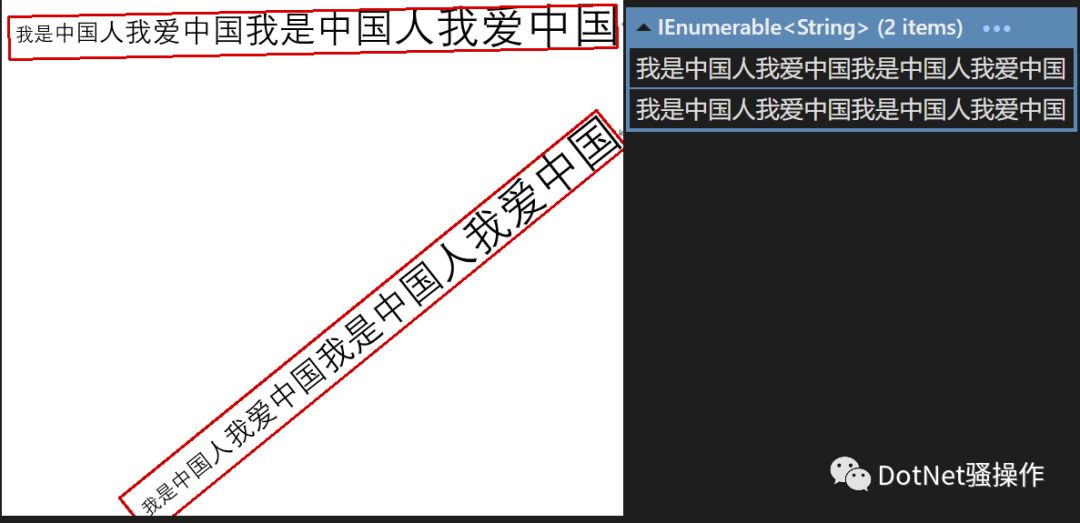

促使我给PaddleOCR做.NET封装的原因,是PaddleOCR令人惊讶的识别精度。我之前用过TesseractOCR,看到有人说是“世界上唯一”免费且好用的OCR引擎,但我发现它不好用,它的精度一直介于“可用”与“不可用”之间,处于勉强可用的状态——即使是我使用了Best的TesseractOCR模型也是如此(而且性能也不快)。
比如你看这个例子,用TesseractOCR跑的,耗时48秒,英语和数字识别还是可圈可点的,但中文……里面有空格不说,而且大量识别错误,非常不通顺,诠释了什么叫“介于可用与不可用之间”。
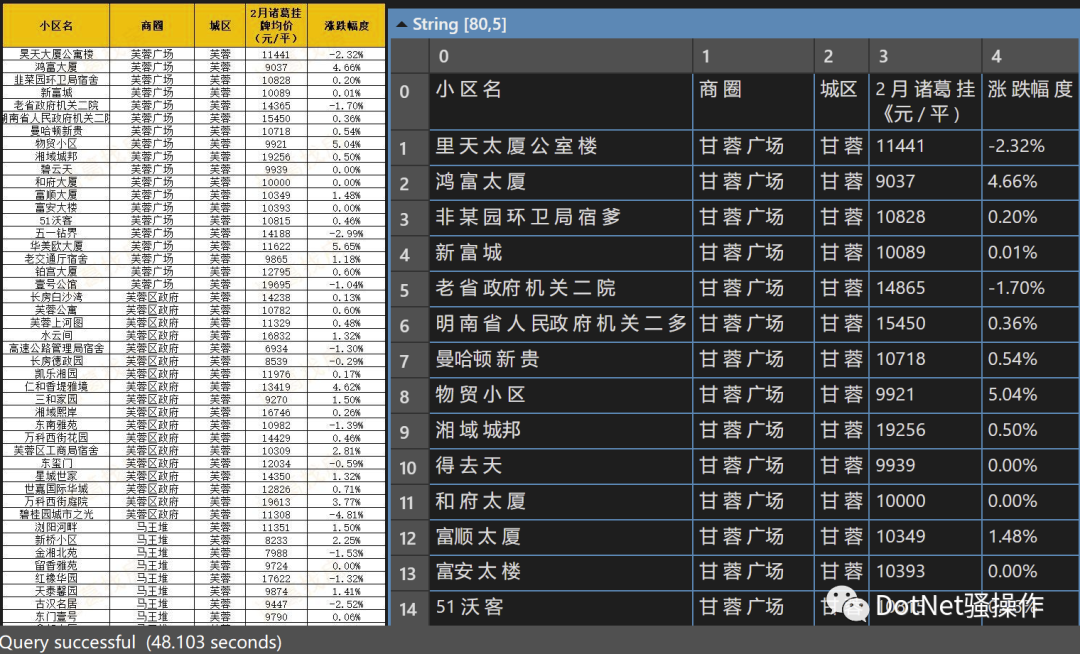
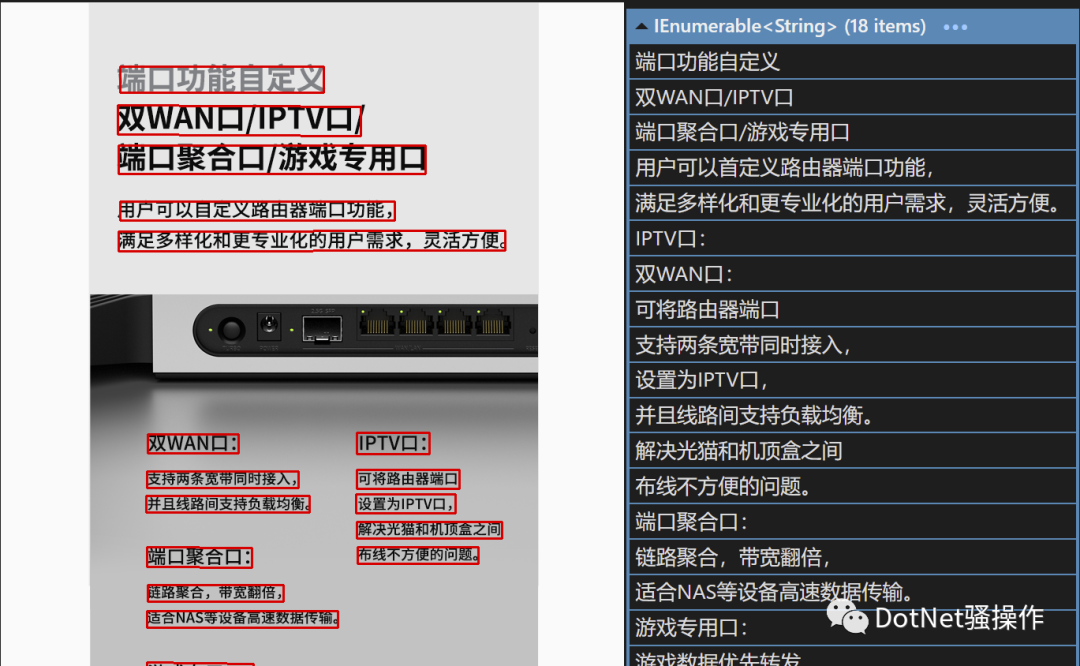
但PaddleOCR不同,去看看官网示例,全部都是效果爆炸的感觉,最令人我惊讶的是它的精度,尤其是文字在旋转的状态下的精度:

上文中同样的例子,在PaddleOCR中的执行结果:
可见精度好得多,耗时也只要9秒。
我是怎么封装的?
我发现市场上有人封装过,但他们都是基于C++ API,然后自己写了一层C++,然后包装成C API进行封装。这样的好处是暴露出来的C API比较简单,调用起来很方便,但缺点是不方便扩展,使用起来笨重得多,跨平台也很难。
基于C API使用起来不方便,但上层不是有咱们.NET/C#嘛,我相信再不方便的API,只要用上了C#/.NET去封装它,都能做得很方便地去调用,于是我做出了这样的一个架构(这个架构本质是模仿了OpenCvSharp4)
最低层是C API的NuGet封装包,这个用PInvoke来封装C API,它的NuGet包名字是:Sdcb.PaddleInference
与低层配套的包叫native binding包,我提供了两个,一个是基于CPU的Sdcb.PaddleInference.runtime.win64.mkl,一个是基于GPU的Sdcb.PaddleInference.runtime.win64.cuda11_cudnn8_tr7。
值得注意的是,native binding包与低层包没有任何依赖关系。
再往上层是应用包,应用包依赖于低层的推理库包Sdcb.PaddleInference,文字识别OCR就是Paddle推理库Inference的一个应用,因此提供了一个Sdcb.PaddleOCR,封装了PaddleDetector、PaddleClassificator、PaddleRecognizor以及PaddleOcrAll用来做串联
最往上层走就是扩展包,我提供了一个用于帮助用户自动下载OCR模型的Sdcb.PaddleOCR.KnownModels,注意这个扩展包与上述包没有任何引用关系。
有了这些包,我做出来的这个封装就比其它封装更有竞争力,比如能支持GPU或者不支持GPU,比如支持Linux平台,比如更换不同的模型,比如支持设置不同的参数——用户甚至可以不基于我提供的应用包,自己去使用自己的逻辑封装PaddleOCR或者其它应用。
这几天我参与了百度飞桨的一个车牌号识别的3天训练营,我发现可以从百度的BML平台下载模型之后,只需简短的改动就能将我的PaddleSharp改成支持车牌号识别:
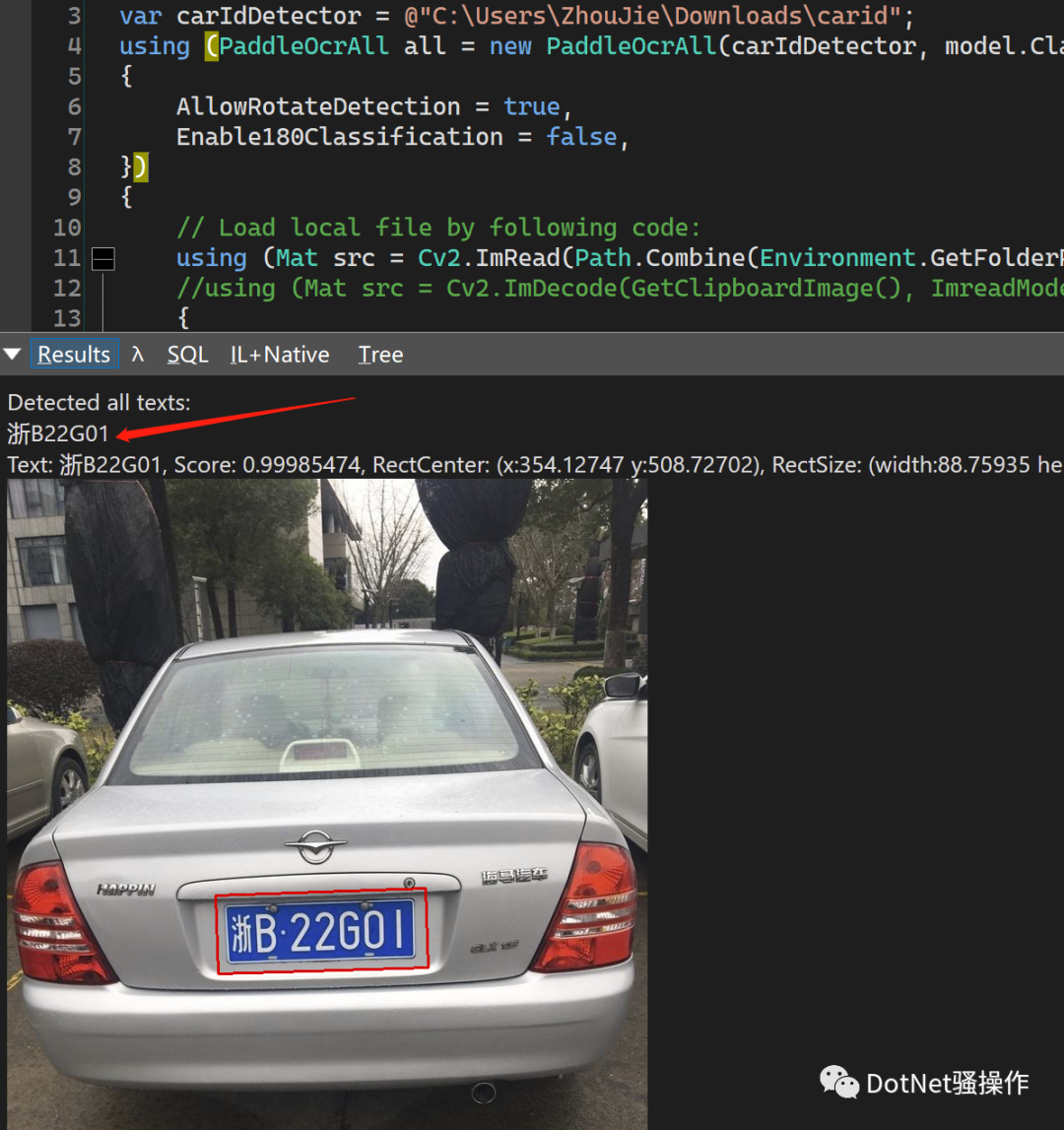
我发现通过这些绵薄之力,能为.NET社区带来一些方便。比如有客户已经用上我的包,做了一个Word插件,是付费产品,效果很不错:

这些内容都是开源的:https://github.com/sdcb/paddlesharp,各位可以点击阅读原文跳转到Github,喜欢的朋友请给我一个star哦。
另外我还创建了一个QQ群,C#/.NET计算机视觉技术交流,里面也包括有关这个PaddleSharp的使用、部署答疑和技术讨论,欢迎有兴趣的同行一起参与!




